 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Cordyceps@LT-EDI: Patching Language-Specific Homophobia/Transphobia Classifiers with a Multilingual Understanding
Sep 24, 2023
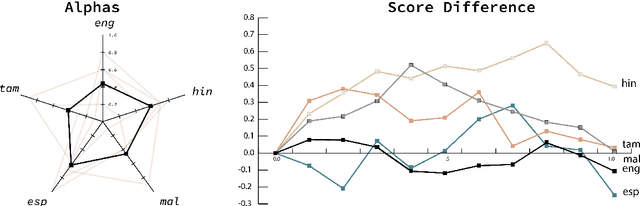
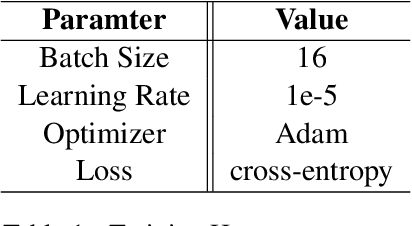
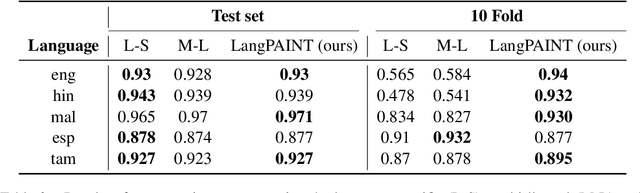
Detecting transphobia, homophobia, and various other forms of hate speech is difficult. Signals can vary depending on factors such as language, culture, geographical region, and the particular online platform. Here, we present a joint multilingual (M-L) and language-specific (L-S) approach to homophobia and transphobic hate speech detection (HSD). M-L models are needed to catch words, phrases, and concepts that are less common or missing in a particular language and subsequently overlooked by L-S models. Nonetheless, L-S models are better situated to understand the cultural and linguistic context of the users who typically write in a particular language. Here we construct a simple and successful way to merge the M-L and L-S approaches through simple weight interpolation in such a way that is interpretable and data-driven. We demonstrate our system on task A of the 'Shared Task on Homophobia/Transphobia Detection in social media comments' dataset for homophobia and transphobic HSD. Our system achieves the best results in three of five languages and achieves a 0.997 macro average F1-score on Malayalam texts.
Hybrid Attention-based Encoder-decoder Model for Efficient Language Model Adaptation
Sep 14, 2023
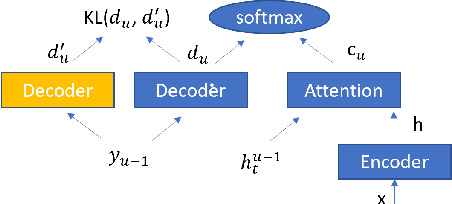
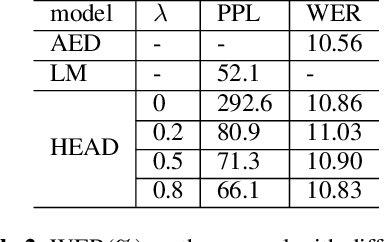
Attention-based encoder-decoder (AED) speech recognition model has been widely successful in recent years. However, the joint optimization of acoustic model and language model in end-to-end manner has created challenges for text adaptation. In particular, effectively, quickly and inexpensively adapting text has become a primary concern for deploying AED systems in industry. To address this issue, we propose a novel model, the hybrid attention-based encoder-decoder (HAED) speech recognition model that preserves the modularity of conventional hybrid automatic speech recognition systems. Our HAED model separates the acoustic and language models, allowing for the use of conventional text-based language model adaptation techniques. We demonstrate that the proposed HAED model yields 21\% Word Error Rate (WER) improvements in relative when out-of-domain text data is used for language model adaptation, and with only a minor degradation in WER on a general test set compared with conventional AED model.
Duplex Diffusion Models Improve Speech-to-Speech Translation
May 22, 2023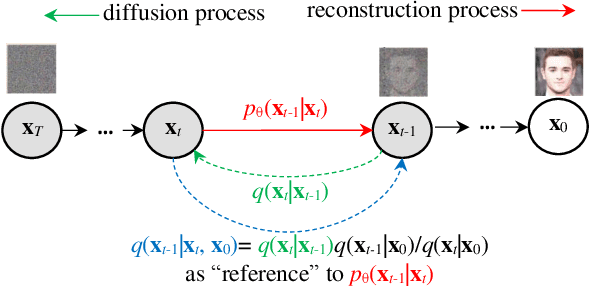
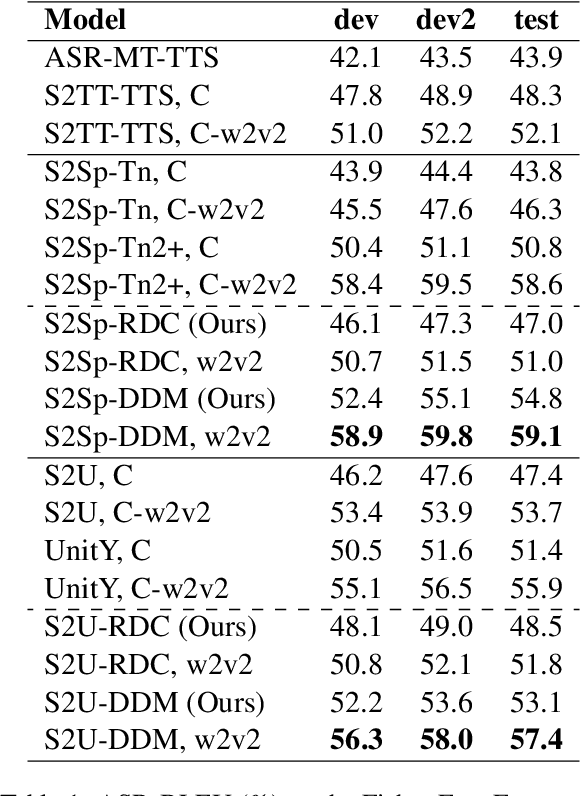

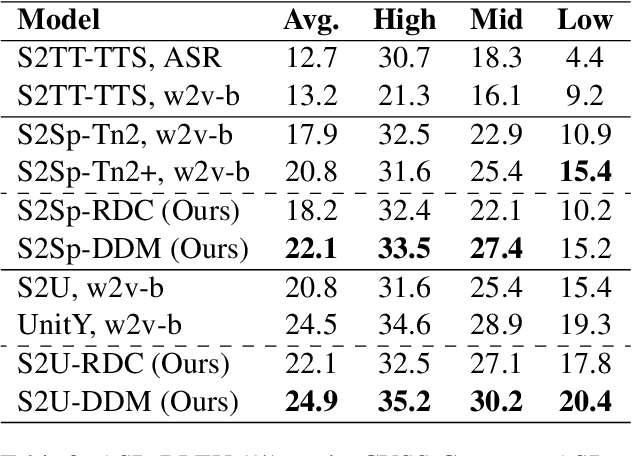
Speech-to-speech translation is a typical sequence-to-sequence learning task that naturally has two directions. How to effectively leverage bidirectional supervision signals to produce high-fidelity audio for both directions? Existing approaches either train two separate models or a multitask-learned model with low efficiency and inferior performance. In this paper, we propose a duplex diffusion model that applies diffusion probabilistic models to both sides of a reversible duplex Conformer, so that either end can simultaneously input and output a distinct language's speech. Our model enables reversible speech translation by simply flipping the input and output ends. Experiments show that our model achieves the first success of reversible speech translation with significant improvements of ASR-BLEU scores compared with a list of state-of-the-art baselines.
Multi-GradSpeech: Towards Diffusion-based Multi-Speaker Text-to-speech Using Consistent Diffusion Models
Aug 21, 2023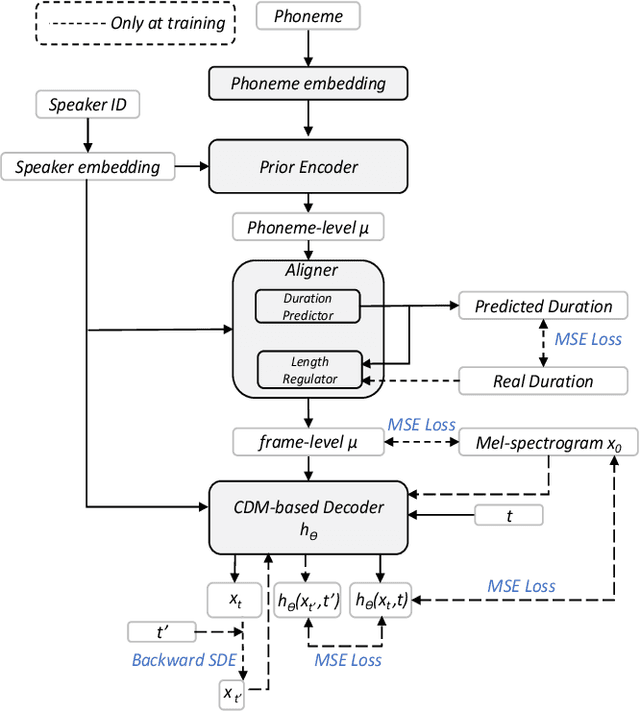
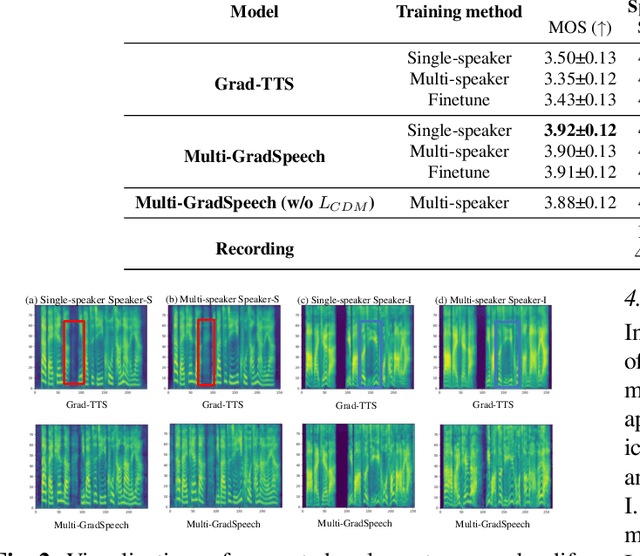
Recent advancements in diffusion-based acoustic models have revolutionized data-sufficient single-speaker Text-to-Speech (TTS) approaches, with Grad-TTS being a prime example. However, diffusion models suffer from drift in training and sampling distributions due to imperfect score-matching. The sampling drift problem leads to these approaches struggling in multi-speaker scenarios in practice. In this paper, we present Multi-GradSpeech, a multi-speaker diffusion-based acoustic models which introduces the Consistent Diffusion Model (CDM) as a generative modeling approach. We enforce the consistency property of CDM during the training process to alleviate the sampling drift problem in the inference stage, resulting in significant improvements in multi-speaker TTS performance. Our experimental results corroborate that our proposed approach can improve the performance of different speakers involved in multi-speaker TTS compared to Grad-TTS, even outperforming the fine-tuning approach. Audio samples are available at https://welkinyang.github.io/multi-gradspeech/
Audio-Visual Speaker Verification via Joint Cross-Attention
Sep 28, 2023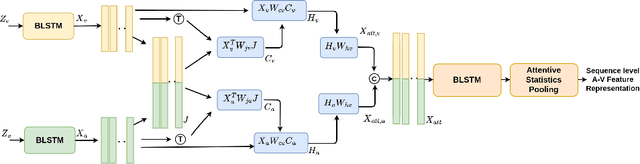

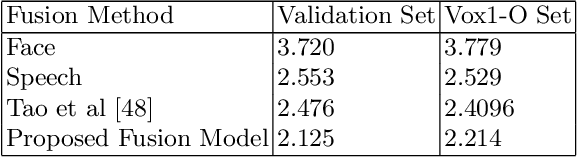
Speaker verification has been widely explored using speech signals, which has shown significant improvement using deep models. Recently, there has been a surge in exploring faces and voices as they can offer more complementary and comprehensive information than relying only on a single modality of speech signals. Though current methods in the literature on the fusion of faces and voices have shown improvement over that of individual face or voice modalities, the potential of audio-visual fusion is not fully explored for speaker verification. Most of the existing methods based on audio-visual fusion either rely on score-level fusion or simple feature concatenation. In this work, we have explored cross-modal joint attention to fully leverage the inter-modal complementary information and the intra-modal information for speaker verification. Specifically, we estimate the cross-attention weights based on the correlation between the joint feature presentation and that of the individual feature representations in order to effectively capture both intra-modal as well inter-modal relationships among the faces and voices. We have shown that efficiently leveraging the intra- and inter-modal relationships significantly improves the performance of audio-visual fusion for speaker verification. The performance of the proposed approach has been evaluated on the Voxceleb1 dataset. Results show that the proposed approach can significantly outperform the state-of-the-art methods of audio-visual fusion for speaker verification.
Sparse Fine-tuning for Inference Acceleration of Large Language Models
Oct 13, 2023We consider the problem of accurate sparse fine-tuning of large language models (LLMs), that is, fine-tuning pretrained LLMs on specialized tasks, while inducing sparsity in their weights. On the accuracy side, we observe that standard loss-based fine-tuning may fail to recover accuracy, especially at high sparsities. To address this, we perform a detailed study of distillation-type losses, determining an L2-based distillation approach we term SquareHead which enables accurate recovery even at higher sparsities, across all model types. On the practical efficiency side, we show that sparse LLMs can be executed with speedups by taking advantage of sparsity, for both CPU and GPU runtimes. While the standard approach is to leverage sparsity for computational reduction, we observe that in the case of memory-bound LLMs sparsity can also be leveraged for reducing memory bandwidth. We exhibit end-to-end results showing speedups due to sparsity, while recovering accuracy, on T5 (language translation), Whisper (speech translation), and open GPT-type (MPT for text generation). For MPT text generation, we show for the first time that sparse fine-tuning can reach 75% sparsity without accuracy drops, provide notable end-to-end speedups for both CPU and GPU inference, and highlight that sparsity is also compatible with quantization approaches. Models and software for reproducing our results are provided in Section 6.
PCNN: A Lightweight Parallel Conformer Neural Network for Efficient Monaural Speech Enhancement
Jul 28, 2023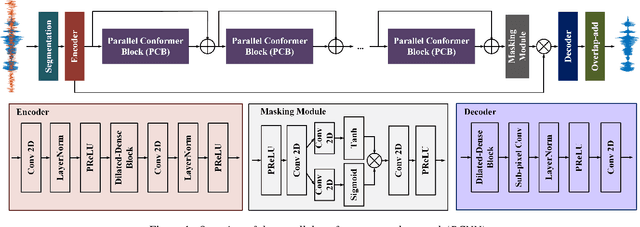
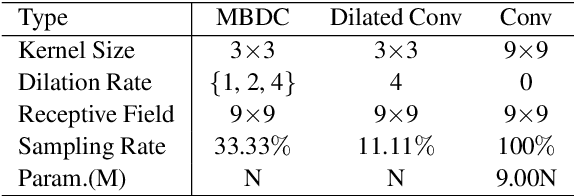
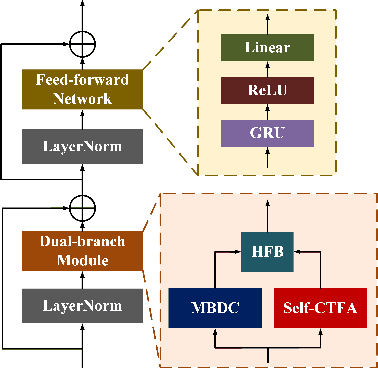
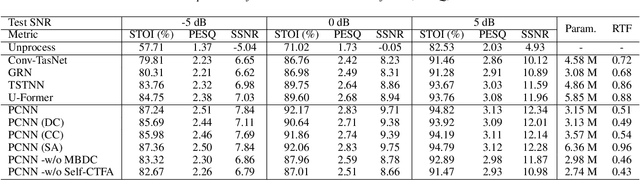
Convolutional neural networks (CNN) and Transformer have wildly succeeded in multimedia applications. However, more effort needs to be made to harmonize these two architectures effectively to satisfy speech enhancement. This paper aims to unify these two architectures and presents a Parallel Conformer for speech enhancement. In particular, the CNN and the self-attention (SA) in the Transformer are fully exploited for local format patterns and global structure representations. Based on the small receptive field size of CNN and the high computational complexity of SA, we specially designed a multi-branch dilated convolution (MBDC) and a self-channel-time-frequency attention (Self-CTFA) module. MBDC contains three convolutional layers with different dilation rates for the feature from local to non-local processing. Experimental results show that our method performs better than state-of-the-art methods in most evaluation criteria while maintaining the lowest model parameters.
Knowledge Distilled Ensemble Model for sEMG-based Silent Speech Interface
Aug 07, 2023Voice disorders affect millions of people worldwide. Surface electromyography-based Silent Speech Interfaces (sEMG-based SSIs) have been explored as a potential solution for decades. However, previous works were limited by small vocabularies and manually extracted features from raw data. To address these limitations, we propose a lightweight deep learning knowledge-distilled ensemble model for sEMG-based SSI (KDE-SSI). Our model can classify a 26 NATO phonetic alphabets dataset with 3900 data samples, enabling the unambiguous generation of any English word through spelling. Extensive experiments validate the effectiveness of KDE-SSI, achieving a test accuracy of 85.9\%. Our findings also shed light on an end-to-end system for portable, practical equipment.
VIC-KD: Variance-Invariance-Covariance Knowledge Distillation to Make Keyword Spotting More Robust Against Adversarial Attacks
Sep 22, 2023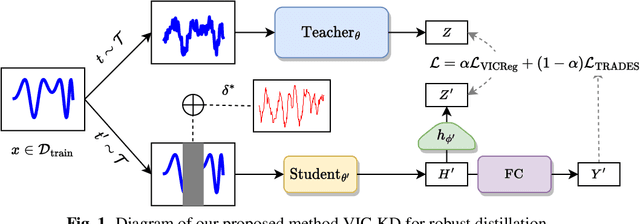
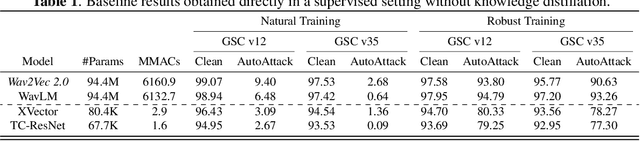
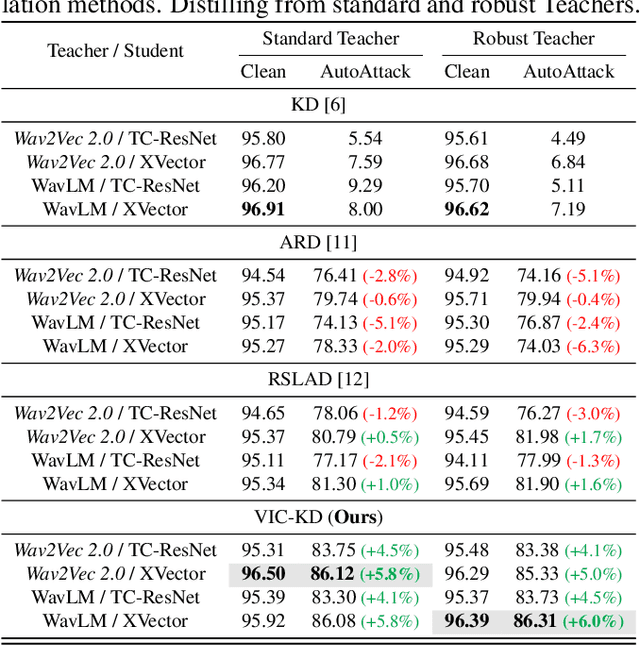
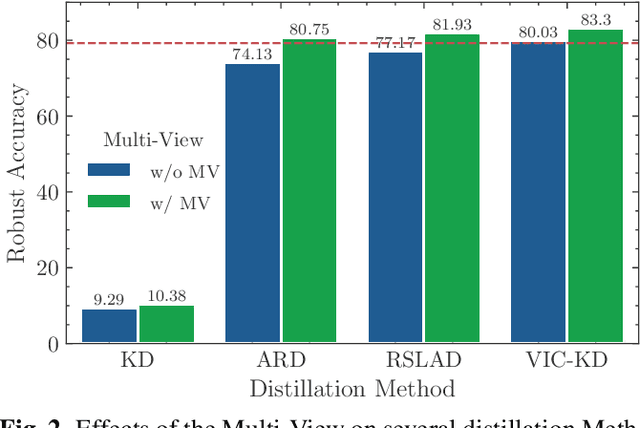
Keyword spotting (KWS) refers to the task of identifying a set of predefined words in audio streams. With the advances seen recently with deep neural networks, it has become a popular technology to activate and control small devices, such as voice assistants. Relying on such models for edge devices, however, can be challenging due to hardware constraints. Moreover, as adversarial attacks have increased against voice-based technologies, developing solutions robust to such attacks has become crucial. In this work, we propose VIC-KD, a robust distillation recipe for model compression and adversarial robustness. Using self-supervised speech representations, we show that imposing geometric priors to the latent representations of both Teacher and Student models leads to more robust target models. Experiments on the Google Speech Commands datasets show that the proposed methodology improves upon current state-of-the-art robust distillation methods, such as ARD and RSLAD, by 12% and 8% in robust accuracy, respectively.
Robust Hate Speech Detection in Social Media: A Cross-Dataset Empirical Evaluation
Jul 04, 2023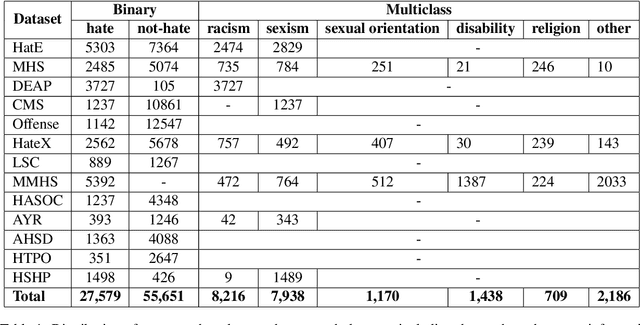
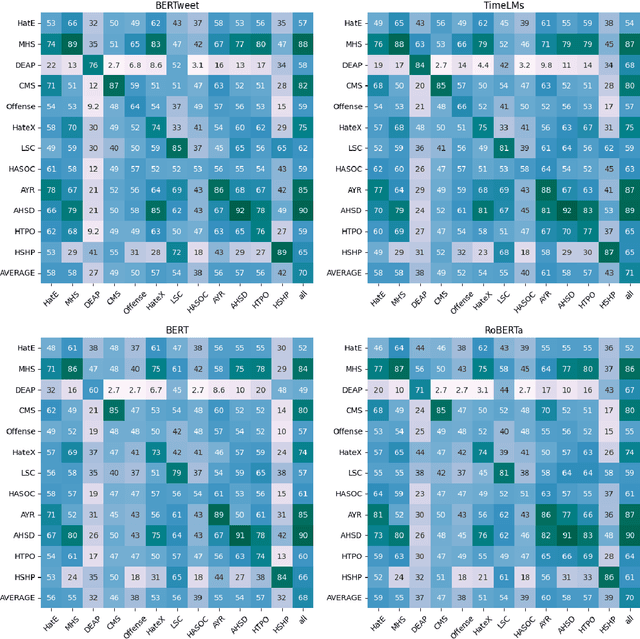
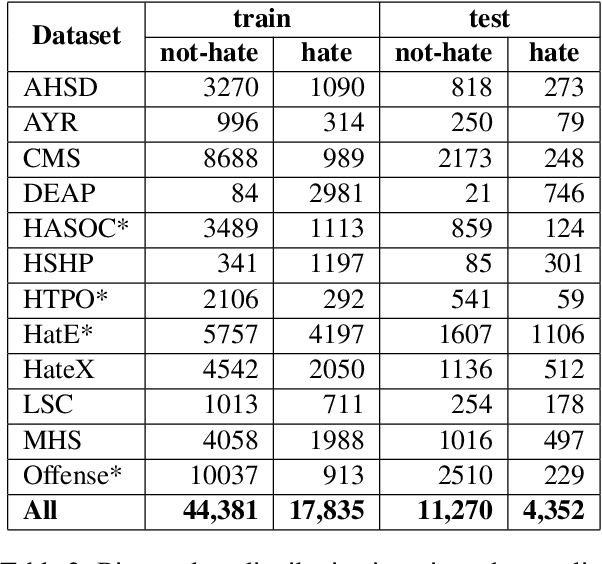
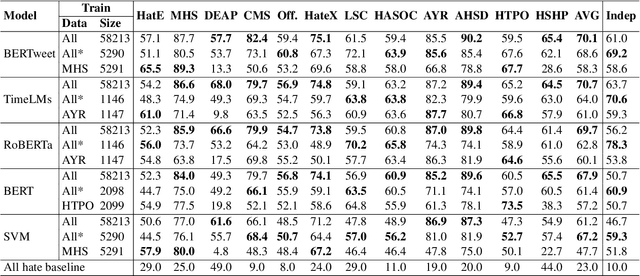
The automatic detection of hate speech online is an active research area in NLP. Most of the studies to date are based on social media datasets that contribute to the creation of hate speech detection models trained on them. However, data creation processes contain their own biases, and models inherently learn from these dataset-specific biases. In this paper, we perform a large-scale cross-dataset comparison where we fine-tune language models on different hate speech detection datasets. This analysis shows how some datasets are more generalisable than others when used as training data. Crucially, our experiments show how combining hate speech detection datasets can contribute to the development of robust hate speech detection models. This robustness holds even when controlling by data size and compared with the best individual datasets.