 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
GestSync: Determining who is speaking without a talking head
Oct 08, 2023
In this paper we introduce a new synchronisation task, Gesture-Sync: determining if a person's gestures are correlated with their speech or not. In comparison to Lip-Sync, Gesture-Sync is far more challenging as there is a far looser relationship between the voice and body movement than there is between voice and lip motion. We introduce a dual-encoder model for this task, and compare a number of input representations including RGB frames, keypoint images, and keypoint vectors, assessing their performance and advantages. We show that the model can be trained using self-supervised learning alone, and evaluate its performance on the LRS3 dataset. Finally, we demonstrate applications of Gesture-Sync for audio-visual synchronisation, and in determining who is the speaker in a crowd, without seeing their faces. The code, datasets and pre-trained models can be found at: \url{https://www.robots.ox.ac.uk/~vgg/research/gestsync}.
Haha-Pod: An Attempt for Laughter-based Non-Verbal Speaker Verification
Sep 25, 2023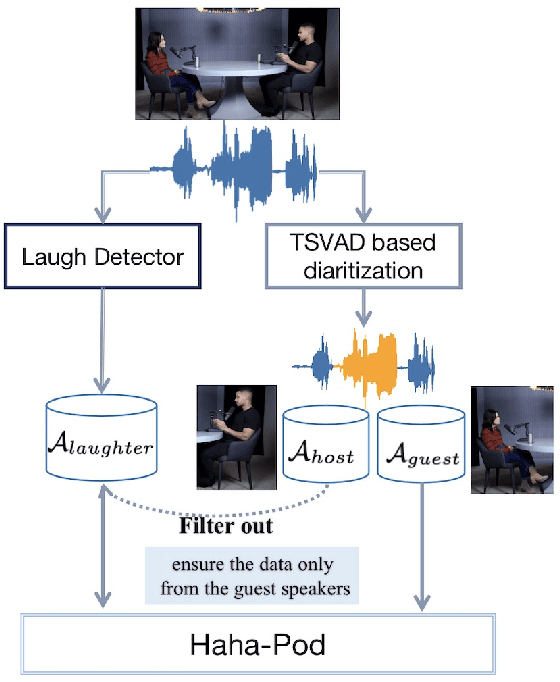
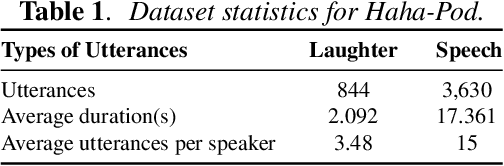
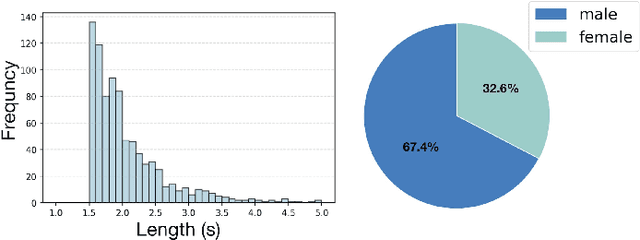
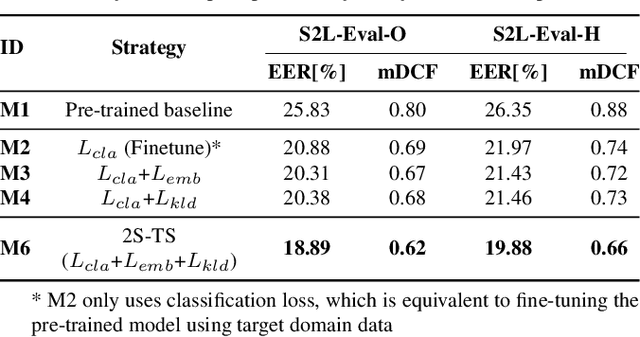
It is widely acknowledged that discriminative representation for speaker verification can be extracted from verbal speech. However, how much speaker information that non-verbal vocalization carries is still a puzzle. This paper explores speaker verification based on the most ubiquitous form of non-verbal voice, laughter. First, we use a semi-automatic pipeline to collect a new Haha-Pod dataset from open-source podcast media. The dataset contains over 240 speakers' laughter clips with corresponding high-quality verbal speech. Second, we propose a Two-Stage Teacher-Student (2S-TS) framework to minimize the within-speaker embedding distance between verbal and non-verbal (laughter) signals. Considering Haha-Pod as a test set, two trials (S2L-Eval) are designed to verify the speaker's identity through laugh sounds. Experimental results demonstrate that our method can significantly improve the performance of the S2L-Eval test set with only a minor degradation on the VoxCeleb1 test set. The Haha-Pod dataset is open to access on https://drive.google.com/file/d/1J-HBRTsm_yWrcbkXupy-tiWRt5gE2LzG/view?usp=drive_link.
VoiceLens: Controllable Speaker Generation and Editing with Flow
Sep 25, 2023Currently, many multi-speaker speech synthesis and voice conversion systems address speaker variations with an embedding vector. Modeling it directly allows new voices outside of training data to be synthesized. GMM based approaches such as Tacospawn are favored in literature for this generation task, but there are still some limitations when difficult conditionings are involved. In this paper, we propose VoiceLens, a semi-supervised flow-based approach, to model speaker embedding distributions for multi-conditional speaker generation. VoiceLens maps speaker embeddings into a combination of independent attributes and residual information. It allows new voices associated with certain attributes to be \textit{generated} for existing TTS models, and attributes of known voices to be meaningfully \textit{edited}. We show in this paper, VoiceLens displays an unconditional generation capacity that is similar to Tacospawn while obtaining higher controllability and flexibility when used in a conditional manner. In addition, we show synthesizing less noisy speech from known noisy speakers without re-training the TTS model is possible via solely editing their embeddings with a SNR conditioned VoiceLens model. Demos are available at sos1sos2sixteen.github.io/voicelens.
Using Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
Text Injection for Capitalization and Turn-Taking Prediction in Speech Models
Aug 14, 2023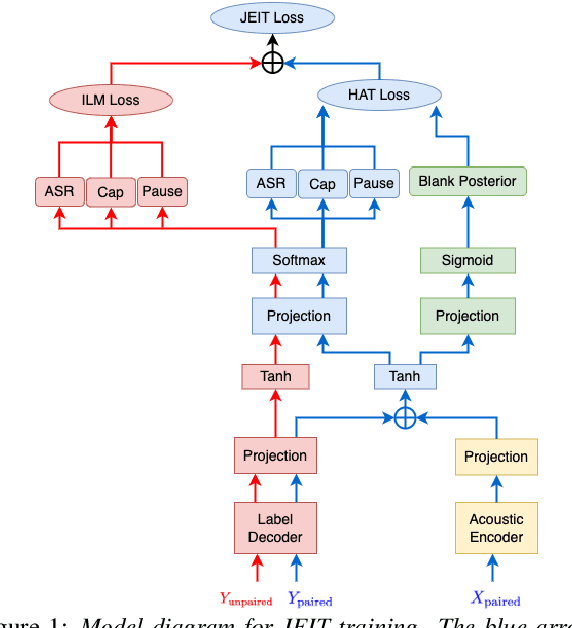
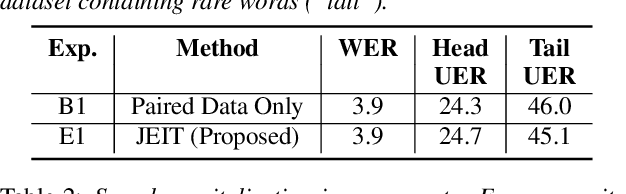

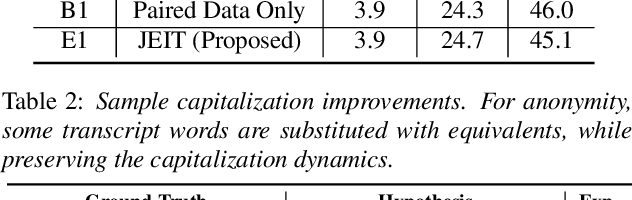
Text injection for automatic speech recognition (ASR), wherein unpaired text-only data is used to supplement paired audio-text data, has shown promising improvements for word error rate. This study examines the use of text injection for auxiliary tasks, which are the non-ASR tasks often performed by an E2E model. In this work, we use joint end-to-end and internal language model training (JEIT) as our text injection algorithm to train an ASR model which performs two auxiliary tasks. The first is capitalization, which is a de-normalization task. The second is turn-taking prediction, which attempts to identify whether a user has completed their conversation turn in a digital assistant interaction. We show results demonstrating that our text injection method boosts capitalization performance for long-tail data, and improves turn-taking detection recall.
Leveraging Large Language Models for Exploiting ASR Uncertainty
Sep 12, 2023
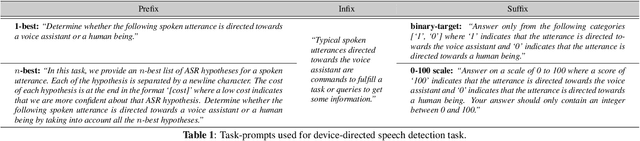

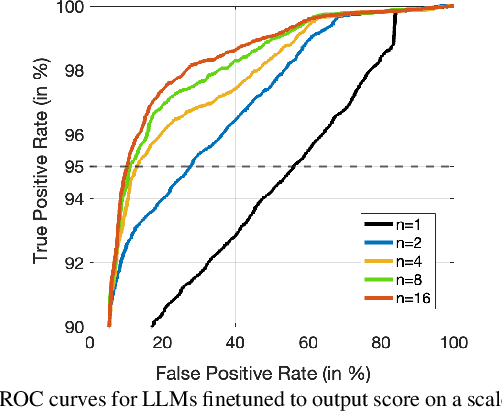
While large language models excel in a variety of natural language processing (NLP) tasks, to perform well on spoken language understanding (SLU) tasks, they must either rely on off-the-shelf automatic speech recognition (ASR) systems for transcription, or be equipped with an in-built speech modality. This work focuses on the former scenario, where LLM's accuracy on SLU tasks is constrained by the accuracy of a fixed ASR system on the spoken input. Specifically, we tackle speech-intent classification task, where a high word-error-rate can limit the LLM's ability to understand the spoken intent. Instead of chasing a high accuracy by designing complex or specialized architectures regardless of deployment costs, we seek to answer how far we can go without substantially changing the underlying ASR and LLM, which can potentially be shared by multiple unrelated tasks. To this end, we propose prompting the LLM with an n-best list of ASR hypotheses instead of only the error-prone 1-best hypothesis. We explore prompt-engineering to explain the concept of n-best lists to the LLM; followed by the finetuning of Low-Rank Adapters on the downstream tasks. Our approach using n-best lists proves to be effective on a device-directed speech detection task as well as on a keyword spotting task, where systems using n-best list prompts outperform those using 1-best ASR hypothesis; thus paving the way for an efficient method to exploit ASR uncertainty via LLMs for speech-based applications.
PCNN: A Lightweight Parallel Conformer Neural Network for Efficient Monaural Speech Enhancement
Jul 28, 2023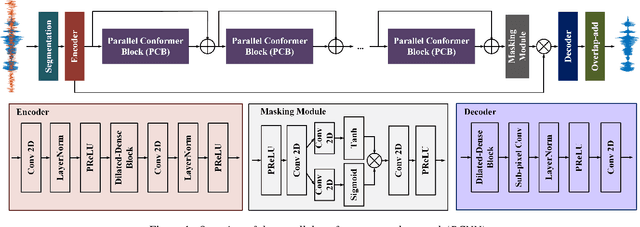
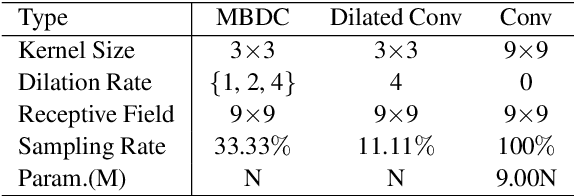
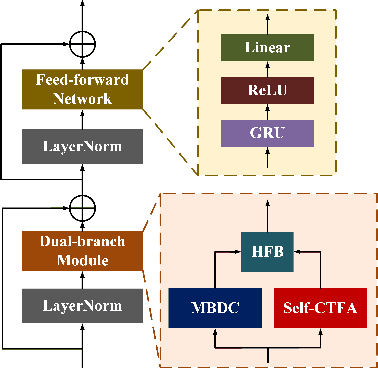
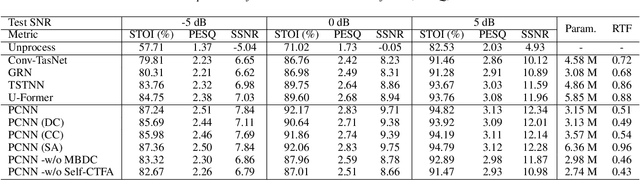
Convolutional neural networks (CNN) and Transformer have wildly succeeded in multimedia applications. However, more effort needs to be made to harmonize these two architectures effectively to satisfy speech enhancement. This paper aims to unify these two architectures and presents a Parallel Conformer for speech enhancement. In particular, the CNN and the self-attention (SA) in the Transformer are fully exploited for local format patterns and global structure representations. Based on the small receptive field size of CNN and the high computational complexity of SA, we specially designed a multi-branch dilated convolution (MBDC) and a self-channel-time-frequency attention (Self-CTFA) module. MBDC contains three convolutional layers with different dilation rates for the feature from local to non-local processing. Experimental results show that our method performs better than state-of-the-art methods in most evaluation criteria while maintaining the lowest model parameters.
Robust Hate Speech Detection in Social Media: A Cross-Dataset Empirical Evaluation
Jul 04, 2023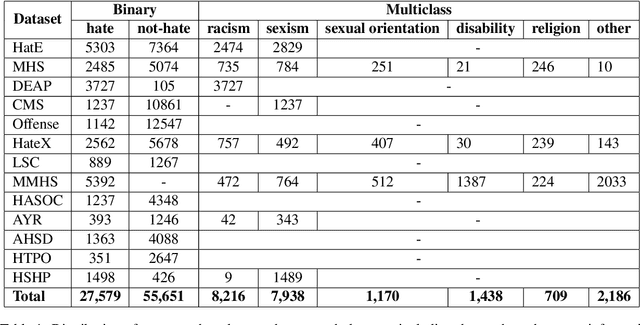
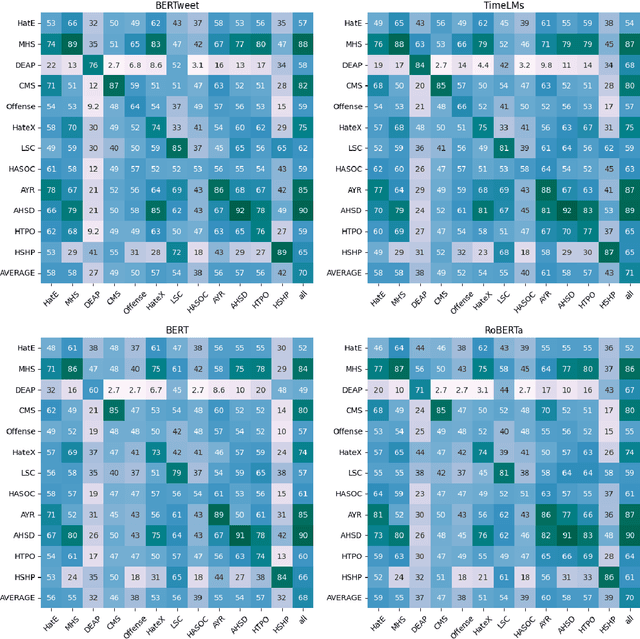
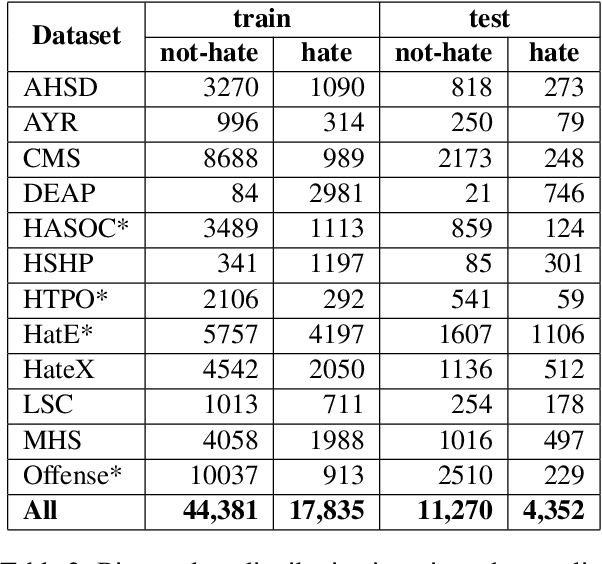
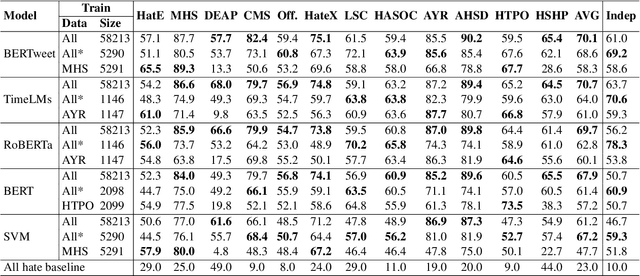
The automatic detection of hate speech online is an active research area in NLP. Most of the studies to date are based on social media datasets that contribute to the creation of hate speech detection models trained on them. However, data creation processes contain their own biases, and models inherently learn from these dataset-specific biases. In this paper, we perform a large-scale cross-dataset comparison where we fine-tune language models on different hate speech detection datasets. This analysis shows how some datasets are more generalisable than others when used as training data. Crucially, our experiments show how combining hate speech detection datasets can contribute to the development of robust hate speech detection models. This robustness holds even when controlling by data size and compared with the best individual datasets.
Massive End-to-end Models for Short Search Queries
Sep 22, 2023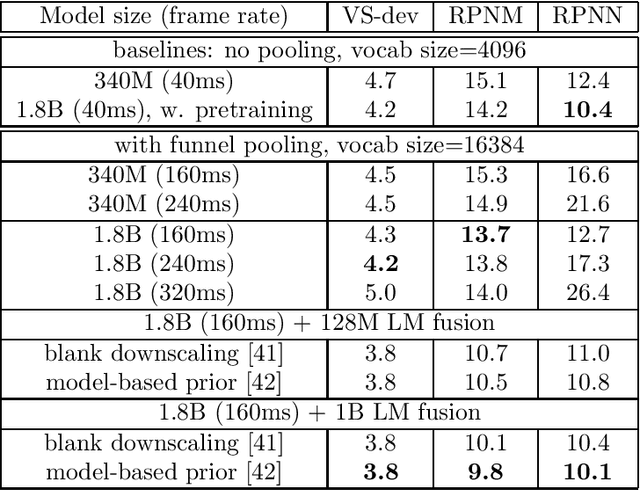
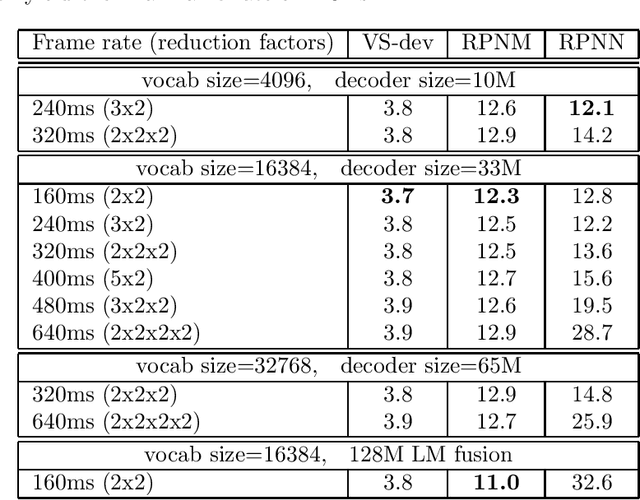
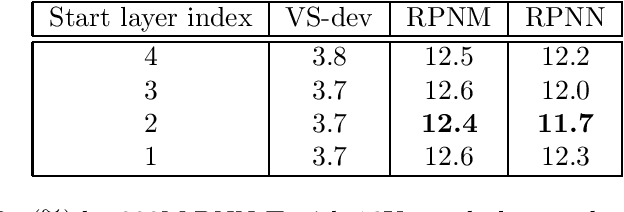
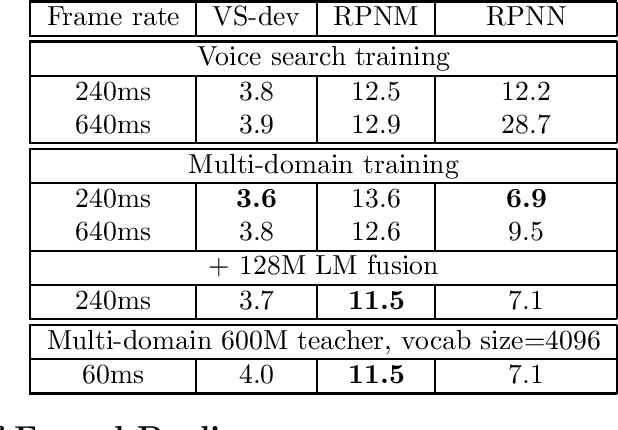
In this work, we investigate two popular end-to-end automatic speech recognition (ASR) models, namely Connectionist Temporal Classification (CTC) and RNN-Transducer (RNN-T), for offline recognition of voice search queries, with up to 2B model parameters. The encoders of our models use the neural architecture of Google's universal speech model (USM), with additional funnel pooling layers to significantly reduce the frame rate and speed up training and inference. We perform extensive studies on vocabulary size, time reduction strategy, and its generalization performance on long-form test sets. Despite the speculation that, as the model size increases, CTC can be as good as RNN-T which builds label dependency into the prediction, we observe that a 900M RNN-T clearly outperforms a 1.8B CTC and is more tolerant to severe time reduction, although the WER gap can be largely removed by LM shallow fusion.
Attentive Multi-Layer Perceptron for Non-autoregressive Generation
Oct 14, 2023Autoregressive~(AR) generation almost dominates sequence generation for its efficacy. Recently, non-autoregressive~(NAR) generation gains increasing popularity for its efficiency and growing efficacy. However, its efficiency is still bottlenecked by quadratic complexity in sequence lengths, which is prohibitive for scaling to long sequence generation and few works have been done to mitigate this problem. In this paper, we propose a novel MLP variant, \textbf{A}ttentive \textbf{M}ulti-\textbf{L}ayer \textbf{P}erceptron~(AMLP), to produce a generation model with linear time and space complexity. Different from classic MLP with static and learnable projection matrices, AMLP leverages adaptive projections computed from inputs in an attentive mode. The sample-aware adaptive projections enable communications among tokens in a sequence, and model the measurement between the query and key space. Furthermore, we marry AMLP with popular NAR models, deriving a highly efficient NAR-AMLP architecture with linear time and space complexity. Empirical results show that such marriage architecture surpasses competitive efficient NAR models, by a significant margin on text-to-speech synthesis and machine translation. We also test AMLP's self- and cross-attention ability separately with extensive ablation experiments, and find them comparable or even superior to the other efficient models. The efficiency analysis further shows that AMLP extremely reduces the memory cost against vanilla non-autoregressive models for long sequences.