 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Empowering Psychotherapy with Large Language Models: Cognitive Distortion Detection through Diagnosis of Thought Prompting
Oct 11, 2023

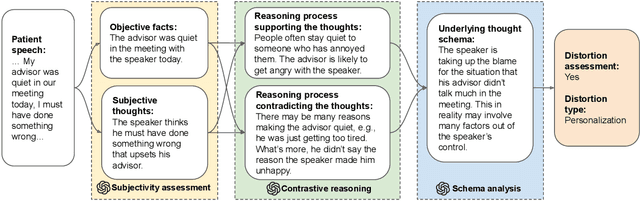
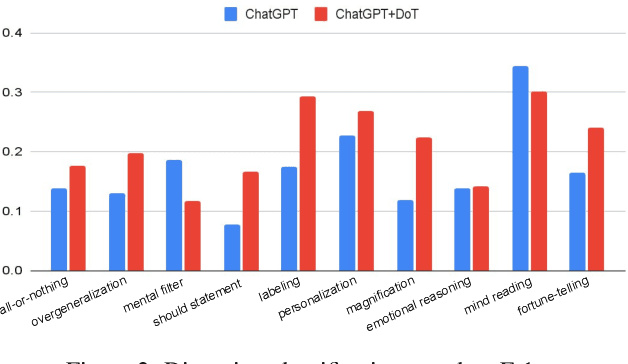
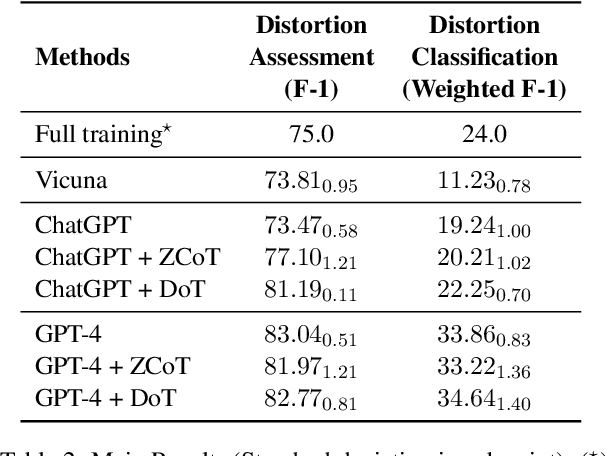
Mental illness remains one of the most critical public health issues of our time, due to the severe scarcity and accessibility limit of professionals. Psychotherapy requires high-level expertise to conduct deep, complex reasoning and analysis on the cognition modeling of the patients. In the era of Large Language Models, we believe it is the right time to develop AI assistance for computational psychotherapy. We study the task of cognitive distortion detection and propose the Diagnosis of Thought (DoT) prompting. DoT performs diagnosis on the patient's speech via three stages: subjectivity assessment to separate the facts and the thoughts; contrastive reasoning to elicit the reasoning processes supporting and contradicting the thoughts; and schema analysis to summarize the cognition schemas. The generated diagnosis rationales through the three stages are essential for assisting the professionals. Experiments demonstrate that DoT obtains significant improvements over ChatGPT for cognitive distortion detection, while generating high-quality rationales approved by human experts.
Learning Multilingual Expressive Speech Representation for Prosody Prediction without Parallel Data
Jun 29, 2023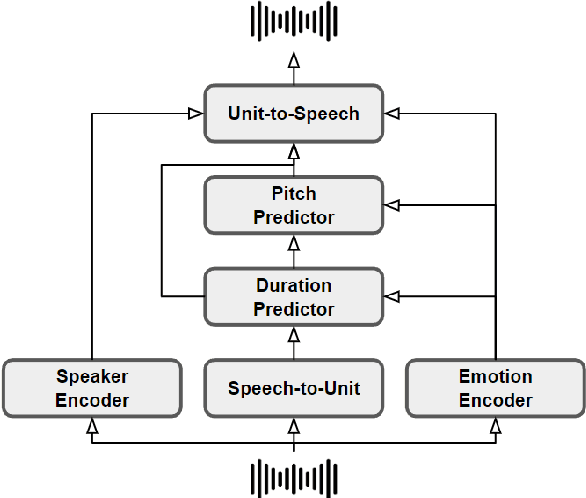
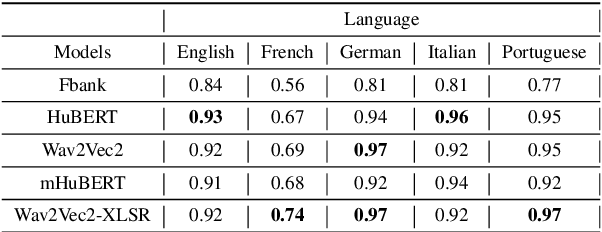
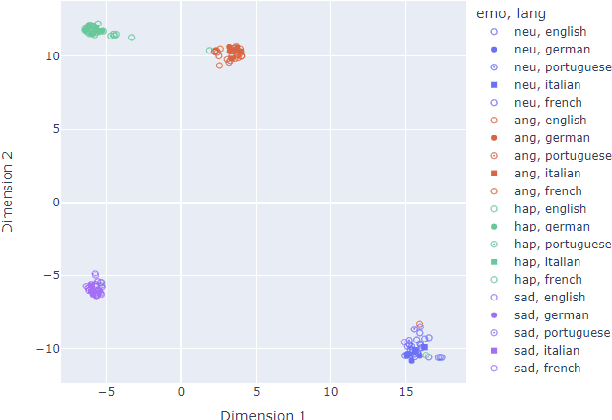
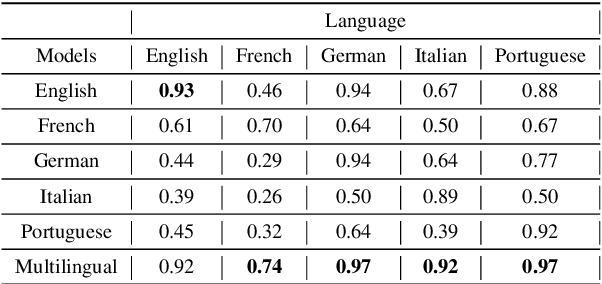
We propose a method for speech-to-speech emotionpreserving translation that operates at the level of discrete speech units. Our approach relies on the use of multilingual emotion embedding that can capture affective information in a language-independent manner. We show that this embedding can be used to predict the pitch and duration of speech units in a target language, allowing us to resynthesize the source speech signal with the same emotional content. We evaluate our approach to English and French speech signals and show that it outperforms a baseline method that does not use emotional information, including when the emotion embedding is extracted from a different language. Even if this preliminary study does not address directly the machine translation issue, our results demonstrate the effectiveness of our approach for cross-lingual emotion preservation in the context of speech resynthesis.
Unsupervised speech enhancement with deep dynamical generative speech and noise models
Jun 13, 2023
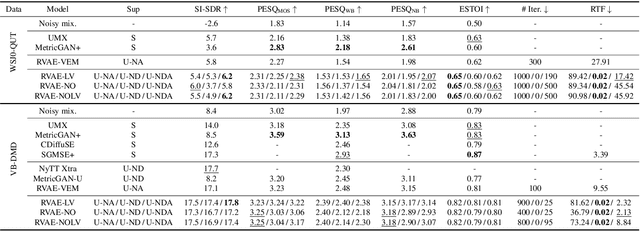
This work builds on a previous work on unsupervised speech enhancement using a dynamical variational autoencoder (DVAE) as the clean speech model and non-negative matrix factorization (NMF) as the noise model. We propose to replace the NMF noise model with a deep dynamical generative model (DDGM) depending either on the DVAE latent variables, or on the noisy observations, or on both. This DDGM can be trained in three configurations: noise-agnostic, noise-dependent and noise adaptation after noise-dependent training. Experimental results show that the proposed method achieves competitive performance compared to state-of-the-art unsupervised speech enhancement methods, while the noise-dependent training configuration yields a much more time-efficient inference process.
ed-cec: improving rare word recognition using asr postprocessing based on error detection and context-aware error correction
Oct 08, 2023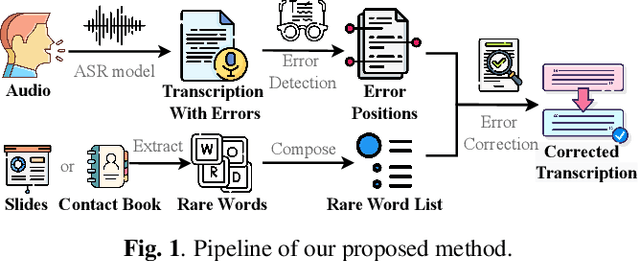
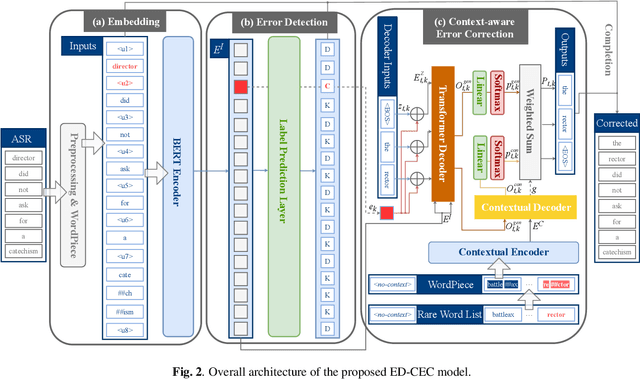
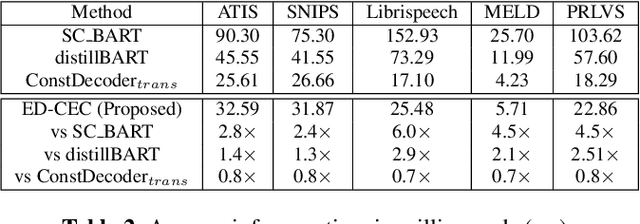
Automatic speech recognition (ASR) systems often encounter difficulties in accurately recognizing rare words, leading to errors that can have a negative impact on downstream tasks such as keyword spotting, intent detection, and text summarization. To address this challenge, we present a novel ASR postprocessing method that focuses on improving the recognition of rare words through error detection and context-aware error correction. Our method optimizes the decoding process by targeting only the predicted error positions, minimizing unnecessary computations. Moreover, we leverage a rare word list to provide additional contextual knowledge, enabling the model to better correct rare words. Experimental results across five datasets demonstrate that our proposed method achieves significantly lower word error rates (WERs) than previous approaches while maintaining a reasonable inference speed. Furthermore, our approach exhibits promising robustness across different ASR systems.
End-to-End Lip Reading in Romanian with Cross-Lingual Domain Adaptation and Lateral Inhibition
Oct 07, 2023Lip reading or visual speech recognition has gained significant attention in recent years, particularly because of hardware development and innovations in computer vision. While considerable progress has been obtained, most models have only been tested on a few large-scale datasets. This work addresses this shortcoming by analyzing several architectures and optimizations on the underrepresented, short-scale Romanian language dataset called Wild LRRo. Most notably, we compare different backend modules, demonstrating the effectiveness of adding ample regularization methods. We obtain state-of-the-art results using our proposed method, namely cross-lingual domain adaptation and unlabeled videos from English and German datasets to help the model learn language-invariant features. Lastly, we assess the performance of adding a layer inspired by the neural inhibition mechanism.
Robust Automatic Speech Recognition via WavAugment Guided Phoneme Adversarial Training
Jul 24, 2023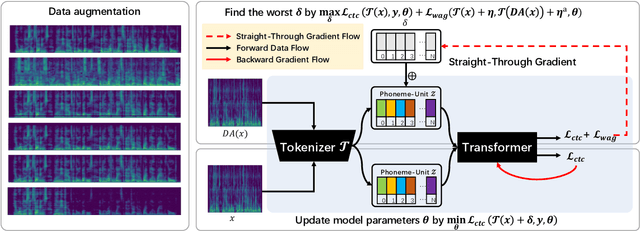
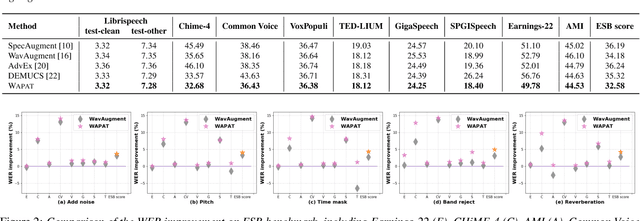
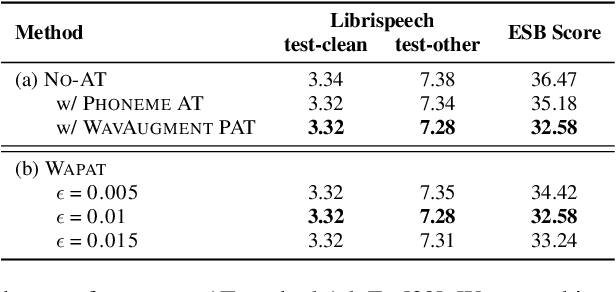
Developing a practically-robust automatic speech recognition (ASR) is challenging since the model should not only maintain the original performance on clean samples, but also achieve consistent efficacy under small volume perturbations and large domain shifts. To address this problem, we propose a novel WavAugment Guided Phoneme Adversarial Training (wapat). wapat use adversarial examples in phoneme space as augmentation to make the model invariant to minor fluctuations in phoneme representation and preserve the performance on clean samples. In addition, wapat utilizes the phoneme representation of augmented samples to guide the generation of adversaries, which helps to find more stable and diverse gradient-directions, resulting in improved generalization. Extensive experiments demonstrate the effectiveness of wapat on End-to-end Speech Challenge Benchmark (ESB). Notably, SpeechLM-wapat outperforms the original model by 6.28% WER reduction on ESB, achieving the new state-of-the-art.
Improving speech translation by fusing speech and text
May 23, 2023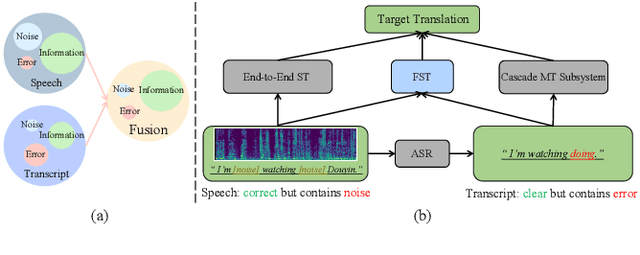
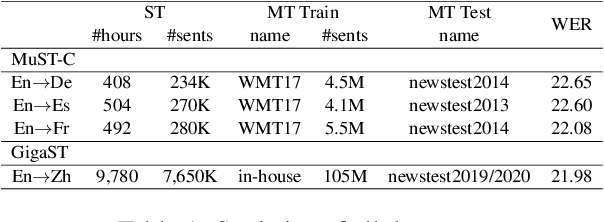
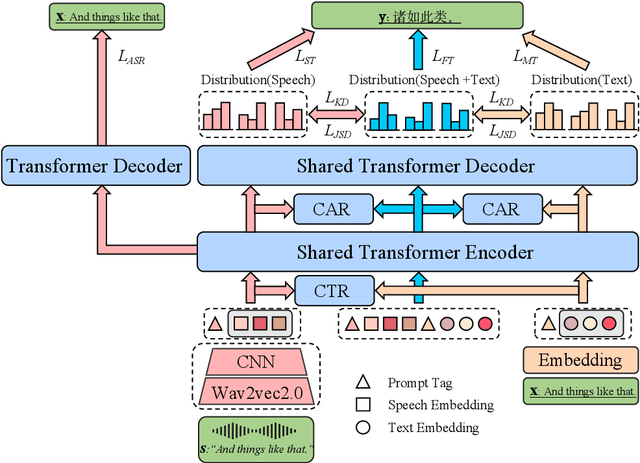
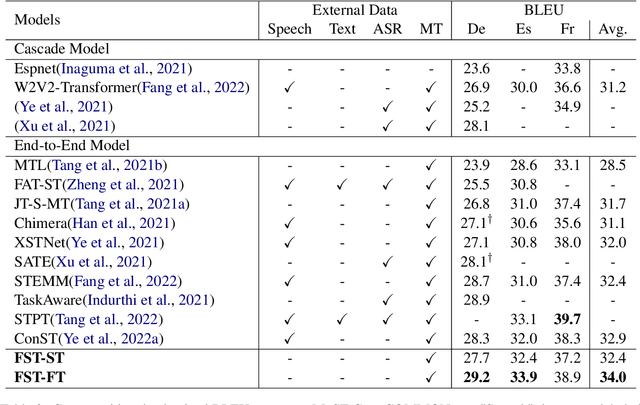
In speech translation, leveraging multimodal data to improve model performance and address limitations of individual modalities has shown significant effectiveness. In this paper, we harness the complementary strengths of speech and text, which are disparate modalities. We observe three levels of modality gap between them, denoted by Modal input representation, Modal semantic, and Modal hidden states. To tackle these gaps, we propose \textbf{F}use-\textbf{S}peech-\textbf{T}ext (\textbf{FST}), a cross-modal model which supports three distinct input modalities for translation: speech, text, and fused speech-text. We leverage multiple techniques for cross-modal alignment and conduct a comprehensive analysis to assess its impact on speech translation, machine translation, and fused speech-text translation. We evaluate FST on MuST-C, GigaST, and newstest benchmark. Experiments show that the proposed FST achieves an average 34.0 BLEU on MuST-C En$\rightarrow$De/Es/Fr (vs SOTA +1.1 BLEU). Further experiments demonstrate that FST does not degrade on MT task, as observed in prior works. Instead, it yields an average improvement of 3.2 BLEU over the pre-trained MT model.
Speech representation learning: Learning bidirectional encoders with single-view, multi-view, and multi-task methods
Jul 25, 2023This thesis focuses on representation learning for sequence data over time or space, aiming to improve downstream sequence prediction tasks by using the learned representations. Supervised learning has been the most dominant approach for training deep neural networks for learning good sequential representations. However, one limiting factor to scale supervised learning is the lack of enough annotated data. Motivated by this challenge, it is natural to explore representation learning methods that can utilize large amounts of unlabeled and weakly labeled data, as well as an additional data modality. I describe my broad study of representation learning for speech data. Unlike most other works that focus on a single learning setting, this thesis studies multiple settings: supervised learning with auxiliary losses, unsupervised learning, semi-supervised learning, and multi-view learning. Besides different learning problems, I also explore multiple approaches for representation learning. Though I focus on speech data, the methods described in this thesis can also be applied to other domains. Overall, the field of representation learning is developing rapidly. State-of-the-art results on speech related tasks are typically based on Transformers pre-trained with large-scale self-supervised learning, which aims to learn generic representations that can benefit multiple downstream tasks. Since 2020, large-scale pre-training has been the de facto choice to achieve good performance. This delayed thesis does not attempt to summarize and compare with the latest results on speech representation learning; instead, it presents a unique study on speech representation learning before the Transformer era, that covers multiple learning settings. Some of the findings in this thesis can still be useful today.
Mitigating Bias in Conversations: A Hate Speech Classifier and Debiaser with Prompts
Jul 14, 2023Discriminatory language and biases are often present in hate speech during conversations, which usually lead to negative impacts on targeted groups such as those based on race, gender, and religion. To tackle this issue, we propose an approach that involves a two-step process: first, detecting hate speech using a classifier, and then utilizing a debiasing component that generates less biased or unbiased alternatives through prompts. We evaluated our approach on a benchmark dataset and observed reduction in negativity due to hate speech comments. The proposed method contributes to the ongoing efforts to reduce biases in online discourse and promote a more inclusive and fair environment for communication.
Improving Voice Conversion for Dissimilar Speakers Using Perceptual Losses
Sep 15, 2023The rising trend of using voice as a means of interacting with smart devices has sparked worries over the protection of users' privacy and data security. These concerns have become more pressing, especially after the European Union's adoption of the General Data Protection Regulation (GDPR). The information contained in an utterance encompasses critical personal details about the speaker, such as their age, gender, socio-cultural origins and more. If there is a security breach and the data is compromised, attackers may utilise the speech data to circumvent the speaker verification systems or imitate authorised users. Therefore, it is pertinent to anonymise the speech data before being shared across devices, such that the source speaker of the utterance cannot be traced. Voice conversion (VC) can be used to achieve speech anonymisation, which involves altering the speaker's characteristics while preserving the linguistic content.