 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MSM-VC: High-fidelity Source Style Transfer for Non-Parallel Voice Conversion by Multi-scale Style Modeling
Sep 03, 2023
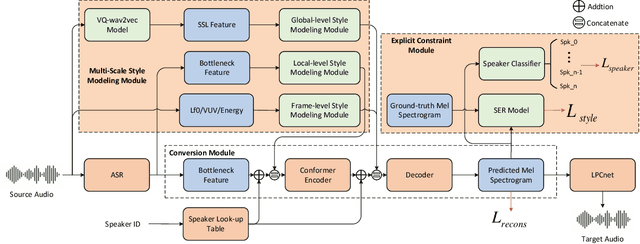
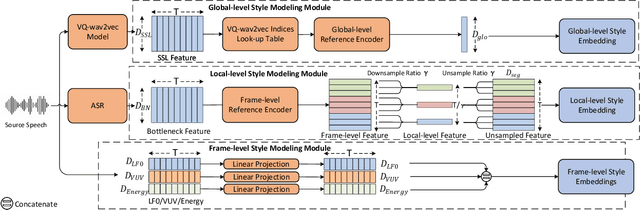
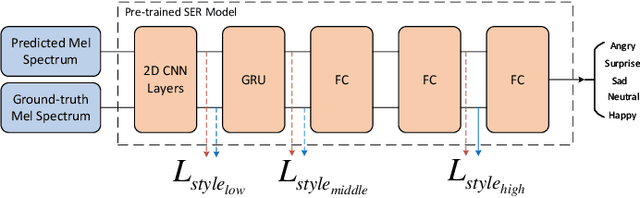
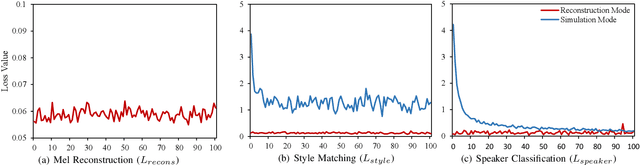
In addition to conveying the linguistic content from source speech to converted speech, maintaining the speaking style of source speech also plays an important role in the voice conversion (VC) task, which is essential in many scenarios with highly expressive source speech, such as dubbing and data augmentation. Previous work generally took explicit prosodic features or fixed-length style embedding extracted from source speech to model the speaking style of source speech, which is insufficient to achieve comprehensive style modeling and target speaker timbre preservation. Inspired by the style's multi-scale nature of human speech, a multi-scale style modeling method for the VC task, referred to as MSM-VC, is proposed in this paper. MSM-VC models the speaking style of source speech from different levels. To effectively convey the speaking style and meanwhile prevent timbre leakage from source speech to converted speech, each level's style is modeled by specific representation. Specifically, prosodic features, pre-trained ASR model's bottleneck features, and features extracted by a model trained with a self-supervised strategy are adopted to model the frame, local, and global-level styles, respectively. Besides, to balance the performance of source style modeling and target speaker timbre preservation, an explicit constraint module consisting of a pre-trained speech emotion recognition model and a speaker classifier is introduced to MSM-VC. This explicit constraint module also makes it possible to simulate the style transfer inference process during the training to improve the disentanglement ability and alleviate the mismatch between training and inference. Experiments performed on the highly expressive speech corpus demonstrate that MSM-VC is superior to the state-of-the-art VC methods for modeling source speech style while maintaining good speech quality and speaker similarity.
All-for-One and One-For-All: Deep learning-based feature fusion for Synthetic Speech Detection
Jul 28, 2023Recent advances in deep learning and computer vision have made the synthesis and counterfeiting of multimedia content more accessible than ever, leading to possible threats and dangers from malicious users. In the audio field, we are witnessing the growth of speech deepfake generation techniques, which solicit the development of synthetic speech detection algorithms to counter possible mischievous uses such as frauds or identity thefts. In this paper, we consider three different feature sets proposed in the literature for the synthetic speech detection task and present a model that fuses them, achieving overall better performances with respect to the state-of-the-art solutions. The system was tested on different scenarios and datasets to prove its robustness to anti-forensic attacks and its generalization capabilities.
Capturing Spectral and Long-term Contextual Information for Speech Emotion Recognition Using Deep Learning Techniques
Aug 04, 2023
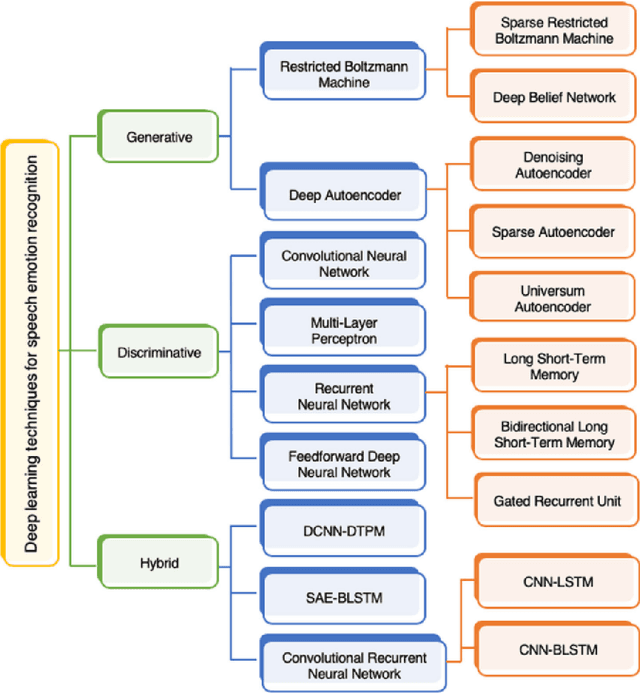
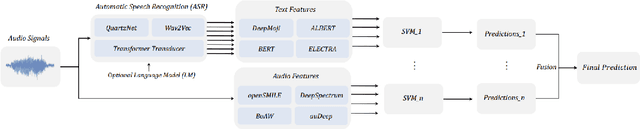
Traditional approaches in speech emotion recognition, such as LSTM, CNN, RNN, SVM, and MLP, have limitations such as difficulty capturing long-term dependencies in sequential data, capturing the temporal dynamics, and struggling to capture complex patterns and relationships in multimodal data. This research addresses these shortcomings by proposing an ensemble model that combines Graph Convolutional Networks (GCN) for processing textual data and the HuBERT transformer for analyzing audio signals. We found that GCNs excel at capturing Long-term contextual dependencies and relationships within textual data by leveraging graph-based representations of text and thus detecting the contextual meaning and semantic relationships between words. On the other hand, HuBERT utilizes self-attention mechanisms to capture long-range dependencies, enabling the modeling of temporal dynamics present in speech and capturing subtle nuances and variations that contribute to emotion recognition. By combining GCN and HuBERT, our ensemble model can leverage the strengths of both approaches. This allows for the simultaneous analysis of multimodal data, and the fusion of these modalities enables the extraction of complementary information, enhancing the discriminative power of the emotion recognition system. The results indicate that the combined model can overcome the limitations of traditional methods, leading to enhanced accuracy in recognizing emotions from speech.
RobustL2S: Speaker-Specific Lip-to-Speech Synthesis exploiting Self-Supervised Representations
Jul 03, 2023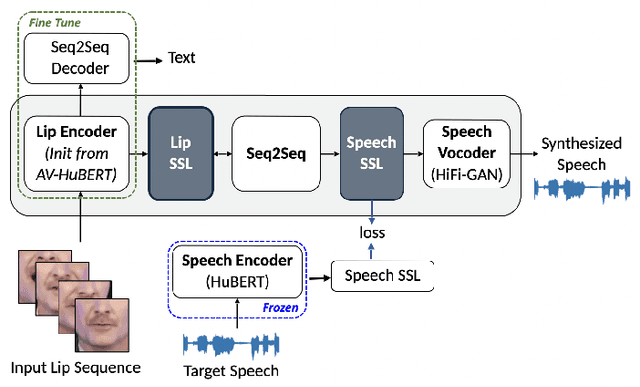
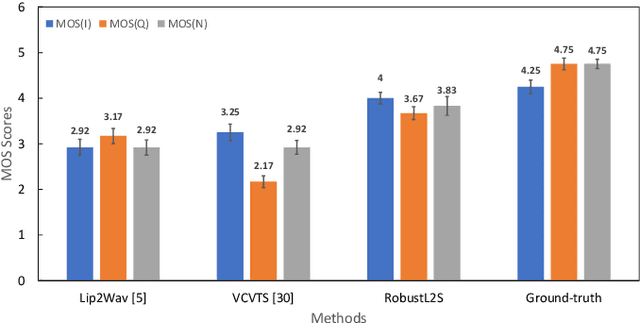
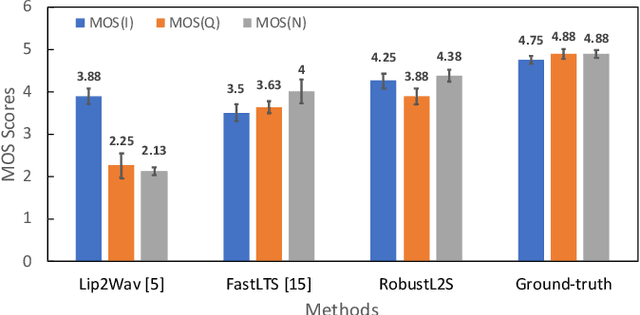
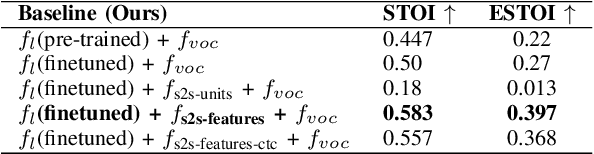
Significant progress has been made in speaker dependent Lip-to-Speech synthesis, which aims to generate speech from silent videos of talking faces. Current state-of-the-art approaches primarily employ non-autoregressive sequence-to-sequence architectures to directly predict mel-spectrograms or audio waveforms from lip representations. We hypothesize that the direct mel-prediction hampers training/model efficiency due to the entanglement of speech content with ambient information and speaker characteristics. To this end, we propose RobustL2S, a modularized framework for Lip-to-Speech synthesis. First, a non-autoregressive sequence-to-sequence model maps self-supervised visual features to a representation of disentangled speech content. A vocoder then converts the speech features into raw waveforms. Extensive evaluations confirm the effectiveness of our setup, achieving state-of-the-art performance on the unconstrained Lip2Wav dataset and the constrained GRID and TCD-TIMIT datasets. Speech samples from RobustL2S can be found at https://neha-sherin.github.io/RobustL2S/
SeqXGPT: Sentence-Level AI-Generated Text Detection
Oct 13, 2023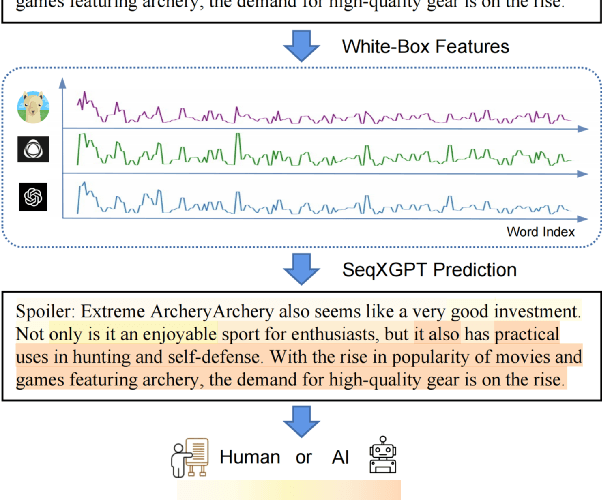
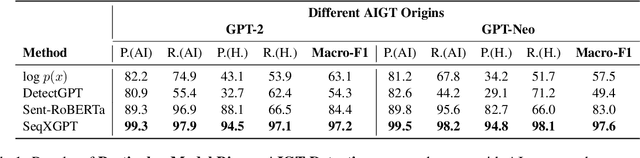
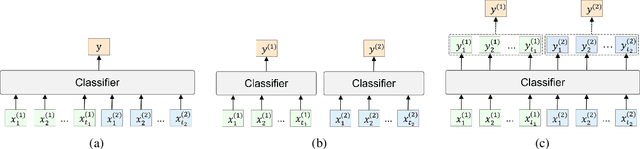
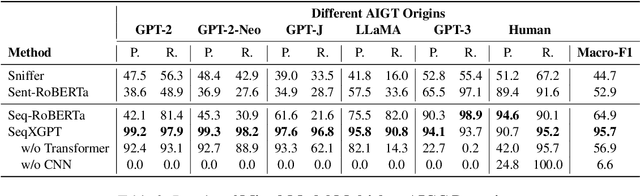
Widely applied large language models (LLMs) can generate human-like content, raising concerns about the abuse of LLMs. Therefore, it is important to build strong AI-generated text (AIGT) detectors. Current works only consider document-level AIGT detection, therefore, in this paper, we first introduce a sentence-level detection challenge by synthesizing a dataset that contains documents that are polished with LLMs, that is, the documents contain sentences written by humans and sentences modified by LLMs. Then we propose \textbf{Seq}uence \textbf{X} (Check) \textbf{GPT}, a novel method that utilizes log probability lists from white-box LLMs as features for sentence-level AIGT detection. These features are composed like \textit{waves} in speech processing and cannot be studied by LLMs. Therefore, we build SeqXGPT based on convolution and self-attention networks. We test it in both sentence and document-level detection challenges. Experimental results show that previous methods struggle in solving sentence-level AIGT detection, while our method not only significantly surpasses baseline methods in both sentence and document-level detection challenges but also exhibits strong generalization capabilities.
Spiking-LEAF: A Learnable Auditory front-end for Spiking Neural Networks
Sep 18, 2023Brain-inspired spiking neural networks (SNNs) have demonstrated great potential for temporal signal processing. However, their performance in speech processing remains limited due to the lack of an effective auditory front-end. To address this limitation, we introduce Spiking-LEAF, a learnable auditory front-end meticulously designed for SNN-based speech processing. Spiking-LEAF combines a learnable filter bank with a novel two-compartment spiking neuron model called IHC-LIF. The IHC-LIF neurons draw inspiration from the structure of inner hair cells (IHC) and they leverage segregated dendritic and somatic compartments to effectively capture multi-scale temporal dynamics of speech signals. Additionally, the IHC-LIF neurons incorporate the lateral feedback mechanism along with spike regularization loss to enhance spike encoding efficiency. On keyword spotting and speaker identification tasks, the proposed Spiking-LEAF outperforms both SOTA spiking auditory front-ends and conventional real-valued acoustic features in terms of classification accuracy, noise robustness, and encoding efficiency.
Topic Identification For Spontaneous Speech: Enriching Audio Features With Embedded Linguistic Information
Jul 21, 2023Traditional topic identification solutions from audio rely on an automatic speech recognition system (ASR) to produce transcripts used as input to a text-based model. These approaches work well in high-resource scenarios, where there are sufficient data to train both components of the pipeline. However, in low-resource situations, the ASR system, even if available, produces low-quality transcripts, leading to a bad text-based classifier. Moreover, spontaneous speech containing hesitations can further degrade the performance of the ASR model. In this paper, we investigate alternatives to the standard text-only solutions by comparing audio-only and hybrid techniques of jointly utilising text and audio features. The models evaluated on spontaneous Finnish speech demonstrate that purely audio-based solutions are a viable option when ASR components are not available, while the hybrid multi-modal solutions achieve the best results.
PromptTTS 2: Describing and Generating Voices with Text Prompt
Sep 05, 2023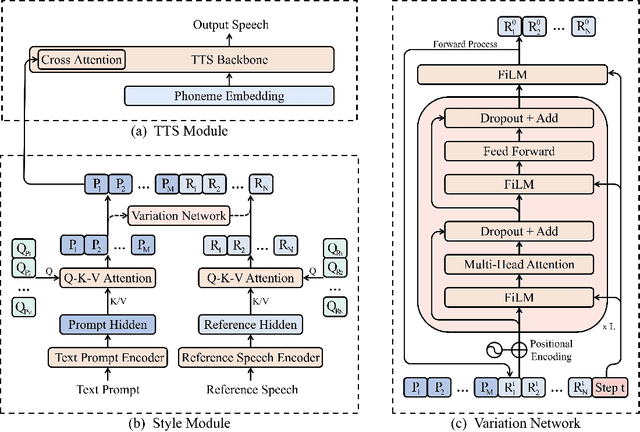

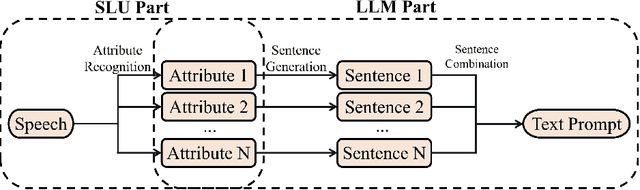
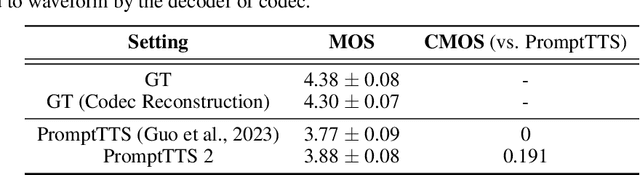
Speech conveys more information than just text, as the same word can be uttered in various voices to convey diverse information. Compared to traditional text-to-speech (TTS) methods relying on speech prompts (reference speech) for voice variability, using text prompts (descriptions) is more user-friendly since speech prompts can be hard to find or may not exist at all. TTS approaches based on the text prompt face two challenges: 1) the one-to-many problem, where not all details about voice variability can be described in the text prompt, and 2) the limited availability of text prompt datasets, where vendors and large cost of data labeling are required to write text prompt for speech. In this work, we introduce PromptTTS 2 to address these challenges with a variation network to provide variability information of voice not captured by text prompts, and a prompt generation pipeline to utilize the large language models (LLM) to compose high quality text prompts. Specifically, the variation network predicts the representation extracted from the reference speech (which contains full information about voice) based on the text prompt representation. For the prompt generation pipeline, it generates text prompts for speech with a speech understanding model to recognize voice attributes (e.g., gender, speed) from speech and a large language model to formulate text prompt based on the recognition results. Experiments on a large-scale (44K hours) speech dataset demonstrate that compared to the previous works, PromptTTS 2 generates voices more consistent with text prompts and supports the sampling of diverse voice variability, thereby offering users more choices on voice generation. Additionally, the prompt generation pipeline produces high-quality prompts, eliminating the large labeling cost. The demo page of PromptTTS 2 is available online\footnote{https://speechresearch.github.io/prompttts2}.
UnitSpeech: Speaker-adaptive Speech Synthesis with Untranscribed Data
Jun 28, 2023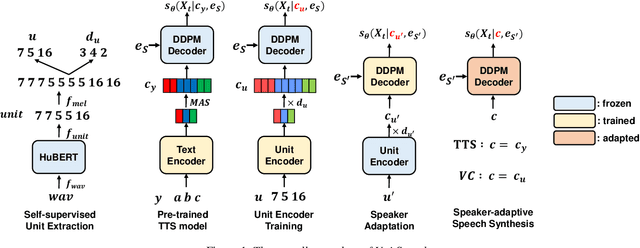
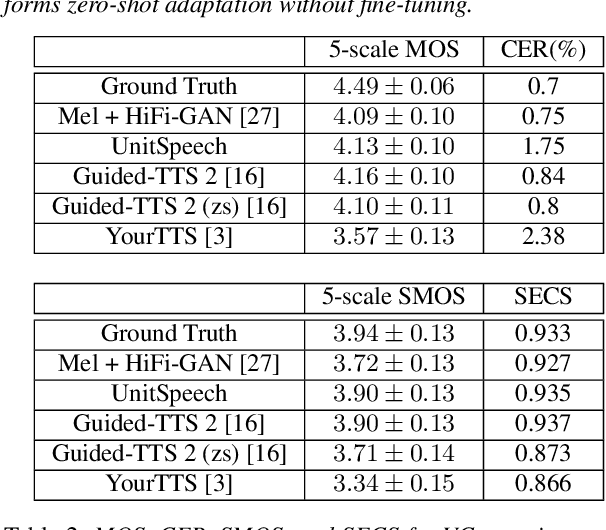
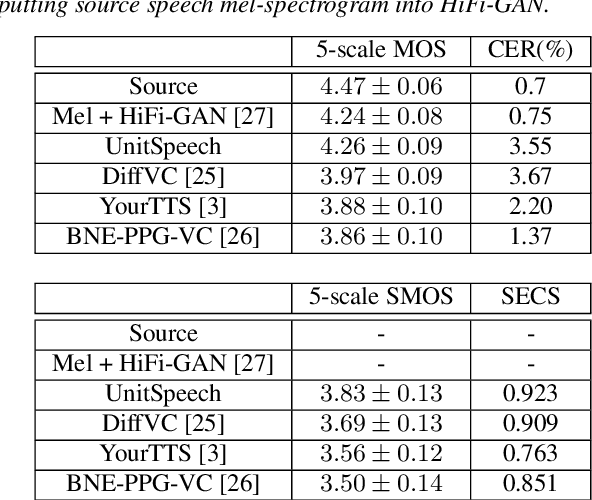
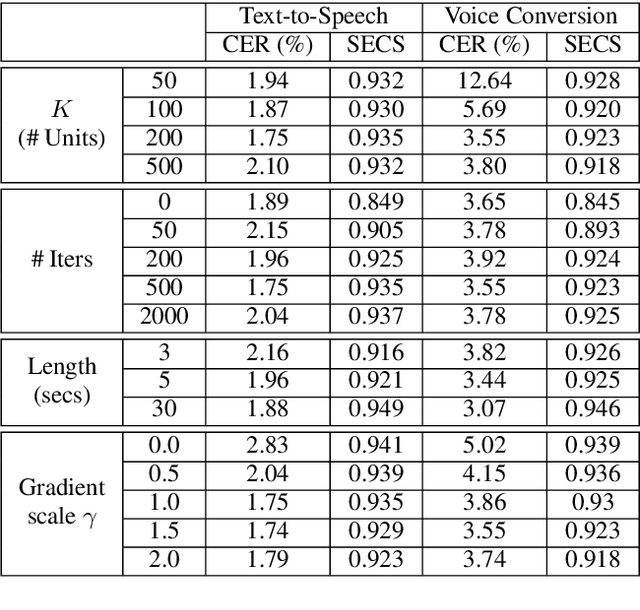
We propose UnitSpeech, a speaker-adaptive speech synthesis method that fine-tunes a diffusion-based text-to-speech (TTS) model using minimal untranscribed data. To achieve this, we use the self-supervised unit representation as a pseudo transcript and integrate the unit encoder into the pre-trained TTS model. We train the unit encoder to provide speech content to the diffusion-based decoder and then fine-tune the decoder for speaker adaptation to the reference speaker using a single $<$unit, speech$>$ pair. UnitSpeech performs speech synthesis tasks such as TTS and voice conversion (VC) in a personalized manner without requiring model re-training for each task. UnitSpeech achieves comparable and superior results on personalized TTS and any-to-any VC tasks compared to previous baselines. Our model also shows widespread adaptive performance on real-world data and other tasks that use a unit sequence as input.
EmoSpeech: Guiding FastSpeech2 Towards Emotional Text to Speech
Jun 28, 2023State-of-the-art speech synthesis models try to get as close as possible to the human voice. Hence, modelling emotions is an essential part of Text-To-Speech (TTS) research. In our work, we selected FastSpeech2 as the starting point and proposed a series of modifications for synthesizing emotional speech. According to automatic and human evaluation, our model, EmoSpeech, surpasses existing models regarding both MOS score and emotion recognition accuracy in generated speech. We provided a detailed ablation study for every extension to FastSpeech2 architecture that forms EmoSpeech. The uneven distribution of emotions in the text is crucial for better, synthesized speech and intonation perception. Our model includes a conditioning mechanism that effectively handles this issue by allowing emotions to contribute to each phone with varying intensity levels. The human assessment indicates that proposed modifications generate audio with higher MOS and emotional expressiveness.