 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ARC-NLP at Multimodal Hate Speech Event Detection 2023: Multimodal Methods Boosted by Ensemble Learning, Syntactical and Entity Features
Jul 25, 2023
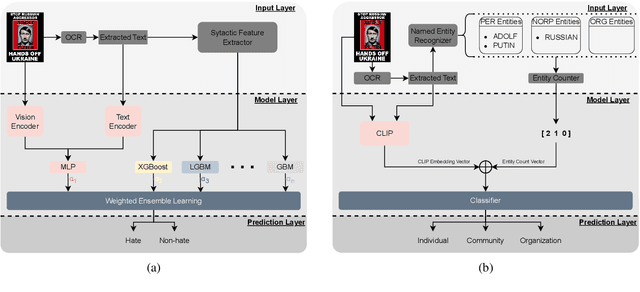

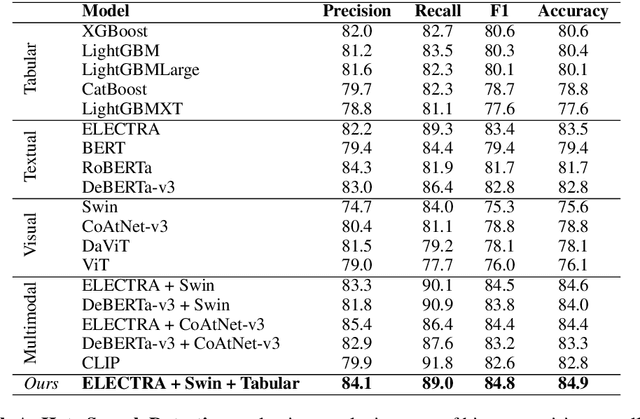
Text-embedded images can serve as a means of spreading hate speech, propaganda, and extremist beliefs. Throughout the Russia-Ukraine war, both opposing factions heavily relied on text-embedded images as a vehicle for spreading propaganda and hate speech. Ensuring the effective detection of hate speech and propaganda is of utmost importance to mitigate the negative effect of hate speech dissemination. In this paper, we outline our methodologies for two subtasks of Multimodal Hate Speech Event Detection 2023. For the first subtask, hate speech detection, we utilize multimodal deep learning models boosted by ensemble learning and syntactical text attributes. For the second subtask, target detection, we employ multimodal deep learning models boosted by named entity features. Through experimentation, we demonstrate the superior performance of our models compared to all textual, visual, and text-visual baselines employed in multimodal hate speech detection. Furthermore, our models achieve the first place in both subtasks on the final leaderboard of the shared task.
An empirical study on speech restoration guided by self supervised speech representation
May 30, 2023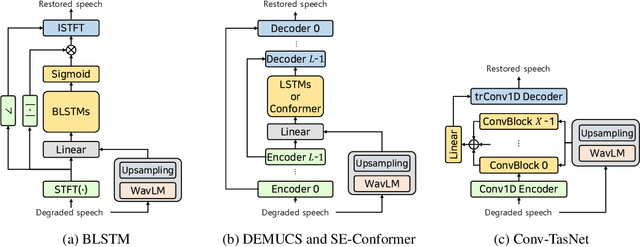
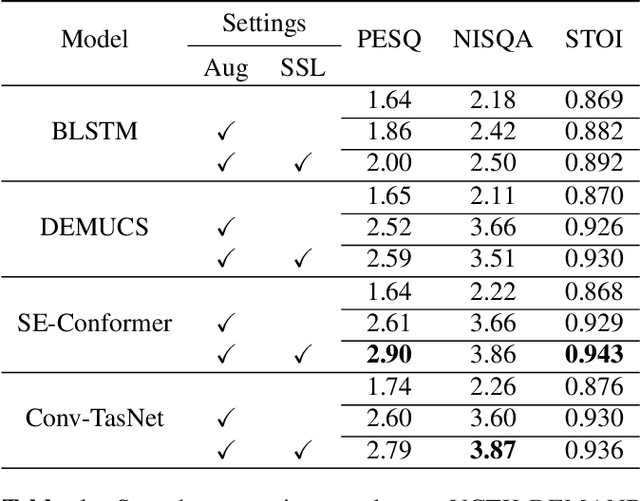
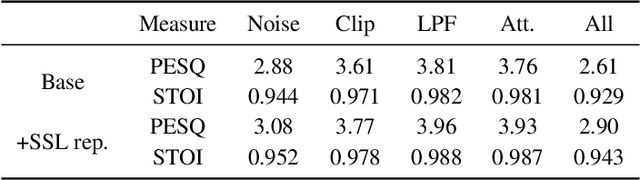
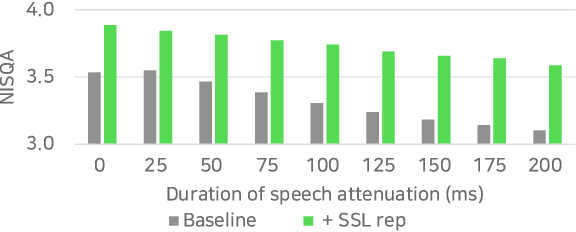
Enhancing speech quality is an indispensable yet difficult task as it is often complicated by a range of degradation factors. In addition to additive noise, reverberation, clipping, and speech attenuation can all adversely affect speech quality. Speech restoration aims to recover speech components from these distortions. This paper focuses on exploring the impact of self-supervised speech representation learning on the speech restoration task. Specifically, we employ speech representation in various speech restoration networks and evaluate their performance under complicated distortion scenarios. Our experiments demonstrate that the contextual information provided by the self-supervised speech representation can enhance speech restoration performance in various distortion scenarios, while also increasing robustness against the duration of speech attenuation and mismatched test conditions.
SLMGAN: Exploiting Speech Language Model Representations for Unsupervised Zero-Shot Voice Conversion in GANs
Jul 18, 2023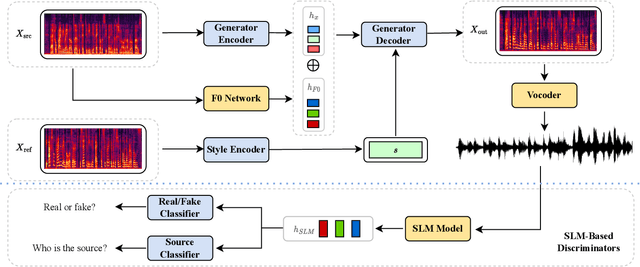
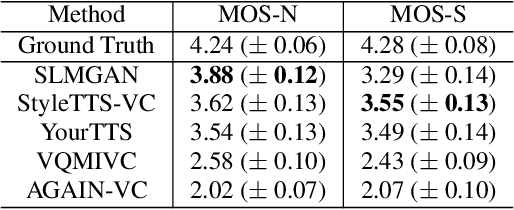
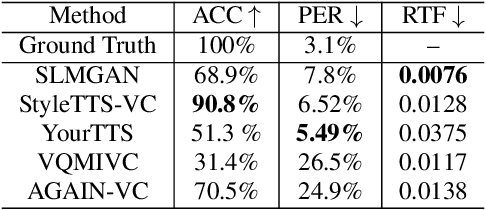
In recent years, large-scale pre-trained speech language models (SLMs) have demonstrated remarkable advancements in various generative speech modeling applications, such as text-to-speech synthesis, voice conversion, and speech enhancement. These applications typically involve mapping text or speech inputs to pre-trained SLM representations, from which target speech is decoded. This paper introduces a new approach, SLMGAN, to leverage SLM representations for discriminative tasks within the generative adversarial network (GAN) framework, specifically for voice conversion. Building upon StarGANv2-VC, we add our novel SLM-based WavLM discriminators on top of the mel-based discriminators along with our newly designed SLM feature matching loss function, resulting in an unsupervised zero-shot voice conversion system that does not require text labels during training. Subjective evaluation results show that SLMGAN outperforms existing state-of-the-art zero-shot voice conversion models in terms of naturalness and achieves comparable similarity, highlighting the potential of SLM-based discriminators for related applications.
Noise-aware Speech Enhancement using Diffusion Probabilistic Model
Jul 16, 2023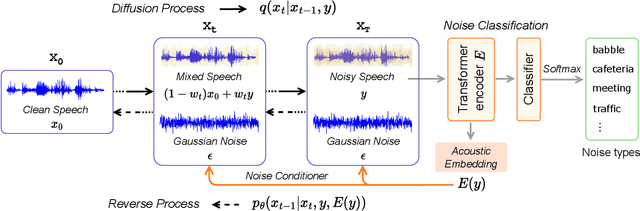
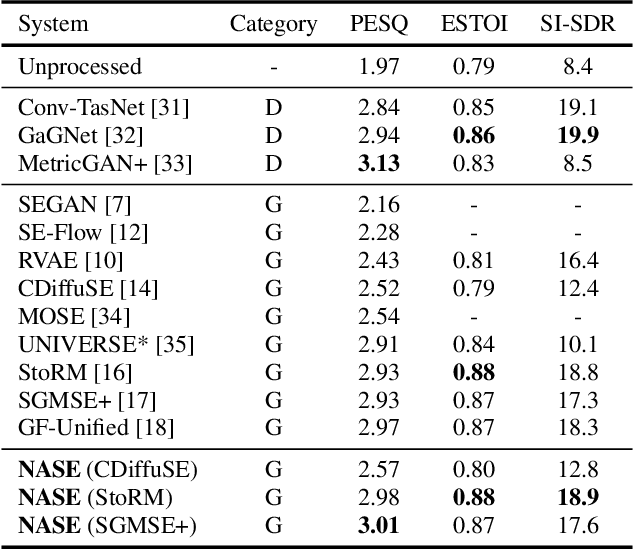
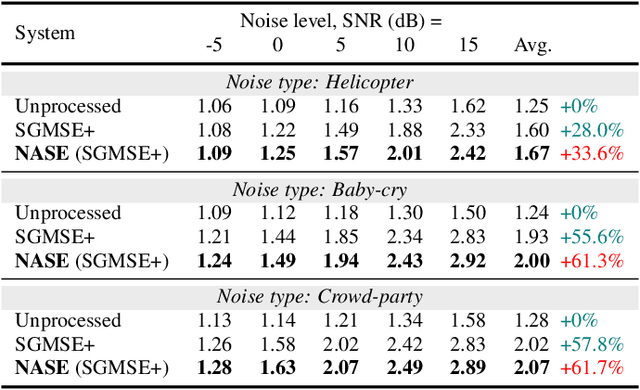
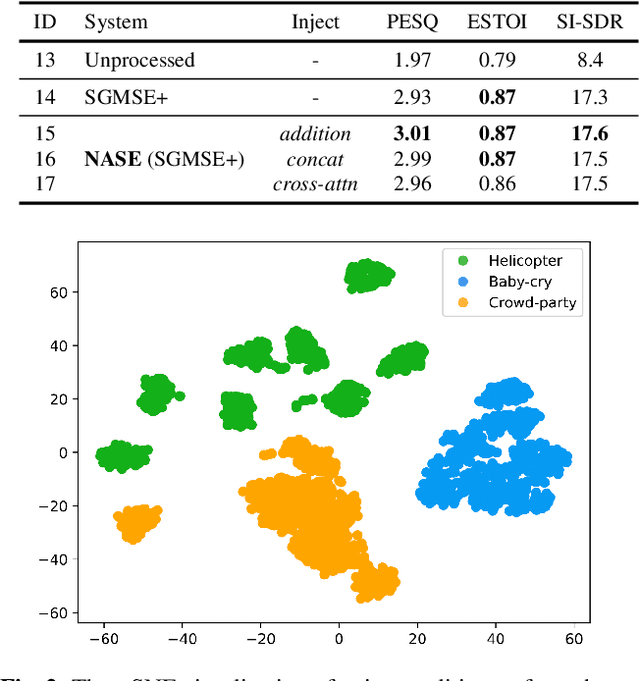
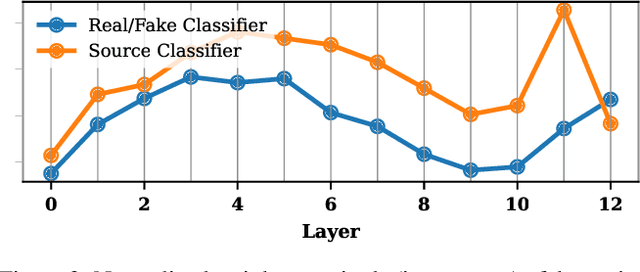
With recent advances of diffusion model, generative speech enhancement (SE) has attracted a surge of research interest due to its great potential for unseen testing noises. However, existing efforts mainly focus on inherent properties of clean speech for inference, underexploiting the varying noise information in real-world conditions. In this paper, we propose a noise-aware speech enhancement (NASE) approach that extracts noise-specific information to guide the reverse process in diffusion model. Specifically, we design a noise classification (NC) model to produce acoustic embedding as a noise conditioner for guiding the reverse denoising process. Meanwhile, a multi-task learning scheme is devised to jointly optimize SE and NC tasks, in order to enhance the noise specificity of extracted noise conditioner. Our proposed NASE is shown to be a plug-and-play module that can be generalized to any diffusion SE models. Experiment evidence on VoiceBank-DEMAND dataset shows that NASE achieves significant improvement over multiple mainstream diffusion SE models, especially on unseen testing noises.
SC VALL-E: Style-Controllable Zero-Shot Text to Speech Synthesizer
Jul 20, 2023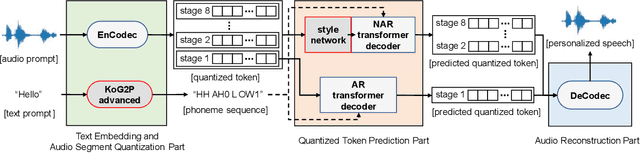
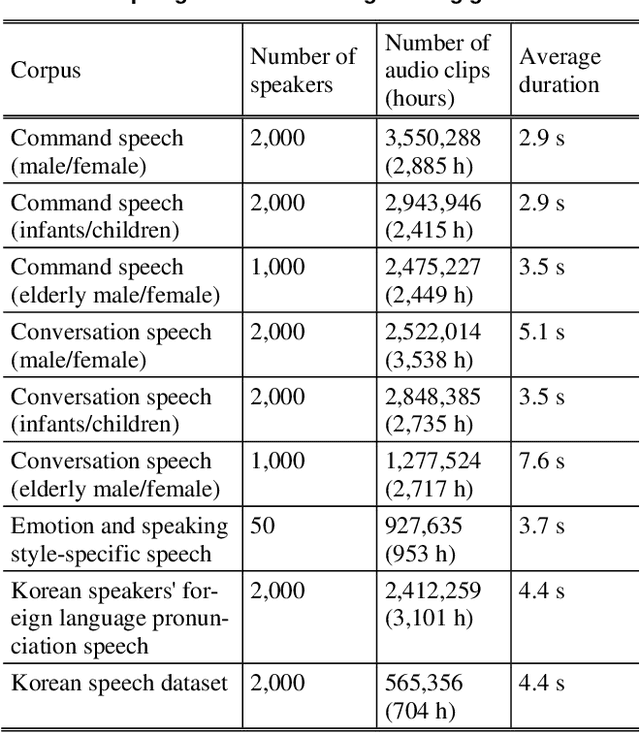
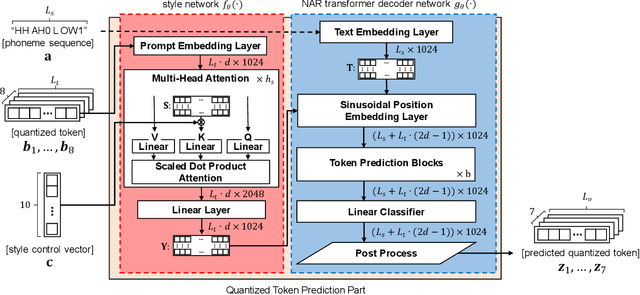
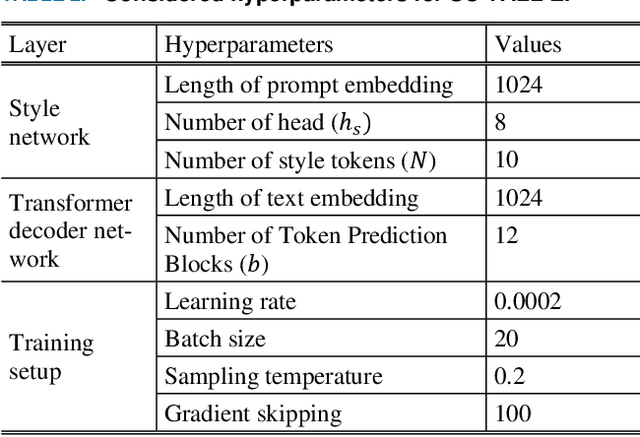
Expressive speech synthesis models are trained by adding corpora with diverse speakers, various emotions, and different speaking styles to the dataset, in order to control various characteristics of speech and generate the desired voice. In this paper, we propose a style control (SC) VALL-E model based on the neural codec language model (called VALL-E), which follows the structure of the generative pretrained transformer 3 (GPT-3). The proposed SC VALL-E takes input from text sentences and prompt audio and is designed to generate controllable speech by not simply mimicking the characteristics of the prompt audio but by controlling the attributes to produce diverse voices. We identify tokens in the style embedding matrix of the newly designed style network that represent attributes such as emotion, speaking rate, pitch, and voice intensity, and design a model that can control these attributes. To evaluate the performance of SC VALL-E, we conduct comparative experiments with three representative expressive speech synthesis models: global style token (GST) Tacotron2, variational autoencoder (VAE) Tacotron2, and original VALL-E. We measure word error rate (WER), F0 voiced error (FVE), and F0 gross pitch error (F0GPE) as evaluation metrics to assess the accuracy of generated sentences. For comparing the quality of synthesized speech, we measure comparative mean option score (CMOS) and similarity mean option score (SMOS). To evaluate the style control ability of the generated speech, we observe the changes in F0 and mel-spectrogram by modifying the trained tokens. When using prompt audio that is not present in the training data, SC VALL-E generates a variety of expressive sounds and demonstrates competitive performance compared to the existing models. Our implementation, pretrained models, and audio samples are located on GitHub.
SCRAPS: Speech Contrastive Representations of Acoustic and Phonetic Spaces
Jul 23, 2023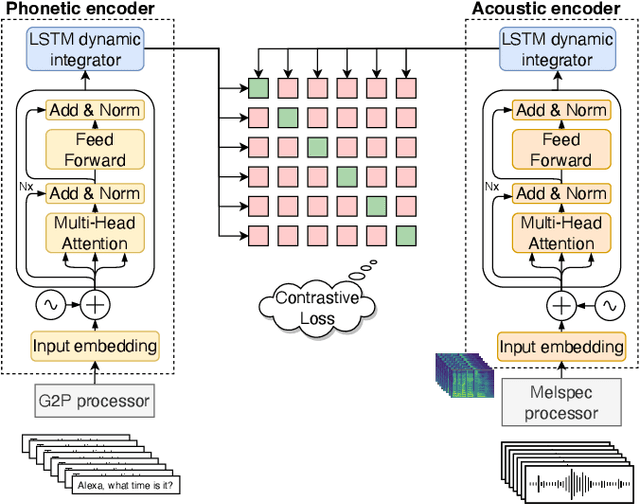
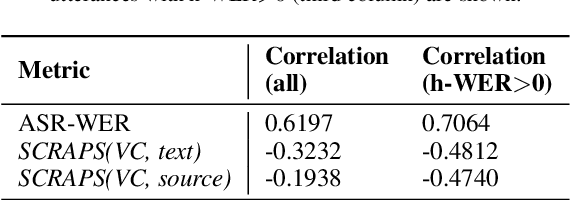
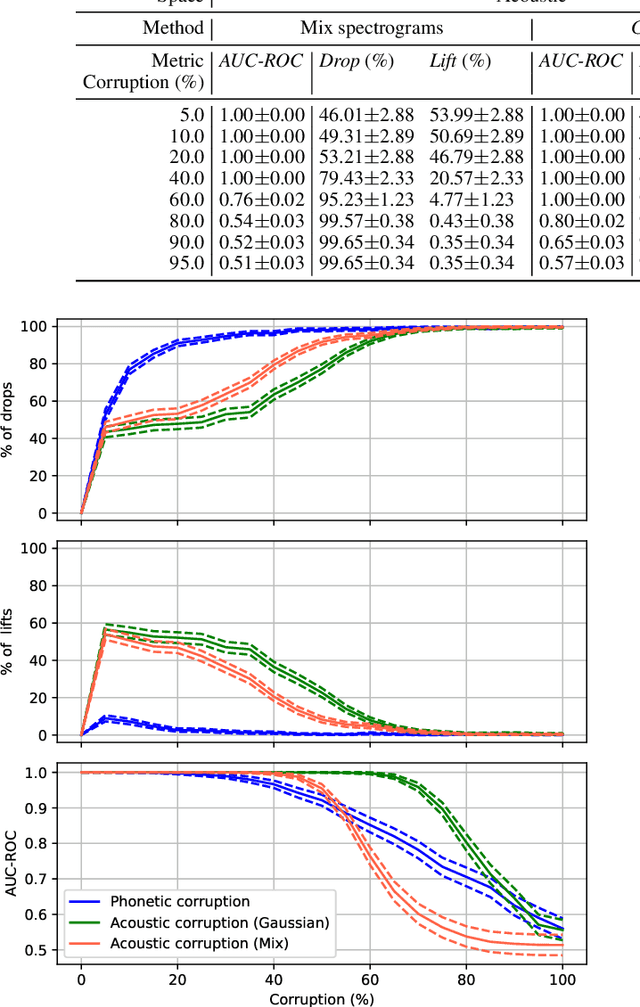
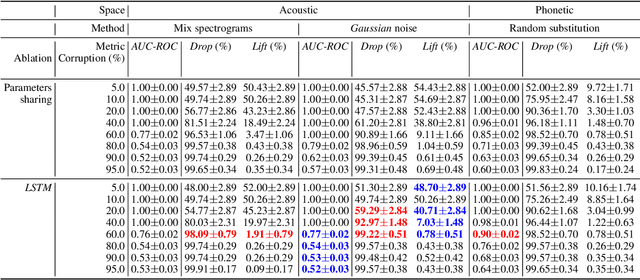
Numerous examples in the literature proved that deep learning models have the ability to work well with multimodal data. Recently, CLIP has enabled deep learning systems to learn shared latent spaces between images and text descriptions, with outstanding zero- or few-shot results in downstream tasks. In this paper we explore the same idea proposed by CLIP but applied to the speech domain, where the phonetic and acoustic spaces usually coexist. We train a CLIP-based model with the aim to learn shared representations of phonetic and acoustic spaces. The results show that the proposed model is sensible to phonetic changes, with a 91% of score drops when replacing 20% of the phonemes at random, while providing substantial robustness against different kinds of noise, with a 10% performance drop when mixing the audio with 75% of Gaussian noise. We also provide empirical evidence showing that the resulting embeddings are useful for a variety of downstream applications, such as intelligibility evaluation and the ability to leverage rich pre-trained phonetic embeddings in speech generation task. Finally, we discuss potential applications with interesting implications for the speech generation and recognition fields.
Temporally Aligning Long Audio Interviews with Questions: A Case Study in Multimodal Data Integration
Oct 10, 2023
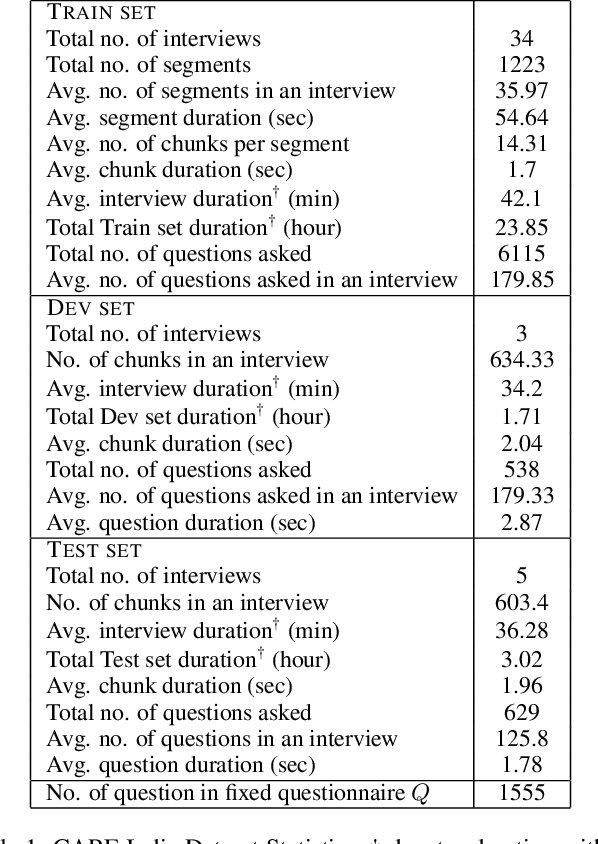
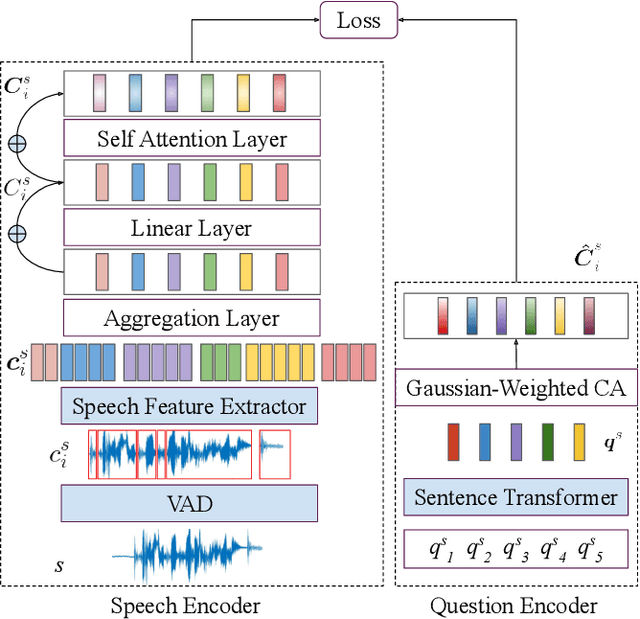
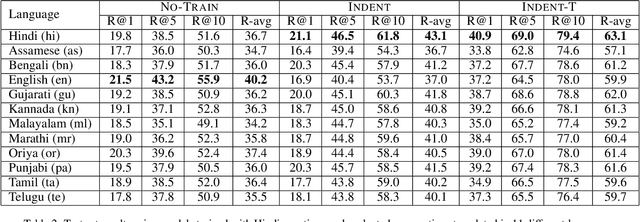
The problem of audio-to-text alignment has seen significant amount of research using complete supervision during training. However, this is typically not in the context of long audio recordings wherein the text being queried does not appear verbatim within the audio file. This work is a collaboration with a non-governmental organization called CARE India that collects long audio health surveys from young mothers residing in rural parts of Bihar, India. Given a question drawn from a questionnaire that is used to guide these surveys, we aim to locate where the question is asked within a long audio recording. This is of great value to African and Asian organizations that would otherwise have to painstakingly go through long and noisy audio recordings to locate questions (and answers) of interest. Our proposed framework, INDENT, uses a cross-attention-based model and prior information on the temporal ordering of sentences to learn speech embeddings that capture the semantics of the underlying spoken text. These learnt embeddings are used to retrieve the corresponding audio segment based on text queries at inference time. We empirically demonstrate the significant effectiveness (improvement in R-avg of about 3%) of our model over those obtained using text-based heuristics. We also show how noisy ASR, generated using state-of-the-art ASR models for Indian languages, yields better results when used in place of speech. INDENT, trained only on Hindi data is able to cater to all languages supported by the (semantically) shared text space. We illustrate this empirically on 11 Indic languages.
Single Channel Speech Enhancement Using U-Net Spiking Neural Networks
Jul 26, 2023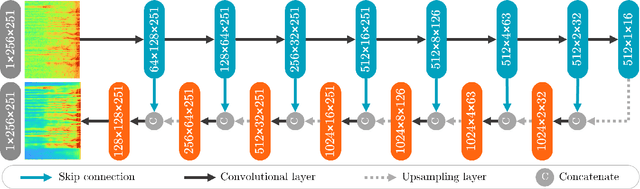
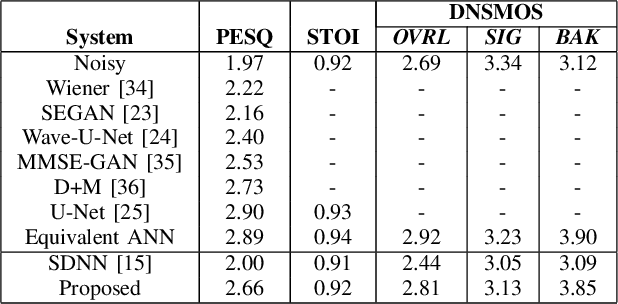
Speech enhancement (SE) is crucial for reliable communication devices or robust speech recognition systems. Although conventional artificial neural networks (ANN) have demonstrated remarkable performance in SE, they require significant computational power, along with high energy costs. In this paper, we propose a novel approach to SE using a spiking neural network (SNN) based on a U-Net architecture. SNNs are suitable for processing data with a temporal dimension, such as speech, and are known for their energy-efficient implementation on neuromorphic hardware. As such, SNNs are thus interesting candidates for real-time applications on devices with limited resources. The primary objective of the current work is to develop an SNN-based model with comparable performance to a state-of-the-art ANN model for SE. We train a deep SNN using surrogate-gradient-based optimization and evaluate its performance using perceptual objective tests under different signal-to-noise ratios and real-world noise conditions. Our results demonstrate that the proposed energy-efficient SNN model outperforms the Intel Neuromorphic Deep Noise Suppression Challenge (Intel N-DNS Challenge) baseline solution and achieves acceptable performance compared to an equivalent ANN model.
ALDi: Quantifying the Arabic Level of Dialectness of Text
Oct 20, 2023Transcribed speech and user-generated text in Arabic typically contain a mixture of Modern Standard Arabic (MSA), the standardized language taught in schools, and Dialectal Arabic (DA), used in daily communications. To handle this variation, previous work in Arabic NLP has focused on Dialect Identification (DI) on the sentence or the token level. However, DI treats the task as binary, whereas we argue that Arabic speakers perceive a spectrum of dialectness, which we operationalize at the sentence level as the Arabic Level of Dialectness (ALDi), a continuous linguistic variable. We introduce the AOC-ALDi dataset (derived from the AOC dataset), containing 127,835 sentences (17% from news articles and 83% from user comments on those articles) which are manually labeled with their level of dialectness. We provide a detailed analysis of AOC-ALDi and show that a model trained on it can effectively identify levels of dialectness on a range of other corpora (including dialects and genres not included in AOC-ALDi), providing a more nuanced picture than traditional DI systems. Through case studies, we illustrate how ALDi can reveal Arabic speakers' stylistic choices in different situations, a useful property for sociolinguistic analyses.
Corpus Synthesis for Zero-shot ASR domain Adaptation using Large Language Models
Sep 18, 2023While Automatic Speech Recognition (ASR) systems are widely used in many real-world applications, they often do not generalize well to new domains and need to be finetuned on data from these domains. However, target-domain data usually are not readily available in many scenarios. In this paper, we propose a new strategy for adapting ASR models to new target domains without any text or speech from those domains. To accomplish this, we propose a novel data synthesis pipeline that uses a Large Language Model (LLM) to generate a target domain text corpus, and a state-of-the-art controllable speech synthesis model to generate the corresponding speech. We propose a simple yet effective in-context instruction finetuning strategy to increase the effectiveness of LLM in generating text corpora for new domains. Experiments on the SLURP dataset show that the proposed method achieves an average relative word error rate improvement of $28\%$ on unseen target domains without any performance drop in source domains.