 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech Emotion Diarization: Which Emotion Appears When?
Jun 22, 2023
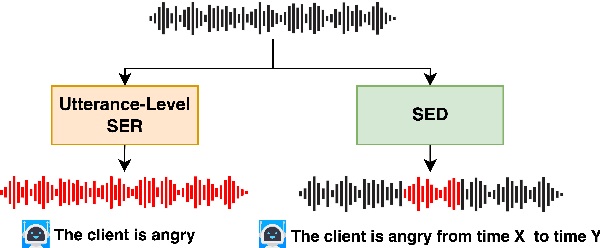
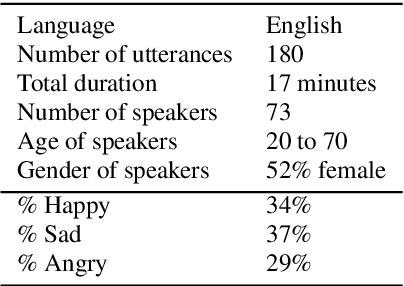


Speech Emotion Recognition (SER) typically relies on utterance-level solutions. However, emotions conveyed through speech should be considered as discrete speech events with definite temporal boundaries, rather than attributes of the entire utterance. To reflect the fine-grained nature of speech emotions, we propose a new task: Speech Emotion Diarization (SED). Just as Speaker Diarization answers the question of "Who speaks when?", Speech Emotion Diarization answers the question of "Which emotion appears when?". To facilitate the evaluation of the performance and establish a common benchmark for researchers, we introduce the Zaion Emotion Dataset (ZED), an openly accessible speech emotion dataset that includes non-acted emotions recorded in real-life conditions, along with manually-annotated boundaries of emotion segments within the utterance. We provide competitive baselines and open-source the code and the pre-trained models.
Multi-Modal Automatic Prosody Annotation with Contrastive Pretraining of SSWP
Sep 11, 2023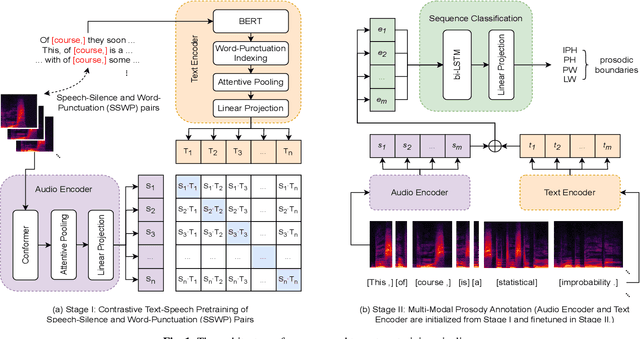
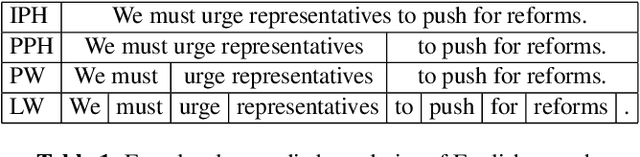
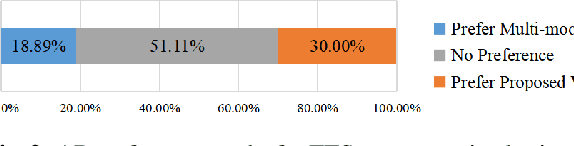
In the realm of expressive Text-to-Speech (TTS), explicit prosodic boundaries significantly advance the naturalness and controllability of synthesized speech. While human prosody annotation contributes a lot to the performance, it is a labor-intensive and time-consuming process, often resulting in inconsistent outcomes. Despite the availability of extensive supervised data, the current benchmark model still faces performance setbacks. To address this issue, a two-stage automatic annotation pipeline is novelly proposed in this paper. Specifically, in the first stage, we propose contrastive text-speech pretraining of Speech-Silence and Word-Punctuation (SSWP) pairs. The pretraining procedure hammers at enhancing the prosodic space extracted from joint text-speech space. In the second stage, we build a multi-modal prosody annotator, which consists of pretrained encoders, a straightforward yet effective text-speech feature fusion scheme, and a sequence classifier. Extensive experiments conclusively demonstrate that our proposed method excels at automatically generating prosody annotation and achieves state-of-the-art (SOTA) performance. Furthermore, our novel model has exhibited remarkable resilience when tested with varying amounts of data.
Exploring the Integration of Speech Separation and Recognition with Self-Supervised Learning Representation
Jul 23, 2023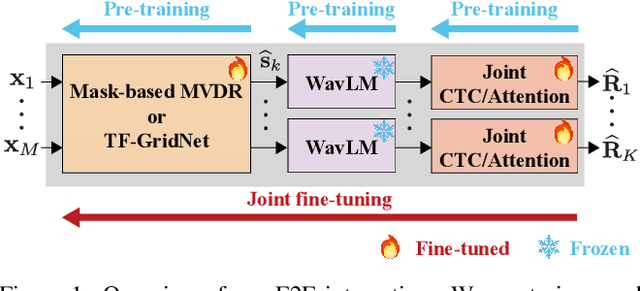
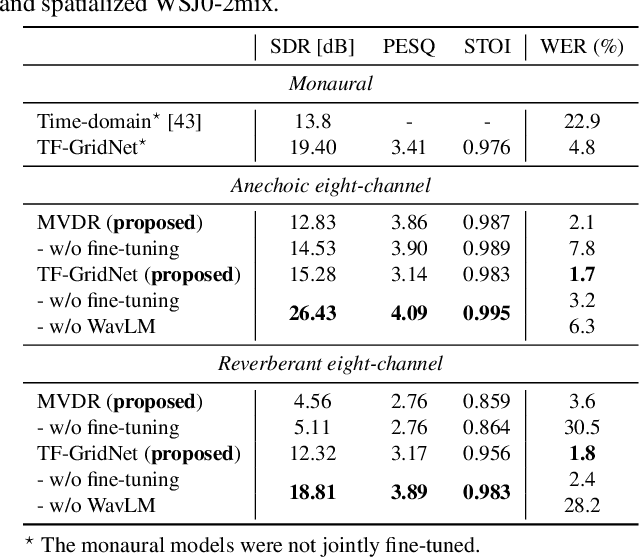
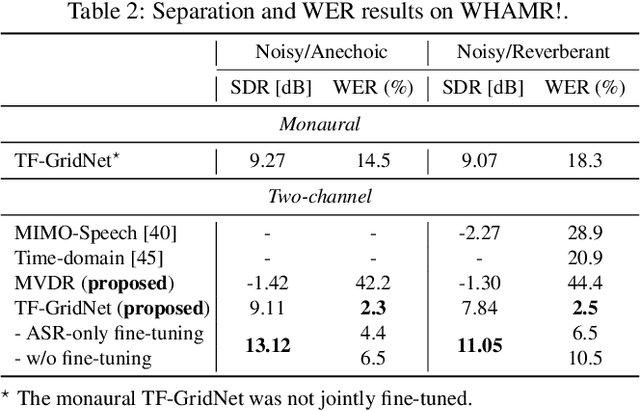
Neural speech separation has made remarkable progress and its integration with automatic speech recognition (ASR) is an important direction towards realizing multi-speaker ASR. This work provides an insightful investigation of speech separation in reverberant and noisy-reverberant scenarios as an ASR front-end. In detail, we explore multi-channel separation methods, mask-based beamforming and complex spectral mapping, as well as the best features to use in the ASR back-end model. We employ the recent self-supervised learning representation (SSLR) as a feature and improve the recognition performance from the case with filterbank features. To further improve multi-speaker recognition performance, we present a carefully designed training strategy for integrating speech separation and recognition with SSLR. The proposed integration using TF-GridNet-based complex spectral mapping and WavLM-based SSLR achieves a 2.5% word error rate in reverberant WHAMR! test set, significantly outperforming an existing mask-based MVDR beamforming and filterbank integration (28.9%).
Prompting Large Language Models with Speech Recognition Abilities
Jul 21, 2023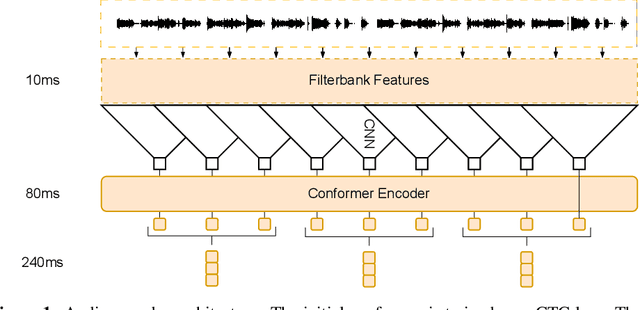
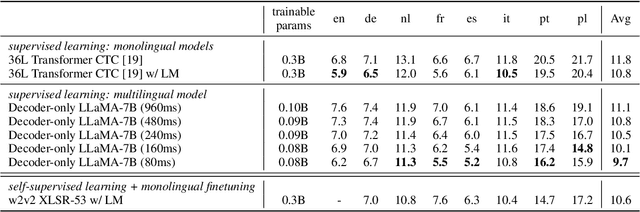
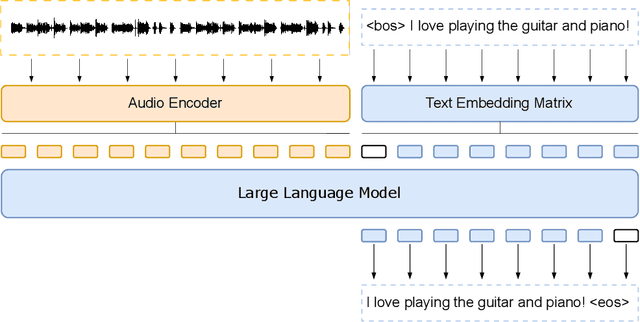

Large language models have proven themselves highly flexible, able to solve a wide range of generative tasks, such as abstractive summarization and open-ended question answering. In this paper we extend the capabilities of LLMs by directly attaching a small audio encoder allowing it to perform speech recognition. By directly prepending a sequence of audial embeddings to the text token embeddings, the LLM can be converted to an automatic speech recognition (ASR) system, and be used in the exact same manner as its textual counterpart. Experiments on Multilingual LibriSpeech (MLS) show that incorporating a conformer encoder into the open sourced LLaMA-7B allows it to outperform monolingual baselines by 18% and perform multilingual speech recognition despite LLaMA being trained overwhelmingly on English text. Furthermore, we perform ablation studies to investigate whether the LLM can be completely frozen during training to maintain its original capabilities, scaling up the audio encoder, and increasing the audio encoder striding to generate fewer embeddings. The results from these studies show that multilingual ASR is possible even when the LLM is frozen or when strides of almost 1 second are used in the audio encoder opening up the possibility for LLMs to operate on long-form audio.
Audio-AdapterFusion: A Task-ID-free Approach for Efficient and Non-Destructive Multi-task Speech Recognition
Oct 17, 2023Adapters are an efficient, composable alternative to full fine-tuning of pre-trained models and help scale the deployment of large ASR models to many tasks. In practice, a task ID is commonly prepended to the input during inference to route to single-task adapters for the specified task. However, one major limitation of this approach is that the task ID may not be known during inference, rendering it unsuitable for most multi-task settings. To address this, we propose three novel task-ID-free methods to combine single-task adapters in multi-task ASR and investigate two learning algorithms for training. We evaluate our methods on 10 test sets from 4 diverse ASR tasks and show that our methods are non-destructive and parameter-efficient. While only updating 17% of the model parameters, our methods can achieve an 8% mean WER improvement relative to full fine-tuning and are on-par with task-ID adapter routing.
HowToCaption: Prompting LLMs to Transform Video Annotations at Scale
Oct 07, 2023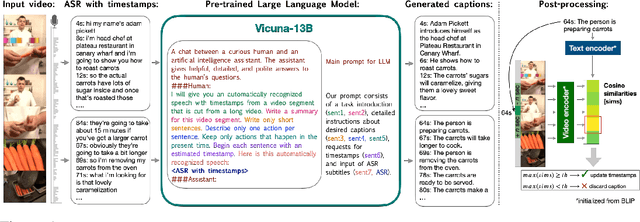
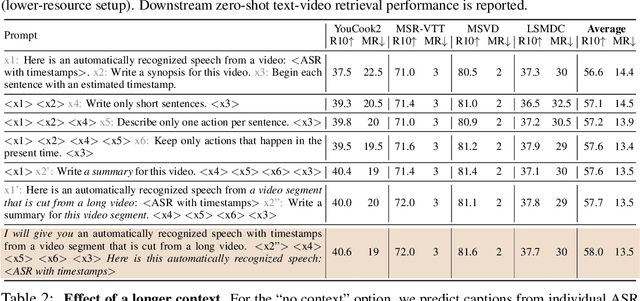


Instructional videos are an excellent source for learning multimodal representations by leveraging video-subtitle pairs extracted with automatic speech recognition systems (ASR) from the audio signal in the videos. However, in contrast to human-annotated captions, both speech and subtitles naturally differ from the visual content of the videos and thus provide only noisy supervision for multimodal learning. As a result, large-scale annotation-free web video training data remains sub-optimal for training text-video models. In this work, we propose to leverage the capability of large language models (LLMs) to obtain fine-grained video descriptions aligned with videos. Specifically, we prompt an LLM to create plausible video descriptions based on ASR narrations of the video for a large-scale instructional video dataset. To this end, we introduce a prompting method that is able to take into account a longer text of subtitles, allowing us to capture context beyond a single sentence. To align the captions to the video temporally, we prompt the LLM to generate timestamps for each produced caption based on the subtitles. In this way, we obtain human-style video captions at scale without human supervision. We apply our method to the subtitles of the HowTo100M dataset, creating a new large-scale dataset, HowToCaption. Our evaluation shows that the resulting captions not only significantly improve the performance over many different benchmark datasets for text-video retrieval but also lead to a disentangling of textual narration from the audio, boosting performance in text-video-audio tasks.
Unintended Memorization in Large ASR Models, and How to Mitigate It
Oct 18, 2023It is well-known that neural networks can unintentionally memorize their training examples, causing privacy concerns. However, auditing memorization in large non-auto-regressive automatic speech recognition (ASR) models has been challenging due to the high compute cost of existing methods such as hardness calibration. In this work, we design a simple auditing method to measure memorization in large ASR models without the extra compute overhead. Concretely, we speed up randomly-generated utterances to create a mapping between vocal and text information that is difficult to learn from typical training examples. Hence, accurate predictions only for sped-up training examples can serve as clear evidence for memorization, and the corresponding accuracy can be used to measure memorization. Using the proposed method, we showcase memorization in the state-of-the-art ASR models. To mitigate memorization, we tried gradient clipping during training to bound the influence of any individual example on the final model. We empirically show that clipping each example's gradient can mitigate memorization for sped-up training examples with up to 16 repetitions in the training set. Furthermore, we show that in large-scale distributed training, clipping the average gradient on each compute core maintains neutral model quality and compute cost while providing strong privacy protection.
Improving Short Utterance Anti-Spoofing with AASIST2
Sep 15, 2023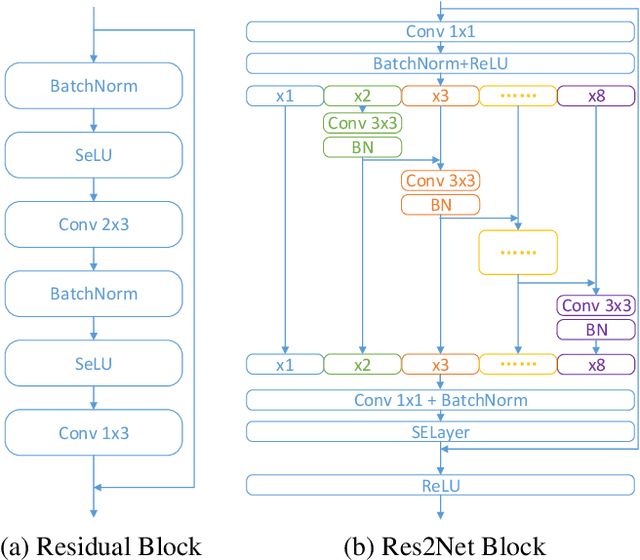

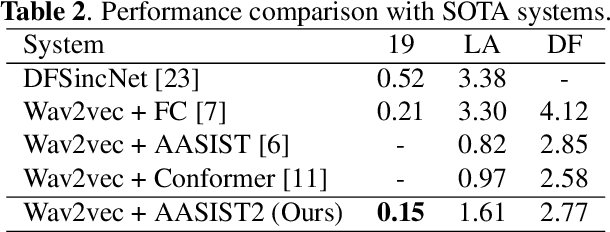
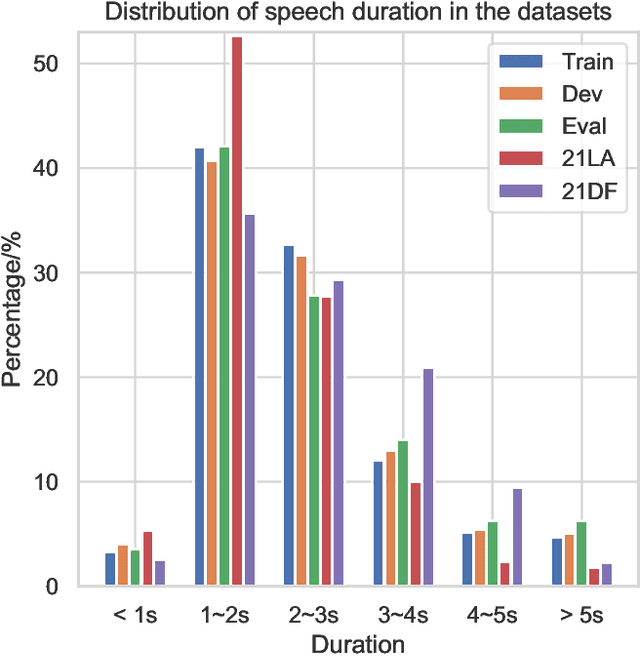
The wav2vec 2.0 and integrated spectro-temporal graph attention network (AASIST) based countermeasure achieves great performance in speech anti-spoofing. However, current spoof speech detection systems have fixed training and evaluation durations, while the performance degrades significantly during short utterance evaluation. To solve this problem, AASIST can be improved to AASIST2 by modifying the residual blocks to Res2Net blocks. The modified Res2Net blocks can extract multi-scale features and improve the detection performance for speech of different durations, thus improving the short utterance evaluation performance. On the other hand, adaptive large margin fine-tuning (ALMFT) has achieved performance improvement in short utterance speaker verification. Therefore, we apply Dynamic Chunk Size (DCS) and ALMFT training strategies in speech anti-spoofing to further improve the performance of short utterance evaluation. Experiments demonstrate that the proposed AASIST2 improves the performance of short utterance evaluation while maintaining the performance of regular evaluation on different datasets.
CQNV: A combination of coarsely quantized bitstream and neural vocoder for low rate speech coding
Jul 25, 2023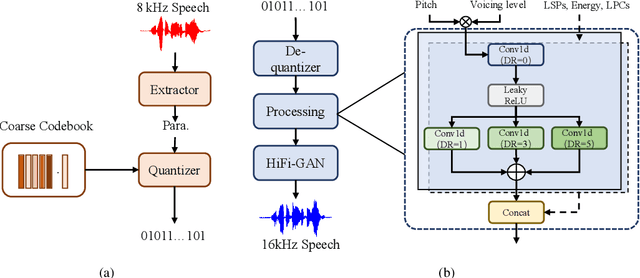

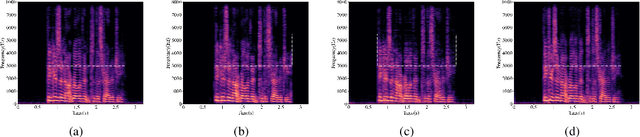

Recently, speech codecs based on neural networks have proven to perform better than traditional methods. However, redundancy in traditional parameter quantization is visible within the codec architecture of combining the traditional codec with the neural vocoder. In this paper, we propose a novel framework named CQNV, which combines the coarsely quantized parameters of a traditional parametric codec to reduce the bitrate with a neural vocoder to improve the quality of the decoded speech. Furthermore, we introduce a parameters processing module into the neural vocoder to enhance the application of the bitstream of traditional speech coding parameters to the neural vocoder, further improving the reconstructed speech's quality. In the experiments, both subjective and objective evaluations demonstrate the effectiveness of the proposed CQNV framework. Specifically, our proposed method can achieve higher quality reconstructed speech at 1.1 kbps than Lyra and Encodec at 3 kbps.
Improving Speaker Diarization using Semantic Information: Joint Pairwise Constraints Propagation
Sep 19, 2023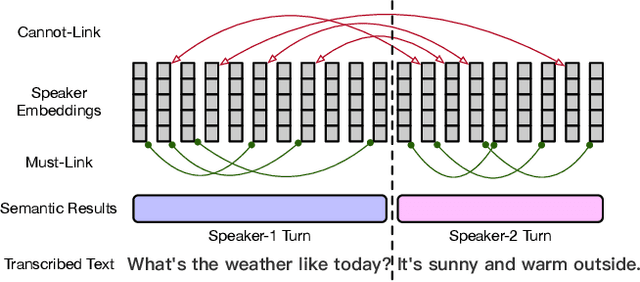
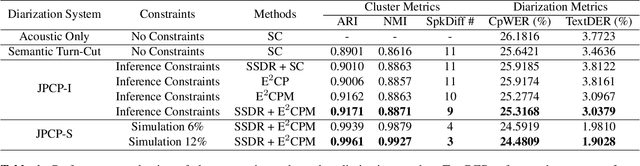
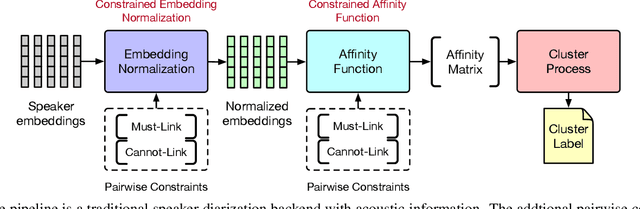
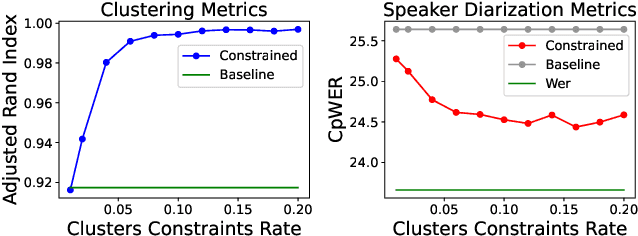
Speaker diarization has gained considerable attention within speech processing research community. Mainstream speaker diarization rely primarily on speakers' voice characteristics extracted from acoustic signals and often overlook the potential of semantic information. Considering the fact that speech signals can efficiently convey the content of a speech, it is of our interest to fully exploit these semantic cues utilizing language models. In this work we propose a novel approach to effectively leverage semantic information in clustering-based speaker diarization systems. Firstly, we introduce spoken language understanding modules to extract speaker-related semantic information and utilize these information to construct pairwise constraints. Secondly, we present a novel framework to integrate these constraints into the speaker diarization pipeline, enhancing the performance of the entire system. Extensive experiments conducted on the public dataset demonstrate the consistent superiority of our proposed approach over acoustic-only speaker diarization systems.