 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Quantifying the Dialect Gap and its Correlates Across Languages
Oct 23, 2023
Historically, researchers and consumers have noticed a decrease in quality when applying NLP tools to minority variants of languages (i.e. Puerto Rican Spanish or Swiss German), but studies exploring this have been limited to a select few languages. Additionally, past studies have mainly been conducted in a monolingual context, so cross-linguistic trends have not been identified and tied to external factors. In this work, we conduct a comprehensive evaluation of the most influential, state-of-the-art large language models (LLMs) across two high-use applications, machine translation and automatic speech recognition, to assess their functionality on the regional dialects of several high- and low-resource languages. Additionally, we analyze how the regional dialect gap is correlated with economic, social, and linguistic factors. The impact of training data, including related factors like dataset size and its construction procedure, is shown to be significant but not consistent across models or languages, meaning a one-size-fits-all approach cannot be taken in solving the dialect gap. This work will lay the foundation for furthering the field of dialectal NLP by laying out evident disparities and identifying possible pathways for addressing them through mindful data collection.
Delayed Memory Unit: Modelling Temporal Dependency Through Delay Gate
Oct 23, 2023Recurrent Neural Networks (RNNs) are renowned for their adeptness in modeling temporal dependencies, a trait that has driven their widespread adoption for sequential data processing. Nevertheless, vanilla RNNs are confronted with the well-known issue of gradient vanishing and exploding, posing a significant challenge for learning and establishing long-range dependencies. Additionally, gated RNNs tend to be over-parameterized, resulting in poor network generalization. To address these challenges, we propose a novel Delayed Memory Unit (DMU) in this paper, wherein a delay line structure, coupled with delay gates, is introduced to facilitate temporal interaction and temporal credit assignment, so as to enhance the temporal modeling capabilities of vanilla RNNs. Particularly, the DMU is designed to directly distribute the input information to the optimal time instant in the future, rather than aggregating and redistributing it over time through intricate network dynamics. Our proposed DMU demonstrates superior temporal modeling capabilities across a broad range of sequential modeling tasks, utilizing considerably fewer parameters than other state-of-the-art gated RNN models in applications such as speech recognition, radar gesture recognition, ECG waveform segmentation, and permuted sequential image classification.
InterroLang: Exploring NLP Models and Datasets through Dialogue-based Explanations
Oct 23, 2023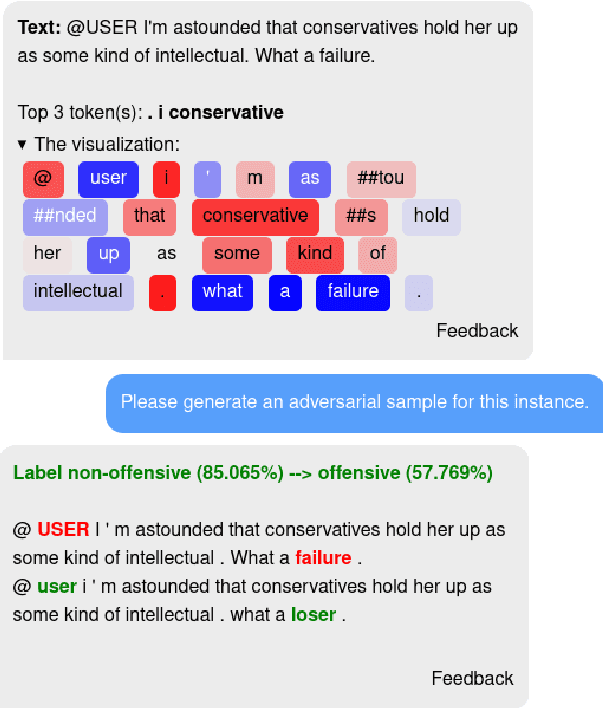
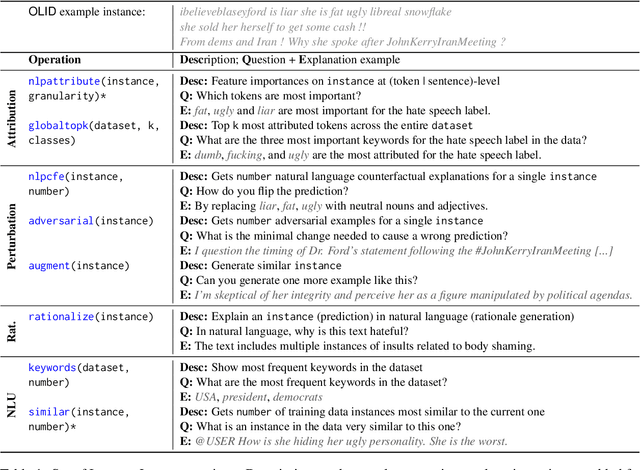
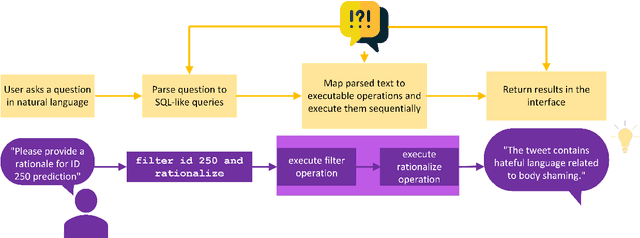
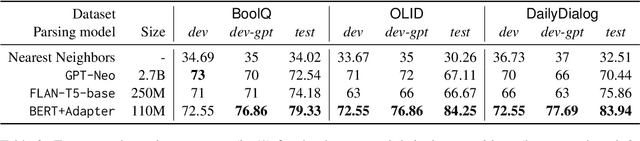
While recently developed NLP explainability methods let us open the black box in various ways (Madsen et al., 2022), a missing ingredient in this endeavor is an interactive tool offering a conversational interface. Such a dialogue system can help users explore datasets and models with explanations in a contextualized manner, e.g. via clarification or follow-up questions, and through a natural language interface. We adapt the conversational explanation framework TalkToModel (Slack et al., 2022) to the NLP domain, add new NLP-specific operations such as free-text rationalization, and illustrate its generalizability on three NLP tasks (dialogue act classification, question answering, hate speech detection). To recognize user queries for explanations, we evaluate fine-tuned and few-shot prompting models and implement a novel Adapter-based approach. We then conduct two user studies on (1) the perceived correctness and helpfulness of the dialogues, and (2) the simulatability, i.e. how objectively helpful dialogical explanations are for humans in figuring out the model's predicted label when it's not shown. We found rationalization and feature attribution were helpful in explaining the model behavior. Moreover, users could more reliably predict the model outcome based on an explanation dialogue rather than one-off explanations.
UniverSLU: Universal Spoken Language Understanding for Diverse Classification and Sequence Generation Tasks with a Single Network
Oct 04, 2023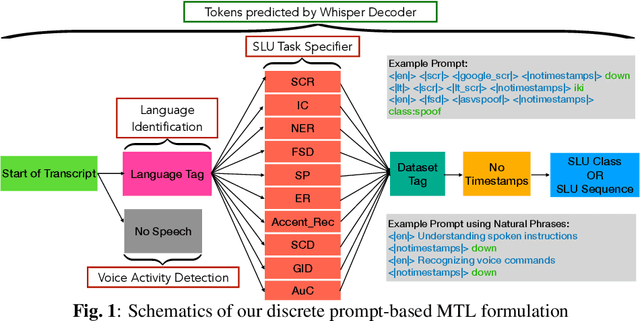
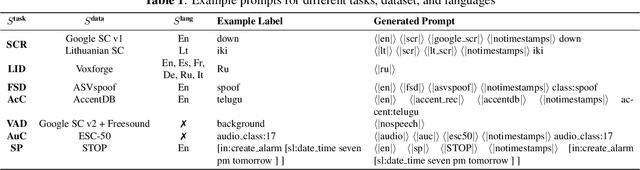


Recent studies have demonstrated promising outcomes by employing large language models with multi-tasking capabilities. They utilize prompts to guide the model's behavior and surpass performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly perform various spoken language understanding (SLU) tasks? To address this, we utilize pre-trained automatic speech recognition (ASR) models and employ various task and dataset specifiers as discrete prompts. We demonstrate efficacy of our single multi-task learning (MTL) model "UniverSLU" for 12 different speech classification and sequence generation tasks across 17 datasets and 9 languages. Results show that UniverSLU achieves competitive performance and even surpasses task-specific models. We also conduct preliminary investigations into enabling human-interpretable natural phrases instead of task specifiers as discrete prompts and test the model's generalization capabilities to new paraphrases.
Improving severity preservation of healthy-to-pathological voice conversion with global style tokens
Oct 04, 2023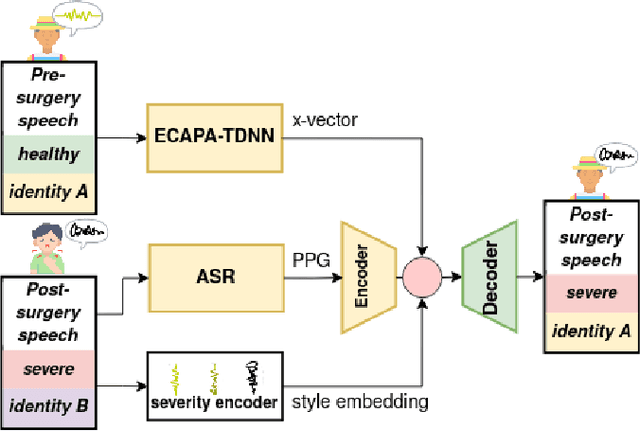


In healthy-to-pathological voice conversion (H2P-VC), healthy speech is converted into pathological while preserving the identity. The paper improves on previous two-stage approach to H2P-VC where (1) speech is created first with the appropriate severity, (2) then the speaker identity of the voice is converted while preserving the severity of the voice. Specifically, we propose improvements to (2) by using phonetic posteriorgrams (PPG) and global style tokens (GST). Furthermore, we present a new dataset that contains parallel recordings of pathological and healthy speakers with the same identity which allows more precise evaluation. Listening tests by expert listeners show that the framework preserves severity of the source sample, while modelling target speaker's voice. We also show that (a) pathology impacts x-vectors but not all speaker information is lost, (b) choosing source speakers based on severity labels alone is insufficient.
Classification of Dysarthria based on the Levels of Severity. A Systematic Review
Oct 11, 2023Dysarthria is a neurological speech disorder that can significantly impact affected individuals' communication abilities and overall quality of life. The accurate and objective classification of dysarthria and the determination of its severity are crucial for effective therapeutic intervention. While traditional assessments by speech-language pathologists (SLPs) are common, they are often subjective, time-consuming, and can vary between practitioners. Emerging machine learning-based models have shown the potential to provide a more objective dysarthria assessment, enhancing diagnostic accuracy and reliability. This systematic review aims to comprehensively analyze current methodologies for classifying dysarthria based on severity levels. Specifically, this review will focus on determining the most effective set and type of features that can be used for automatic patient classification and evaluating the best AI techniques for this purpose. We will systematically review the literature on the automatic classification of dysarthria severity levels. Sources of information will include electronic databases and grey literature. Selection criteria will be established based on relevance to the research questions. Data extraction will include methodologies used, the type of features extracted for classification, and AI techniques employed. The findings of this systematic review will contribute to the current understanding of dysarthria classification, inform future research, and support the development of improved diagnostic tools. The implications of these findings could be significant in advancing patient care and improving therapeutic outcomes for individuals affected by dysarthria.
GASS: Generalizing Audio Source Separation with Large-scale Data
Sep 29, 2023
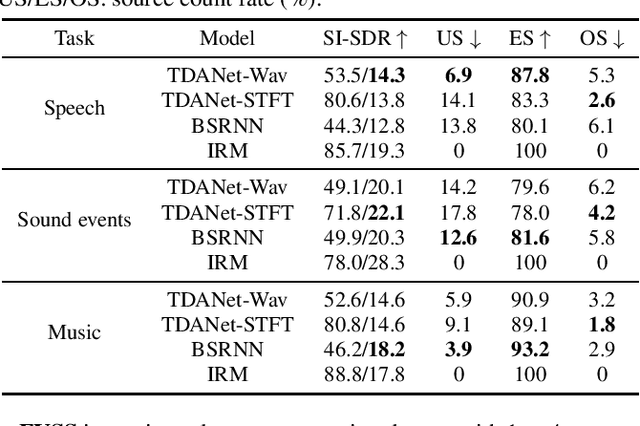
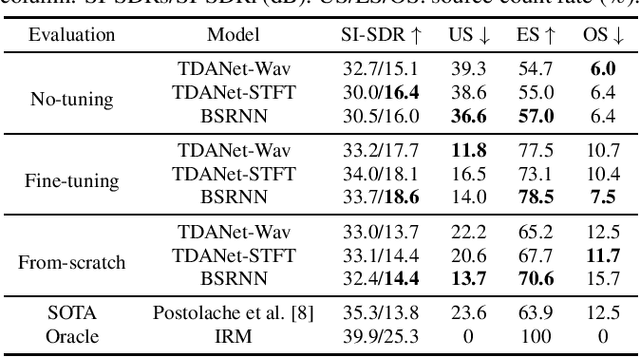
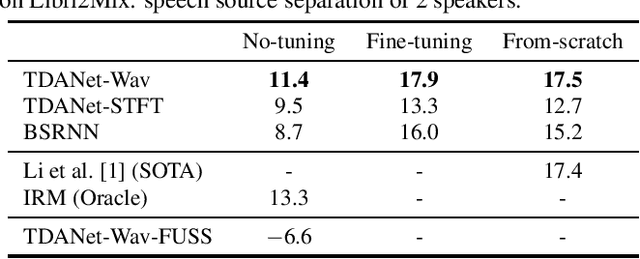
Universal source separation targets at separating the audio sources of an arbitrary mix, removing the constraint to operate on a specific domain like speech or music. Yet, the potential of universal source separation is limited because most existing works focus on mixes with predominantly sound events, and small training datasets also limit its potential for supervised learning. Here, we study a single general audio source separation (GASS) model trained to separate speech, music, and sound events in a supervised fashion with a large-scale dataset. We assess GASS models on a diverse set of tasks. Our strong in-distribution results show the feasibility of GASS models, and the competitive out-of-distribution performance in sound event and speech separation shows its generalization abilities. Yet, it is challenging for GASS models to generalize for separating out-of-distribution cinematic and music content. We also fine-tune GASS models on each dataset and consistently outperform the ones without pre-training. All fine-tuned models (except the music separation one) obtain state-of-the-art results in their respective benchmarks.
End-to-end Multichannel Speaker-Attributed ASR: Speaker Guided Decoder and Input Feature Analysis
Oct 16, 2023We present an end-to-end multichannel speaker-attributed automatic speech recognition (MC-SA-ASR) system that combines a Conformer-based encoder with multi-frame crosschannel attention and a speaker-attributed Transformer-based decoder. To the best of our knowledge, this is the first model that efficiently integrates ASR and speaker identification modules in a multichannel setting. On simulated mixtures of LibriSpeech data, our system reduces the word error rate (WER) by up to 12% and 16% relative compared to previously proposed single-channel and multichannel approaches, respectively. Furthermore, we investigate the impact of different input features, including multichannel magnitude and phase information, on the ASR performance. Finally, our experiments on the AMI corpus confirm the effectiveness of our system for real-world multichannel meeting transcription.
Alzheimer's Disease Detection from Spontaneous Speech and Text: A review
Jul 19, 2023
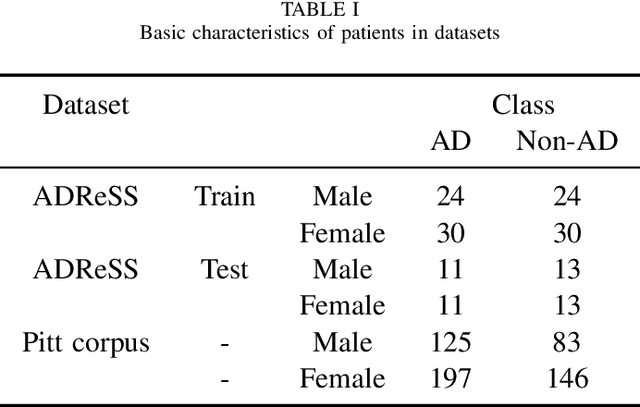
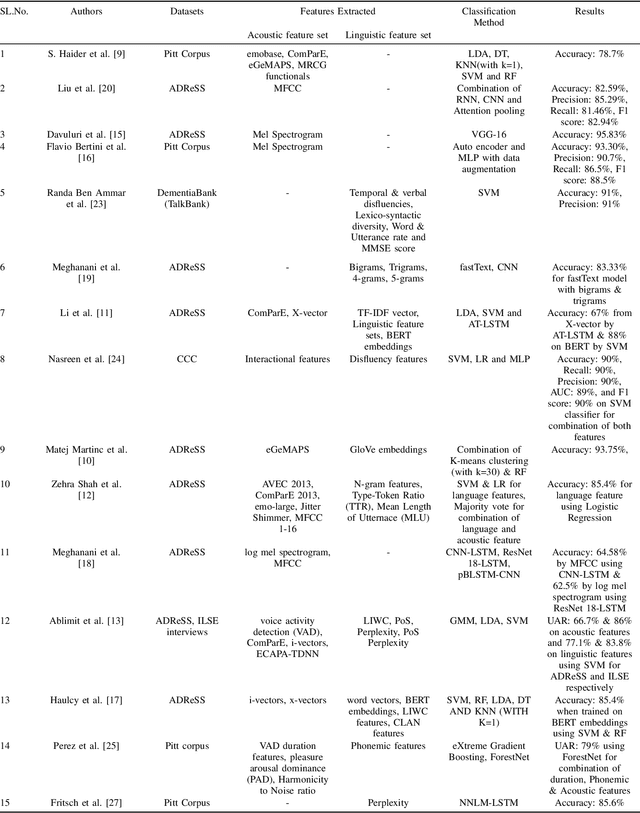
In the past decade, there has been a surge in research examining the use of voice and speech analysis as a means of detecting neurodegenerative diseases such as Alzheimer's. Many studies have shown that certain acoustic features can be used to differentiate between normal aging and Alzheimer's disease, and speech analysis has been found to be a cost-effective method of detecting Alzheimer's dementia. The aim of this review is to analyze the various algorithms used in speech-based detection and classification of Alzheimer's disease. A literature survey was conducted using databases such as Web of Science, Google Scholar, and Science Direct, and articles published from January 2020 to the present were included based on keywords such as ``Alzheimer's detection'', "speech," and "natural language processing." The ADReSS, Pitt corpus, and CCC datasets are commonly used for the analysis of dementia from speech, and this review focuses on the various acoustic and linguistic feature engineering-based classification models drawn from 15 studies. Based on the findings of this study, it appears that a more accurate model for classifying Alzheimer's disease can be developed by considering both linguistic and acoustic data. The review suggests that speech signals can be a useful tool for detecting dementia and may serve as a reliable biomarker for efficiently identifying Alzheimer's disease.
Audio-Visual Speech Enhancement Using Self-supervised Learning to Improve Speech Intelligibility in Cochlear Implant Simulations
Jul 15, 2023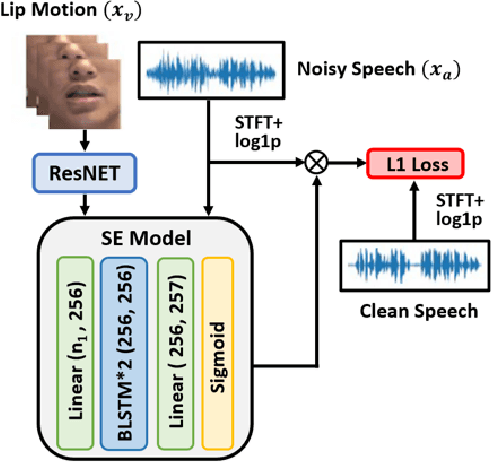
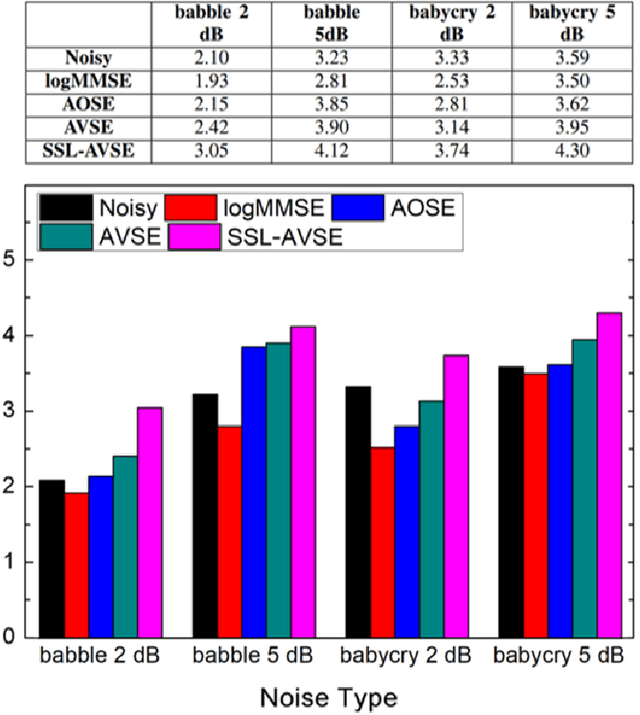
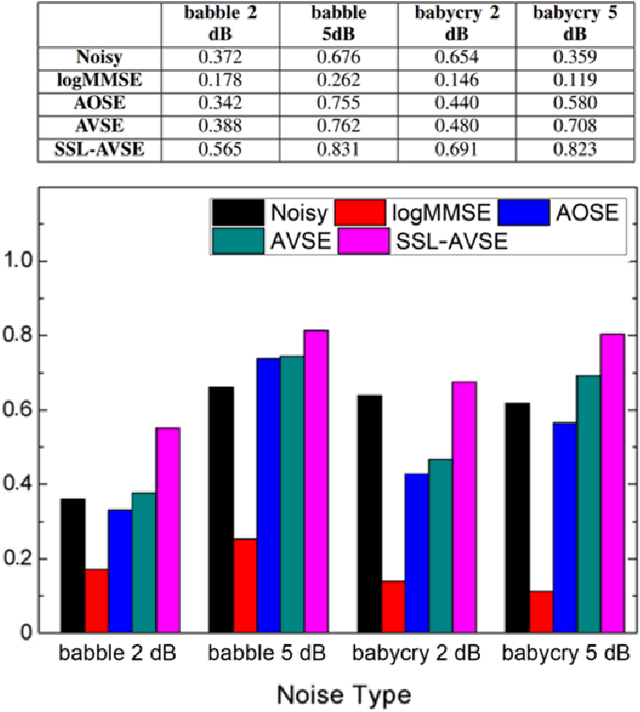
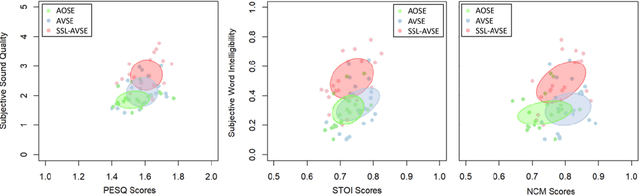
Individuals with hearing impairments face challenges in their ability to comprehend speech, particularly in noisy environments. The aim of this study is to explore the effectiveness of audio-visual speech enhancement (AVSE) in enhancing the intelligibility of vocoded speech in cochlear implant (CI) simulations. Notably, the study focuses on a challenged scenario where there is limited availability of training data for the AVSE task. To address this problem, we propose a novel deep neural network framework termed Self-Supervised Learning-based AVSE (SSL-AVSE). The proposed SSL-AVSE combines visual cues, such as lip and mouth movements, from the target speakers with corresponding audio signals. The contextually combined audio and visual data are then fed into a Transformer-based SSL AV-HuBERT model to extract features, which are further processed using a BLSTM-based SE model. The results demonstrate several key findings. Firstly, SSL-AVSE successfully overcomes the issue of limited data by leveraging the AV-HuBERT model. Secondly, by fine-tuning the AV-HuBERT model parameters for the target SE task, significant performance improvements are achieved. Specifically, there is a notable enhancement in PESQ (Perceptual Evaluation of Speech Quality) from 1.43 to 1.67 and in STOI (Short-Time Objective Intelligibility) from 0.70 to 0.74. Furthermore, the performance of the SSL-AVSE was evaluated using CI vocoded speech to assess the intelligibility for CI users. Comparative experimental outcomes reveal that in the presence of dynamic noises encountered during human conversations, SSL-AVSE exhibits a substantial improvement. The NCM (Normal Correlation Matrix) values indicate an increase of 26.5% to 87.2% compared to the noisy baseline.