 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Reproducing Whisper-Style Training Using an Open-Source Toolkit and Publicly Available Data
Oct 02, 2023
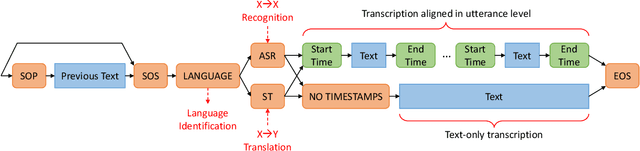
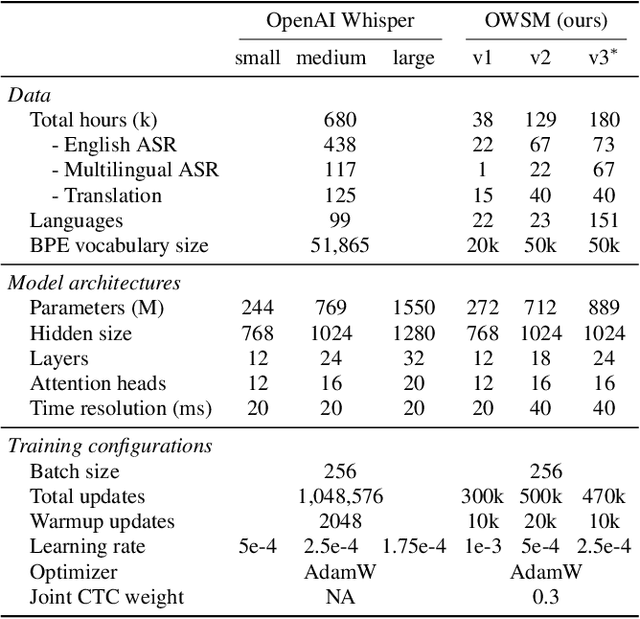
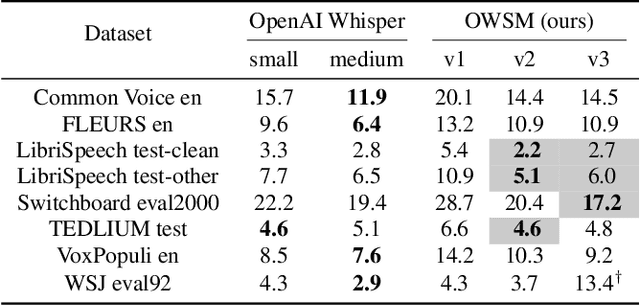
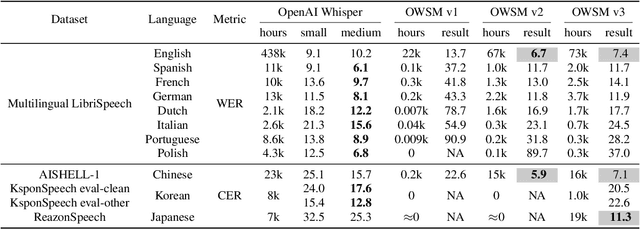
Pre-training speech models on large volumes of data has achieved remarkable success. OpenAI Whisper is a multilingual multitask model trained on 680k hours of supervised speech data. It generalizes well to various speech recognition and translation benchmarks even in a zero-shot setup. However, the full pipeline for developing such models (from data collection to training) is not publicly accessible, which makes it difficult for researchers to further improve its performance and address training-related issues such as efficiency, robustness, fairness, and bias. This work presents an Open Whisper-style Speech Model (OWSM), which reproduces Whisper-style training using an open-source toolkit and publicly available data. OWSM even supports more translation directions and can be more efficient to train. We will publicly release all scripts used for data preparation, training, inference, and scoring as well as pre-trained models and training logs to promote open science.
Dual-path Transformer Based Neural Beamformer for Target Speech Extraction
Sep 07, 2023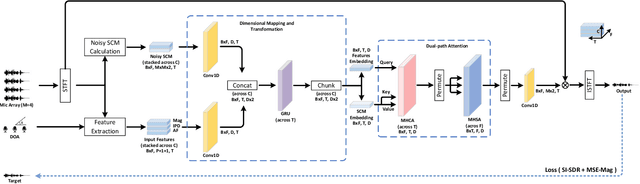
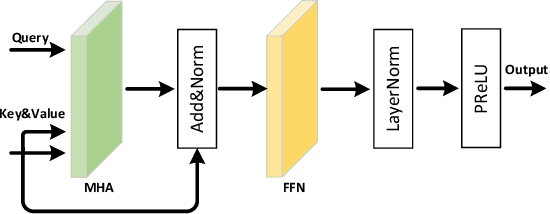
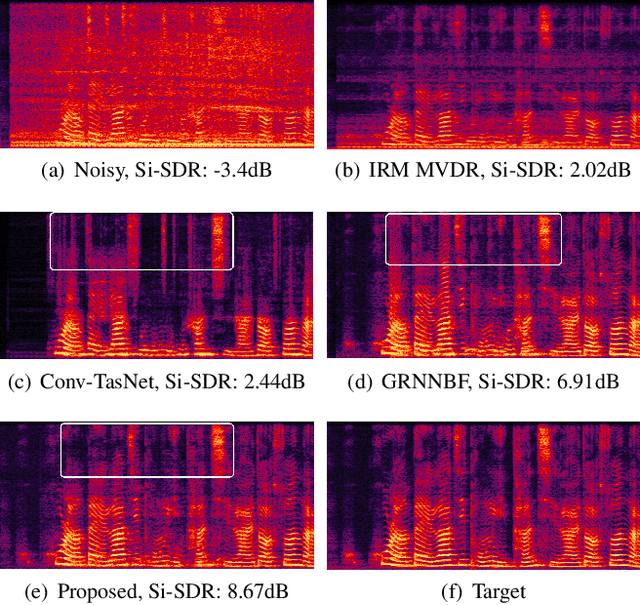
Neural beamformers, which integrate both pre-separation and beamforming modules, have demonstrated impressive effectiveness in target speech extraction. Nevertheless, the performance of these beamformers is inherently limited by the predictive accuracy of the pre-separation module. In this paper, we introduce a neural beamformer supported by a dual-path transformer. Initially, we employ the cross-attention mechanism in the time domain to extract crucial spatial information related to beamforming from the noisy covariance matrix. Subsequently, in the frequency domain, the self-attention mechanism is employed to enhance the model's ability to process frequency-specific details. By design, our model circumvents the influence of pre-separation modules, delivering performance in a more comprehensive end-to-end manner. Experimental results reveal that our model not only outperforms contemporary leading neural beamforming algorithms in separation performance but also achieves this with a significant reduction in parameter count.
Co-Speech Gesture Detection through Multi-phase Sequence Labeling
Aug 21, 2023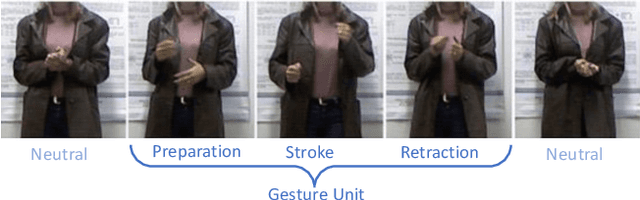
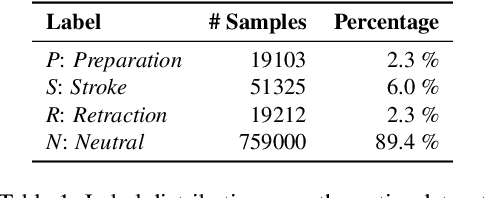

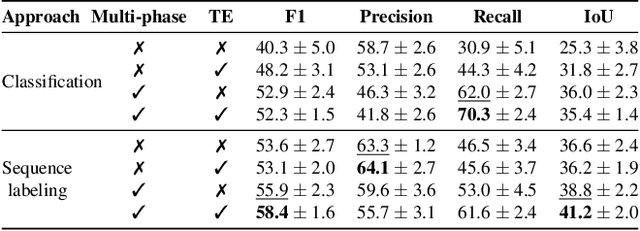
Gestures are integral components of face-to-face communication. They unfold over time, often following predictable movement phases of preparation, stroke, and retraction. Yet, the prevalent approach to automatic gesture detection treats the problem as binary classification, classifying a segment as either containing a gesture or not, thus failing to capture its inherently sequential and contextual nature. To address this, we introduce a novel framework that reframes the task as a multi-phase sequence labeling problem rather than binary classification. Our model processes sequences of skeletal movements over time windows, uses Transformer encoders to learn contextual embeddings, and leverages Conditional Random Fields to perform sequence labeling. We evaluate our proposal on a large dataset of diverse co-speech gestures in task-oriented face-to-face dialogues. The results consistently demonstrate that our method significantly outperforms strong baseline models in detecting gesture strokes. Furthermore, applying Transformer encoders to learn contextual embeddings from movement sequences substantially improves gesture unit detection. These results highlight our framework's capacity to capture the fine-grained dynamics of co-speech gesture phases, paving the way for more nuanced and accurate gesture detection and analysis.
DiCLET-TTS: Diffusion Model based Cross-lingual Emotion Transfer for Text-to-Speech -- A Study between English and Mandarin
Sep 02, 2023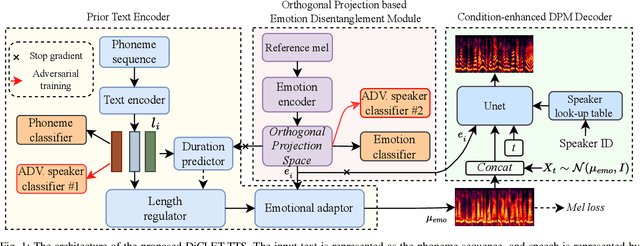
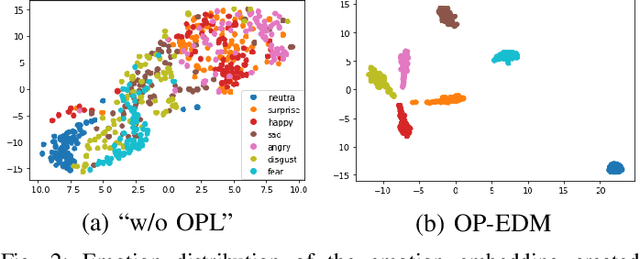
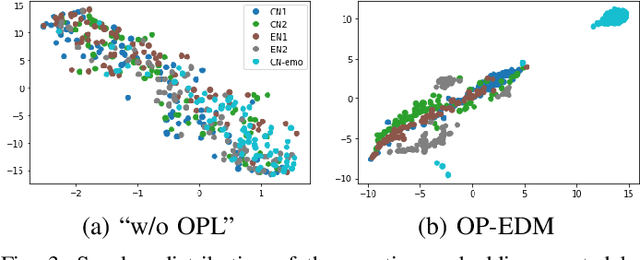
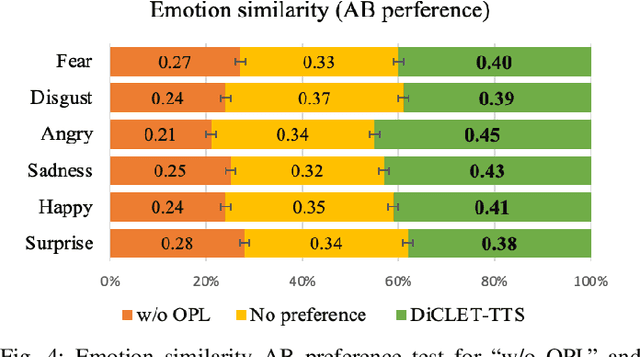
While the performance of cross-lingual TTS based on monolingual corpora has been significantly improved recently, generating cross-lingual speech still suffers from the foreign accent problem, leading to limited naturalness. Besides, current cross-lingual methods ignore modeling emotion, which is indispensable paralinguistic information in speech delivery. In this paper, we propose DiCLET-TTS, a Diffusion model based Cross-Lingual Emotion Transfer method that can transfer emotion from a source speaker to the intra- and cross-lingual target speakers. Specifically, to relieve the foreign accent problem while improving the emotion expressiveness, the terminal distribution of the forward diffusion process is parameterized into a speaker-irrelevant but emotion-related linguistic prior by a prior text encoder with the emotion embedding as a condition. To address the weaker emotional expressiveness problem caused by speaker disentanglement in emotion embedding, a novel orthogonal projection based emotion disentangling module (OP-EDM) is proposed to learn the speaker-irrelevant but emotion-discriminative embedding. Moreover, a condition-enhanced DPM decoder is introduced to strengthen the modeling ability of the speaker and the emotion in the reverse diffusion process to further improve emotion expressiveness in speech delivery. Cross-lingual emotion transfer experiments show the superiority of DiCLET-TTS over various competitive models and the good design of OP-EDM in learning speaker-irrelevant but emotion-discriminative embedding.
Pre-training End-to-end ASR Models with Augmented Speech Samples Queried by Text
Jul 30, 2023In end-to-end automatic speech recognition system, one of the difficulties for language expansion is the limited paired speech and text training data. In this paper, we propose a novel method to generate augmented samples with unpaired speech feature segments and text data for model pre-training, which has the advantage of low cost without using additional speech data. When mixing 20,000 hours augmented speech data generated by our method with 12,500 hours original transcribed speech data for Italian Transformer transducer model pre-training, we achieve 8.7% relative word error rate reduction. The pre-trained model achieves similar performance as the model pre-trained with multilingual transcribed 75,000 hours raw speech data. When merging the augmented speech data with the multilingual data to pre-train a new model, we achieve even more relative word error rate reduction of 12.2% over the baseline, which further verifies the effectiveness of our method for speech data augmentation.
PILL: Plug Into LLM with Adapter Expert and Attention Gate
Nov 03, 2023Due to the remarkable capabilities of powerful Large Language Models (LLMs) in effectively following instructions, there has been a growing number of assistants in the community to assist humans. Recently, significant progress has been made in the development of Vision Language Models (VLMs), expanding the capabilities of LLMs and enabling them to execute more diverse instructions. However, it is foreseeable that models will likely need to handle tasks involving additional modalities such as speech, video, and others. This poses a particularly prominent challenge of dealing with the complexity of mixed modalities. To address this, we introduce a novel architecture called PILL: Plug Into LLM with adapter expert and attention gate to better decouple these complex modalities and leverage efficient fine-tuning. We introduce two modules: Firstly, utilizing Mixture-of-Modality-Adapter-Expert to independently handle different modalities, enabling better adaptation to downstream tasks while preserving the expressive capability of the original model. Secondly, by introducing Modality-Attention-Gating, which enables adaptive control of the contribution of modality tokens to the overall representation. In addition, we have made improvements to the Adapter to enhance its learning and expressive capabilities. Experimental results demonstrate that our approach exhibits competitive performance compared to other mainstream methods for modality fusion. For researchers interested in our work, we provide free access to the code and models at https://github.com/DsaltYfish/PILL.
PolyVoice: Language Models for Speech to Speech Translation
Jun 13, 2023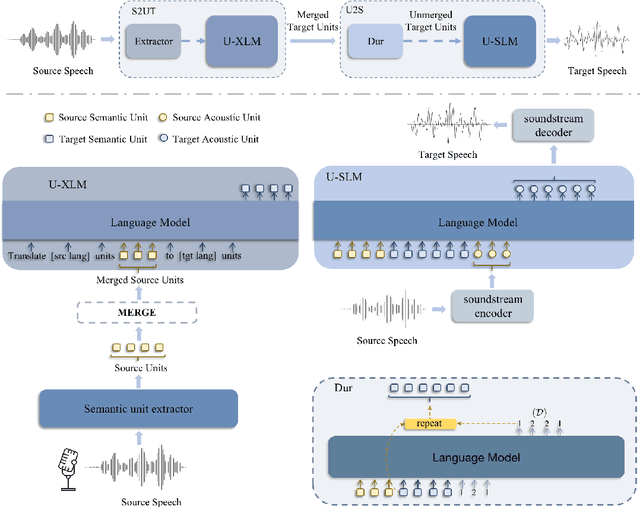

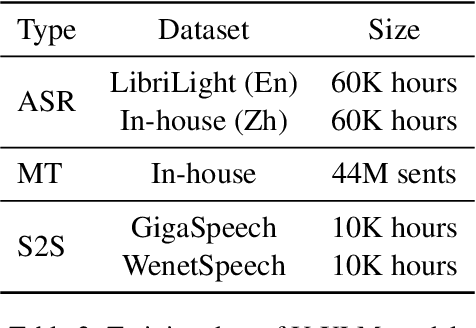
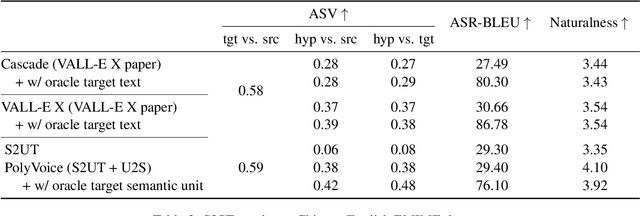
We propose PolyVoice, a language model-based framework for speech-to-speech translation (S2ST) system. Our framework consists of two language models: a translation language model and a speech synthesis language model. We use discretized speech units, which are generated in a fully unsupervised way, and thus our framework can be used for unwritten languages. For the speech synthesis part, we adopt the existing VALL-E X approach and build a unit-based audio language model. This grants our framework the ability to preserve the voice characteristics and the speaking style of the original speech. We examine our system on Chinese $\rightarrow$ English and English $\rightarrow$ Spanish pairs. Experimental results show that our system can generate speech with high translation quality and audio quality. Speech samples are available at https://speechtranslation.github.io/polyvoice.
Mispronunciation detection using self-supervised speech representations
Jul 30, 2023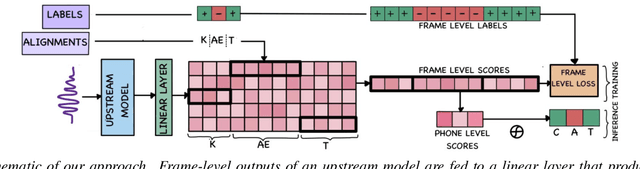
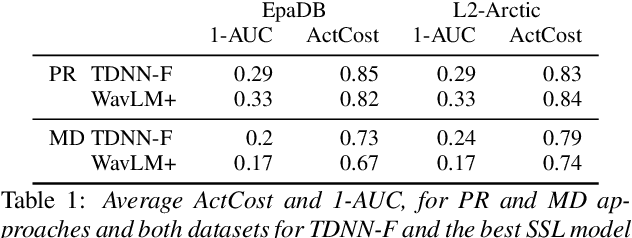
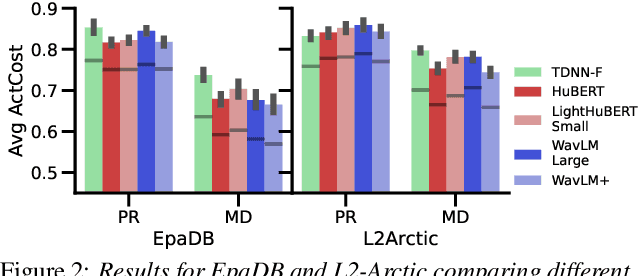
In recent years, self-supervised learning (SSL) models have produced promising results in a variety of speech-processing tasks, especially in contexts of data scarcity. In this paper, we study the use of SSL models for the task of mispronunciation detection for second language learners. We compare two downstream approaches: 1) training the model for phone recognition (PR) using native English data, and 2) training a model directly for the target task using non-native English data. We compare the performance of these two approaches for various SSL representations as well as a representation extracted from a traditional DNN-based speech recognition model. We evaluate the models on L2Arctic and EpaDB, two datasets of non-native speech annotated with pronunciation labels at the phone level. Overall, we find that using a downstream model trained for the target task gives the best performance and that most upstream models perform similarly for the task.
Mi-Go: Test Framework which uses YouTube as Data Source for Evaluating Speech Recognition Models like OpenAI's Whisper
Sep 01, 2023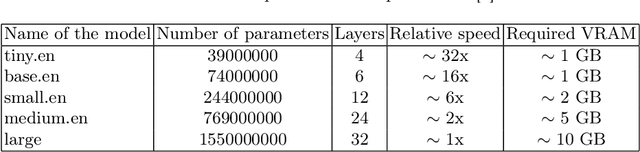
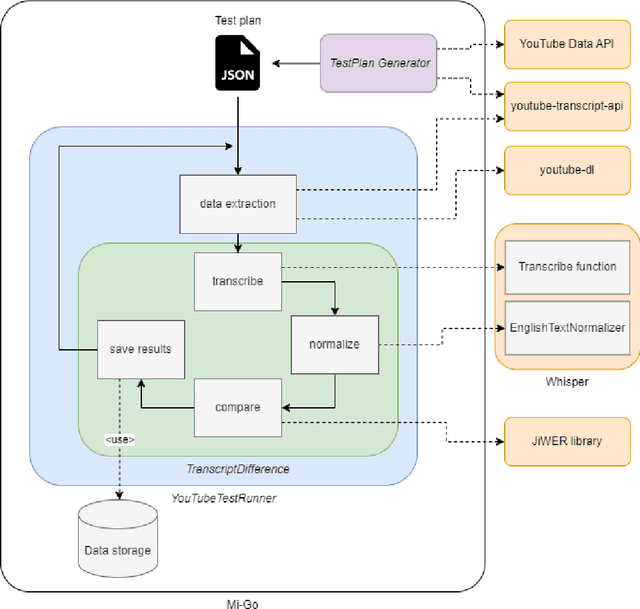
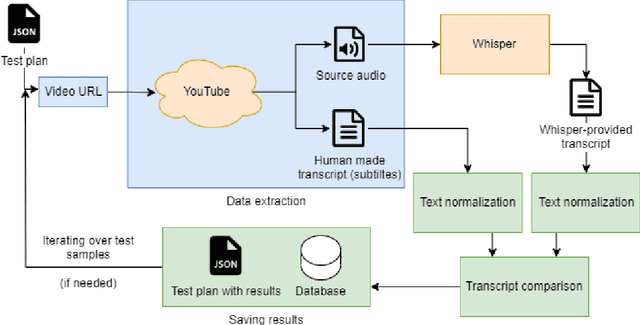
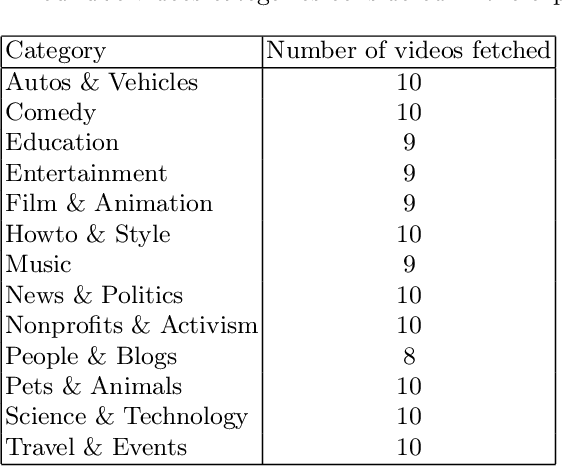
This article introduces Mi-Go, a novel testing framework aimed at evaluating the performance and adaptability of general-purpose speech recognition machine learning models across diverse real-world scenarios. The framework leverages YouTube as a rich and continuously updated data source, accounting for multiple languages, accents, dialects, speaking styles, and audio quality levels. To demonstrate the effectiveness of the framework, the Whisper model, developed by OpenAI, was employed as a test object. The tests involve using a total of 124 YouTube videos to test all Whisper model versions. The results underscore the utility of YouTube as a valuable testing platform for speech recognition models, ensuring their robustness, accuracy, and adaptability to diverse languages and acoustic conditions. Additionally, by contrasting the machine-generated transcriptions against human-made subtitles, the Mi-Go framework can help pinpoint potential misuse of YouTube subtitles, like Search Engine Optimization.
ChiSCor: A Corpus of Freely Told Fantasy Stories by Dutch Children for Computational Linguistics and Cognitive Science
Oct 31, 2023In this resource paper we release ChiSCor, a new corpus containing 619 fantasy stories, told freely by 442 Dutch children aged 4-12. ChiSCor was compiled for studying how children render character perspectives, and unravelling language and cognition in development, with computational tools. Unlike existing resources, ChiSCor's stories were produced in natural contexts, in line with recent calls for more ecologically valid datasets. ChiSCor hosts text, audio, and annotations for character complexity and linguistic complexity. Additional metadata (e.g. education of caregivers) is available for one third of the Dutch children. ChiSCor also includes a small set of 62 English stories. This paper details how ChiSCor was compiled and shows its potential for future work with three brief case studies: i) we show that the syntactic complexity of stories is strikingly stable across children's ages; ii) we extend work on Zipfian distributions in free speech and show that ChiSCor obeys Zipf's law closely, reflecting its social context; iii) we show that even though ChiSCor is relatively small, the corpus is rich enough to train informative lemma vectors that allow us to analyse children's language use. We end with a reflection on the value of narrative datasets in computational linguistics.