 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Audio-Visual Neural Syntax Acquisition
Oct 11, 2023
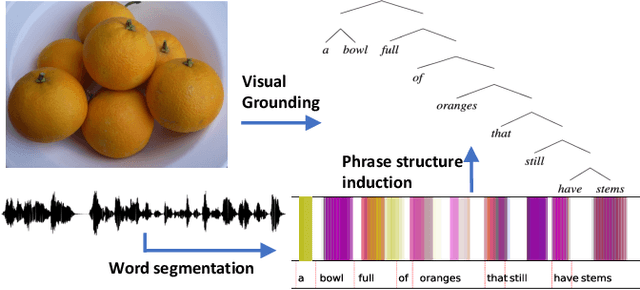

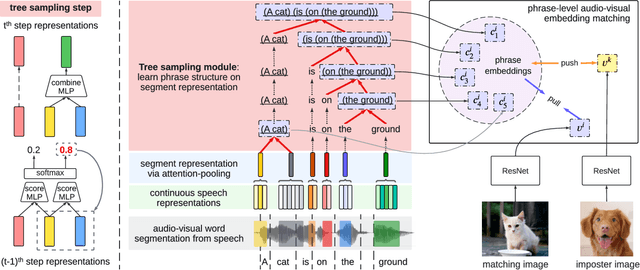
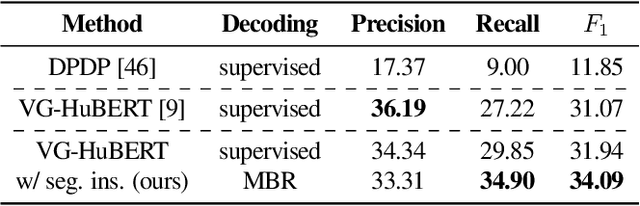
We study phrase structure induction from visually-grounded speech. The core idea is to first segment the speech waveform into sequences of word segments, and subsequently induce phrase structure using the inferred segment-level continuous representations. We present the Audio-Visual Neural Syntax Learner (AV-NSL) that learns phrase structure by listening to audio and looking at images, without ever being exposed to text. By training on paired images and spoken captions, AV-NSL exhibits the capability to infer meaningful phrase structures that are comparable to those derived by naturally-supervised text parsers, for both English and German. Our findings extend prior work in unsupervised language acquisition from speech and grounded grammar induction, and present one approach to bridge the gap between the two topics.
MyVoice: Arabic Speech Resource Collaboration Platform
Jul 23, 2023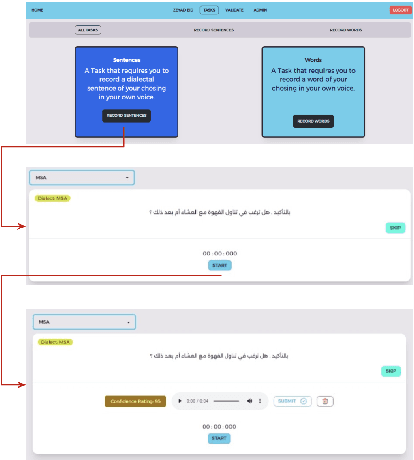
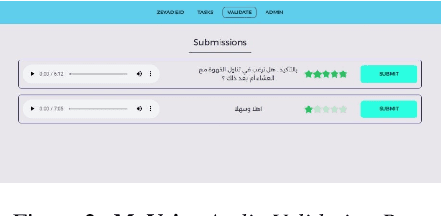
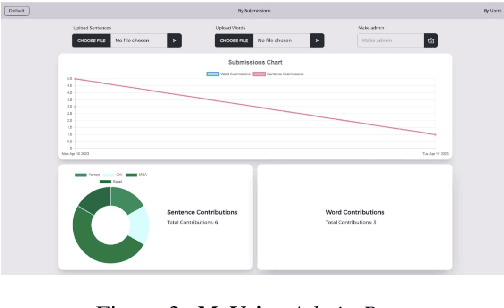
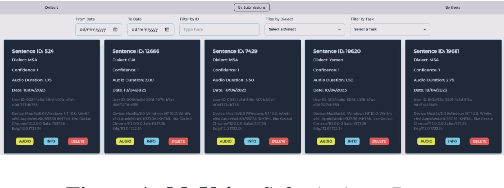
We introduce MyVoice, a crowdsourcing platform designed to collect Arabic speech to enhance dialectal speech technologies. This platform offers an opportunity to design large dialectal speech datasets; and makes them publicly available. MyVoice allows contributors to select city/country-level fine-grained dialect and record the displayed utterances. Users can switch roles between contributors and annotators. The platform incorporates a quality assurance system that filters out low-quality and spurious recordings before sending them for validation. During the validation phase, contributors can assess the quality of recordings, annotate them, and provide feedback which is then reviewed by administrators. Furthermore, the platform offers flexibility to admin roles to add new data or tasks beyond dialectal speech and word collection, which are displayed to contributors. Thus, enabling collaborative efforts in gathering diverse and large Arabic speech data.
Causality Guided Disentanglement for Cross-Platform Hate Speech Detection
Aug 10, 2023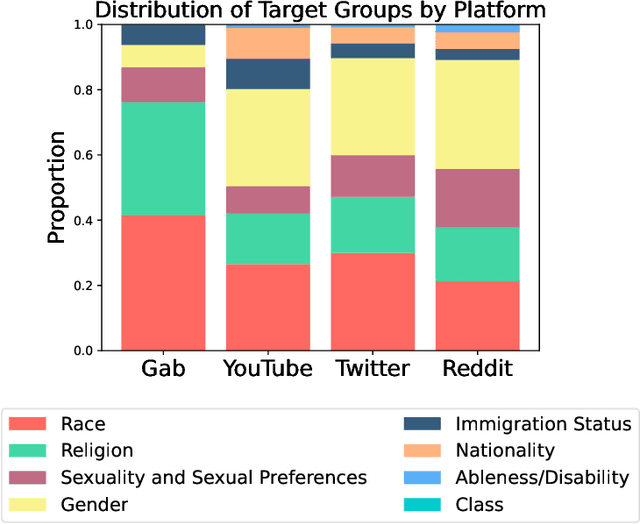
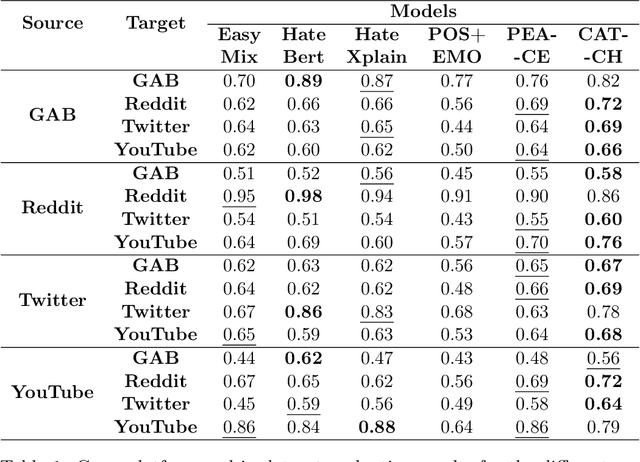
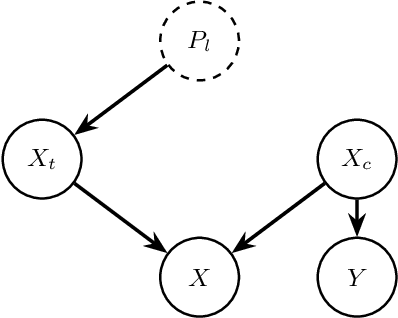
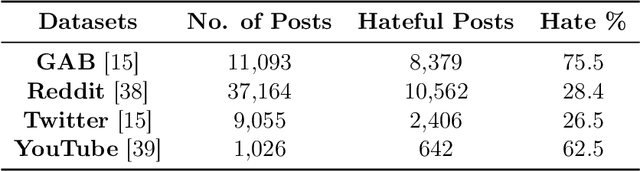
Social media platforms, despite their value in promoting open discourse, are often exploited to spread harmful content. Current deep learning and natural language processing models used for detecting this harmful content overly rely on domain-specific terms affecting their capabilities to adapt to generalizable hate speech detection. This is because they tend to focus too narrowly on particular linguistic signals or the use of certain categories of words. Another significant challenge arises when platforms lack high-quality annotated data for training, leading to a need for cross-platform models that can adapt to different distribution shifts. Our research introduces a cross-platform hate speech detection model capable of being trained on one platform's data and generalizing to multiple unseen platforms. To achieve good generalizability across platforms, one way is to disentangle the input representations into invariant and platform-dependent features. We also argue that learning causal relationships, which remain constant across diverse environments, can significantly aid in understanding invariant representations in hate speech. By disentangling input into platform-dependent features (useful for predicting hate targets) and platform-independent features (used to predict the presence of hate), we learn invariant representations resistant to distribution shifts. These features are then used to predict hate speech across unseen platforms. Our extensive experiments across four platforms highlight our model's enhanced efficacy compared to existing state-of-the-art methods in detecting generalized hate speech.
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Aug 11, 2023
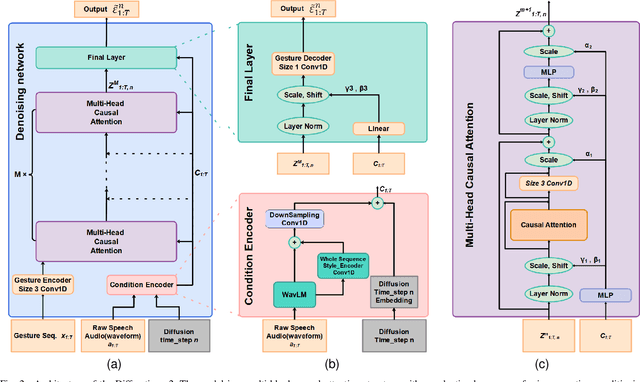
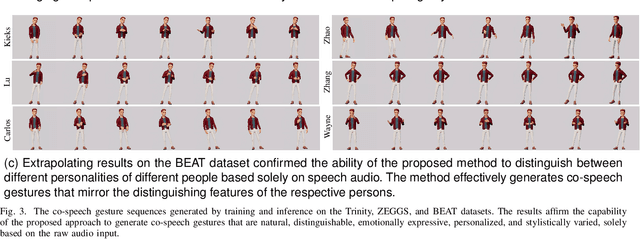
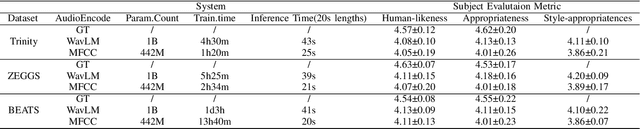
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces "diffmotion-v2," a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
Audio-visual video-to-speech synthesis with synthesized input audio
Jul 31, 2023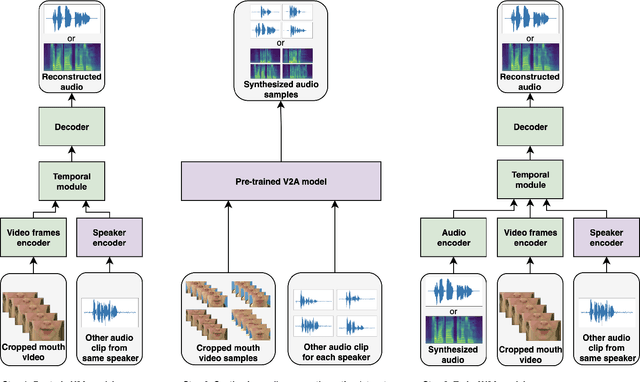
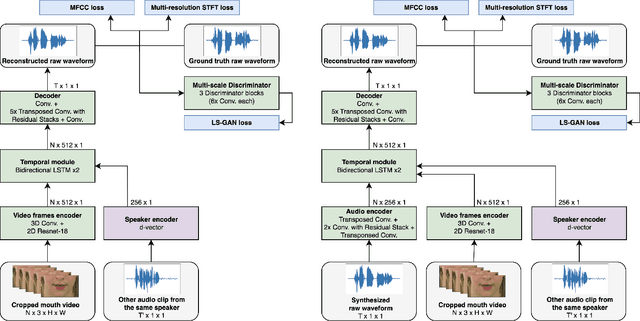
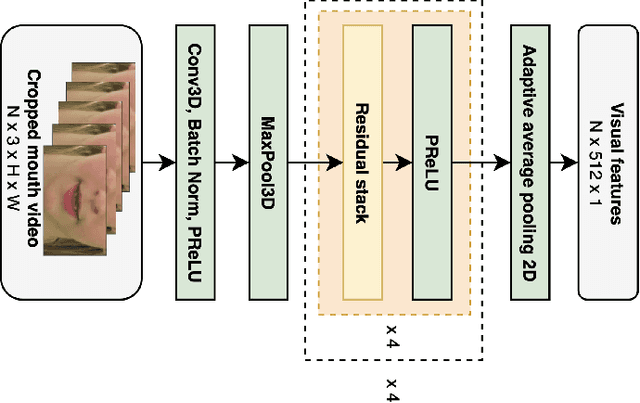
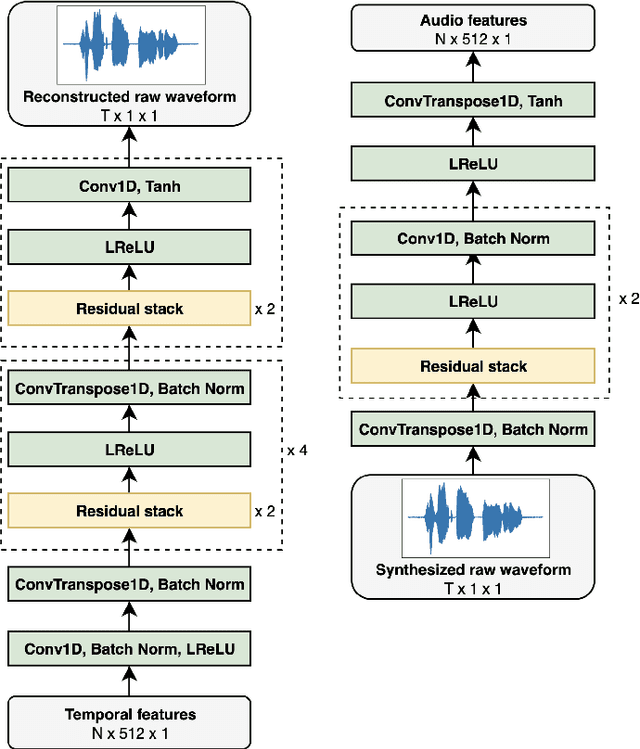
Video-to-speech synthesis involves reconstructing the speech signal of a speaker from a silent video. The implicit assumption of this task is that the sound signal is either missing or contains a high amount of noise/corruption such that it is not useful for processing. Previous works in the literature either use video inputs only or employ both video and audio inputs during training, and discard the input audio pathway during inference. In this work we investigate the effect of using video and audio inputs for video-to-speech synthesis during both training and inference. In particular, we use pre-trained video-to-speech models to synthesize the missing speech signals and then train an audio-visual-to-speech synthesis model, using both the silent video and the synthesized speech as inputs, to predict the final reconstructed speech. Our experiments demonstrate that this approach is successful with both raw waveforms and mel spectrograms as target outputs.
SGGNet$^2$: Speech-Scene Graph Grounding Network for Speech-guided Navigation
Jul 14, 2023
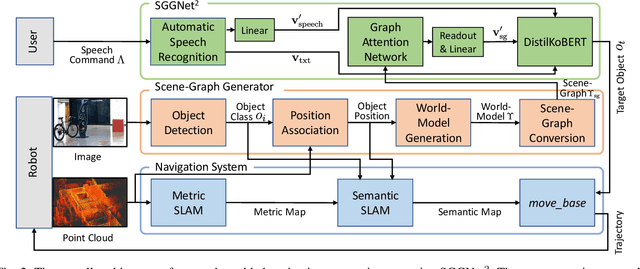
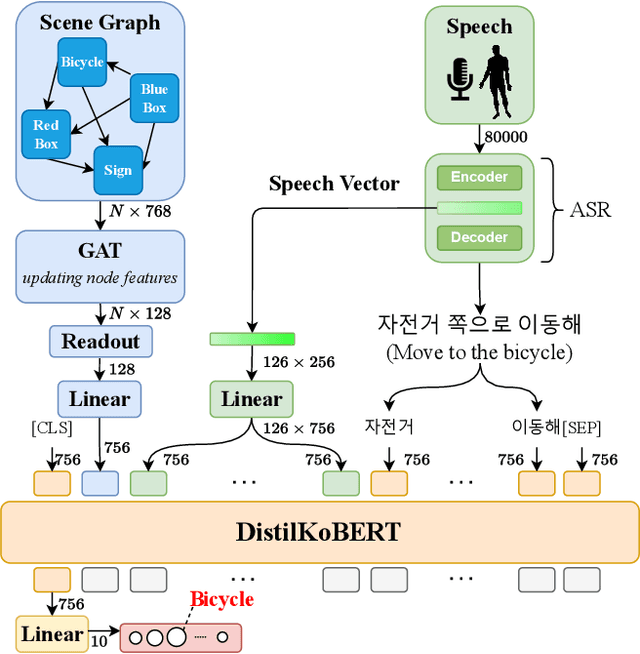

The spoken language serves as an accessible and efficient interface, enabling non-experts and disabled users to interact with complex assistant robots. However, accurately grounding language utterances gives a significant challenge due to the acoustic variability in speakers' voices and environmental noise. In this work, we propose a novel speech-scene graph grounding network (SGGNet$^2$) that robustly grounds spoken utterances by leveraging the acoustic similarity between correctly recognized and misrecognized words obtained from automatic speech recognition (ASR) systems. To incorporate the acoustic similarity, we extend our previous grounding model, the scene-graph-based grounding network (SGGNet), with the ASR model from NVIDIA NeMo. We accomplish this by feeding the latent vector of speech pronunciations into the BERT-based grounding network within SGGNet. We evaluate the effectiveness of using latent vectors of speech commands in grounding through qualitative and quantitative studies. We also demonstrate the capability of SGGNet$^2$ in a speech-based navigation task using a real quadruped robot, RBQ-3, from Rainbow Robotics.
Thesis Distillation: Investigating The Impact of Bias in NLP Models on Hate Speech Detection
Aug 31, 2023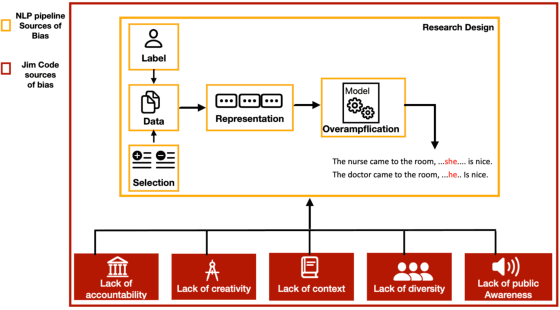
This paper is a summary of the work in my PhD thesis. In which, I investigate the impact of bias in NLP models on the task of hate speech detection from three perspectives: explainability, offensive stereotyping bias, and fairness. I discuss the main takeaways from my thesis and how they can benefit the broader NLP community. Finally, I discuss important future research directions. The findings of my thesis suggest that bias in NLP models impacts the task of hate speech detection from all three perspectives. And that unless we start incorporating social sciences in studying bias in NLP models, we will not effectively overcome the current limitations of measuring and mitigating bias in NLP models.
BanLemma: A Word Formation Dependent Rule and Dictionary Based Bangla Lemmatizer
Nov 06, 2023Lemmatization holds significance in both natural language processing (NLP) and linguistics, as it effectively decreases data density and aids in comprehending contextual meaning. However, due to the highly inflected nature and morphological richness, lemmatization in Bangla text poses a complex challenge. In this study, we propose linguistic rules for lemmatization and utilize a dictionary along with the rules to design a lemmatizer specifically for Bangla. Our system aims to lemmatize words based on their parts of speech class within a given sentence. Unlike previous rule-based approaches, we analyzed the suffix marker occurrence according to the morpho-syntactic values and then utilized sequences of suffix markers instead of entire suffixes. To develop our rules, we analyze a large corpus of Bangla text from various domains, sources, and time periods to observe the word formation of inflected words. The lemmatizer achieves an accuracy of 96.36% when tested against a manually annotated test dataset by trained linguists and demonstrates competitive performance on three previously published Bangla lemmatization datasets. We are making the code and datasets publicly available at https://github.com/eblict-gigatech/BanLemma in order to contribute to the further advancement of Bangla NLP.
Monaural Multi-Speaker Speech Separation Using Efficient Transformer Model
Jul 29, 2023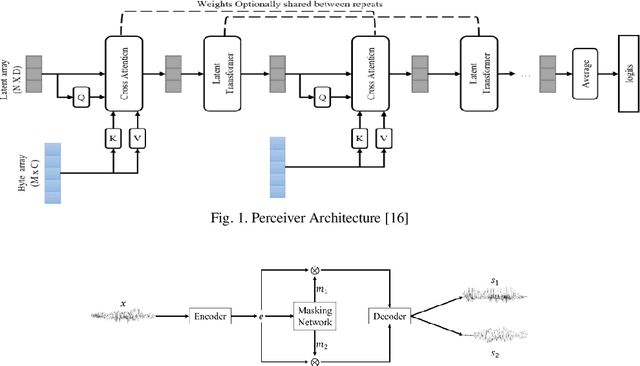
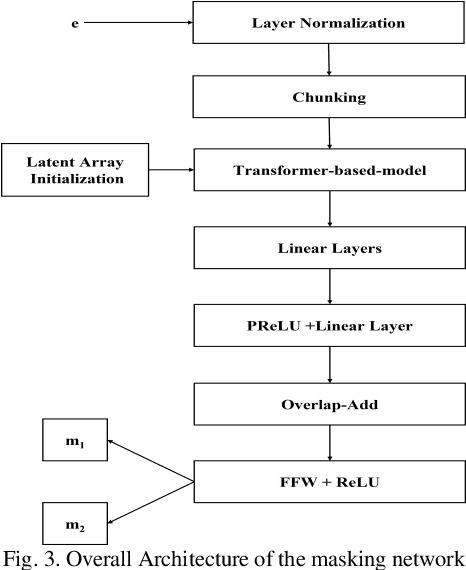
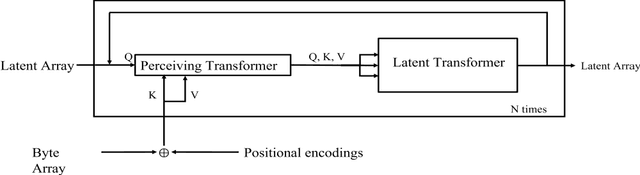
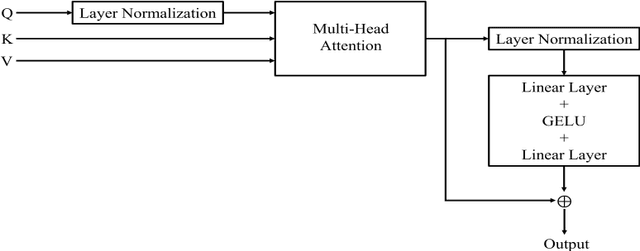
Cocktail party problem is the scenario where it is difficult to separate or distinguish individual speaker from a mixed speech from several speakers. There have been several researches going on in this field but the size and complexity of the model is being traded off with the accuracy and robustness of speech separation. "Monaural multi-speaker speech separation" presents a speech-separation model based on the Transformer architecture and its efficient forms. The model has been trained with the LibriMix dataset containing diverse speakers' utterances. The model separates 2 distinct speaker sources from a mixed audio input. The developed model approaches the reduction in computational complexity of the speech separation model, with minimum tradeoff with the performance of prevalent speech separation model and it has shown significant movement towards that goal. This project foresees, a rise in contribution towards the ongoing research in the field of speech separation with computational efficiency at its core.
Indonesian Automatic Speech Recognition with XLSR-53
Aug 20, 2023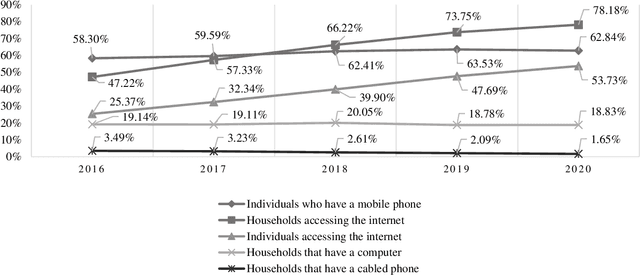
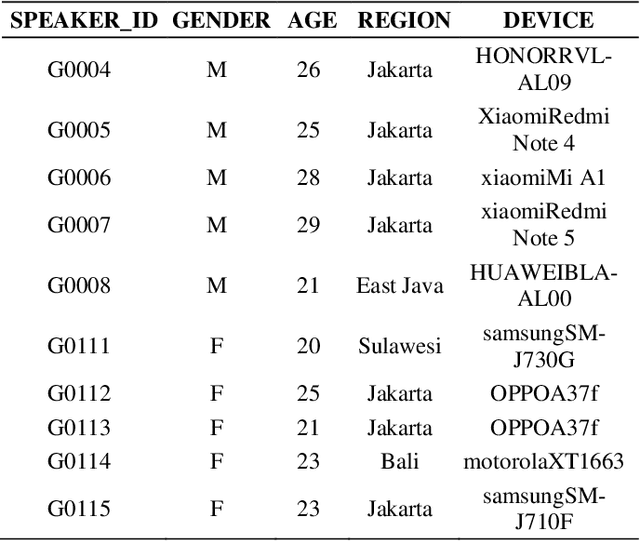
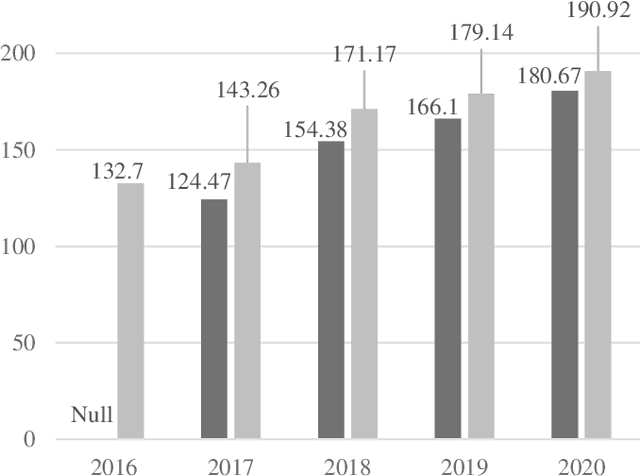
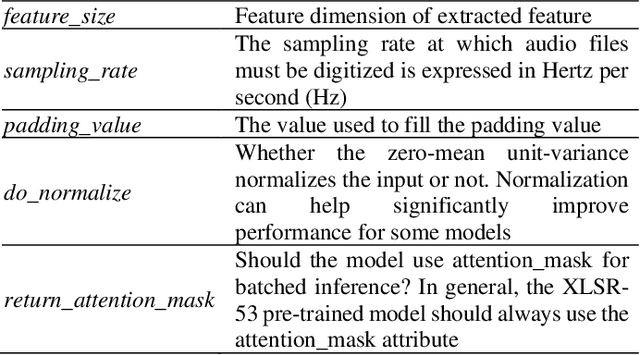
This study focuses on the development of Indonesian Automatic Speech Recognition (ASR) using the XLSR-53 pre-trained model, the XLSR stands for cross-lingual speech representations. The use of this XLSR-53 pre-trained model is to significantly reduce the amount of training data in non-English languages required to achieve a competitive Word Error Rate (WER). The total amount of data used in this study is 24 hours, 18 minutes, and 1 second: (1) TITML-IDN 14 hours and 31 minutes; (2) Magic Data 3 hours and 33 minutes; and (3) Common Voice 6 hours, 14 minutes, and 1 second. With a WER of 20%, the model built in this study can compete with similar models using the Common Voice dataset split test. WER can be decreased by around 8% using a language model, resulted in WER from 20% to 12%. Thus, the results of this study have succeeded in perfecting previous research in contributing to the creation of a better Indonesian ASR with a smaller amount of data.