 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
CPPF: A contextual and post-processing-free model for automatic speech recognition
Sep 14, 2023
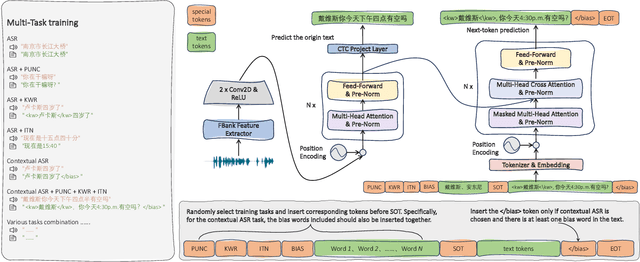
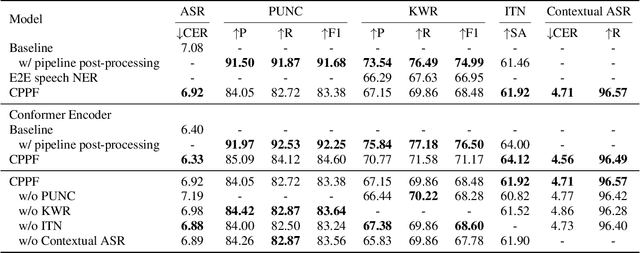

ASR systems have become increasingly widespread in recent years. However, their textual outputs often require post-processing tasks before they can be practically utilized. To address this issue, we draw inspiration from the multifaceted capabilities of LLMs and Whisper, and focus on integrating multiple ASR text processing tasks related to speech recognition into the ASR model. This integration not only shortens the multi-stage pipeline, but also prevents the propagation of cascading errors, resulting in direct generation of post-processed text. In this study, we focus on ASR-related processing tasks, including Contextual ASR and multiple ASR post processing tasks. To achieve this objective, we introduce the CPPF model, which offers a versatile and highly effective alternative to ASR processing. CPPF seamlessly integrates these tasks without any significant loss in recognition performance.
Monaural Multi-Speaker Speech Separation Using Efficient Transformer Model
Jul 29, 2023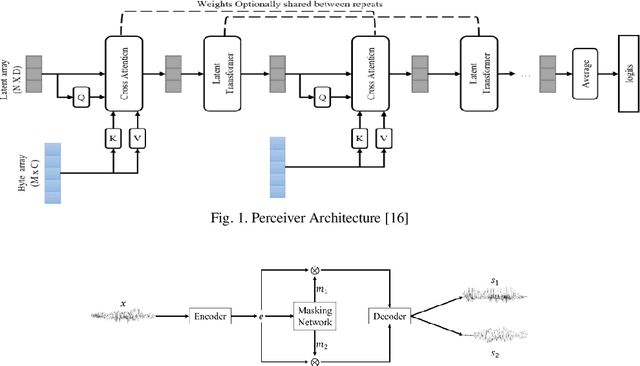
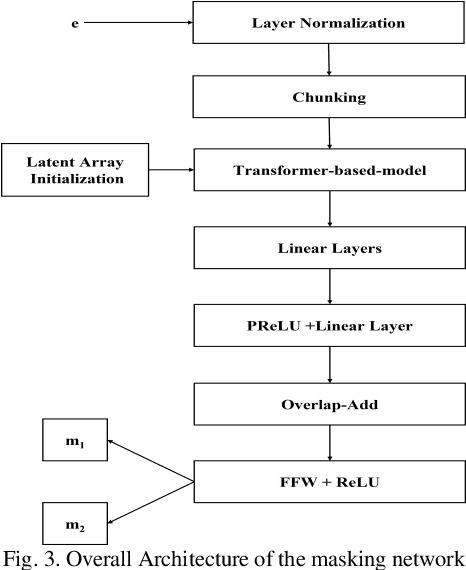
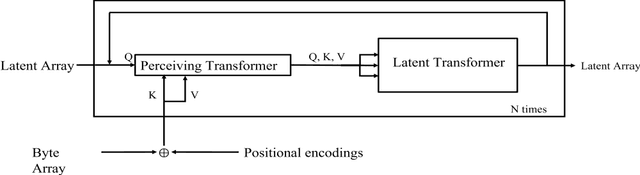
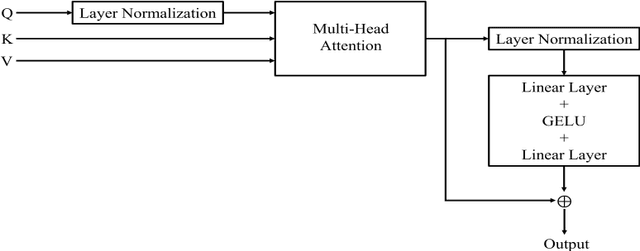
Cocktail party problem is the scenario where it is difficult to separate or distinguish individual speaker from a mixed speech from several speakers. There have been several researches going on in this field but the size and complexity of the model is being traded off with the accuracy and robustness of speech separation. "Monaural multi-speaker speech separation" presents a speech-separation model based on the Transformer architecture and its efficient forms. The model has been trained with the LibriMix dataset containing diverse speakers' utterances. The model separates 2 distinct speaker sources from a mixed audio input. The developed model approaches the reduction in computational complexity of the speech separation model, with minimum tradeoff with the performance of prevalent speech separation model and it has shown significant movement towards that goal. This project foresees, a rise in contribution towards the ongoing research in the field of speech separation with computational efficiency at its core.
Prosody Analysis of Audiobooks
Oct 10, 2023Recent advances in text-to-speech have made it possible to generate natural-sounding audio from text. However, audiobook narrations involve dramatic vocalizations and intonations by the reader, with greater reliance on emotions, dialogues, and descriptions in the narrative. Using our dataset of 93 aligned book-audiobook pairs, we present improved models for prosody prediction properties (pitch, volume, and rate of speech) from narrative text using language modeling. Our predicted prosody attributes correlate much better with human audiobook readings than results from a state-of-the-art commercial TTS system: our predicted pitch shows a higher correlation with human reading for 22 out of the 24 books, while our predicted volume attribute proves more similar to human reading for 23 out of the 24 books. Finally, we present a human evaluation study to quantify the extent that people prefer prosody-enhanced audiobook readings over commercial text-to-speech systems.
Task-Agnostic Low-Rank Adapters for Unseen English Dialects
Nov 02, 2023Large Language Models (LLMs) are trained on corpora disproportionally weighted in favor of Standard American English. As a result, speakers of other dialects experience significantly more failures when interacting with these technologies. In practice, these speakers often accommodate their speech to be better understood. Our work shares the belief that language technologies should be designed to accommodate the diversity in English dialects and not the other way around. However, prior works on dialect struggle with generalizing to evolving and emerging dialects in a scalable manner. To fill this gap, our method, HyperLoRA, leverages expert linguistic knowledge to enable resource-efficient adaptation via hypernetworks. By disentangling dialect-specific and cross-dialectal information, HyperLoRA improves generalization to unseen dialects in a task-agnostic fashion. Not only is HyperLoRA more scalable in the number of parameters, but it also achieves the best or most competitive performance across 5 dialects in a zero-shot setting. In this way, our approach facilitates access to language technology for billions of English dialect speakers who are traditionally underrepresented.
Identifying Context-Dependent Translations for Evaluation Set Production
Nov 04, 2023A major impediment to the transition to context-aware machine translation is the absence of good evaluation metrics and test sets. Sentences that require context to be translated correctly are rare in test sets, reducing the utility of standard corpus-level metrics such as COMET or BLEU. On the other hand, datasets that annotate such sentences are also rare, small in scale, and available for only a few languages. To address this, we modernize, generalize, and extend previous annotation pipelines to produce CTXPRO, a tool that identifies subsets of parallel documents containing sentences that require context to correctly translate five phenomena: gender, formality, and animacy for pronouns, verb phrase ellipsis, and ambiguous noun inflections. The input to the pipeline is a set of hand-crafted, per-language, linguistically-informed rules that select contextual sentence pairs using coreference, part-of-speech, and morphological features provided by state-of-the-art tools. We apply this pipeline to seven languages pairs (EN into and out-of DE, ES, FR, IT, PL, PT, and RU) and two datasets (OpenSubtitles and WMT test sets), and validate its performance using both overlap with previous work and its ability to discriminate a contextual MT system from a sentence-based one. We release the CTXPRO pipeline and data as open source.
On the Opportunities of Green Computing: A Survey
Nov 06, 2023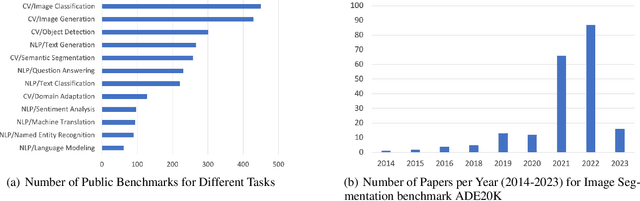
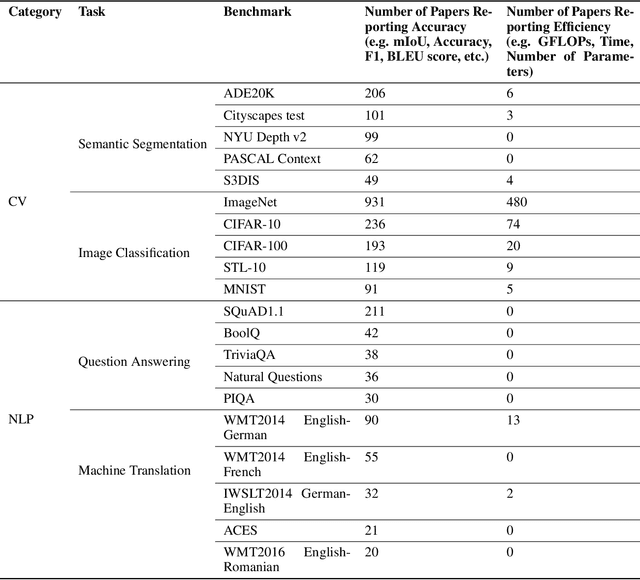
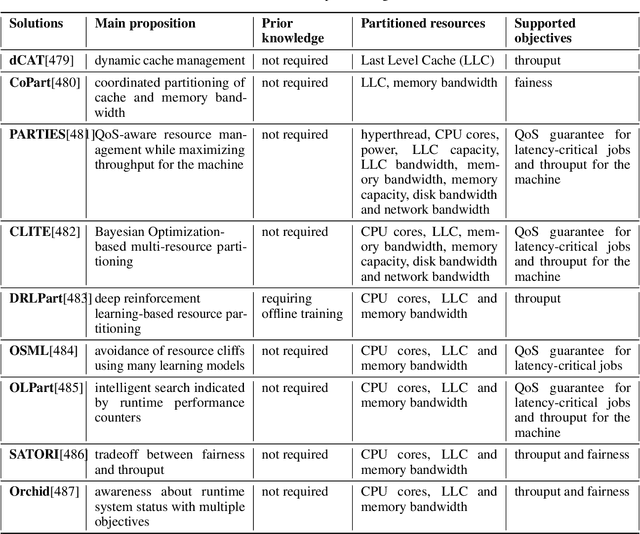
Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
Securing Voice Biometrics: One-Shot Learning Approach for Audio Deepfake Detection
Oct 05, 2023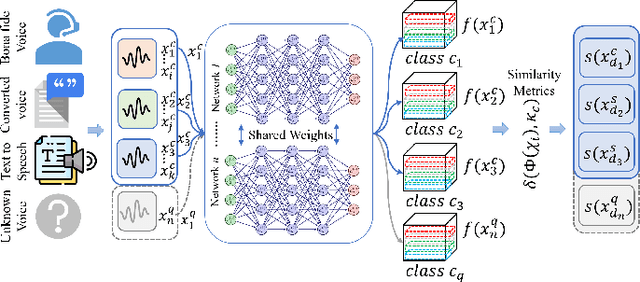
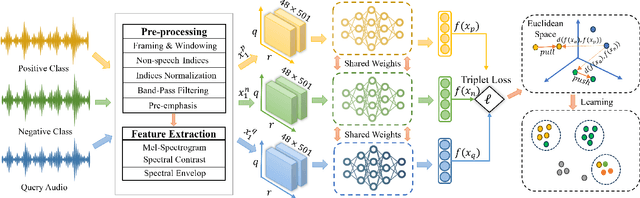
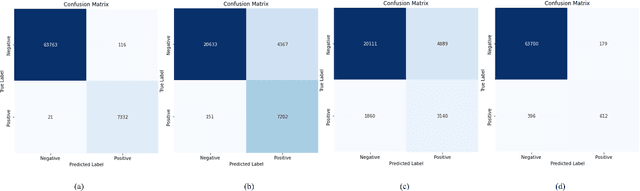
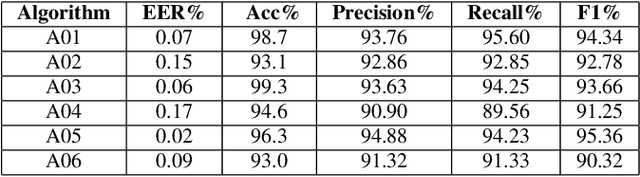
The Automatic Speaker Verification (ASV) system is vulnerable to fraudulent activities using audio deepfakes, also known as logical-access voice spoofing attacks. These deepfakes pose a concerning threat to voice biometrics due to recent advancements in generative AI and speech synthesis technologies. While several deep learning models for speech synthesis detection have been developed, most of them show poor generalizability, especially when the attacks have different statistical distributions from the ones seen. Therefore, this paper presents Quick-SpoofNet, an approach for detecting both seen and unseen synthetic attacks in the ASV system using one-shot learning and metric learning techniques. By using the effective spectral feature set, the proposed method extracts compact and representative temporal embeddings from the voice samples and utilizes metric learning and triplet loss to assess the similarity index and distinguish different embeddings. The system effectively clusters similar speech embeddings, classifying bona fide speeches as the target class and identifying other clusters as spoofing attacks. The proposed system is evaluated using the ASVspoof 2019 logical access (LA) dataset and tested against unseen deepfake attacks from the ASVspoof 2021 dataset. Additionally, its generalization ability towards unseen bona fide speech is assessed using speech data from the VSDC dataset.
MM-VID: Advancing Video Understanding with GPT-4V(ision)
Oct 30, 2023
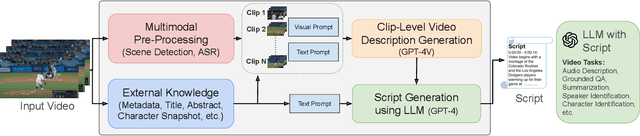

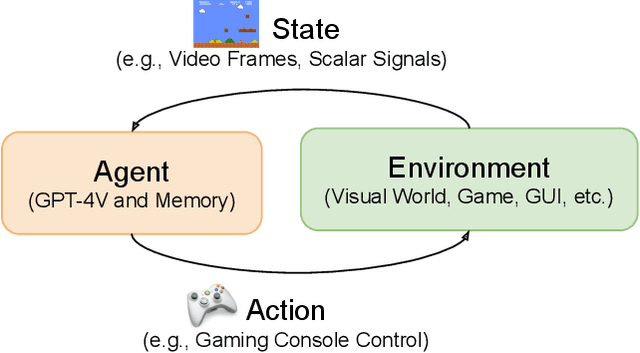
We present MM-VID, an integrated system that harnesses the capabilities of GPT-4V, combined with specialized tools in vision, audio, and speech, to facilitate advanced video understanding. MM-VID is designed to address the challenges posed by long-form videos and intricate tasks such as reasoning within hour-long content and grasping storylines spanning multiple episodes. MM-VID uses a video-to-script generation with GPT-4V to transcribe multimodal elements into a long textual script. The generated script details character movements, actions, expressions, and dialogues, paving the way for large language models (LLMs) to achieve video understanding. This enables advanced capabilities, including audio description, character identification, and multimodal high-level comprehension. Experimental results demonstrate the effectiveness of MM-VID in handling distinct video genres with various video lengths. Additionally, we showcase its potential when applied to interactive environments, such as video games and graphic user interfaces.
Challenges and Insights: Exploring 3D Spatial Features and Complex Networks on the MISP Dataset
Oct 05, 2023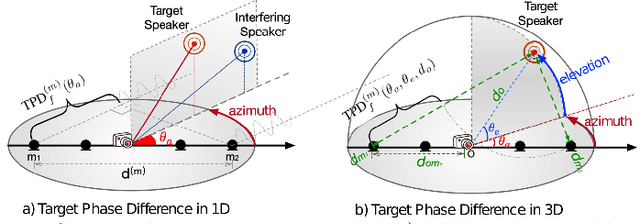


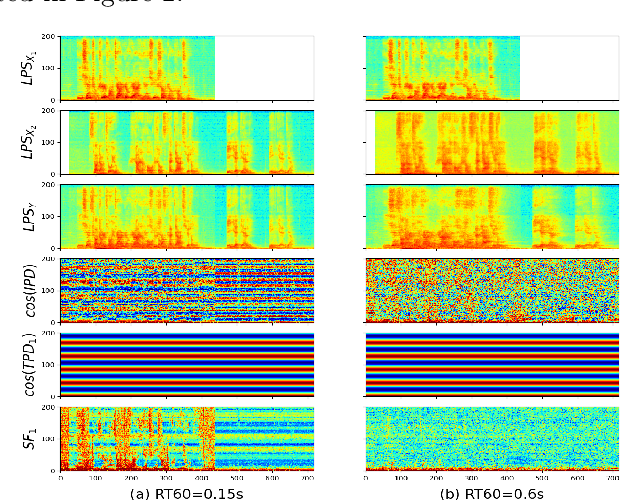
Multi-channel multi-talker speech recognition presents formidable challenges in the realm of speech processing, marked by issues such as background noise, reverberation, and overlapping speech. Overcoming these complexities requires leveraging contextual cues to separate target speech from a cacophonous mix, enabling accurate recognition. Among these cues, the 3D spatial feature has emerged as a cutting-edge solution, particularly when equipped with spatial information about the target speaker. Its exceptional ability to discern the target speaker within mixed audio, often rendering intermediate processing redundant, paves the way for the direct training of "All-in-one" ASR models. These models have demonstrated commendable performance on both simulated and real-world data. In this paper, we extend this approach to the MISP dataset to further validate its efficacy. We delve into the challenges encountered and insights gained when applying 3D spatial features to MISP, while also exploring preliminary experiments involving the replacement of these features with more complex input and models.
Speech-Driven 3D Face Animation with Composite and Regional Facial Movements
Aug 10, 2023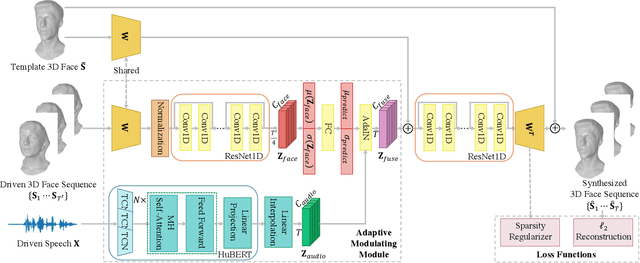
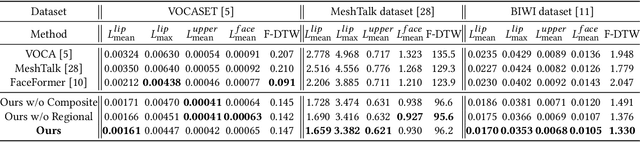
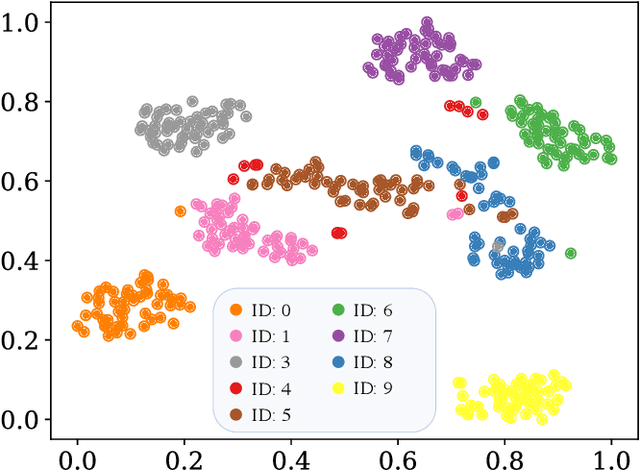
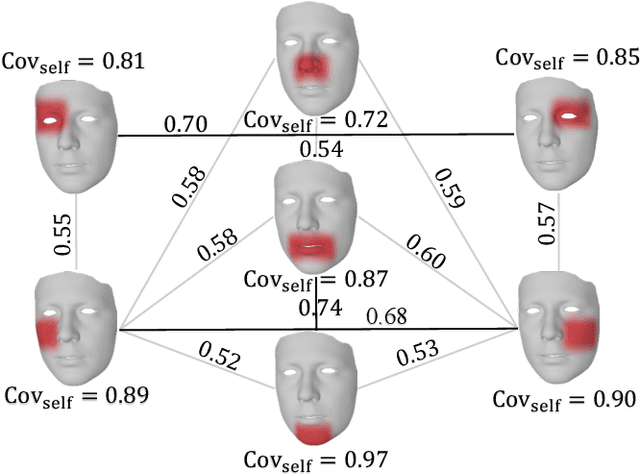
Speech-driven 3D face animation poses significant challenges due to the intricacy and variability inherent in human facial movements. This paper emphasizes the importance of considering both the composite and regional natures of facial movements in speech-driven 3D face animation. The composite nature pertains to how speech-independent factors globally modulate speech-driven facial movements along the temporal dimension. Meanwhile, the regional nature alludes to the notion that facial movements are not globally correlated but are actuated by local musculature along the spatial dimension. It is thus indispensable to incorporate both natures for engendering vivid animation. To address the composite nature, we introduce an adaptive modulation module that employs arbitrary facial movements to dynamically adjust speech-driven facial movements across frames on a global scale. To accommodate the regional nature, our approach ensures that each constituent of the facial features for every frame focuses on the local spatial movements of 3D faces. Moreover, we present a non-autoregressive backbone for translating audio to 3D facial movements, which maintains high-frequency nuances of facial movements and facilitates efficient inference. Comprehensive experiments and user studies demonstrate that our method surpasses contemporary state-of-the-art approaches both qualitatively and quantitatively.