 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Explicit Estimation of Magnitude and Phase Spectra in Parallel for High-Quality Speech Enhancement
Aug 17, 2023
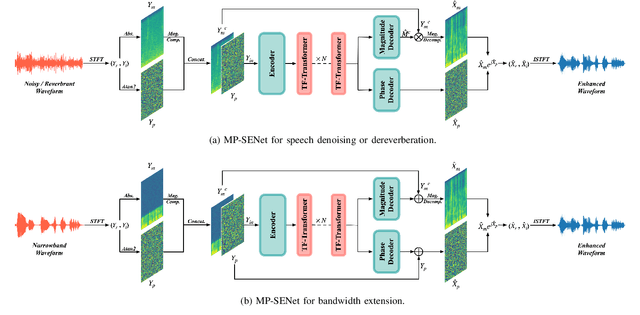
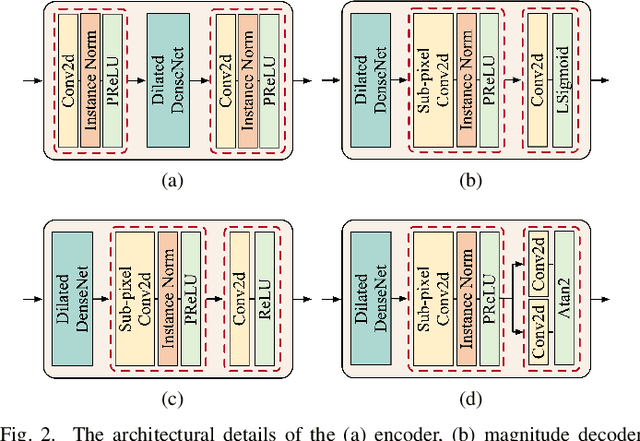
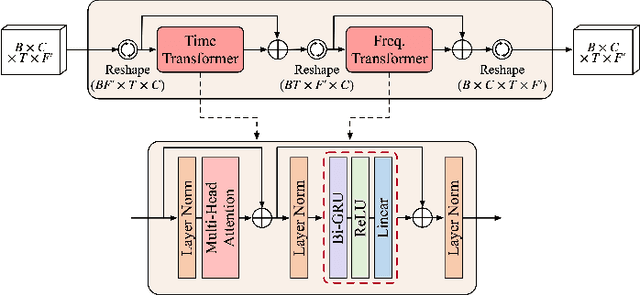
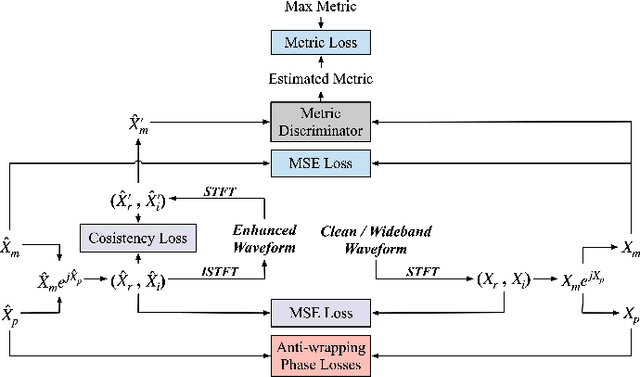
Phase information has a significant impact on speech perceptual quality and intelligibility. However, existing speech enhancement methods encounter limitations in explicit phase estimation due to the non-structural nature and wrapping characteristics of the phase, leading to a bottleneck in enhanced speech quality. To overcome the above issue, in this paper, we proposed MP-SENet, a novel Speech Enhancement Network which explicitly enhances Magnitude and Phase spectra in parallel. The proposed MP-SENet adopts a codec architecture in which the encoder and decoder are bridged by time-frequency Transformers along both time and frequency dimensions. The encoder aims to encode time-frequency representations derived from the input distorted magnitude and phase spectra. The decoder comprises dual-stream magnitude and phase decoders, directly enhancing magnitude and wrapped phase spectra by incorporating a magnitude estimation architecture and a phase parallel estimation architecture, respectively. To train the MP-SENet model effectively, we define multi-level loss functions, including mean square error and perceptual metric loss of magnitude spectra, anti-wrapping loss of phase spectra, as well as mean square error and consistency loss of short-time complex spectra. Experimental results demonstrate that our proposed MP-SENet excels in high-quality speech enhancement across multiple tasks, including speech denoising, dereverberation, and bandwidth extension. Compared to existing phase-aware speech enhancement methods, it successfully avoids the bidirectional compensation effect between the magnitude and phase, leading to a better harmonic restoration. Notably, for the speech denoising task, the MP-SENet yields a state-of-the-art performance with a PESQ of 3.60 on the public VoiceBank+DEMAND dataset.
Federated Learning with Differential Privacy for End-to-End Speech Recognition
Sep 29, 2023While federated learning (FL) has recently emerged as a promising approach to train machine learning models, it is limited to only preliminary explorations in the domain of automatic speech recognition (ASR). Moreover, FL does not inherently guarantee user privacy and requires the use of differential privacy (DP) for robust privacy guarantees. However, we are not aware of prior work on applying DP to FL for ASR. In this paper, we aim to bridge this research gap by formulating an ASR benchmark for FL with DP and establishing the first baselines. First, we extend the existing research on FL for ASR by exploring different aspects of recent $\textit{large end-to-end transformer models}$: architecture design, seed models, data heterogeneity, domain shift, and impact of cohort size. With a $\textit{practical}$ number of central aggregations we are able to train $\textbf{FL models}$ that are \textbf{nearly optimal} even with heterogeneous data, a seed model from another domain, or no pre-trained seed model. Second, we apply DP to FL for ASR, which is non-trivial since DP noise severely affects model training, especially for large transformer models, due to highly imbalanced gradients in the attention block. We counteract the adverse effect of DP noise by reviving per-layer clipping and explaining why its effect is more apparent in our case than in the prior work. Remarkably, we achieve user-level ($7.2$, $10^{-9}$)-$\textbf{DP}$ (resp. ($4.5$, $10^{-9}$)-$\textbf{DP}$) with a 1.3% (resp. 4.6%) absolute drop in the word error rate for extrapolation to high (resp. low) population scale for $\textbf{FL with DP in ASR}$.
Exploring Emotion Expression Recognition in Older Adults Interacting with a Virtual Coach
Nov 09, 2023
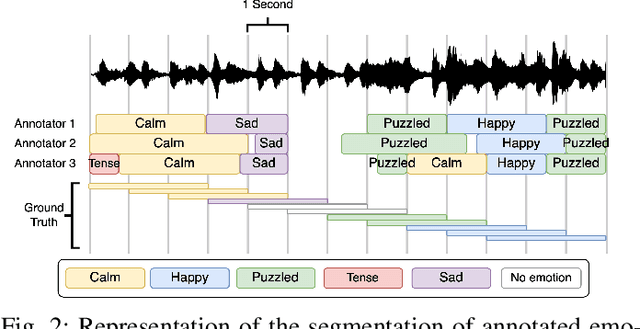
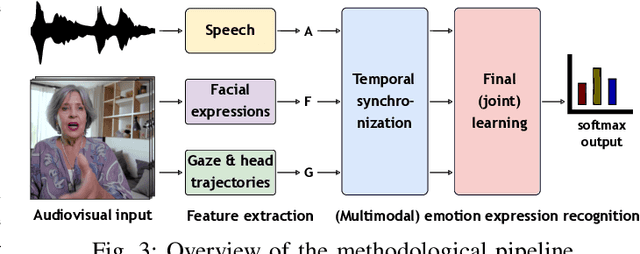
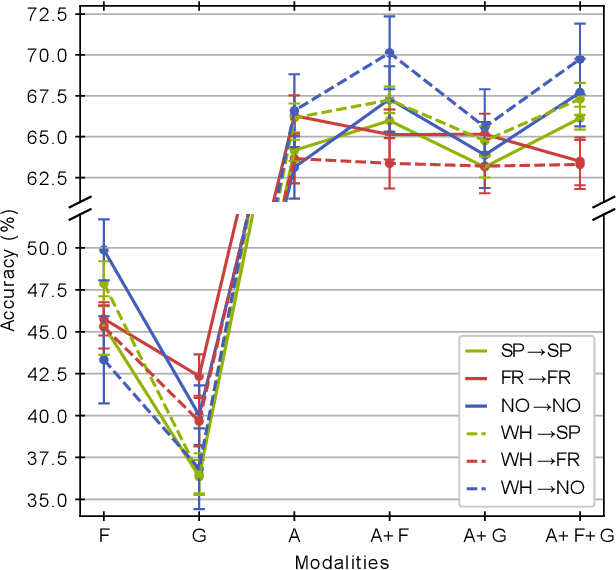
The EMPATHIC project aimed to design an emotionally expressive virtual coach capable of engaging healthy seniors to improve well-being and promote independent aging. One of the core aspects of the system is its human sensing capabilities, allowing for the perception of emotional states to provide a personalized experience. This paper outlines the development of the emotion expression recognition module of the virtual coach, encompassing data collection, annotation design, and a first methodological approach, all tailored to the project requirements. With the latter, we investigate the role of various modalities, individually and combined, for discrete emotion expression recognition in this context: speech from audio, and facial expressions, gaze, and head dynamics from video. The collected corpus includes users from Spain, France, and Norway, and was annotated separately for the audio and video channels with distinct emotional labels, allowing for a performance comparison across cultures and label types. Results confirm the informative power of the modalities studied for the emotional categories considered, with multimodal methods generally outperforming others (around 68% accuracy with audio labels and 72-74% with video labels). The findings are expected to contribute to the limited literature on emotion recognition applied to older adults in conversational human-machine interaction.
Mega-TTS 2: Zero-Shot Text-to-Speech with Arbitrary Length Speech Prompts
Jul 14, 2023
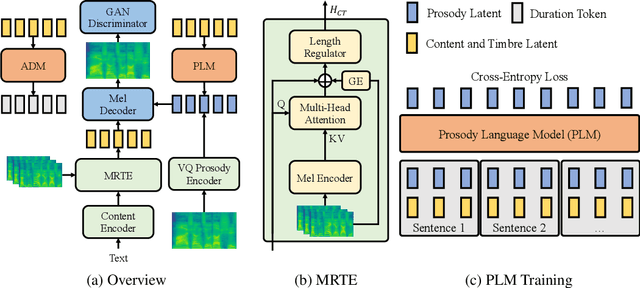
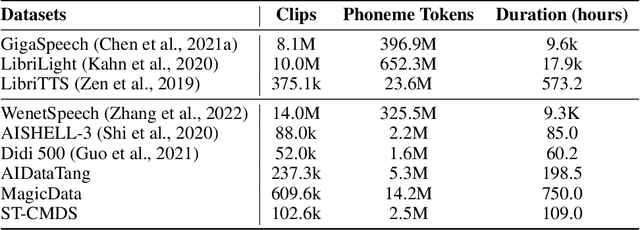
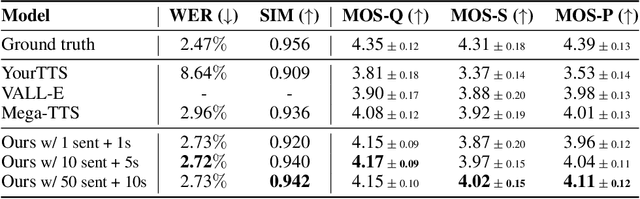
Zero-shot text-to-speech aims at synthesizing voices with unseen speech prompts. Previous large-scale multispeaker TTS models have successfully achieved this goal with an enrolled recording within 10 seconds. However, most of them are designed to utilize only short speech prompts. The limited information in short speech prompts significantly hinders the performance of fine-grained identity imitation. In this paper, we introduce Mega-TTS 2, a generic zero-shot multispeaker TTS model that is capable of synthesizing speech for unseen speakers with arbitrary-length prompts. Specifically, we 1) design a multi-reference timbre encoder to extract timbre information from multiple reference speeches; 2) and train a prosody language model with arbitrary-length speech prompts; With these designs, our model is suitable for prompts of different lengths, which extends the upper bound of speech quality for zero-shot text-to-speech. Besides arbitrary-length prompts, we introduce arbitrary-source prompts, which leverages the probabilities derived from multiple P-LLM outputs to produce expressive and controlled prosody. Furthermore, we propose a phoneme-level auto-regressive duration model to introduce in-context learning capabilities to duration modeling. Experiments demonstrate that our method could not only synthesize identity-preserving speech with a short prompt of an unseen speaker but also achieve improved performance with longer speech prompts. Audio samples can be found in https://mega-tts.github.io/mega2_demo/.
Break it, Imitate it, Fix it: Robustness by Generating Human-Like Attacks
Oct 25, 2023Real-world natural language processing systems need to be robust to human adversaries. Collecting examples of human adversaries for training is an effective but expensive solution. On the other hand, training on synthetic attacks with small perturbations - such as word-substitution - does not actually improve robustness to human adversaries. In this paper, we propose an adversarial training framework that uses limited human adversarial examples to generate more useful adversarial examples at scale. We demonstrate the advantages of this system on the ANLI and hate speech detection benchmark datasets - both collected via an iterative, adversarial human-and-model-in-the-loop procedure. Compared to training only on observed human attacks, also training on our synthetic adversarial examples improves model robustness to future rounds. In ANLI, we see accuracy gains on the current set of attacks (44.1%$\,\to\,$50.1%) and on two future unseen rounds of human generated attacks (32.5%$\,\to\,$43.4%, and 29.4%$\,\to\,$40.2%). In hate speech detection, we see AUC gains on current attacks (0.76 $\to$ 0.84) and a future round (0.77 $\to$ 0.79). Attacks from methods that do not learn the distribution of existing human adversaries, meanwhile, degrade robustness.
mahaNLP: A Marathi Natural Language Processing Library
Nov 05, 2023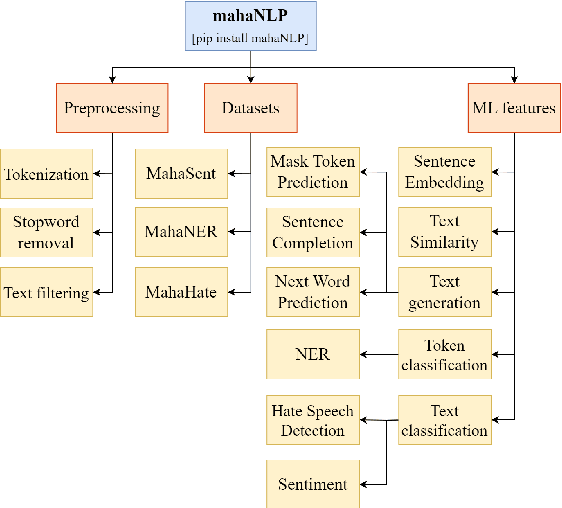
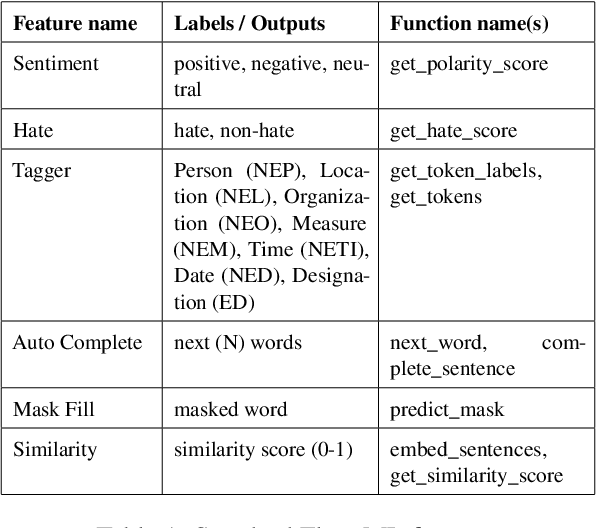
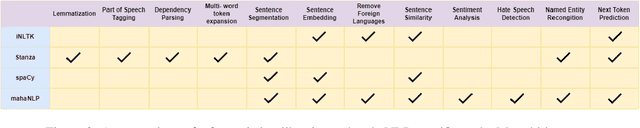

We present mahaNLP, an open-source natural language processing (NLP) library specifically built for the Marathi language. It aims to enhance the support for the low-resource Indian language Marathi in the field of NLP. It is an easy-to-use, extensible, and modular toolkit for Marathi text analysis built on state-of-the-art MahaBERT-based transformer models. Our work holds significant importance as other existing Indic NLP libraries provide basic Marathi processing support and rely on older models with restricted performance. Our toolkit stands out by offering a comprehensive array of NLP tasks, encompassing both fundamental preprocessing tasks and advanced NLP tasks like sentiment analysis, NER, hate speech detection, and sentence completion. This paper focuses on an overview of the mahaNLP framework, its features, and its usage. This work is a part of the L3Cube MahaNLP initiative, more information about it can be found at https://github.com/l3cube-pune/MarathiNLP .
Can large-scale vocoded spoofed data improve speech spoofing countermeasure with a self-supervised front end?
Sep 12, 2023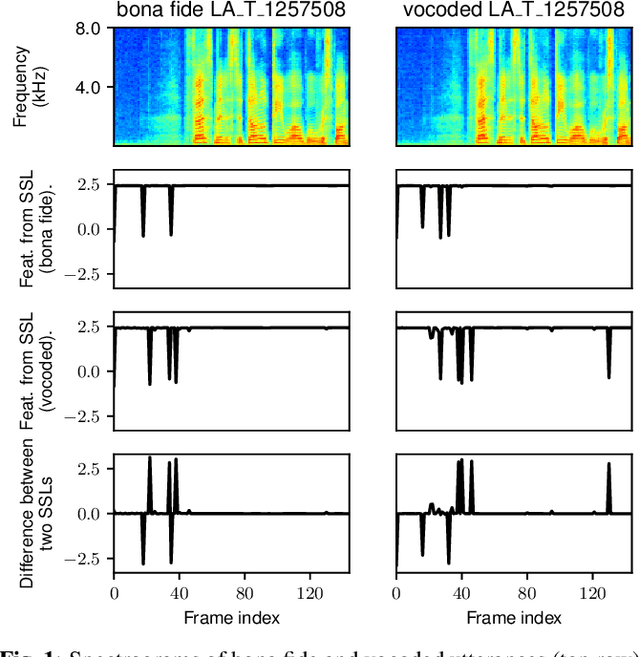
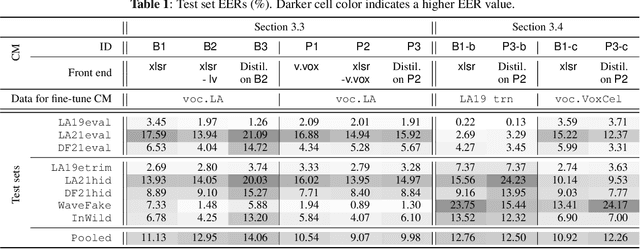
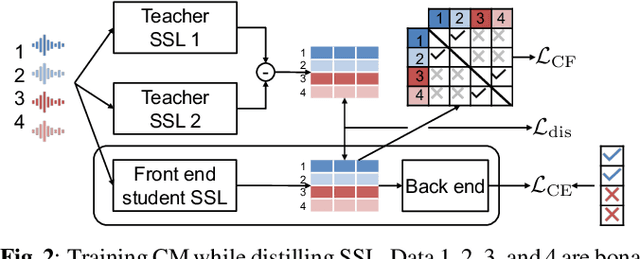
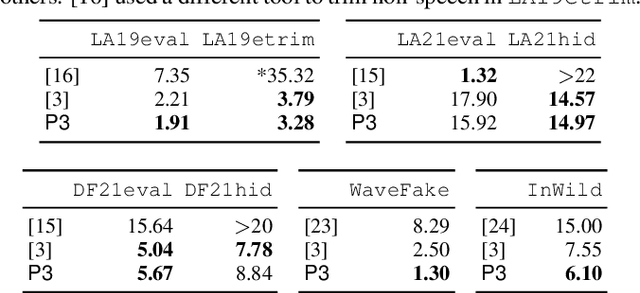
A speech spoofing countermeasure (CM) that discriminates between unseen spoofed and bona fide data requires diverse training data. While many datasets use spoofed data generated by speech synthesis systems, it was recently found that data vocoded by neural vocoders were also effective as the spoofed training data. Since many neural vocoders are fast in building and generation, this study used multiple neural vocoders and created more than 9,000 hours of vocoded data on the basis of the VoxCeleb2 corpus. This study investigates how this large-scale vocoded data can improve spoofing countermeasures that use data-hungry self-supervised learning (SSL) models. Experiments demonstrated that the overall CM performance on multiple test sets improved when using features extracted by an SSL model continually trained on the vocoded data. Further improvement was observed when using a new SSL distilled from the two SSLs before and after the continual training. The CM with the distilled SSL outperformed the previous best model on challenging unseen test sets, including the ASVspoof 2019 logical access, WaveFake, and In-the-Wild.
Optimized Tokenization for Transcribed Error Correction
Oct 16, 2023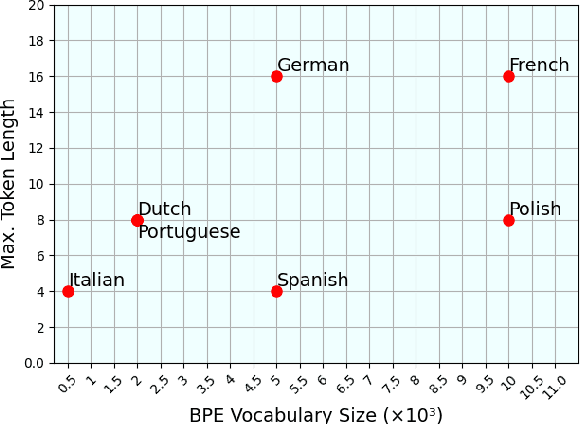
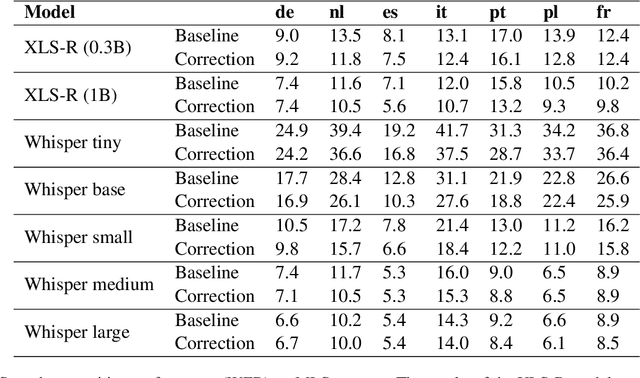
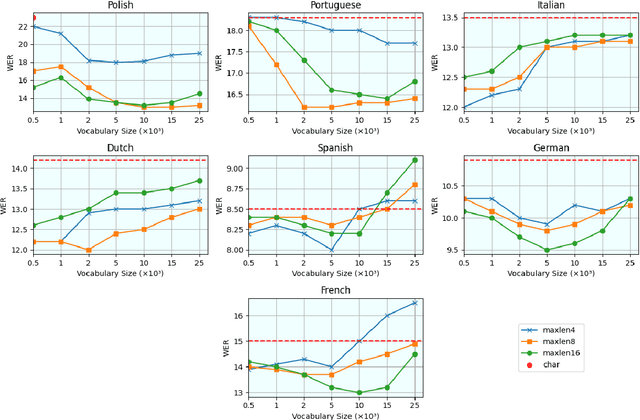
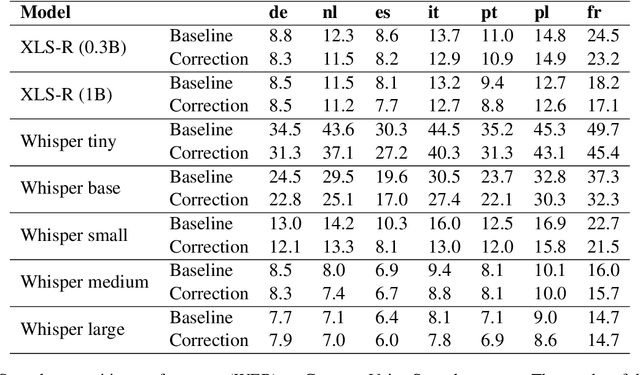
The challenges facing speech recognition systems, such as variations in pronunciations, adverse audio conditions, and the scarcity of labeled data, emphasize the necessity for a post-processing step that corrects recurring errors. Previous research has shown the advantages of employing dedicated error correction models, yet training such models requires large amounts of labeled data which is not easily obtained. To overcome this limitation, synthetic transcribed-like data is often utilized, however, bridging the distribution gap between transcribed errors and synthetic noise is not trivial. In this paper, we demonstrate that the performance of correction models can be significantly increased by training solely using synthetic data. Specifically, we empirically show that: (1) synthetic data generated using the error distribution derived from a set of transcribed data outperforms the common approach of applying random perturbations; (2) applying language-specific adjustments to the vocabulary of a BPE tokenizer strike a balance between adapting to unseen distributions and retaining knowledge of transcribed errors. We showcase the benefits of these key observations, and evaluate our approach using multiple languages, speech recognition systems and prominent speech recognition datasets.
Weigh Your Own Words: Improving Hate Speech Counter Narrative Generation via Attention Regularization
Sep 05, 2023Recent computational approaches for combating online hate speech involve the automatic generation of counter narratives by adapting Pretrained Transformer-based Language Models (PLMs) with human-curated data. This process, however, can produce in-domain overfitting, resulting in models generating acceptable narratives only for hatred similar to training data, with little portability to other targets or to real-world toxic language. This paper introduces novel attention regularization methodologies to improve the generalization capabilities of PLMs for counter narratives generation. Overfitting to training-specific terms is then discouraged, resulting in more diverse and richer narratives. We experiment with two attention-based regularization techniques on a benchmark English dataset. Regularized models produce better counter narratives than state-of-the-art approaches in most cases, both in terms of automatic metrics and human evaluation, especially when hateful targets are not present in the training data. This work paves the way for better and more flexible counter-speech generation models, a task for which datasets are highly challenging to produce.
On the Use of Self-Supervised Speech Representations in Spontaneous Speech Synthesis
Jul 11, 2023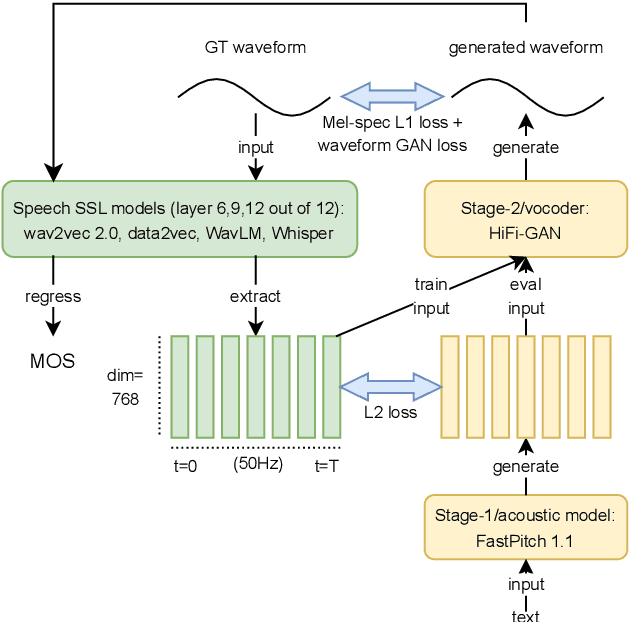
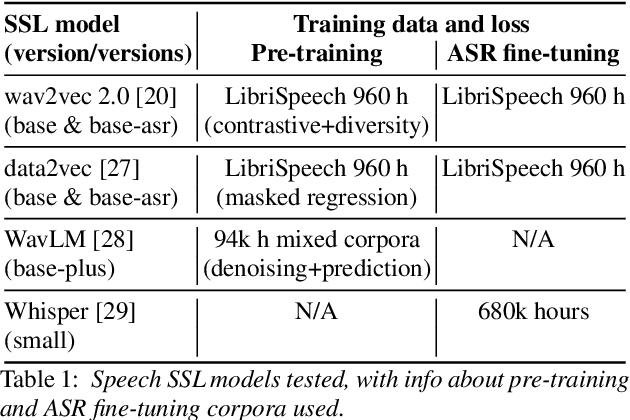
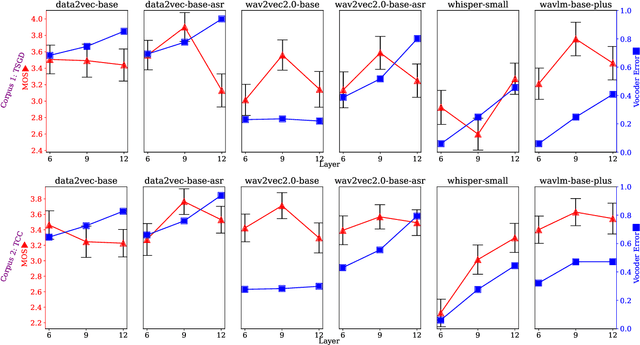
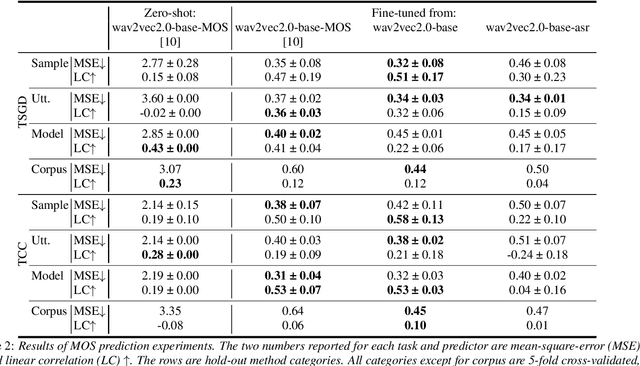
Self-supervised learning (SSL) speech representations learned from large amounts of diverse, mixed-quality speech data without transcriptions are gaining ground in many speech technology applications. Prior work has shown that SSL is an effective intermediate representation in two-stage text-to-speech (TTS) for both read and spontaneous speech. However, it is still not clear which SSL and which layer from each SSL model is most suited for spontaneous TTS. We address this shortcoming by extending the scope of comparison for SSL in spontaneous TTS to 6 different SSLs and 3 layers within each SSL. Furthermore, SSL has also shown potential in predicting the mean opinion scores (MOS) of synthesized speech, but this has only been done in read-speech MOS prediction. We extend an SSL-based MOS prediction framework previously developed for scoring read speech synthesis and evaluate its performance on synthesized spontaneous speech. All experiments are conducted twice on two different spontaneous corpora in order to find generalizable trends. Overall, we present comprehensive experimental results on the use of SSL in spontaneous TTS and MOS prediction to further quantify and understand how SSL can be used in spontaneous TTS. Audios samples: https://www.speech.kth.se/tts-demos/sp_ssl_tts