 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
On the Use of Self-Supervised Speech Representations in Spontaneous Speech Synthesis
Jul 11, 2023
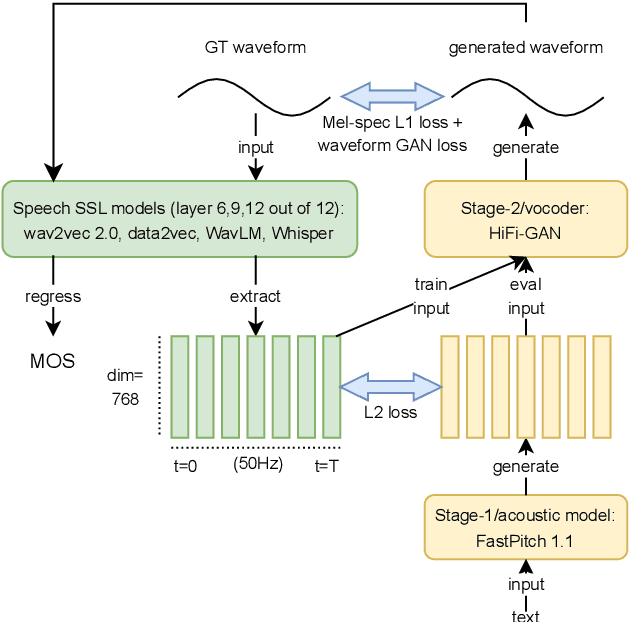
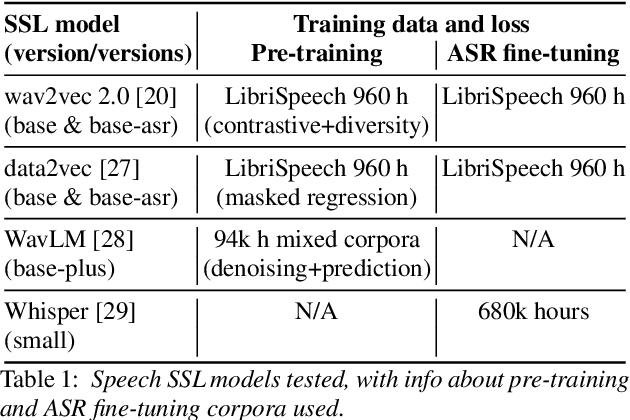
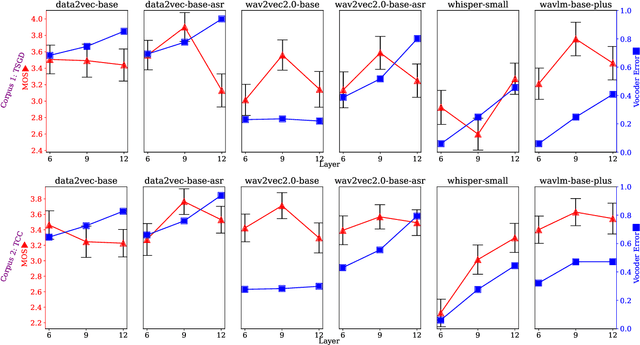
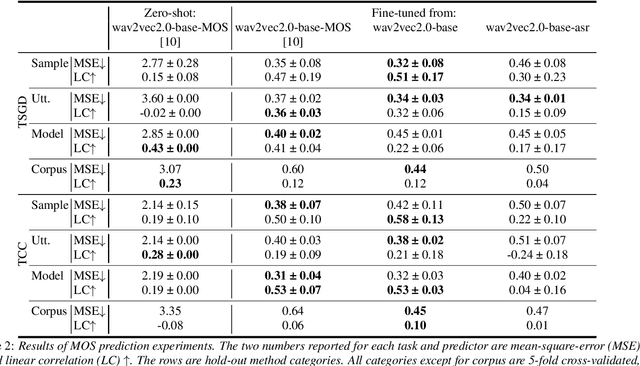
Self-supervised learning (SSL) speech representations learned from large amounts of diverse, mixed-quality speech data without transcriptions are gaining ground in many speech technology applications. Prior work has shown that SSL is an effective intermediate representation in two-stage text-to-speech (TTS) for both read and spontaneous speech. However, it is still not clear which SSL and which layer from each SSL model is most suited for spontaneous TTS. We address this shortcoming by extending the scope of comparison for SSL in spontaneous TTS to 6 different SSLs and 3 layers within each SSL. Furthermore, SSL has also shown potential in predicting the mean opinion scores (MOS) of synthesized speech, but this has only been done in read-speech MOS prediction. We extend an SSL-based MOS prediction framework previously developed for scoring read speech synthesis and evaluate its performance on synthesized spontaneous speech. All experiments are conducted twice on two different spontaneous corpora in order to find generalizable trends. Overall, we present comprehensive experimental results on the use of SSL in spontaneous TTS and MOS prediction to further quantify and understand how SSL can be used in spontaneous TTS. Audios samples: https://www.speech.kth.se/tts-demos/sp_ssl_tts
Adapting Large Language Model with Speech for Fully Formatted End-to-End Speech Recognition
Aug 03, 2023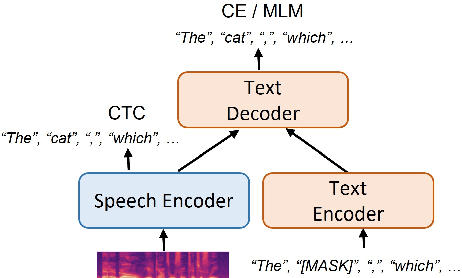
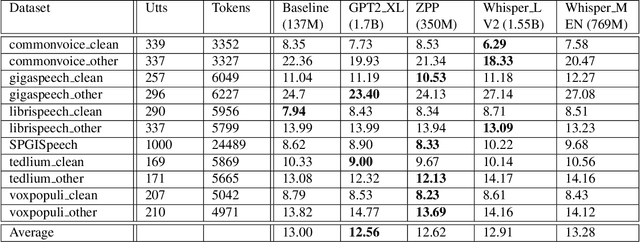
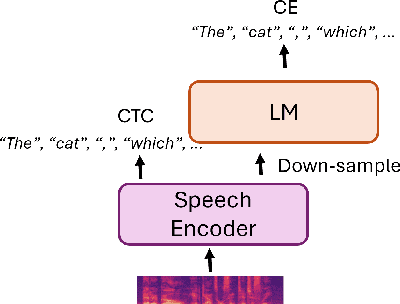

Most end-to-end (E2E) speech recognition models are composed of encoder and decoder blocks that perform acoustic and language modeling functions. Pretrained large language models (LLMs) have the potential to improve the performance of E2E ASR. However, integrating a pretrained language model into an E2E speech recognition model has shown limited benefits due to the mismatches between text-based LLMs and those used in E2E ASR. In this paper, we explore an alternative approach by adapting a pretrained LLMs to speech. Our experiments on fully-formatted E2E ASR transcription tasks across various domains demonstrate that our approach can effectively leverage the strengths of pretrained LLMs to produce more readable ASR transcriptions. Our model, which is based on the pretrained large language models with either an encoder-decoder or decoder-only structure, surpasses strong ASR models such as Whisper, in terms of recognition error rate, considering formats like punctuation and capitalization as well.
LocSelect: Target Speaker Localization with an Auditory Selective Hearing Mechanism
Oct 17, 2023The prevailing noise-resistant and reverberation-resistant localization algorithms primarily emphasize separating and providing directional output for each speaker in multi-speaker scenarios, without association with the identity of speakers. In this paper, we present a target speaker localization algorithm with a selective hearing mechanism. Given a reference speech of the target speaker, we first produce a speaker-dependent spectrogram mask to eliminate interfering speakers' speech. Subsequently, a Long short-term memory (LSTM) network is employed to extract the target speaker's location from the filtered spectrogram. Experiments validate the superiority of our proposed method over the existing algorithms for different scale invariant signal-to-noise ratios (SNR) conditions. Specifically, at SNR = -10 dB, our proposed network LocSelect achieves a mean absolute error (MAE) of 3.55 and an accuracy (ACC) of 87.40%.
Thesis Distillation: Investigating The Impact of Bias in NLP Models on Hate Speech Detection
Aug 31, 2023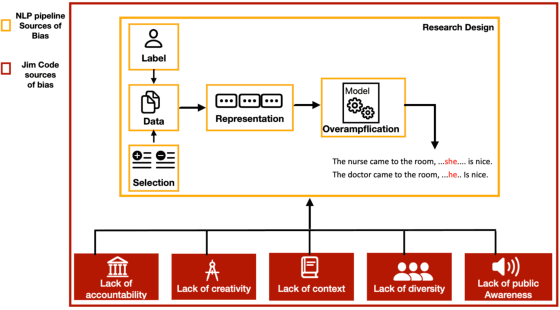
This paper is a summary of the work in my PhD thesis. In which, I investigate the impact of bias in NLP models on the task of hate speech detection from three perspectives: explainability, offensive stereotyping bias, and fairness. I discuss the main takeaways from my thesis and how they can benefit the broader NLP community. Finally, I discuss important future research directions. The findings of my thesis suggest that bias in NLP models impacts the task of hate speech detection from all three perspectives. And that unless we start incorporating social sciences in studying bias in NLP models, we will not effectively overcome the current limitations of measuring and mitigating bias in NLP models.
Causality Guided Disentanglement for Cross-Platform Hate Speech Detection
Aug 10, 2023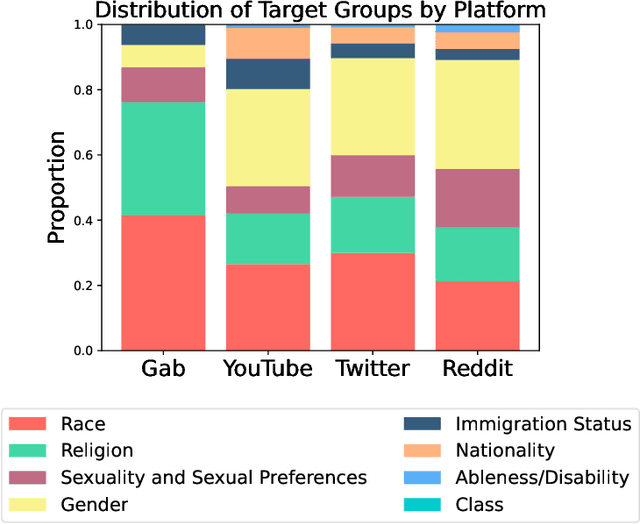
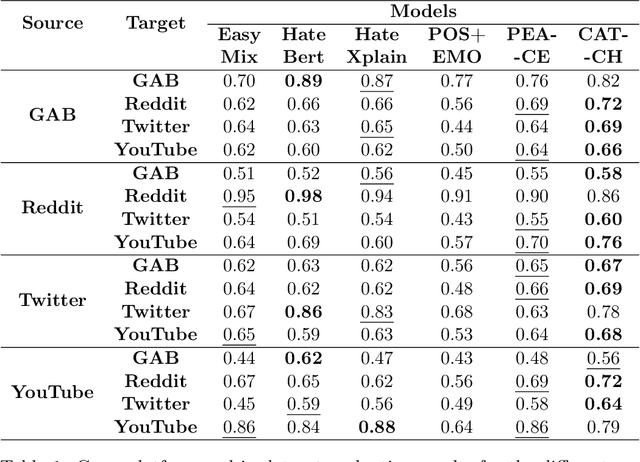
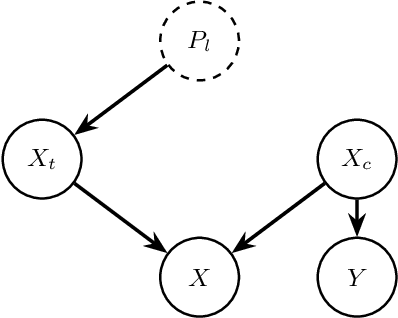
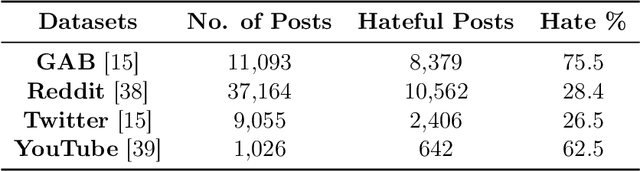
Social media platforms, despite their value in promoting open discourse, are often exploited to spread harmful content. Current deep learning and natural language processing models used for detecting this harmful content overly rely on domain-specific terms affecting their capabilities to adapt to generalizable hate speech detection. This is because they tend to focus too narrowly on particular linguistic signals or the use of certain categories of words. Another significant challenge arises when platforms lack high-quality annotated data for training, leading to a need for cross-platform models that can adapt to different distribution shifts. Our research introduces a cross-platform hate speech detection model capable of being trained on one platform's data and generalizing to multiple unseen platforms. To achieve good generalizability across platforms, one way is to disentangle the input representations into invariant and platform-dependent features. We also argue that learning causal relationships, which remain constant across diverse environments, can significantly aid in understanding invariant representations in hate speech. By disentangling input into platform-dependent features (useful for predicting hate targets) and platform-independent features (used to predict the presence of hate), we learn invariant representations resistant to distribution shifts. These features are then used to predict hate speech across unseen platforms. Our extensive experiments across four platforms highlight our model's enhanced efficacy compared to existing state-of-the-art methods in detecting generalized hate speech.
Study of speaker localization with binaural microphone array incorporating auditory filters and lateral angle estimation
Oct 31, 2023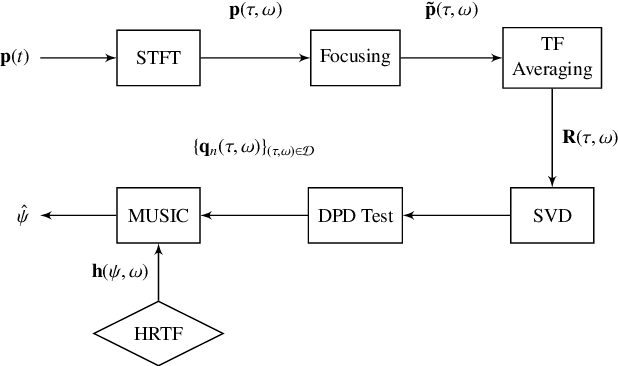
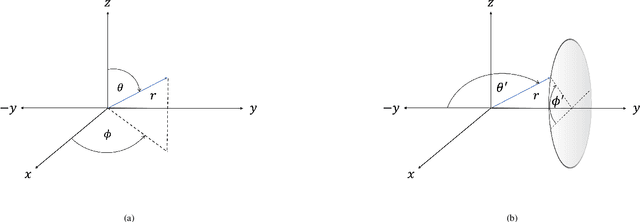

Speaker localization for binaural microphone arrays has been widely studied for applications such as speech communication, video conferencing, and robot audition. Many methods developed for this task, including the direct path dominance (DPD) test, share common stages in their processing, which include transformation using the short-time Fourier transform (STFT), and a direction of arrival (DOA) search that is based on the head related transfer function (HRTF) set. In this paper, alternatives to these processing stages, motivated by human hearing, are proposed. These include incorporating an auditory filter bank to replace the STFT, and a new DOA search based on transformed HRTF as steering vectors. A simulation study and an experimental study are conducted to validate the proposed alternatives, and both are applied to two binaural DOA estimation methods; the results show that the proposed method compares favorably with current methods.
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Aug 11, 2023
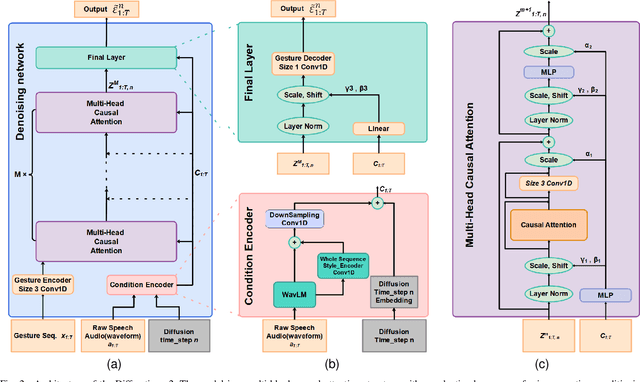
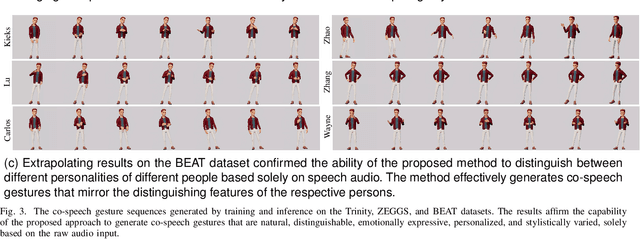
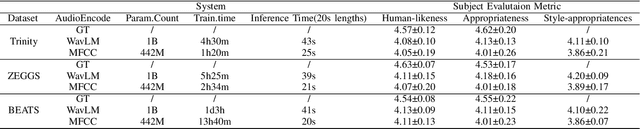
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces "diffmotion-v2," a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
MyVoice: Arabic Speech Resource Collaboration Platform
Jul 23, 2023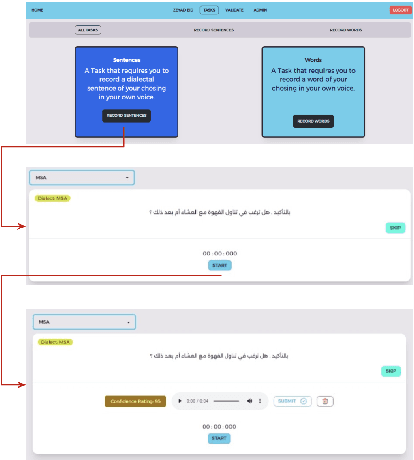
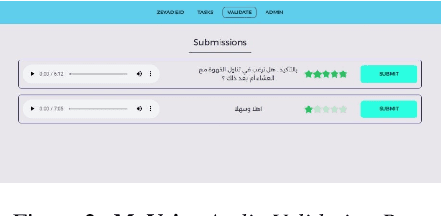
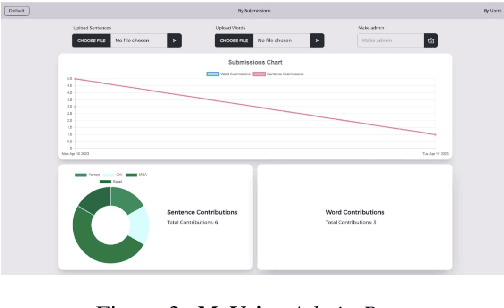
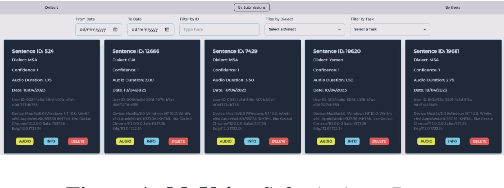
We introduce MyVoice, a crowdsourcing platform designed to collect Arabic speech to enhance dialectal speech technologies. This platform offers an opportunity to design large dialectal speech datasets; and makes them publicly available. MyVoice allows contributors to select city/country-level fine-grained dialect and record the displayed utterances. Users can switch roles between contributors and annotators. The platform incorporates a quality assurance system that filters out low-quality and spurious recordings before sending them for validation. During the validation phase, contributors can assess the quality of recordings, annotate them, and provide feedback which is then reviewed by administrators. Furthermore, the platform offers flexibility to admin roles to add new data or tasks beyond dialectal speech and word collection, which are displayed to contributors. Thus, enabling collaborative efforts in gathering diverse and large Arabic speech data.
Learning Separable Hidden Unit Contributions for Speaker-Adaptive Lip-Reading
Oct 08, 2023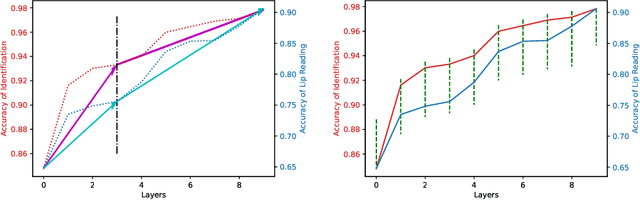
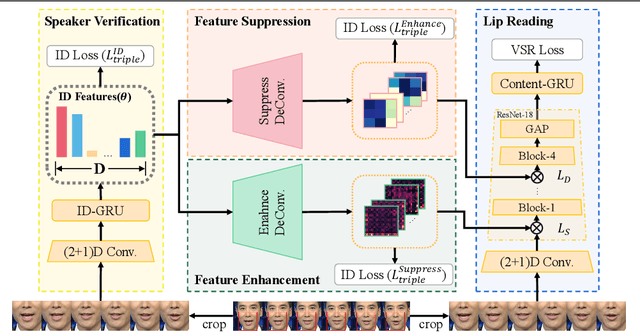
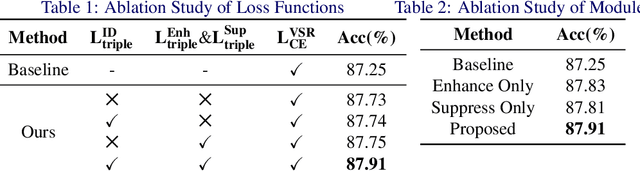
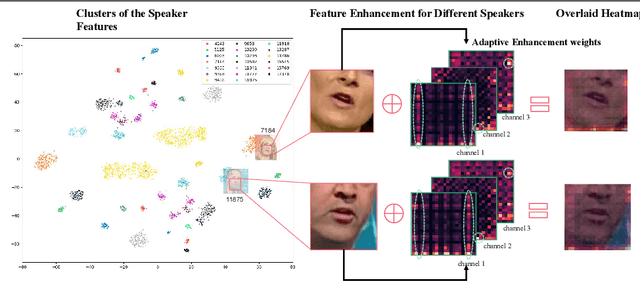
In this paper, we propose a novel method for speaker adaptation in lip reading, motivated by two observations. Firstly, a speaker's own characteristics can always be portrayed well by his/her few facial images or even a single image with shallow networks, while the fine-grained dynamic features associated with speech content expressed by the talking face always need deep sequential networks to represent accurately. Therefore, we treat the shallow and deep layers differently for speaker adaptive lip reading. Secondly, we observe that a speaker's unique characteristics ( e.g. prominent oral cavity and mandible) have varied effects on lip reading performance for different words and pronunciations, necessitating adaptive enhancement or suppression of the features for robust lip reading. Based on these two observations, we propose to take advantage of the speaker's own characteristics to automatically learn separable hidden unit contributions with different targets for shallow layers and deep layers respectively. For shallow layers where features related to the speaker's characteristics are stronger than the speech content related features, we introduce speaker-adaptive features to learn for enhancing the speech content features. For deep layers where both the speaker's features and the speech content features are all expressed well, we introduce the speaker-adaptive features to learn for suppressing the speech content irrelevant noise for robust lip reading. Our approach consistently outperforms existing methods, as confirmed by comprehensive analysis and comparison across different settings. Besides the evaluation on the popular LRW-ID and GRID datasets, we also release a new dataset for evaluation, CAS-VSR-S68h, to further assess the performance in an extreme setting where just a few speakers are available but the speech content covers a large and diversified range.
Audio-visual video-to-speech synthesis with synthesized input audio
Jul 31, 2023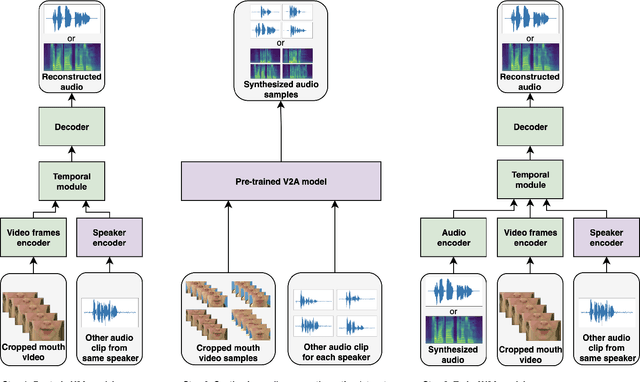
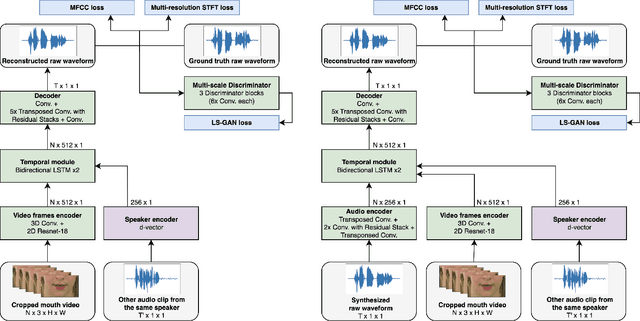
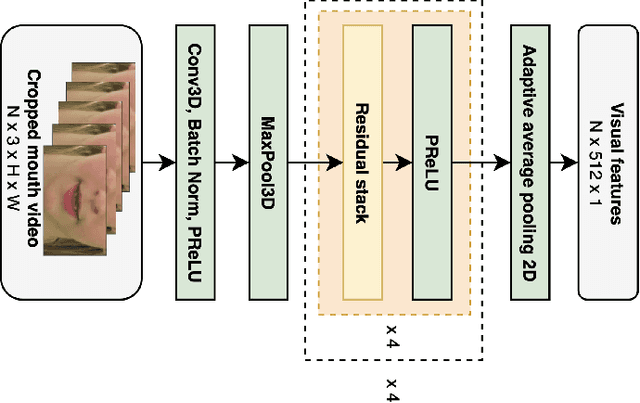
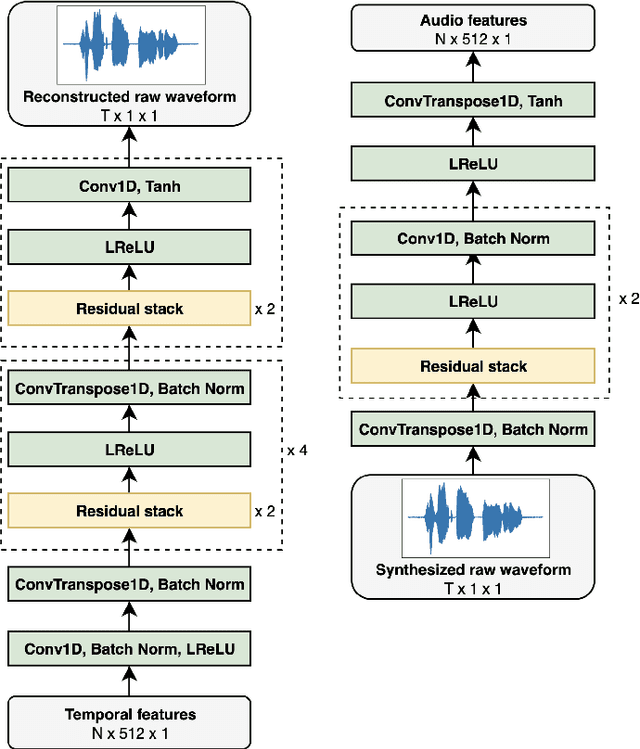
Video-to-speech synthesis involves reconstructing the speech signal of a speaker from a silent video. The implicit assumption of this task is that the sound signal is either missing or contains a high amount of noise/corruption such that it is not useful for processing. Previous works in the literature either use video inputs only or employ both video and audio inputs during training, and discard the input audio pathway during inference. In this work we investigate the effect of using video and audio inputs for video-to-speech synthesis during both training and inference. In particular, we use pre-trained video-to-speech models to synthesize the missing speech signals and then train an audio-visual-to-speech synthesis model, using both the silent video and the synthesized speech as inputs, to predict the final reconstructed speech. Our experiments demonstrate that this approach is successful with both raw waveforms and mel spectrograms as target outputs.