 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Weigh Your Own Words: Improving Hate Speech Counter Narrative Generation via Attention Regularization
Sep 05, 2023
Recent computational approaches for combating online hate speech involve the automatic generation of counter narratives by adapting Pretrained Transformer-based Language Models (PLMs) with human-curated data. This process, however, can produce in-domain overfitting, resulting in models generating acceptable narratives only for hatred similar to training data, with little portability to other targets or to real-world toxic language. This paper introduces novel attention regularization methodologies to improve the generalization capabilities of PLMs for counter narratives generation. Overfitting to training-specific terms is then discouraged, resulting in more diverse and richer narratives. We experiment with two attention-based regularization techniques on a benchmark English dataset. Regularized models produce better counter narratives than state-of-the-art approaches in most cases, both in terms of automatic metrics and human evaluation, especially when hateful targets are not present in the training data. This work paves the way for better and more flexible counter-speech generation models, a task for which datasets are highly challenging to produce.
Server-side Rescoring of Spoken Entity-centric Knowledge Queries for Virtual Assistants
Nov 02, 2023On-device Virtual Assistants (VAs) powered by Automatic Speech Recognition (ASR) require effective knowledge integration for the challenging entity-rich query recognition. In this paper, we conduct an empirical study of modeling strategies for server-side rescoring of spoken information domain queries using various categories of Language Models (LMs) (N-gram word LMs, sub-word neural LMs). We investigate the combination of on-device and server-side signals, and demonstrate significant WER improvements of 23%-35% on various entity-centric query subpopulations by integrating various server-side LMs compared to performing ASR on-device only. We also perform a comparison between LMs trained on domain data and a GPT-3 variant offered by OpenAI as a baseline. Furthermore, we also show that model fusion of multiple server-side LMs trained from scratch most effectively combines complementary strengths of each model and integrates knowledge learned from domain-specific data to a VA ASR system.
Explicit Estimation of Magnitude and Phase Spectra in Parallel for High-Quality Speech Enhancement
Aug 17, 2023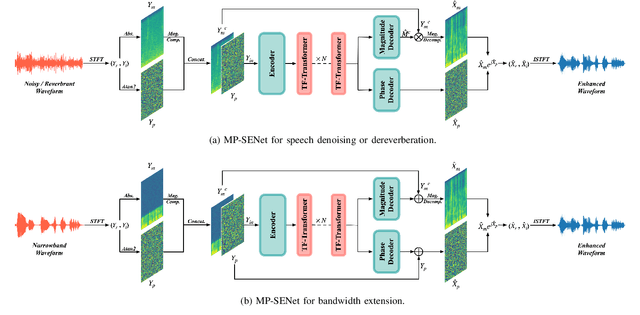
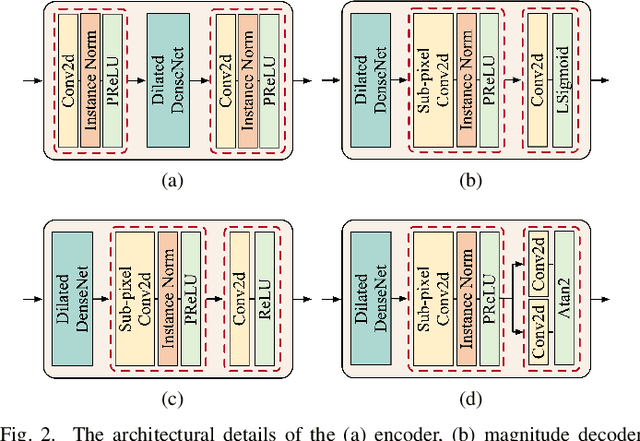
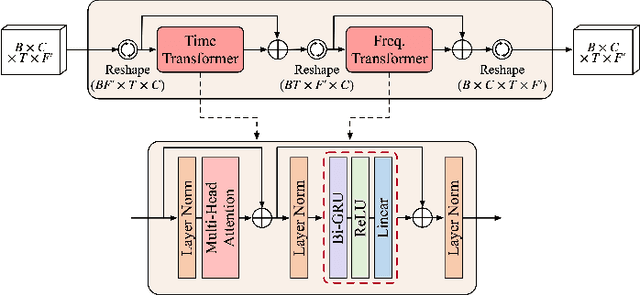
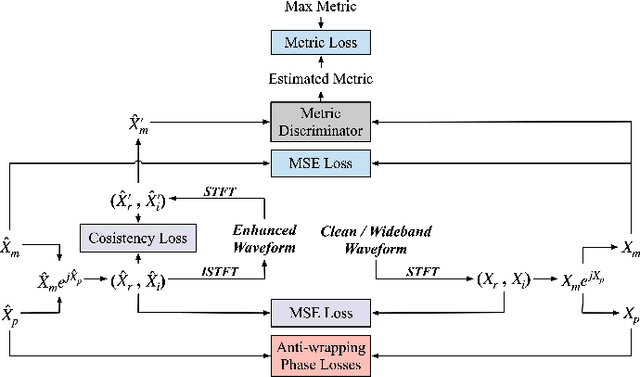
Phase information has a significant impact on speech perceptual quality and intelligibility. However, existing speech enhancement methods encounter limitations in explicit phase estimation due to the non-structural nature and wrapping characteristics of the phase, leading to a bottleneck in enhanced speech quality. To overcome the above issue, in this paper, we proposed MP-SENet, a novel Speech Enhancement Network which explicitly enhances Magnitude and Phase spectra in parallel. The proposed MP-SENet adopts a codec architecture in which the encoder and decoder are bridged by time-frequency Transformers along both time and frequency dimensions. The encoder aims to encode time-frequency representations derived from the input distorted magnitude and phase spectra. The decoder comprises dual-stream magnitude and phase decoders, directly enhancing magnitude and wrapped phase spectra by incorporating a magnitude estimation architecture and a phase parallel estimation architecture, respectively. To train the MP-SENet model effectively, we define multi-level loss functions, including mean square error and perceptual metric loss of magnitude spectra, anti-wrapping loss of phase spectra, as well as mean square error and consistency loss of short-time complex spectra. Experimental results demonstrate that our proposed MP-SENet excels in high-quality speech enhancement across multiple tasks, including speech denoising, dereverberation, and bandwidth extension. Compared to existing phase-aware speech enhancement methods, it successfully avoids the bidirectional compensation effect between the magnitude and phase, leading to a better harmonic restoration. Notably, for the speech denoising task, the MP-SENet yields a state-of-the-art performance with a PESQ of 3.60 on the public VoiceBank+DEMAND dataset.
Time-Frequency Transformer: A Novel Time Frequency Joint Learning Method for Speech Emotion Recognition
Aug 28, 2023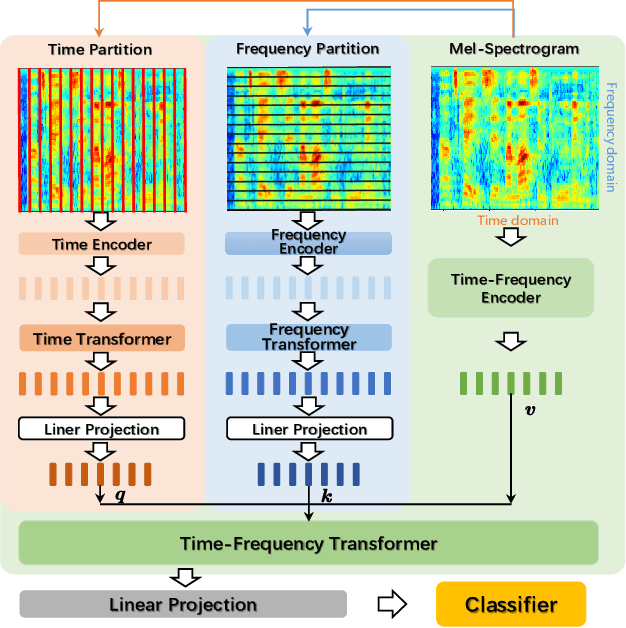
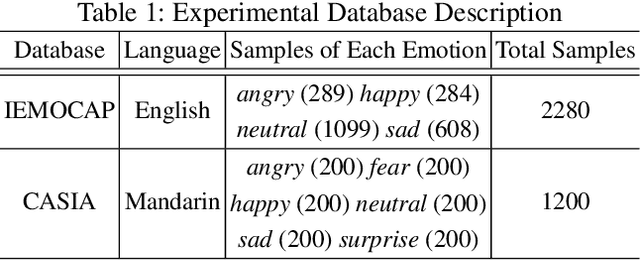

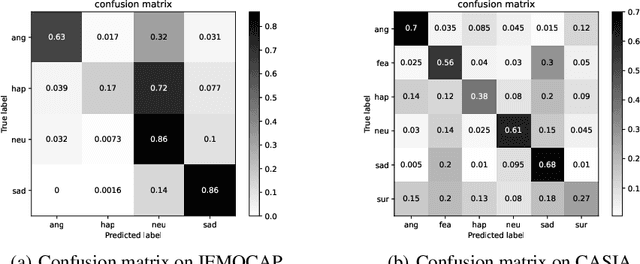
In this paper, we propose a novel time-frequency joint learning method for speech emotion recognition, called Time-Frequency Transformer. Its advantage is that the Time-Frequency Transformer can excavate global emotion patterns in the time-frequency domain of speech signal while modeling the local emotional correlations in the time domain and frequency domain respectively. For the purpose, we first design a Time Transformer and Frequency Transformer to capture the local emotion patterns between frames and inside frequency bands respectively, so as to ensure the integrity of the emotion information modeling in both time and frequency domains. Then, a Time-Frequency Transformer is proposed to mine the time-frequency emotional correlations through the local time-domain and frequency-domain emotion features for learning more discriminative global speech emotion representation. The whole process is a time-frequency joint learning process implemented by a series of Transformer models. Experiments on IEMOCAP and CASIA databases indicate that our proposed method outdoes the state-of-the-art methods.
Where's the Liability in Harmful AI Speech?
Aug 09, 2023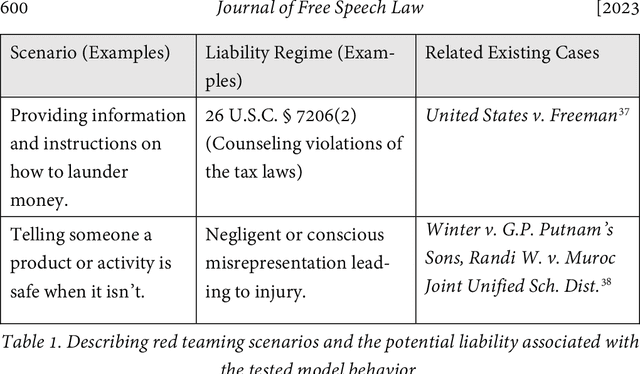


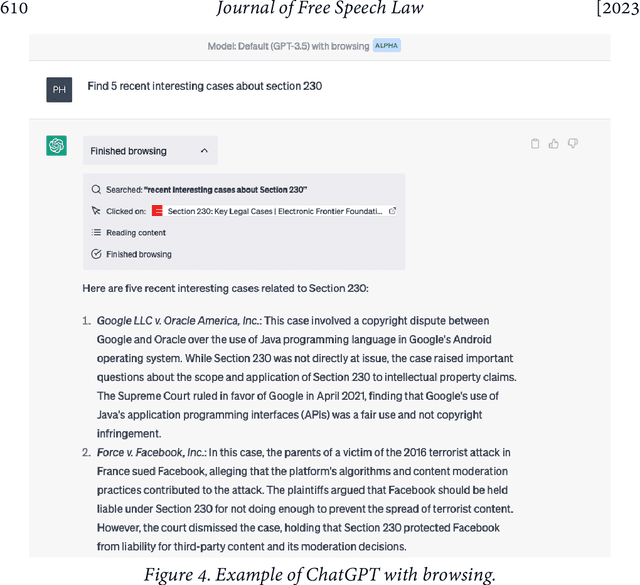
Generative AI, in particular text-based "foundation models" (large models trained on a huge variety of information including the internet), can generate speech that could be problematic under a wide range of liability regimes. Machine learning practitioners regularly "red team" models to identify and mitigate such problematic speech: from "hallucinations" falsely accusing people of serious misconduct to recipes for constructing an atomic bomb. A key question is whether these red-teamed behaviors actually present any liability risk for model creators and deployers under U.S. law, incentivizing investments in safety mechanisms. We examine three liability regimes, tying them to common examples of red-teamed model behaviors: defamation, speech integral to criminal conduct, and wrongful death. We find that any Section 230 immunity analysis or downstream liability analysis is intimately wrapped up in the technical details of algorithm design. And there are many roadblocks to truly finding models (and their associated parties) liable for generated speech. We argue that AI should not be categorically immune from liability in these scenarios and that as courts grapple with the already fine-grained complexities of platform algorithms, the technical details of generative AI loom above with thornier questions. Courts and policymakers should think carefully about what technical design incentives they create as they evaluate these issues.
LocSelect: Target Speaker Localization with an Auditory Selective Hearing Mechanism
Oct 17, 2023The prevailing noise-resistant and reverberation-resistant localization algorithms primarily emphasize separating and providing directional output for each speaker in multi-speaker scenarios, without association with the identity of speakers. In this paper, we present a target speaker localization algorithm with a selective hearing mechanism. Given a reference speech of the target speaker, we first produce a speaker-dependent spectrogram mask to eliminate interfering speakers' speech. Subsequently, a Long short-term memory (LSTM) network is employed to extract the target speaker's location from the filtered spectrogram. Experiments validate the superiority of our proposed method over the existing algorithms for different scale invariant signal-to-noise ratios (SNR) conditions. Specifically, at SNR = -10 dB, our proposed network LocSelect achieves a mean absolute error (MAE) of 3.55 and an accuracy (ACC) of 87.40%.
Study of speaker localization with binaural microphone array incorporating auditory filters and lateral angle estimation
Oct 31, 2023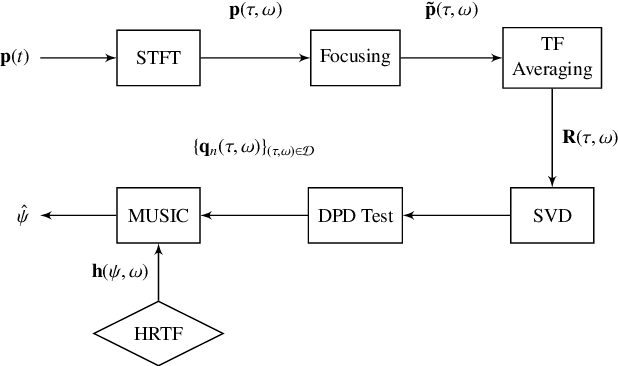
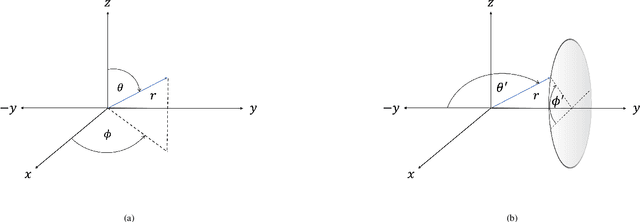

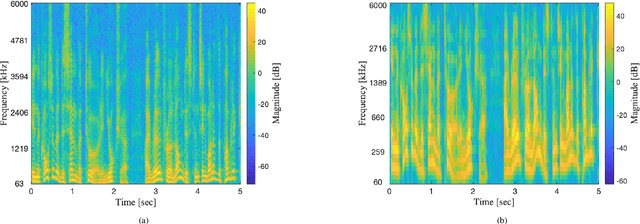
Speaker localization for binaural microphone arrays has been widely studied for applications such as speech communication, video conferencing, and robot audition. Many methods developed for this task, including the direct path dominance (DPD) test, share common stages in their processing, which include transformation using the short-time Fourier transform (STFT), and a direction of arrival (DOA) search that is based on the head related transfer function (HRTF) set. In this paper, alternatives to these processing stages, motivated by human hearing, are proposed. These include incorporating an auditory filter bank to replace the STFT, and a new DOA search based on transformed HRTF as steering vectors. A simulation study and an experimental study are conducted to validate the proposed alternatives, and both are applied to two binaural DOA estimation methods; the results show that the proposed method compares favorably with current methods.
Spatial Reconstructed Local Attention Res2Net with F0 Subband for Fake Speech Detection
Aug 19, 2023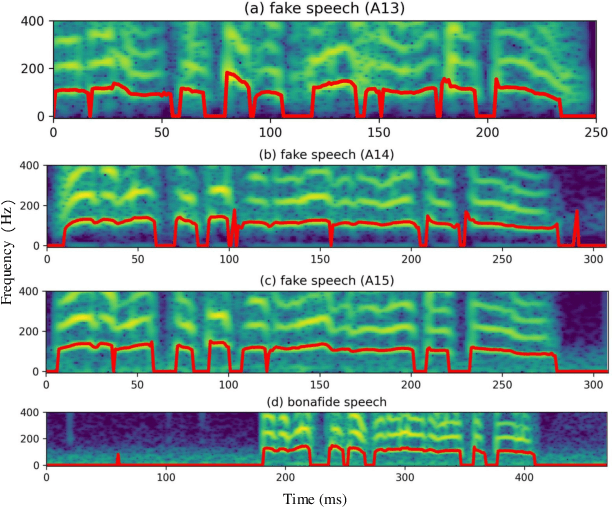
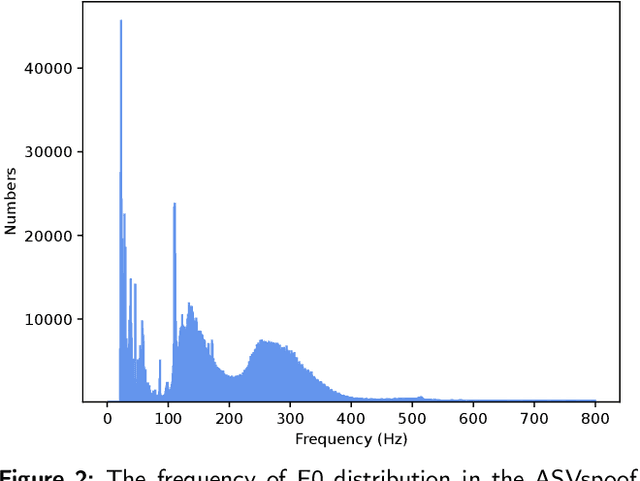
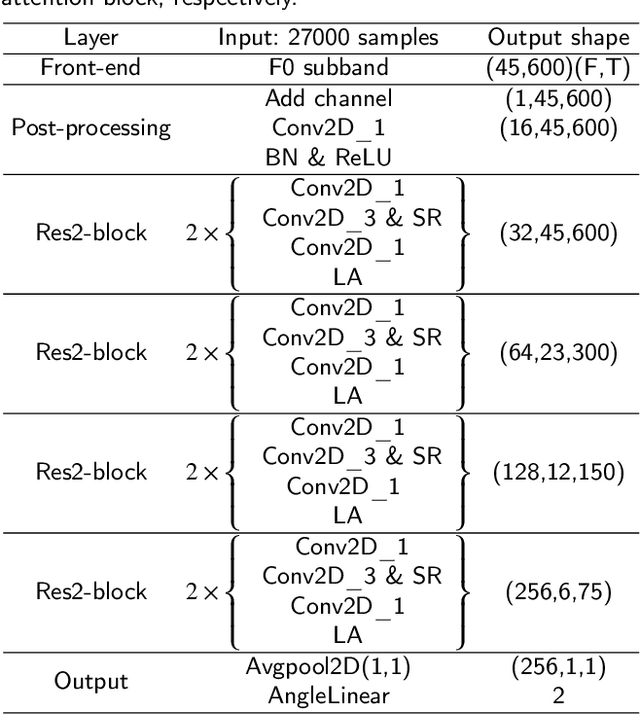
The rhythm of synthetic speech is usually too smooth, which causes that the fundamental frequency (F0) of synthetic speech is significantly different from that of real speech. It is expected that the F0 feature contains the discriminative information for the fake speech detection (FSD) task. In this paper, we propose a novel F0 subband for FSD. In addition, to effectively model the F0 subband so as to improve the performance of FSD, the spatial reconstructed local attention Res2Net (SR-LA Res2Net) is proposed. Specifically, Res2Net is used as a backbone network to obtain multiscale information, and enhanced with a spatial reconstruction mechanism to avoid losing important information when the channel group is constantly superimposed. In addition, local attention is designed to make the model focus on the local information of the F0 subband. Experimental results on the ASVspoof 2019 LA dataset show that our proposed method obtains an equal error rate (EER) of 0.47% and a minimum tandem detection cost function (min t-DCF) of 0.0159, achieving the state-of-the-art performance among all of the single systems.
Joint speech and overlap detection: a benchmark over multiple audio setup and speech domains
Jul 24, 2023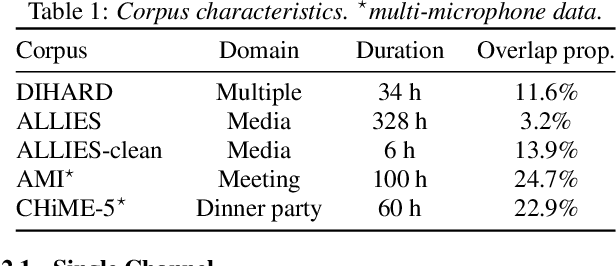
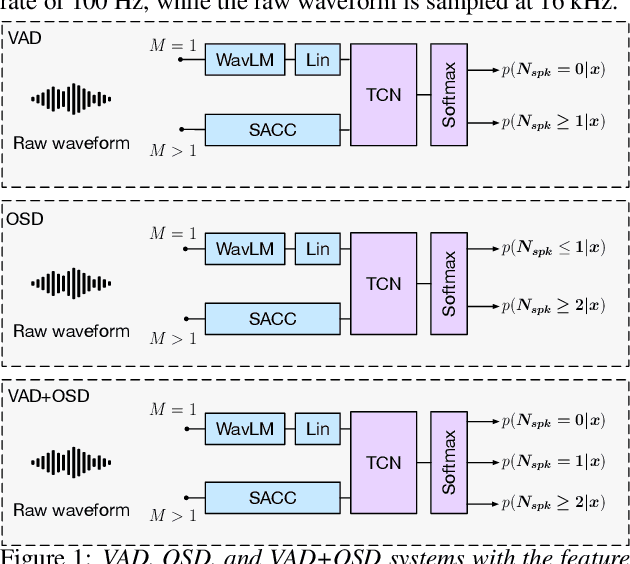
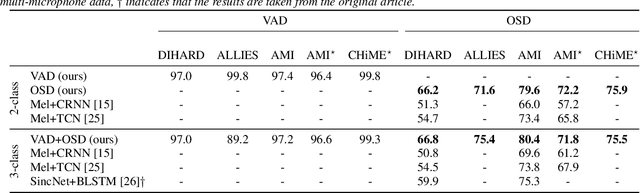
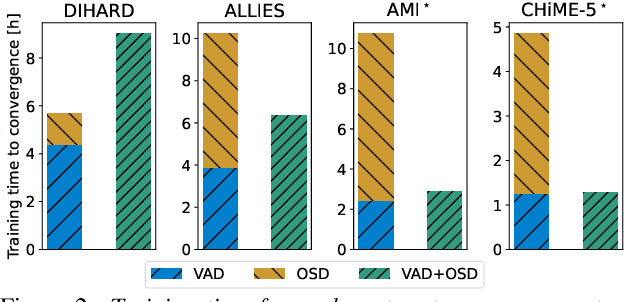
Voice activity and overlapped speech detection (respectively VAD and OSD) are key pre-processing tasks for speaker diarization. The final segmentation performance highly relies on the robustness of these sub-tasks. Recent studies have shown VAD and OSD can be trained jointly using a multi-class classification model. However, these works are often restricted to a specific speech domain, lacking information about the generalization capacities of the systems. This paper proposes a complete and new benchmark of different VAD and OSD models, on multiple audio setups (single/multi-channel) and speech domains (e.g. media, meeting...). Our 2/3-class systems, which combine a Temporal Convolutional Network with speech representations adapted to the setup, outperform state-of-the-art results. We show that the joint training of these two tasks offers similar performances in terms of F1-score to two dedicated VAD and OSD systems while reducing the training cost. This unique architecture can also be used for single and multichannel speech processing.
FinBTech: Blockchain-Based Video and Voice Authentication System for Enhanced Security in Financial Transactions Utilizing FaceNet512 and Gaussian Mixture Models
Oct 28, 2023In the digital age, it is crucial to make sure that financial transactions are as secure and reliable as possible. This abstract offers a ground-breaking method that combines smart contracts, blockchain technology, FaceNet512 for improved face recognition, and Gaussian Mixture Models (GMM) for speech authentication to create a system for video and audio verification that is unmatched. Smart contracts and the immutable ledger of the blockchain are combined to offer a safe and open environment for financial transactions. FaceNet512 and GMM offer multi-factor biometric authentication simultaneously, enhancing security to new heights. By combining cutting-edge technology, this system offers a strong defense against identity theft and illegal access, establishing a new benchmark for safe financial transactions.