 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Audio-Visual Neural Syntax Acquisition
Oct 11, 2023
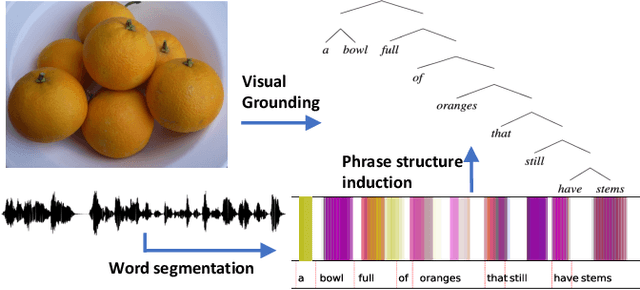

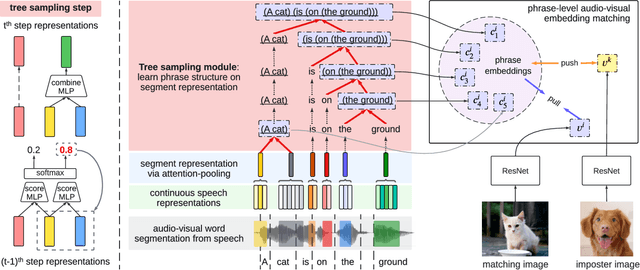
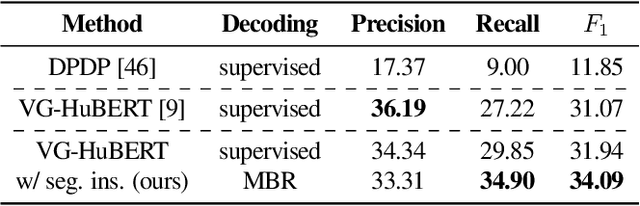
We study phrase structure induction from visually-grounded speech. The core idea is to first segment the speech waveform into sequences of word segments, and subsequently induce phrase structure using the inferred segment-level continuous representations. We present the Audio-Visual Neural Syntax Learner (AV-NSL) that learns phrase structure by listening to audio and looking at images, without ever being exposed to text. By training on paired images and spoken captions, AV-NSL exhibits the capability to infer meaningful phrase structures that are comparable to those derived by naturally-supervised text parsers, for both English and German. Our findings extend prior work in unsupervised language acquisition from speech and grounded grammar induction, and present one approach to bridge the gap between the two topics.
SememeASR: Boosting Performance of End-to-End Speech Recognition against Domain and Long-Tailed Data Shift with Sememe Semantic Knowledge
Sep 04, 2023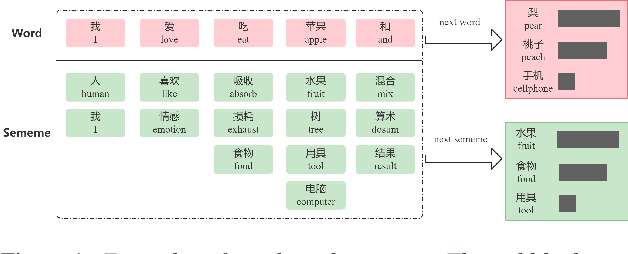
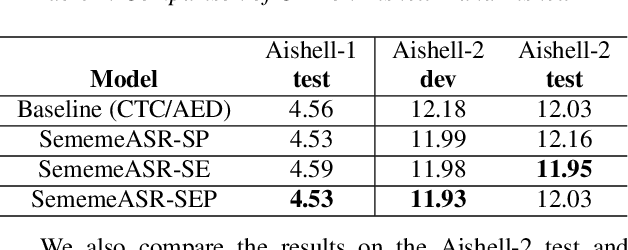
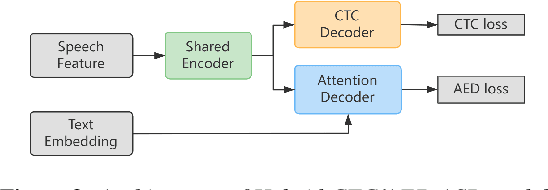
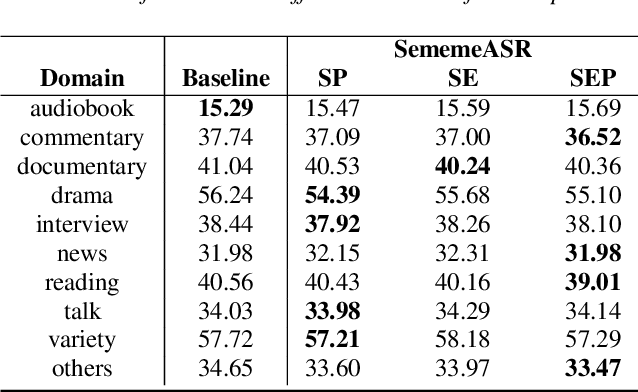
Recently, excellent progress has been made in speech recognition. However, pure data-driven approaches have struggled to solve the problem in domain-mismatch and long-tailed data. Considering that knowledge-driven approaches can help data-driven approaches alleviate their flaws, we introduce sememe-based semantic knowledge information to speech recognition (SememeASR). Sememe, according to the linguistic definition, is the minimum semantic unit in a language and is able to represent the implicit semantic information behind each word very well. Our experiments show that the introduction of sememe information can improve the effectiveness of speech recognition. In addition, our further experiments show that sememe knowledge can improve the model's recognition of long-tailed data and enhance the model's domain generalization ability.
LaughTalk: Expressive 3D Talking Head Generation with Laughter
Nov 02, 2023
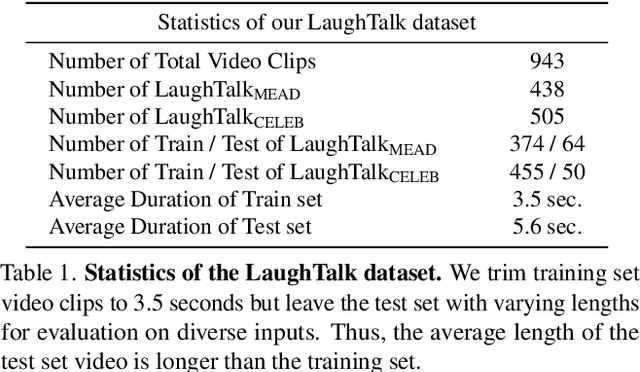

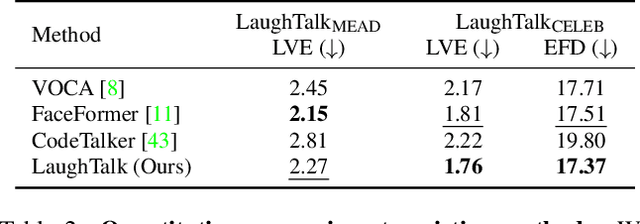
Laughter is a unique expression, essential to affirmative social interactions of humans. Although current 3D talking head generation methods produce convincing verbal articulations, they often fail to capture the vitality and subtleties of laughter and smiles despite their importance in social context. In this paper, we introduce a novel task to generate 3D talking heads capable of both articulate speech and authentic laughter. Our newly curated dataset comprises 2D laughing videos paired with pseudo-annotated and human-validated 3D FLAME parameters and vertices. Given our proposed dataset, we present a strong baseline with a two-stage training scheme: the model first learns to talk and then acquires the ability to express laughter. Extensive experiments demonstrate that our method performs favorably compared to existing approaches in both talking head generation and expressing laughter signals. We further explore potential applications on top of our proposed method for rigging realistic avatars.
Multilingual Speech-to-Speech Translation into Multiple Target Languages
Jul 17, 2023Speech-to-speech translation (S2ST) enables spoken communication between people talking in different languages. Despite a few studies on multilingual S2ST, their focus is the multilinguality on the source side, i.e., the translation from multiple source languages to one target language. We present the first work on multilingual S2ST supporting multiple target languages. Leveraging recent advance in direct S2ST with speech-to-unit and vocoder, we equip these key components with multilingual capability. Speech-to-masked-unit (S2MU) is the multilingual extension of S2U, which applies masking to units which don't belong to the given target language to reduce the language interference. We also propose multilingual vocoder which is trained with language embedding and the auxiliary loss of language identification. On benchmark translation testsets, our proposed multilingual model shows superior performance than bilingual models in the translation from English into $16$ target languages.
VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
Sep 10, 2023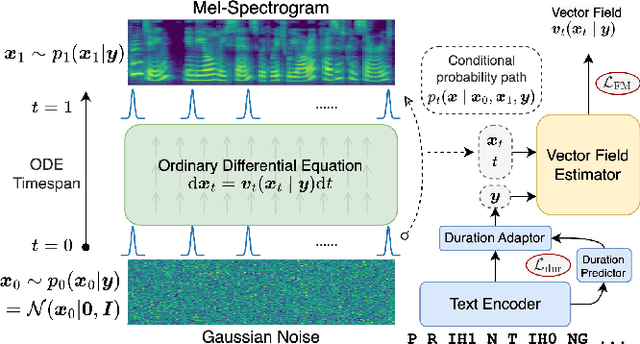
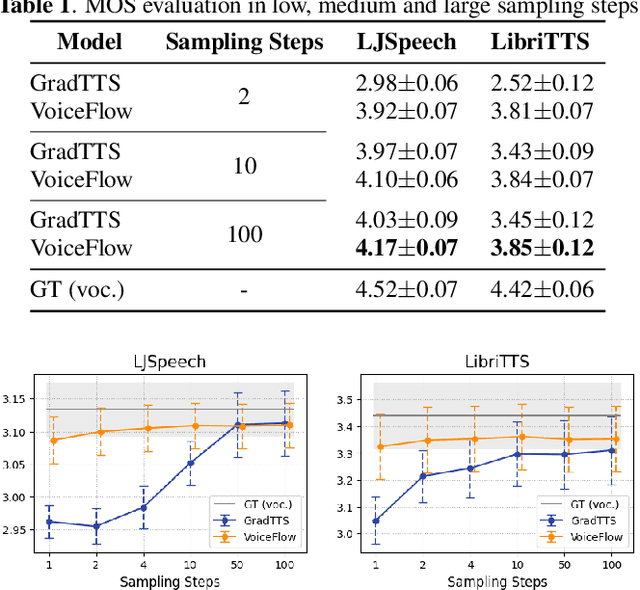
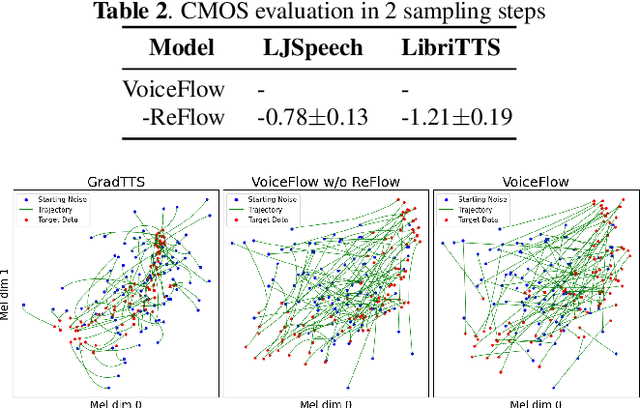
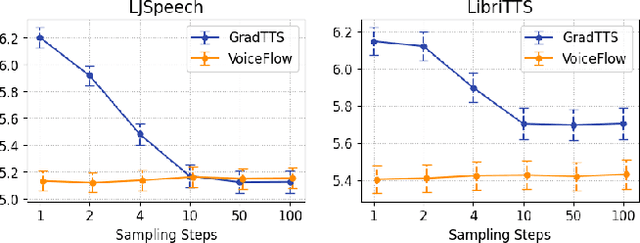
Although diffusion models in text-to-speech have become a popular choice due to their strong generative ability, the intrinsic complexity of sampling from diffusion models harms their efficiency. Alternatively, we propose VoiceFlow, an acoustic model that utilizes a rectified flow matching algorithm to achieve high synthesis quality with a limited number of sampling steps. VoiceFlow formulates the process of generating mel-spectrograms into an ordinary differential equation conditional on text inputs, whose vector field is then estimated. The rectified flow technique then effectively straightens its sampling trajectory for efficient synthesis. Subjective and objective evaluations on both single and multi-speaker corpora showed the superior synthesis quality of VoiceFlow compared to the diffusion counterpart. Ablation studies further verified the validity of the rectified flow technique in VoiceFlow.
Can large-scale vocoded spoofed data improve speech spoofing countermeasure with a self-supervised front end?
Sep 12, 2023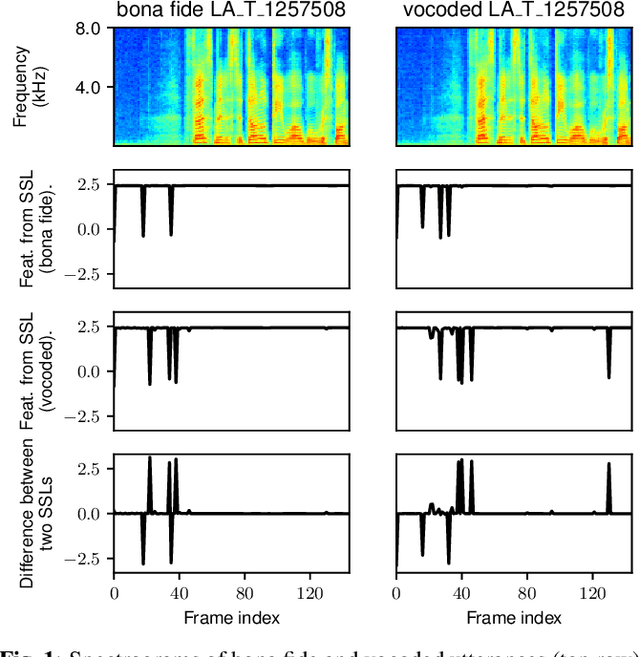
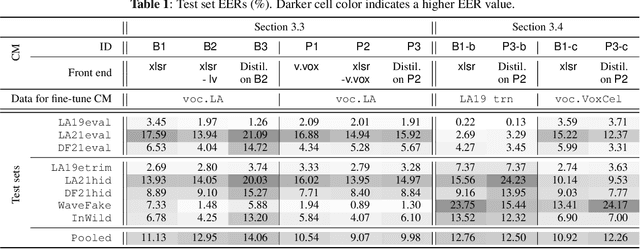
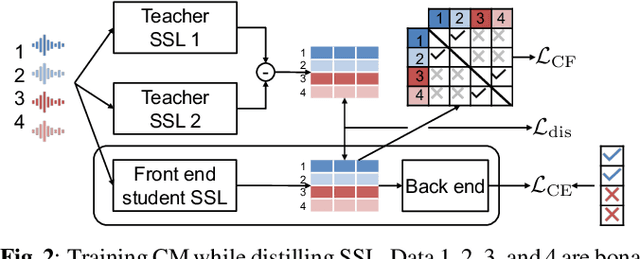
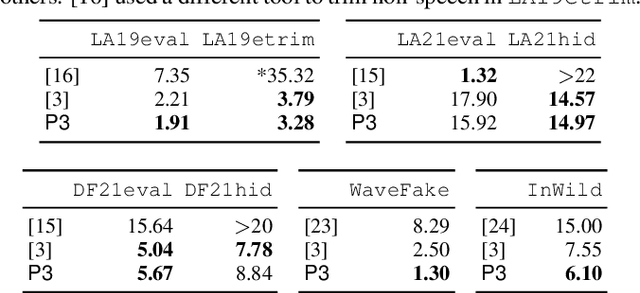
A speech spoofing countermeasure (CM) that discriminates between unseen spoofed and bona fide data requires diverse training data. While many datasets use spoofed data generated by speech synthesis systems, it was recently found that data vocoded by neural vocoders were also effective as the spoofed training data. Since many neural vocoders are fast in building and generation, this study used multiple neural vocoders and created more than 9,000 hours of vocoded data on the basis of the VoxCeleb2 corpus. This study investigates how this large-scale vocoded data can improve spoofing countermeasures that use data-hungry self-supervised learning (SSL) models. Experiments demonstrated that the overall CM performance on multiple test sets improved when using features extracted by an SSL model continually trained on the vocoded data. Further improvement was observed when using a new SSL distilled from the two SSLs before and after the continual training. The CM with the distilled SSL outperformed the previous best model on challenging unseen test sets, including the ASVspoof 2019 logical access, WaveFake, and In-the-Wild.
Sounding Bodies: Modeling 3D Spatial Sound of Humans Using Body Pose and Audio
Nov 01, 2023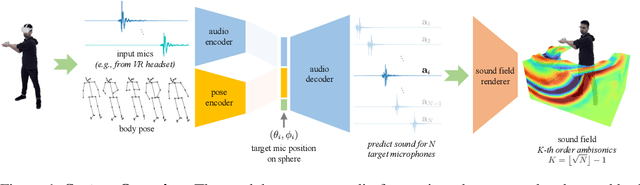

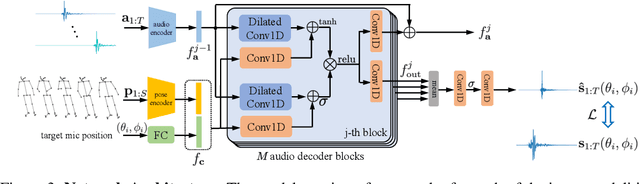
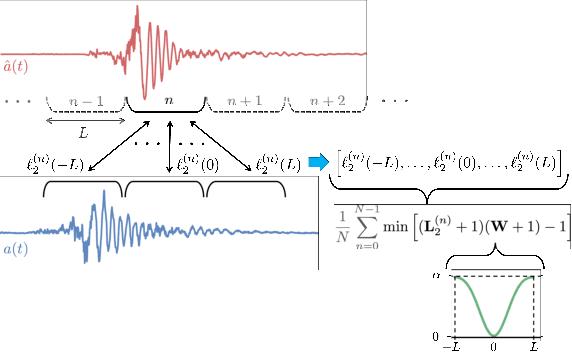
While 3D human body modeling has received much attention in computer vision, modeling the acoustic equivalent, i.e. modeling 3D spatial audio produced by body motion and speech, has fallen short in the community. To close this gap, we present a model that can generate accurate 3D spatial audio for full human bodies. The system consumes, as input, audio signals from headset microphones and body pose, and produces, as output, a 3D sound field surrounding the transmitter's body, from which spatial audio can be rendered at any arbitrary position in the 3D space. We collect a first-of-its-kind multimodal dataset of human bodies, recorded with multiple cameras and a spherical array of 345 microphones. In an empirical evaluation, we demonstrate that our model can produce accurate body-induced sound fields when trained with a suitable loss. Dataset and code are available online.
LightGrad: Lightweight Diffusion Probabilistic Model for Text-to-Speech
Aug 31, 2023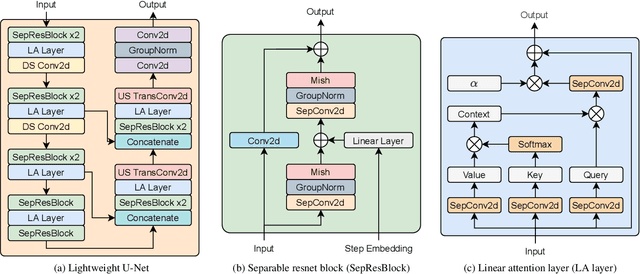
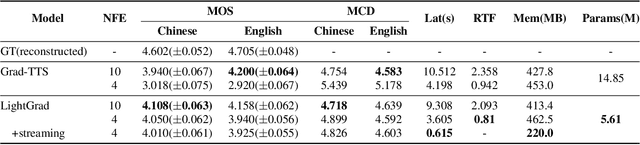
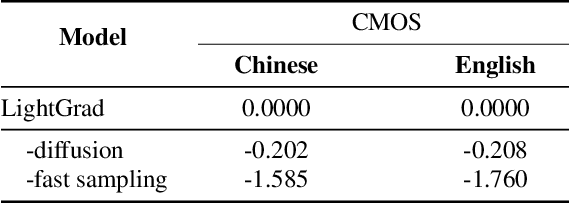
Recent advances in neural text-to-speech (TTS) models bring thousands of TTS applications into daily life, where models are deployed in cloud to provide services for customs. Among these models are diffusion probabilistic models (DPMs), which can be stably trained and are more parameter-efficient compared with other generative models. As transmitting data between customs and the cloud introduces high latency and the risk of exposing private data, deploying TTS models on edge devices is preferred. When implementing DPMs onto edge devices, there are two practical problems. First, current DPMs are not lightweight enough for resource-constrained devices. Second, DPMs require many denoising steps in inference, which increases latency. In this work, we present LightGrad, a lightweight DPM for TTS. LightGrad is equipped with a lightweight U-Net diffusion decoder and a training-free fast sampling technique, reducing both model parameters and inference latency. Streaming inference is also implemented in LightGrad to reduce latency further. Compared with Grad-TTS, LightGrad achieves 62.2% reduction in paramters, 65.7% reduction in latency, while preserving comparable speech quality on both Chinese Mandarin and English in 4 denoising steps.
C2G2: Controllable Co-speech Gesture Generation with Latent Diffusion Model
Aug 29, 2023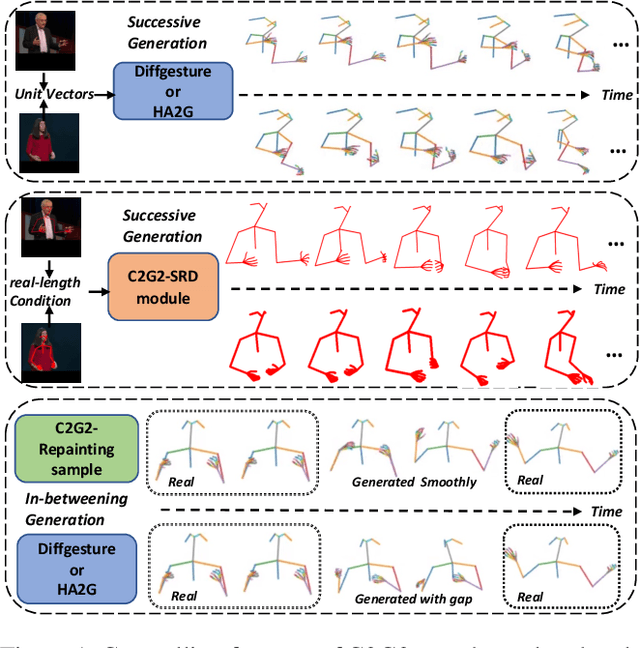
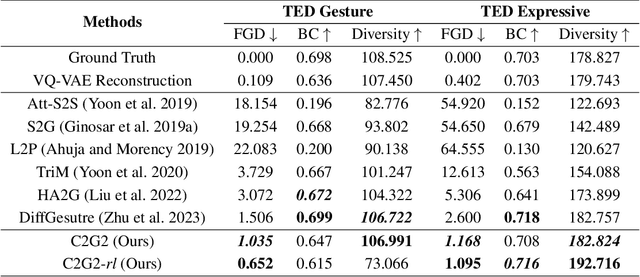
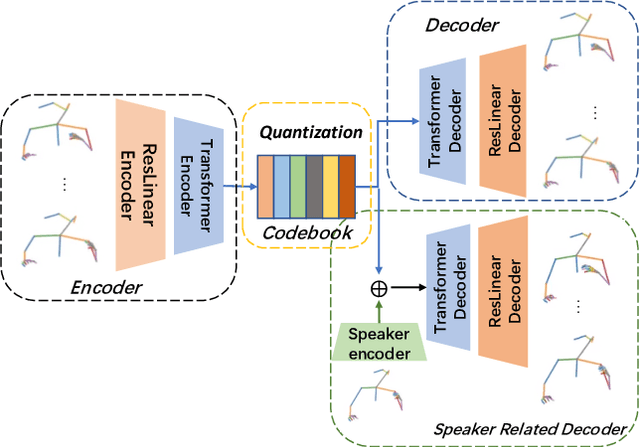

Co-speech gesture generation is crucial for automatic digital avatar animation. However, existing methods suffer from issues such as unstable training and temporal inconsistency, particularly in generating high-fidelity and comprehensive gestures. Additionally, these methods lack effective control over speaker identity and temporal editing of the generated gestures. Focusing on capturing temporal latent information and applying practical controlling, we propose a Controllable Co-speech Gesture Generation framework, named C2G2. Specifically, we propose a two-stage temporal dependency enhancement strategy motivated by latent diffusion models. We further introduce two key features to C2G2, namely a speaker-specific decoder to generate speaker-related real-length skeletons and a repainting strategy for flexible gesture generation/editing. Extensive experiments on benchmark gesture datasets verify the effectiveness of our proposed C2G2 compared with several state-of-the-art baselines. The link of the project demo page can be found at https://c2g2-gesture.github.io/c2_gesture
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Aug 14, 2023
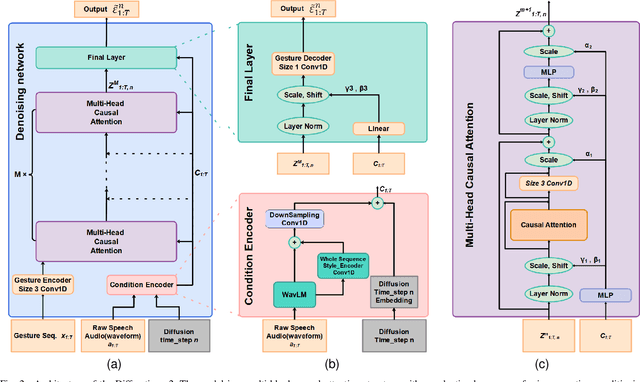
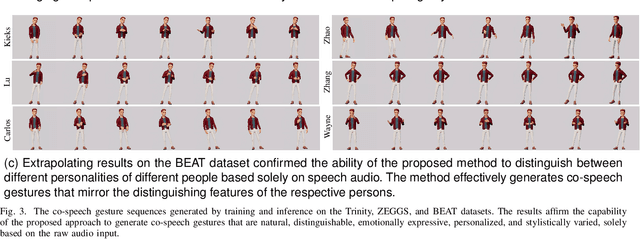
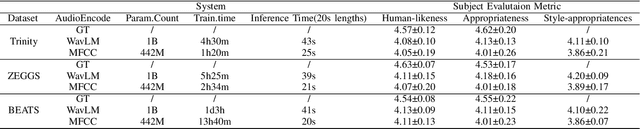
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces "diffmotion-v2," a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.