 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Multilingual Speech-to-Speech Translation into Multiple Target Languages
Jul 17, 2023
Speech-to-speech translation (S2ST) enables spoken communication between people talking in different languages. Despite a few studies on multilingual S2ST, their focus is the multilinguality on the source side, i.e., the translation from multiple source languages to one target language. We present the first work on multilingual S2ST supporting multiple target languages. Leveraging recent advance in direct S2ST with speech-to-unit and vocoder, we equip these key components with multilingual capability. Speech-to-masked-unit (S2MU) is the multilingual extension of S2U, which applies masking to units which don't belong to the given target language to reduce the language interference. We also propose multilingual vocoder which is trained with language embedding and the auxiliary loss of language identification. On benchmark translation testsets, our proposed multilingual model shows superior performance than bilingual models in the translation from English into $16$ target languages.
Privacy-preserving and Privacy-attacking Approaches for Speech and Audio -- A Survey
Sep 26, 2023In contemporary society, voice-controlled devices, such as smartphones and home assistants, have become pervasive due to their advanced capabilities and functionality. The always-on nature of their microphones offers users the convenience of readily accessing these devices. However, recent research and events have revealed that such voice-controlled devices are prone to various forms of malicious attacks, hence making it a growing concern for both users and researchers to safeguard against such attacks. Despite the numerous studies that have investigated adversarial attacks and privacy preservation for images, a conclusive study of this nature has not been conducted for the audio domain. Therefore, this paper aims to examine existing approaches for privacy-preserving and privacy-attacking strategies for audio and speech. To achieve this goal, we classify the attack and defense scenarios into several categories and provide detailed analysis of each approach. We also interpret the dissimilarities between the various approaches, highlight their contributions, and examine their limitations. Our investigation reveals that voice-controlled devices based on neural networks are inherently susceptible to specific types of attacks. Although it is possible to enhance the robustness of such models to certain forms of attack, more sophisticated approaches are required to comprehensively safeguard user privacy.
Comparative Analysis of Transfer Learning in Deep Learning Text-to-Speech Models on a Few-Shot, Low-Resource, Customized Dataset
Oct 08, 2023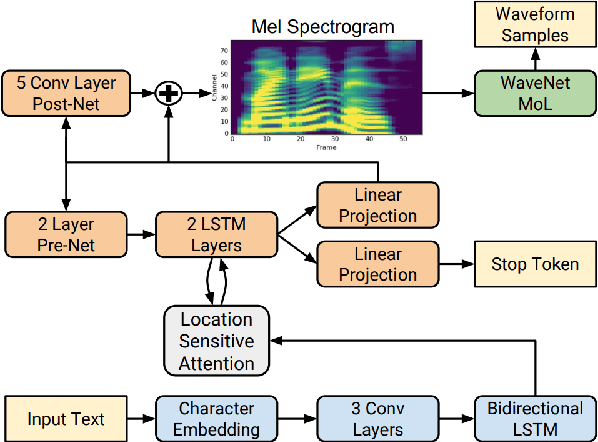
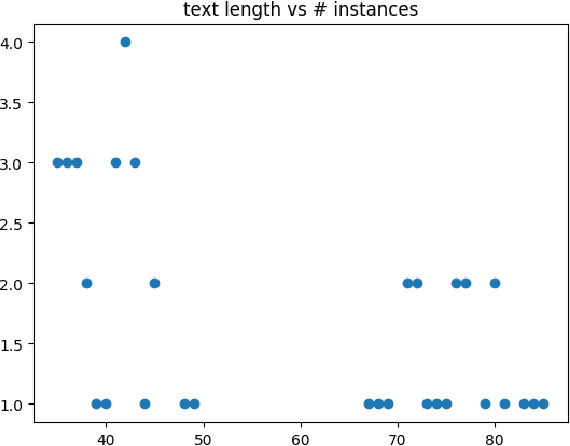
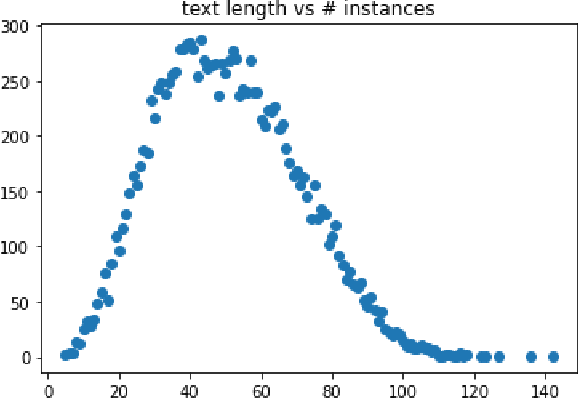
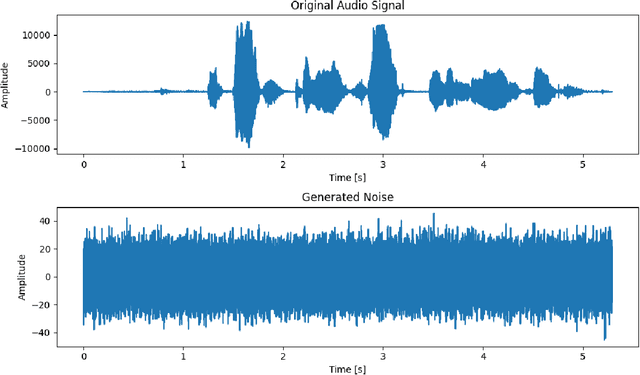
Text-to-Speech (TTS) synthesis using deep learning relies on voice quality. Modern TTS models are advanced, but they need large amount of data. Given the growing computational complexity of these models and the scarcity of large, high-quality datasets, this research focuses on transfer learning, especially on few-shot, low-resource, and customized datasets. In this research, "low-resource" specifically refers to situations where there are limited amounts of training data, such as a small number of audio recordings and corresponding transcriptions for a particular language or dialect. This thesis, is rooted in the pressing need to find TTS models that require less training time, fewer data samples, yet yield high-quality voice output. The research evaluates TTS state-of-the-art model transfer learning capabilities through a thorough technical analysis. It then conducts a hands-on experimental analysis to compare models' performance in a constrained dataset. This study investigates the efficacy of modern TTS systems with transfer learning on specialized datasets and a model that balances training efficiency and synthesis quality. Initial hypotheses suggest that transfer learning could significantly improve TTS models' performance on compact datasets, and an optimal model may exist for such unique conditions. This thesis predicts a rise in transfer learning in TTS as data scarcity increases. In the future, custom TTS applications will favour models optimized for specific datasets over generic, data-intensive ones.
Federated Learning with Differential Privacy for End-to-End Speech Recognition
Sep 29, 2023While federated learning (FL) has recently emerged as a promising approach to train machine learning models, it is limited to only preliminary explorations in the domain of automatic speech recognition (ASR). Moreover, FL does not inherently guarantee user privacy and requires the use of differential privacy (DP) for robust privacy guarantees. However, we are not aware of prior work on applying DP to FL for ASR. In this paper, we aim to bridge this research gap by formulating an ASR benchmark for FL with DP and establishing the first baselines. First, we extend the existing research on FL for ASR by exploring different aspects of recent $\textit{large end-to-end transformer models}$: architecture design, seed models, data heterogeneity, domain shift, and impact of cohort size. With a $\textit{practical}$ number of central aggregations we are able to train $\textbf{FL models}$ that are \textbf{nearly optimal} even with heterogeneous data, a seed model from another domain, or no pre-trained seed model. Second, we apply DP to FL for ASR, which is non-trivial since DP noise severely affects model training, especially for large transformer models, due to highly imbalanced gradients in the attention block. We counteract the adverse effect of DP noise by reviving per-layer clipping and explaining why its effect is more apparent in our case than in the prior work. Remarkably, we achieve user-level ($7.2$, $10^{-9}$)-$\textbf{DP}$ (resp. ($4.5$, $10^{-9}$)-$\textbf{DP}$) with a 1.3% (resp. 4.6%) absolute drop in the word error rate for extrapolation to high (resp. low) population scale for $\textbf{FL with DP in ASR}$.
Deepfake audio as a data augmentation technique for training automatic speech to text transcription models
Sep 22, 2023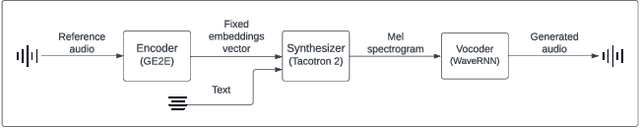
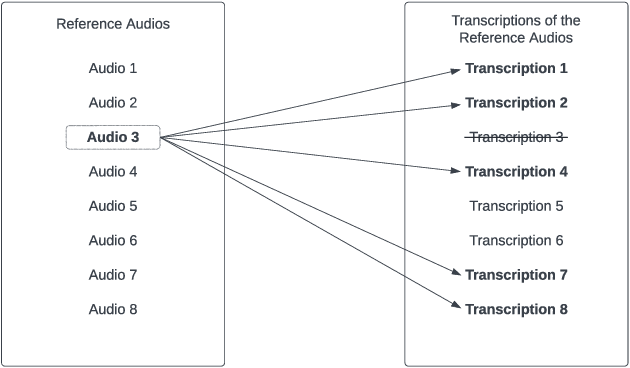
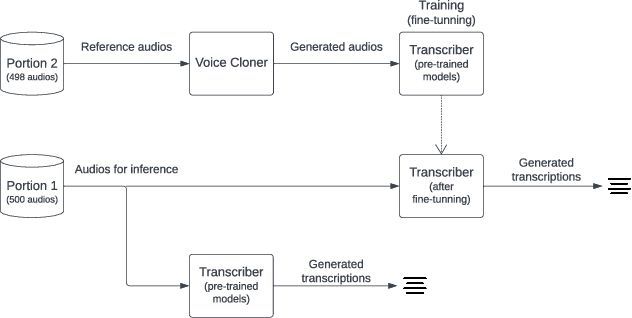
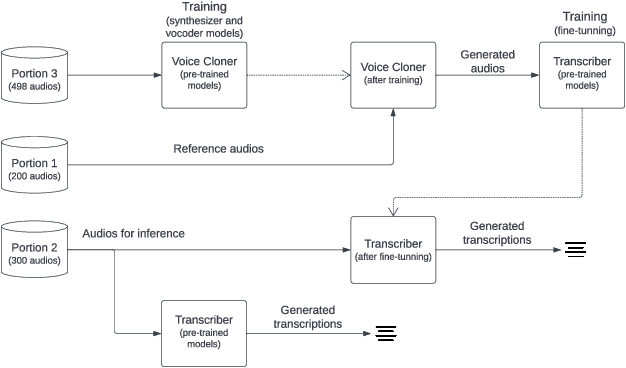
To train transcriptor models that produce robust results, a large and diverse labeled dataset is required. Finding such data with the necessary characteristics is a challenging task, especially for languages less popular than English. Moreover, producing such data requires significant effort and often money. Therefore, a strategy to mitigate this problem is the use of data augmentation techniques. In this work, we propose a framework that approaches data augmentation based on deepfake audio. To validate the produced framework, experiments were conducted using existing deepfake and transcription models. A voice cloner and a dataset produced by Indians (in English) were selected, ensuring the presence of a single accent in the dataset. Subsequently, the augmented data was used to train speech to text models in various scenarios.
Augmenting conformers with structured state space models for online speech recognition
Sep 15, 2023
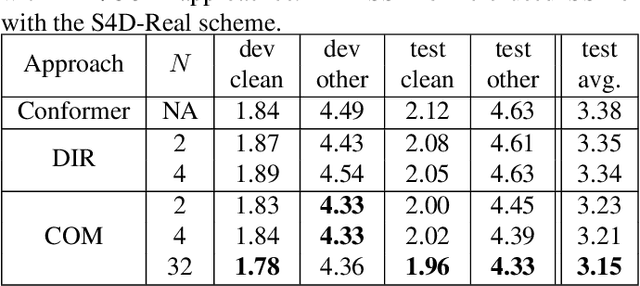
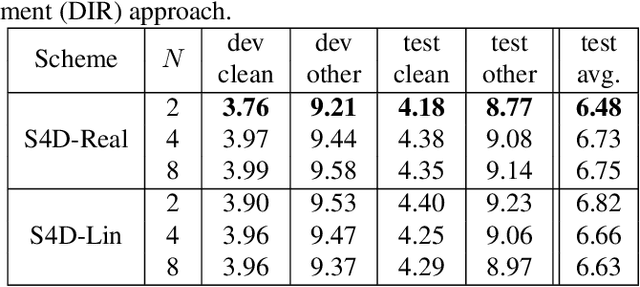
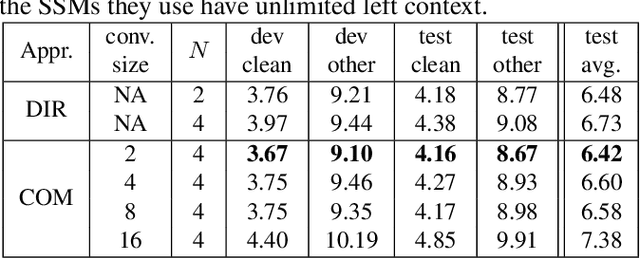
Online speech recognition, where the model only accesses context to the left, is an important and challenging use case for ASR systems. In this work, we investigate augmenting neural encoders for online ASR by incorporating structured state-space sequence models (S4), which are a family of models that provide a parameter-efficient way of accessing arbitrarily long left context. We perform systematic ablation studies to compare variants of S4 models and propose two novel approaches that combine them with convolutions. We find that the most effective design is to stack a small S4 using real-valued recurrent weights with a local convolution, allowing them to work complementarily. Our best model achieves WERs of 4.01%/8.53% on test sets from Librispeech, outperforming Conformers with extensively tuned convolution.
AudioFool: Fast, Universal and synchronization-free Cross-Domain Attack on Speech Recognition
Sep 20, 2023Automatic Speech Recognition systems have been shown to be vulnerable to adversarial attacks that manipulate the command executed on the device. Recent research has focused on exploring methods to create such attacks, however, some issues relating to Over-The-Air (OTA) attacks have not been properly addressed. In our work, we examine the needed properties of robust attacks compatible with the OTA model, and we design a method of generating attacks with arbitrary such desired properties, namely the invariance to synchronization, and the robustness to filtering: this allows a Denial-of-Service (DoS) attack against ASR systems. We achieve these characteristics by constructing attacks in a modified frequency domain through an inverse Fourier transform. We evaluate our method on standard keyword classification tasks and analyze it in OTA, and we analyze the properties of the cross-domain attacks to explain the efficiency of the approach.
LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT
Oct 11, 2023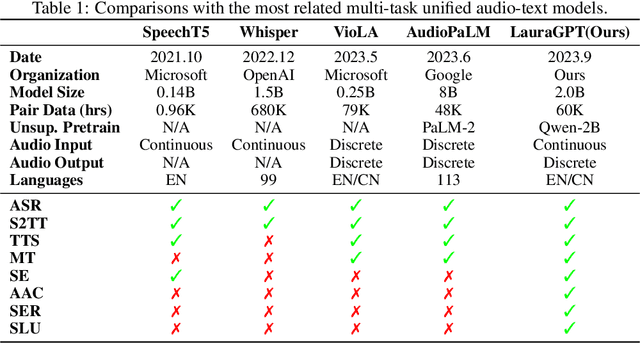
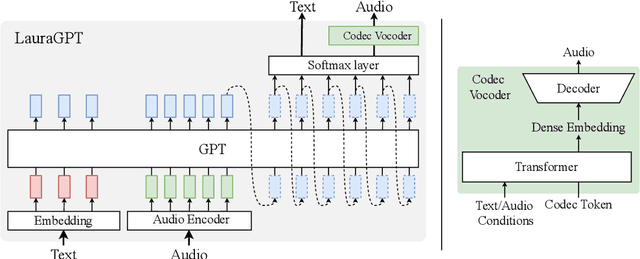
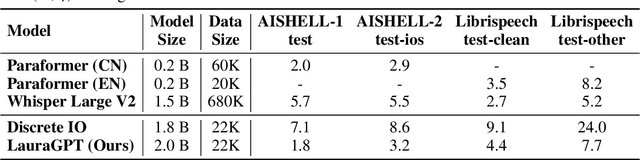

Generative Pre-trained Transformer (GPT) models have achieved remarkable performance on various natural language processing tasks. However, there has been limited research on applying similar frameworks to audio tasks. Previously proposed large language models for audio tasks either lack sufficient quantitative evaluations, or are limited to tasks for recognizing and understanding audio content, or significantly underperform existing state-of-the-art (SOTA) models. In this paper, we propose LauraGPT, a unified GPT model for audio recognition, understanding, and generation. LauraGPT is a versatile language model that can process both audio and text inputs and generate outputs in either modalities. It can perform a wide range of tasks related to content, semantics, paralinguistics, and audio-signal analysis. Some of its noteworthy tasks include automatic speech recognition, speech-to-text translation, text-to-speech synthesis, machine translation, speech enhancement, automated audio captioning, speech emotion recognition, and spoken language understanding. To achieve this goal, we use a combination of continuous and discrete features for audio. We encode input audio into continuous representations using an audio encoder and decode output audio from discrete codec codes. We then fine-tune a large decoder-only Transformer-based language model on multiple audio-to-text, text-to-audio, audio-to-audio, and text-to-text tasks using a supervised multitask learning approach. Extensive experiments show that LauraGPT achieves competitive or superior performance compared to existing SOTA models on various audio processing benchmarks.
SememeASR: Boosting Performance of End-to-End Speech Recognition against Domain and Long-Tailed Data Shift with Sememe Semantic Knowledge
Sep 04, 2023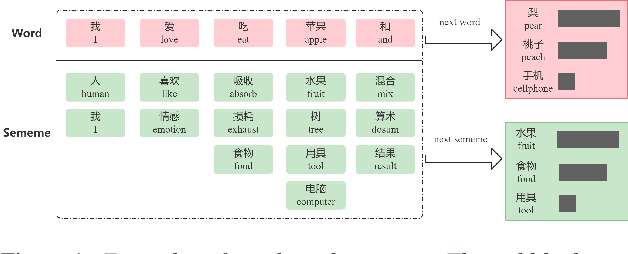
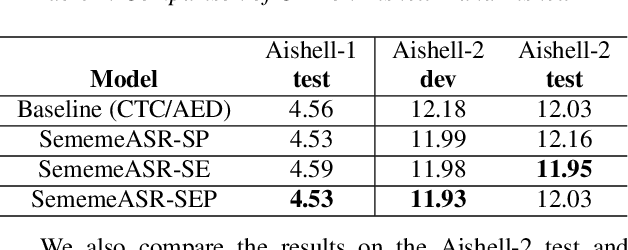
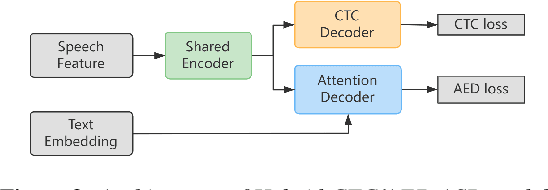
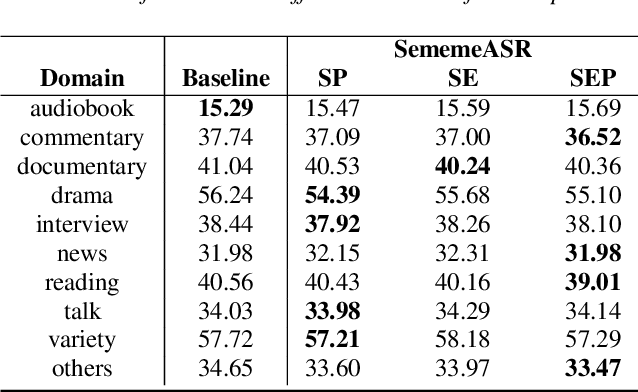
Recently, excellent progress has been made in speech recognition. However, pure data-driven approaches have struggled to solve the problem in domain-mismatch and long-tailed data. Considering that knowledge-driven approaches can help data-driven approaches alleviate their flaws, we introduce sememe-based semantic knowledge information to speech recognition (SememeASR). Sememe, according to the linguistic definition, is the minimum semantic unit in a language and is able to represent the implicit semantic information behind each word very well. Our experiments show that the introduction of sememe information can improve the effectiveness of speech recognition. In addition, our further experiments show that sememe knowledge can improve the model's recognition of long-tailed data and enhance the model's domain generalization ability.
BanLemma: A Word Formation Dependent Rule and Dictionary Based Bangla Lemmatizer
Nov 06, 2023Lemmatization holds significance in both natural language processing (NLP) and linguistics, as it effectively decreases data density and aids in comprehending contextual meaning. However, due to the highly inflected nature and morphological richness, lemmatization in Bangla text poses a complex challenge. In this study, we propose linguistic rules for lemmatization and utilize a dictionary along with the rules to design a lemmatizer specifically for Bangla. Our system aims to lemmatize words based on their parts of speech class within a given sentence. Unlike previous rule-based approaches, we analyzed the suffix marker occurrence according to the morpho-syntactic values and then utilized sequences of suffix markers instead of entire suffixes. To develop our rules, we analyze a large corpus of Bangla text from various domains, sources, and time periods to observe the word formation of inflected words. The lemmatizer achieves an accuracy of 96.36% when tested against a manually annotated test dataset by trained linguists and demonstrates competitive performance on three previously published Bangla lemmatization datasets. We are making the code and datasets publicly available at https://github.com/eblict-gigatech/BanLemma in order to contribute to the further advancement of Bangla NLP.