 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
BUT CHiME-7 system description
Oct 18, 2023
This paper describes the joint effort of Brno University of Technology (BUT), AGH University of Krakow and University of Buenos Aires on the development of Automatic Speech Recognition systems for the CHiME-7 Challenge. We train and evaluate various end-to-end models with several toolkits. We heavily relied on Guided Source Separation (GSS) to convert multi-channel audio to single channel. The ASR is leveraging speech representations from models pre-trained by self-supervised learning, and we do a fusion of several ASR systems. In addition, we modified external data from the LibriSpeech corpus to become a close domain and added it to the training. Our efforts were focused on the far-field acoustic robustness sub-track of Task 1 - Distant Automatic Speech Recognition (DASR), our systems use oracle segmentation.
Unsupervised Active Learning: Optimizing Labeling Cost-Effectiveness for Automatic Speech Recognition
Aug 28, 2023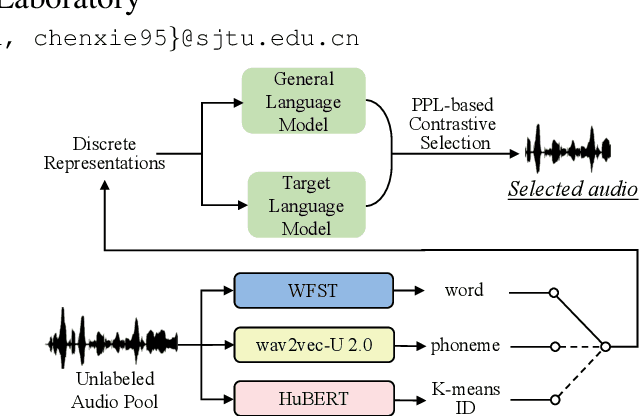
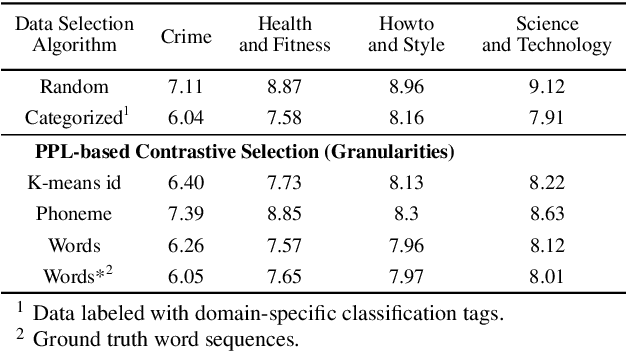
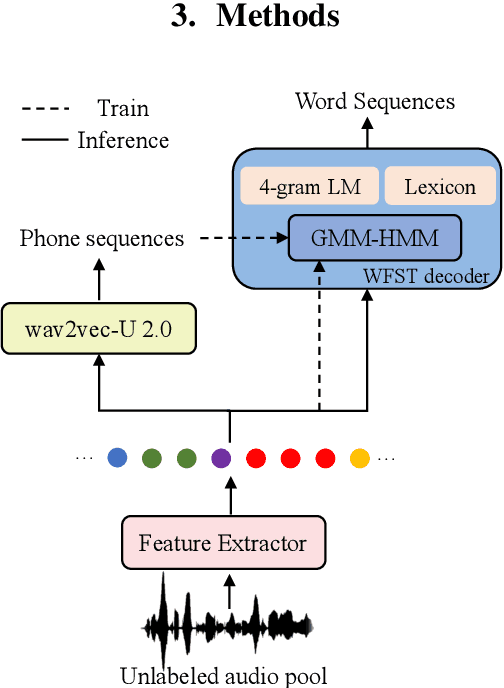
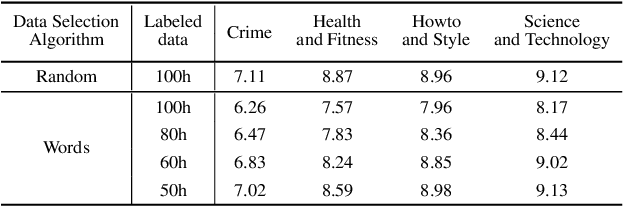
In recent years, speech-based self-supervised learning (SSL) has made significant progress in various tasks, including automatic speech recognition (ASR). An ASR model with decent performance can be realized by fine-tuning an SSL model with a small fraction of labeled data. Reducing the demand for labeled data is always of great practical value. In this paper, we further extend the use of SSL to cut down labeling costs with active learning. Three types of units on different granularities are derived from speech signals in an unsupervised way, and their effects are compared by applying a contrastive data selection method. The experimental results show that our proposed data selection framework can effectively improve the word error rate (WER) by more than 11% with the same amount of labeled data, or halve the labeling cost while maintaining the same WER, compared to random selection.
Text-Only Domain Adaptation for End-to-End Speech Recognition through Down-Sampling Acoustic Representation
Sep 04, 2023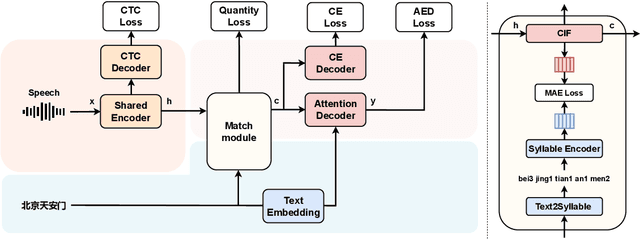
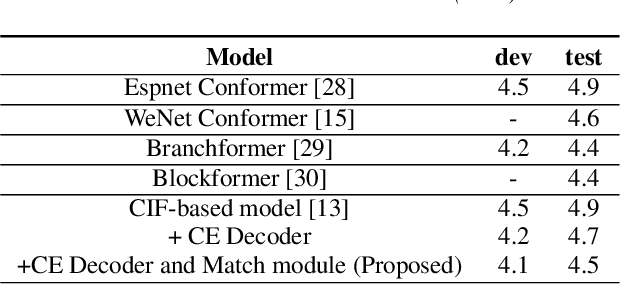
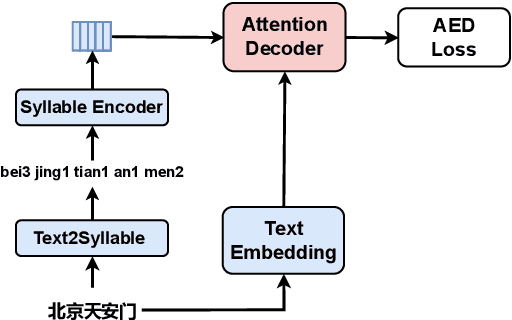

Mapping two modalities, speech and text, into a shared representation space, is a research topic of using text-only data to improve end-to-end automatic speech recognition (ASR) performance in new domains. However, the length of speech representation and text representation is inconsistent. Although the previous method up-samples the text representation to align with acoustic modality, it may not match the expected actual duration. In this paper, we proposed novel representations match strategy through down-sampling acoustic representation to align with text modality. By introducing a continuous integrate-and-fire (CIF) module generating acoustic representations consistent with token length, our ASR model can learn unified representations from both modalities better, allowing for domain adaptation using text-only data of the target domain. Experiment results of new domain data demonstrate the effectiveness of the proposed method.
Investigating Speaker Embedding Disentanglement on Natural Read Speech
Aug 08, 2023
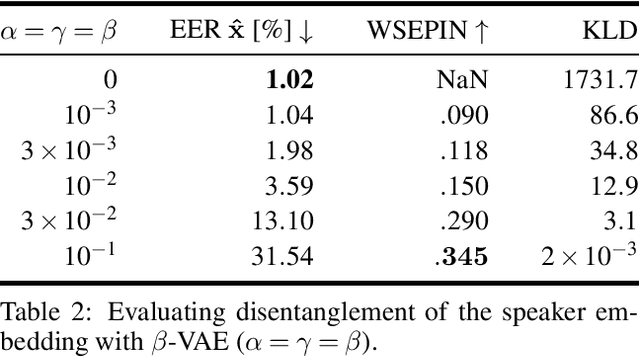
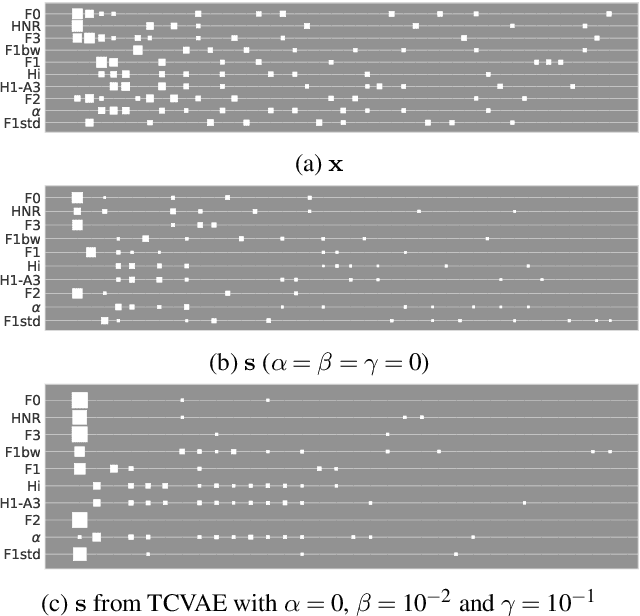
Disentanglement is the task of learning representations that identify and separate factors that explain the variation observed in data. Disentangled representations are useful to increase the generalizability, explainability, and fairness of data-driven models. Only little is known about how well such disentanglement works for speech representations. A major challenge when tackling disentanglement for speech representations are the unknown generative factors underlying the speech signal. In this work, we investigate to what degree speech representations encoding speaker identity can be disentangled. To quantify disentanglement, we identify acoustic features that are highly speaker-variant and can serve as proxies for the factors of variation underlying speech. We find that disentanglement of the speaker embedding is limited when trained with standard objectives promoting disentanglement but can be improved over vanilla representation learning to some extent.
Towards Matching Phones and Speech Representations
Oct 26, 2023Learning phone types from phone instances has been a long-standing problem, while still being open. In this work, we revisit this problem in the context of self-supervised learning, and pose it as the problem of matching cluster centroids to phone embeddings. We study two key properties that enable matching, namely, whether cluster centroids of self-supervised representations reduce the variability of phone instances and respect the relationship among phones. We then use the matching result to produce pseudo-labels and introduce a new loss function for improving self-supervised representations. Our experiments show that the matching result captures the relationship among phones. Training the new loss function jointly with the regular self-supervised losses, such as APC and CPC, significantly improves the downstream phone classification.
Decoder-only Architecture for Speech Recognition with CTC Prompts and Text Data Augmentation
Sep 16, 2023Collecting audio-text pairs is expensive; however, it is much easier to access text-only data. Unless using shallow fusion, end-to-end automatic speech recognition (ASR) models require architecture modifications or additional training schemes to use text-only data. Inspired by recent advances in decoder-only language models (LMs), such as GPT-3 and PaLM adopted for speech-processing tasks, we propose using a decoder-only architecture for ASR with simple text augmentation. To provide audio information, encoder features compressed by CTC prediction are used as prompts for the decoder, which can be regarded as refining CTC prediction using the decoder-only model. Because the decoder architecture is the same as an autoregressive LM, it is simple to enhance the model by leveraging external text data with LM training. An experimental comparison using LibriSpeech and Switchboard shows that our proposed models with text augmentation training reduced word error rates from ordinary CTC by 0.3% and 1.4% on LibriSpeech test-clean and testother set, respectively, and 2.9% and 5.0% on Switchboard and CallHome. The proposed model had advantage on computational efficiency compared with conventional encoder-decoder ASR models with a similar parameter setup, and outperformed them on the LibriSpeech 100h and Switchboard training scenarios.
Identifying depression-related topics in smartphone-collected free-response speech recordings using an automatic speech recognition system and a deep learning topic model
Aug 22, 2023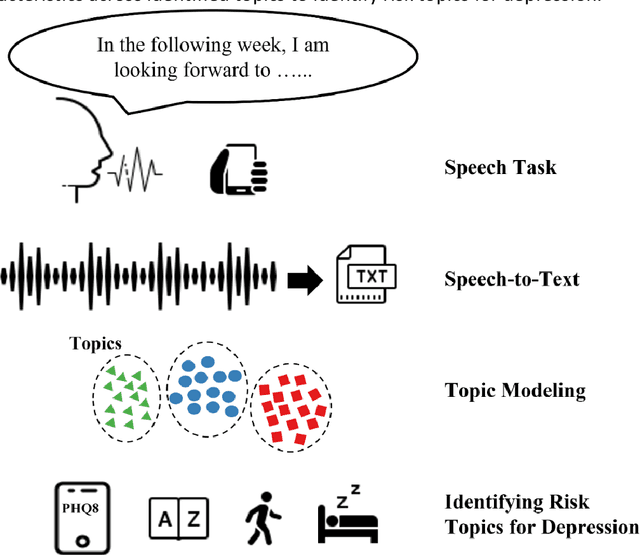
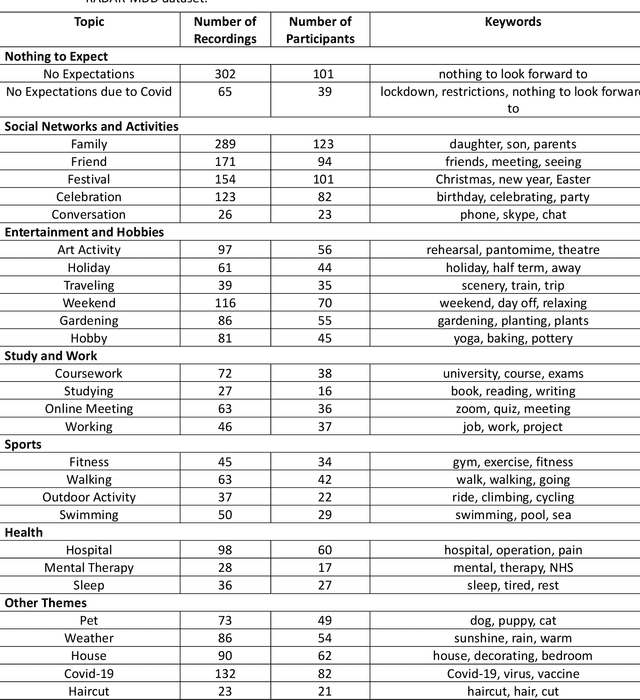
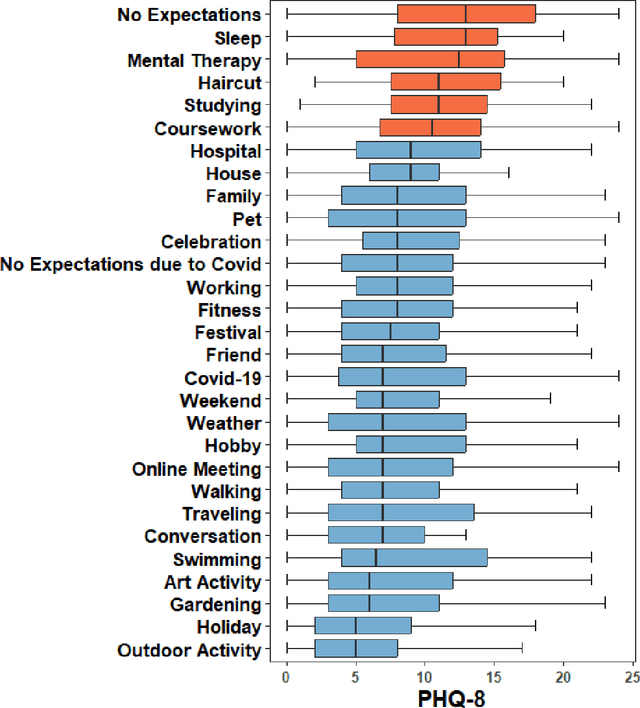
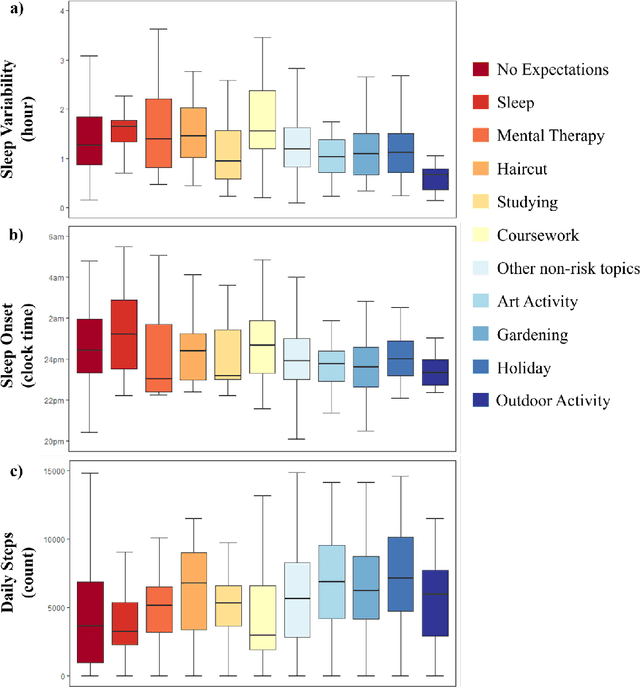
Language use has been shown to correlate with depression, but large-scale validation is needed. Traditional methods like clinic studies are expensive. So, natural language processing has been employed on social media to predict depression, but limitations remain-lack of validated labels, biased user samples, and no context. Our study identified 29 topics in 3919 smartphone-collected speech recordings from 265 participants using the Whisper tool and BERTopic model. Six topics with a median PHQ-8 greater than or equal to 10 were regarded as risk topics for depression: No Expectations, Sleep, Mental Therapy, Haircut, Studying, and Coursework. To elucidate the topic emergence and associations with depression, we compared behavioral (from wearables) and linguistic characteristics across identified topics. The correlation between topic shifts and changes in depression severity over time was also investigated, indicating the importance of longitudinally monitoring language use. We also tested the BERTopic model on a similar smaller dataset (356 speech recordings from 57 participants), obtaining some consistent results. In summary, our findings demonstrate specific speech topics may indicate depression severity. The presented data-driven workflow provides a practical approach to collecting and analyzing large-scale speech data from real-world settings for digital health research.
Pruning Self-Attention for Zero-Shot Multi-Speaker Text-to-Speech
Aug 28, 2023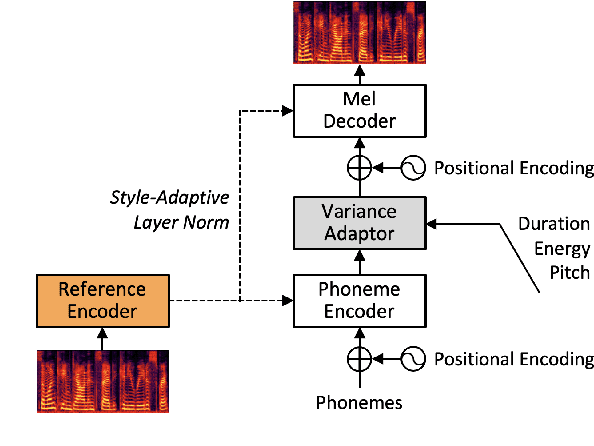
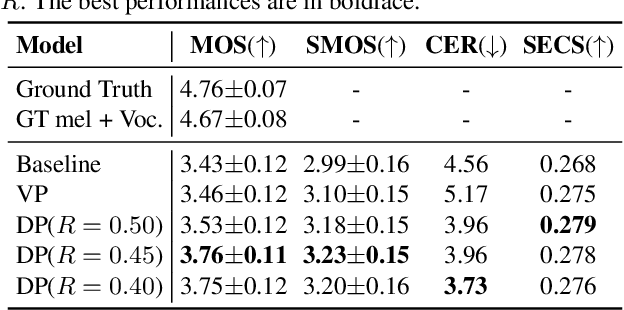
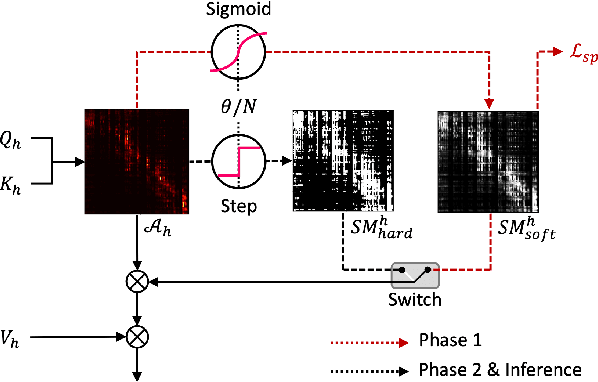

For personalized speech generation, a neural text-to-speech (TTS) model must be successfully implemented with limited data from a target speaker. To this end, the baseline TTS model needs to be amply generalized to out-of-domain data (i.e., target speaker's speech). However, approaches to address this out-of-domain generalization problem in TTS have yet to be thoroughly studied. In this work, we propose an effective pruning method for a transformer known as sparse attention, to improve the TTS model's generalization abilities. In particular, we prune off redundant connections from self-attention layers whose attention weights are below the threshold. To flexibly determine the pruning strength for searching optimal degree of generalization, we also propose a new differentiable pruning method that allows the model to automatically learn the thresholds. Evaluations on zero-shot multi-speaker TTS verify the effectiveness of our method in terms of voice quality and speaker similarity.
* INTERSPEECH 2023
ViSoBERT: A Pre-Trained Language Model for Vietnamese Social Media Text Processing
Oct 28, 2023English and Chinese, known as resource-rich languages, have witnessed the strong development of transformer-based language models for natural language processing tasks. Although Vietnam has approximately 100M people speaking Vietnamese, several pre-trained models, e.g., PhoBERT, ViBERT, and vELECTRA, performed well on general Vietnamese NLP tasks, including POS tagging and named entity recognition. These pre-trained language models are still limited to Vietnamese social media tasks. In this paper, we present the first monolingual pre-trained language model for Vietnamese social media texts, ViSoBERT, which is pre-trained on a large-scale corpus of high-quality and diverse Vietnamese social media texts using XLM-R architecture. Moreover, we explored our pre-trained model on five important natural language downstream tasks on Vietnamese social media texts: emotion recognition, hate speech detection, sentiment analysis, spam reviews detection, and hate speech spans detection. Our experiments demonstrate that ViSoBERT, with far fewer parameters, surpasses the previous state-of-the-art models on multiple Vietnamese social media tasks. Our ViSoBERT model is available only for research purposes.
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Nov 14, 2023Recently, instruction-following audio-language models have received broad attention for audio interaction with humans. However, the absence of pre-trained audio models capable of handling diverse audio types and tasks has hindered progress in this field. Consequently, most existing works have only been able to support a limited range of interaction capabilities. In this paper, we develop the Qwen-Audio model and address this limitation by scaling up audio-language pre-training to cover over 30 tasks and various audio types, such as human speech, natural sounds, music, and songs, to facilitate universal audio understanding abilities. However, directly co-training all tasks and datasets can lead to interference issues, as the textual labels associated with different datasets exhibit considerable variations due to differences in task focus, language, granularity of annotation, and text structure. To overcome the one-to-many interference, we carefully design a multi-task training framework by conditioning on a sequence of hierarchical tags to the decoder for encouraging knowledge sharing and avoiding interference through shared and specified tags respectively. Remarkably, Qwen-Audio achieves impressive performance across diverse benchmark tasks without requiring any task-specific fine-tuning, surpassing its counterparts. Building upon the capabilities of Qwen-Audio, we further develop Qwen-Audio-Chat, which allows for input from various audios and text inputs, enabling multi-turn dialogues and supporting various audio-central scenarios.