 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Identifying depression-related topics in smartphone-collected free-response speech recordings using an automatic speech recognition system and a deep learning topic model
Aug 22, 2023
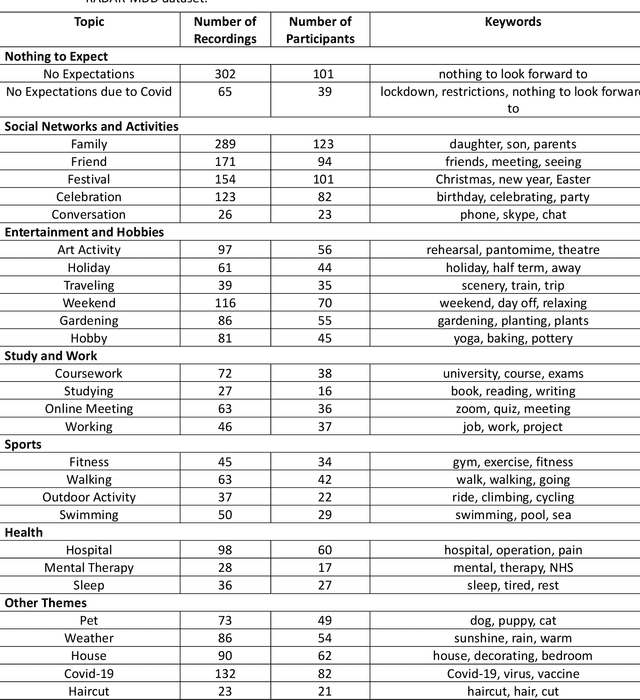
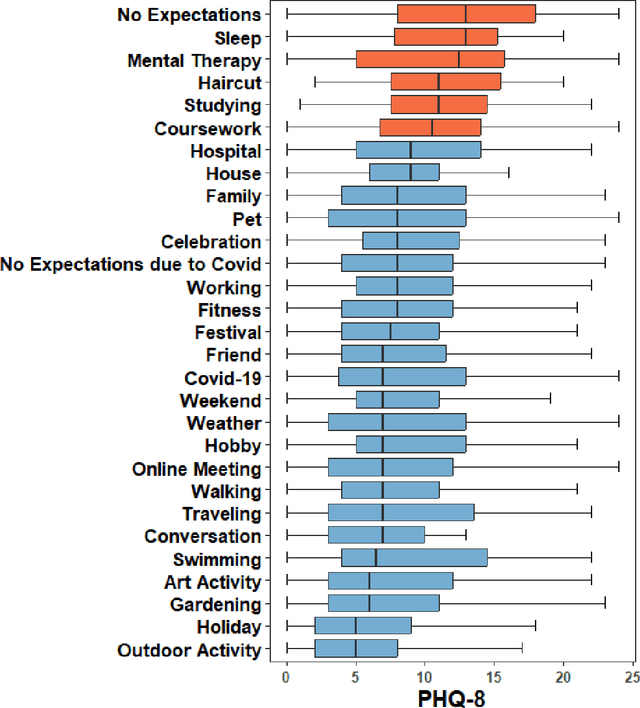
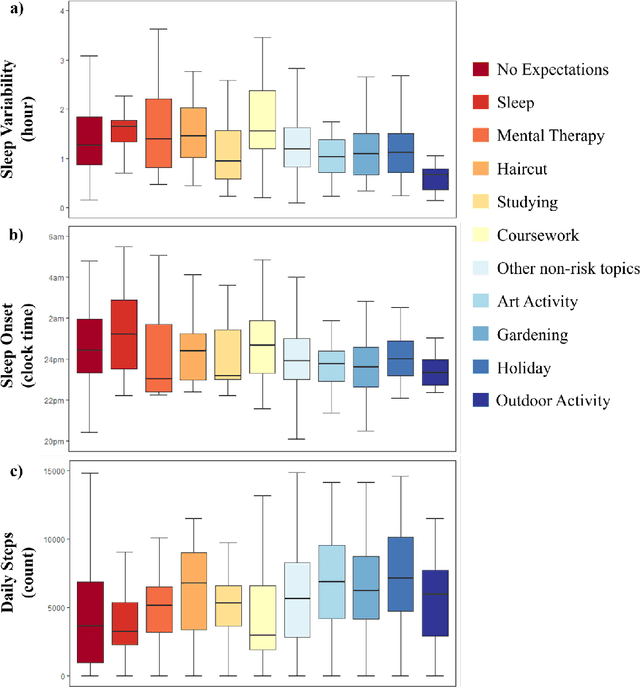
Language use has been shown to correlate with depression, but large-scale validation is needed. Traditional methods like clinic studies are expensive. So, natural language processing has been employed on social media to predict depression, but limitations remain-lack of validated labels, biased user samples, and no context. Our study identified 29 topics in 3919 smartphone-collected speech recordings from 265 participants using the Whisper tool and BERTopic model. Six topics with a median PHQ-8 greater than or equal to 10 were regarded as risk topics for depression: No Expectations, Sleep, Mental Therapy, Haircut, Studying, and Coursework. To elucidate the topic emergence and associations with depression, we compared behavioral (from wearables) and linguistic characteristics across identified topics. The correlation between topic shifts and changes in depression severity over time was also investigated, indicating the importance of longitudinally monitoring language use. We also tested the BERTopic model on a similar smaller dataset (356 speech recordings from 57 participants), obtaining some consistent results. In summary, our findings demonstrate specific speech topics may indicate depression severity. The presented data-driven workflow provides a practical approach to collecting and analyzing large-scale speech data from real-world settings for digital health research.
How Much Context Does My Attention-Based ASR System Need?
Oct 24, 2023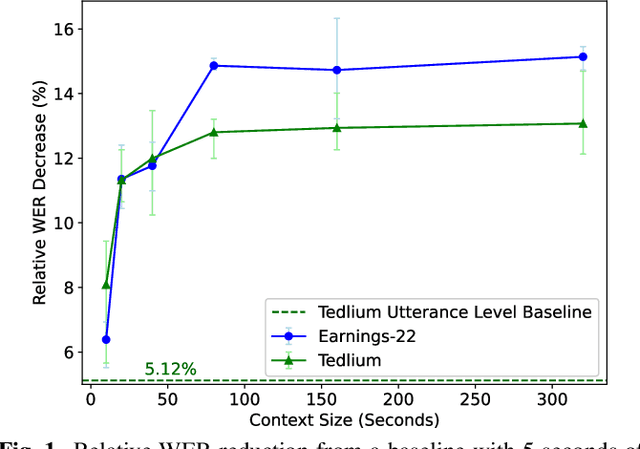


For the task of speech recognition, the use of more than 30 seconds of acoustic context during training is uncommon, and under-investigated in literature. In this work, we examine the effect of scaling the sequence length used to train/evaluate (dense-attention based) acoustic and language models on speech recognition performance. For these experiments a dataset of roughly 100,000 pseudo-labelled Spotify podcasts is used, with context lengths of 5 seconds to 1 hour being explored. Zero-shot evaluations on long-format datasets Earnings-22 and Tedlium demonstrate a benefit from training with around 80 seconds of acoustic context, showing up to a 14.9% relative improvement from a limited context baseline. Furthermore, we perform a system combination with long-context transformer language models via beam search for a fully long-context ASR system, with results that are competitive with the current state-of-the-art.
Analysis of XLS-R for Speech Quality Assessment
Aug 23, 2023In online conferencing applications, estimating the perceived quality of an audio signal is crucial to ensure high quality of experience for the end user. The most reliable way to assess the quality of a speech signal is through human judgments in the form of the mean opinion score (MOS) metric. However, such an approach is labor intensive and not feasible for large-scale applications. The focus has therefore shifted towards automated speech quality assessment through end-to-end training of deep neural networks. Recently, it was shown that leveraging pre-trained wav2vec-based XLS-R embeddings leads to state-of-the-art performance for the task of speech quality prediction. In this paper, we perform an in-depth analysis of the pre-trained model. First, we analyze the performance of embeddings extracted from each layer of XLS-R and also for each size of the model (300M, 1B, 2B parameters). Surprisingly, we find two optimal regions for feature extraction: one in the lower-level features and one in the high-level features. Next, we investigate the reason for the two distinct optima. We hypothesize that the lower-level features capture characteristics of noise and room acoustics, whereas the high-level features focus on speech content and intelligibility. To investigate this, we analyze the sensitivity of the MOS predictions with respect to different levels of corruption in each category. Afterwards, we try fusing the two optimal feature depths to determine if they contain complementary information for MOS prediction. Finally, we compare the performance of the proposed models and assess the generalizability of the models on unseen datasets.
On Feature Importance and Interpretability of Speaker Representations
Oct 19, 2023Unsupervised speech disentanglement aims at separating fast varying from slowly varying components of a speech signal. In this contribution, we take a closer look at the embedding vector representing the slowly varying signal components, commonly named the speaker embedding vector. We ask, which properties of a speaker's voice are captured and investigate to which extent do individual embedding vector components sign responsible for them, using the concept of Shapley values. Our findings show that certain speaker-specific acoustic-phonetic properties can be fairly well predicted from the speaker embedding, while the investigated more abstract voice quality features cannot.
High-Fidelity Noise Reduction with Differentiable Signal Processing
Oct 17, 2023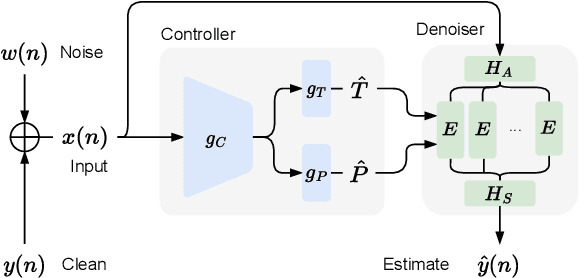
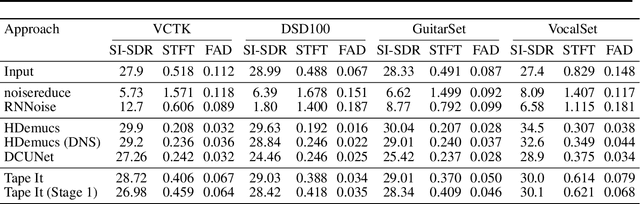
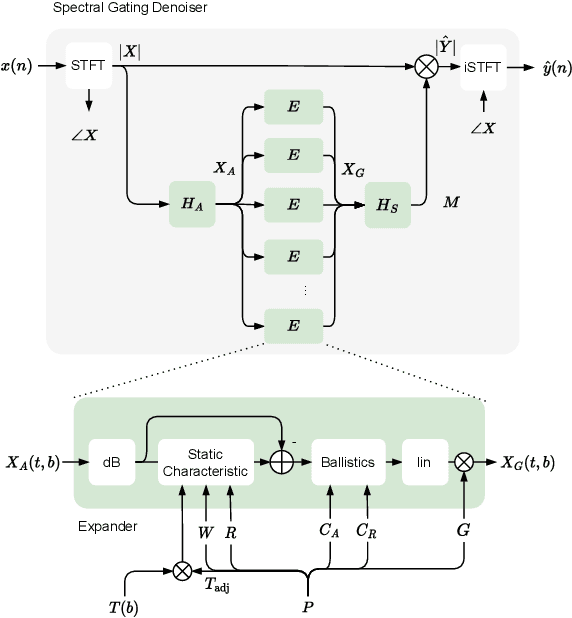

Noise reduction techniques based on deep learning have demonstrated impressive performance in enhancing the overall quality of recorded speech. While these approaches are highly performant, their application in audio engineering can be limited due to a number of factors. These include operation only on speech without support for music, lack of real-time capability, lack of interpretable control parameters, operation at lower sample rates, and a tendency to introduce artifacts. On the other hand, signal processing-based noise reduction algorithms offer fine-grained control and operation on a broad range of content, however, they often require manual operation to achieve the best results. To address the limitations of both approaches, in this work we introduce a method that leverages a signal processing-based denoiser that when combined with a neural network controller, enables fully automatic and high-fidelity noise reduction on both speech and music signals. We evaluate our proposed method with objective metrics and a perceptual listening test. Our evaluation reveals that speech enhancement models can be extended to music, however training the model to remove only stationary noise is critical. Furthermore, our proposed approach achieves performance on par with the deep learning models, while being significantly more efficient and introducing fewer artifacts in some cases. Listening examples are available online at https://tape.it/research/denoiser .
BadSQA: Stealthy Backdoor Attacks Using Presence Events as Triggers in Non-Intrusive Speech Quality Assessment
Sep 04, 2023Non-Intrusive speech quality assessment (NISQA) has gained significant attention for predicting the mean opinion score (MOS) of speech without requiring the reference speech. In practical NISQA scenarios, untrusted third-party resources are often employed during deep neural network training to reduce costs. However, it would introduce a potential security vulnerability as specially designed untrusted resources can launch backdoor attacks against NISQA systems. Existing backdoor attacks primarily focus on classification tasks and are not directly applicable to NISQA which is a regression task. In this paper, we propose a novel backdoor attack on NISQA tasks, leveraging presence events as triggers to achieving highly stealthy attacks. To evaluate the effectiveness of our proposed approach, we conducted experiments on four benchmark datasets and employed two state-of-the-art NISQA models. The results demonstrate that the proposed backdoor attack achieved an average attack success rate of up to 99% with a poisoning rate of only 3%.
Towards End-to-End Spoken Grammatical Error Correction
Nov 09, 2023Grammatical feedback is crucial for L2 learners, teachers, and testers. Spoken grammatical error correction (GEC) aims to supply feedback to L2 learners on their use of grammar when speaking. This process usually relies on a cascaded pipeline comprising an ASR system, disfluency removal, and GEC, with the associated concern of propagating errors between these individual modules. In this paper, we introduce an alternative "end-to-end" approach to spoken GEC, exploiting a speech recognition foundation model, Whisper. This foundation model can be used to replace the whole framework or part of it, e.g., ASR and disfluency removal. These end-to-end approaches are compared to more standard cascaded approaches on the data obtained from a free-speaking spoken language assessment test, Linguaskill. Results demonstrate that end-to-end spoken GEC is possible within this architecture, but the lack of available data limits current performance compared to a system using large quantities of text-based GEC data. Conversely, end-to-end disfluency detection and removal, which is easier for the attention-based Whisper to learn, does outperform cascaded approaches. Additionally, the paper discusses the challenges of providing feedback to candidates when using end-to-end systems for spoken GEC.
USA: Universal Sentiment Analysis Model & Construction of Japanese Sentiment Text Classification and Part of Speech Dataset
Sep 14, 2023

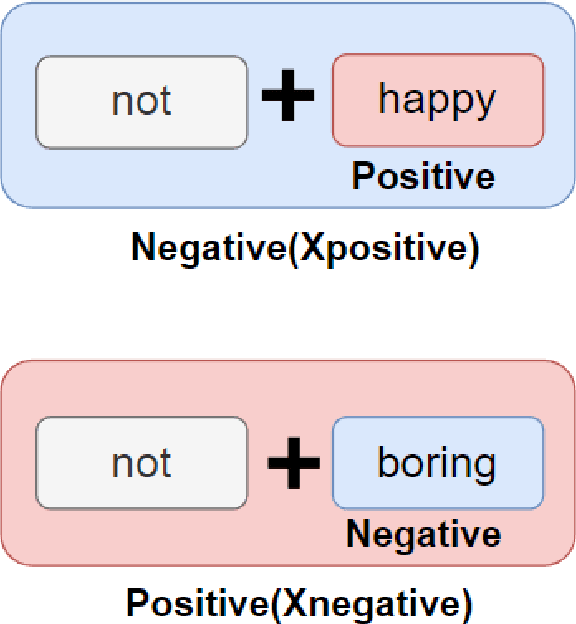
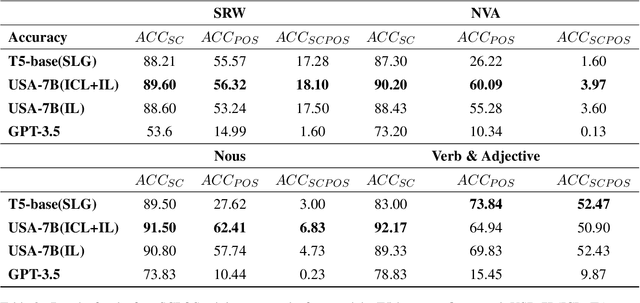
Sentiment analysis is a pivotal task in the domain of natural language processing. It encompasses both text-level sentiment polarity classification and word-level Part of Speech(POS) sentiment polarity determination. Such analysis challenges models to understand text holistically while also extracting nuanced information. With the rise of Large Language Models(LLMs), new avenues for sentiment analysis have opened. This paper proposes enhancing performance by leveraging the Mutual Reinforcement Effect(MRE) between individual words and the overall text. It delves into how word polarity influences the overarching sentiment of a passage. To support our research, we annotated four novel Sentiment Text Classification and Part of Speech(SCPOS) datasets, building upon existing sentiment classification datasets. Furthermore, we developed a Universal Sentiment Analysis(USA) model, with a 7-billion parameter size. Experimental results revealed that our model surpassed the performance of gpt-3.5-turbo across all four datasets, underscoring the significance of MRE in sentiment analysis.
GPT-4V(ision) as A Social Media Analysis Engine
Nov 13, 2023Recent research has offered insights into the extraordinary capabilities of Large Multimodal Models (LMMs) in various general vision and language tasks. There is growing interest in how LMMs perform in more specialized domains. Social media content, inherently multimodal, blends text, images, videos, and sometimes audio. Understanding social multimedia content remains a challenging problem for contemporary machine learning frameworks. In this paper, we explore GPT-4V(ision)'s capabilities for social multimedia analysis. We select five representative tasks, including sentiment analysis, hate speech detection, fake news identification, demographic inference, and political ideology detection, to evaluate GPT-4V. Our investigation begins with a preliminary quantitative analysis for each task using existing benchmark datasets, followed by a careful review of the results and a selection of qualitative samples that illustrate GPT-4V's potential in understanding multimodal social media content. GPT-4V demonstrates remarkable efficacy in these tasks, showcasing strengths such as joint understanding of image-text pairs, contextual and cultural awareness, and extensive commonsense knowledge. Despite the overall impressive capacity of GPT-4V in the social media domain, there remain notable challenges. GPT-4V struggles with tasks involving multilingual social multimedia comprehension and has difficulties in generalizing to the latest trends in social media. Additionally, it exhibits a tendency to generate erroneous information in the context of evolving celebrity and politician knowledge, reflecting the known hallucination problem. The insights gleaned from our findings underscore a promising future for LMMs in enhancing our comprehension of social media content and its users through the analysis of multimodal information.
CPPF: A contextual and post-processing-free model for automatic speech recognition
Sep 21, 2023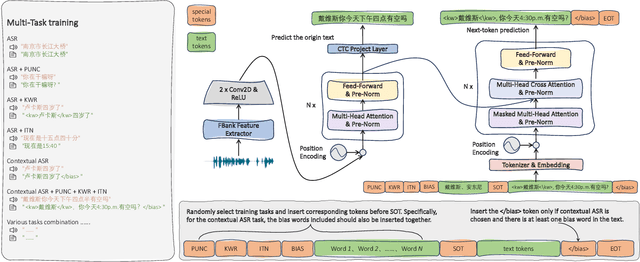
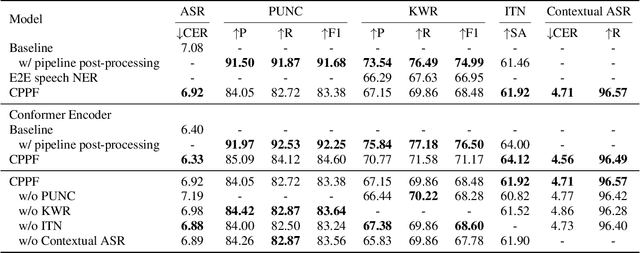

ASR systems have become increasingly widespread in recent years. However, their textual outputs often require post-processing tasks before they can be practically utilized. To address this issue, we draw inspiration from the multifaceted capabilities of LLMs and Whisper, and focus on integrating multiple ASR text processing tasks related to speech recognition into the ASR model. This integration not only shortens the multi-stage pipeline, but also prevents the propagation of cascading errors, resulting in direct generation of post-processed text. In this study, we focus on ASR-related processing tasks, including Contextual ASR and multiple ASR post processing tasks. To achieve this objective, we introduce the CPPF model, which offers a versatile and highly effective alternative to ASR processing. CPPF seamlessly integrates these tasks without any significant loss in recognition performance.