 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SD-HuBERT: Self-Distillation Induces Syllabic Organization in HuBERT
Oct 16, 2023
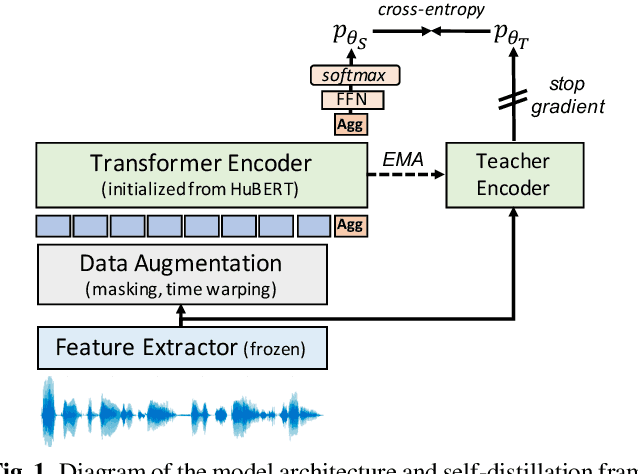
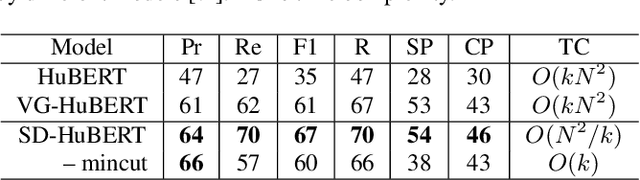
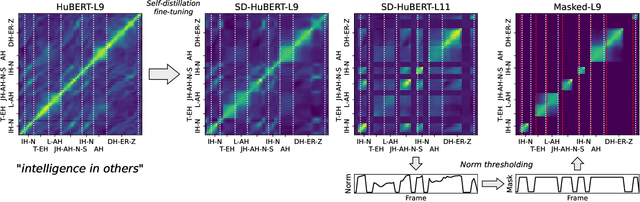
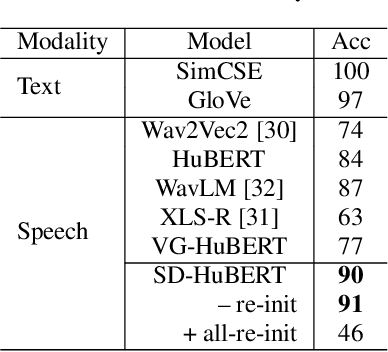
Data-driven unit discovery in self-supervised learning (SSL) of speech has embarked on a new era of spoken language processing. Yet, the discovered units often remain in phonetic space, limiting the utility of SSL representations. Here, we demonstrate that a syllabic organization emerges in learning sentence-level representation of speech. In particular, we adopt "self-distillation" objective to fine-tune the pretrained HuBERT with an aggregator token that summarizes the entire sentence. Without any supervision, the resulting model draws definite boundaries in speech, and the representations across frames show salient syllabic structures. We demonstrate that this emergent structure largely corresponds to the ground truth syllables. Furthermore, we propose a new benchmark task, Spoken Speech ABX, for evaluating sentence-level representation of speech. When compared to previous models, our model outperforms in both unsupervised syllable discovery and learning sentence-level representation. Together, we demonstrate that the self-distillation of HuBERT gives rise to syllabic organization without relying on external labels or modalities, and potentially provides novel data-driven units for spoken language modeling.
The Mason-Alberta Phonetic Segmenter: A forced alignment system based on deep neural networks and interpolation
Oct 24, 2023Forced alignment systems automatically determine boundaries between segments in speech data, given an orthographic transcription. These tools are commonplace in phonetics to facilitate the use of speech data that would be infeasible to manually transcribe and segment. In the present paper, we describe a new neural network-based forced alignment system, the Mason-Alberta Phonetic Segmenter (MAPS). The MAPS aligner serves as a testbed for two possible improvements we pursue for forced alignment systems. The first is treating the acoustic model in a forced aligner as a tagging task, rather than a classification task, motivated by the common understanding that segments in speech are not truly discrete and commonly overlap. The second is an interpolation technique to allow boundaries more precise than the common 10 ms limit in modern forced alignment systems. We compare configurations of our system to a state-of-the-art system, the Montreal Forced Aligner. The tagging approach did not generally yield improved results over the Montreal Forced Aligner. However, a system with the interpolation technique had a 27.92% increase relative to the Montreal Forced Aligner in the amount of boundaries within 10 ms of the target on the test set. We also reflect on the task and training process for acoustic modeling in forced alignment, highlighting how the output targets for these models do not match phoneticians' conception of similarity between phones and that reconciliation of this tension may require rethinking the task and output targets or how speech itself should be segmented.
MuLanTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2023
Sep 12, 2023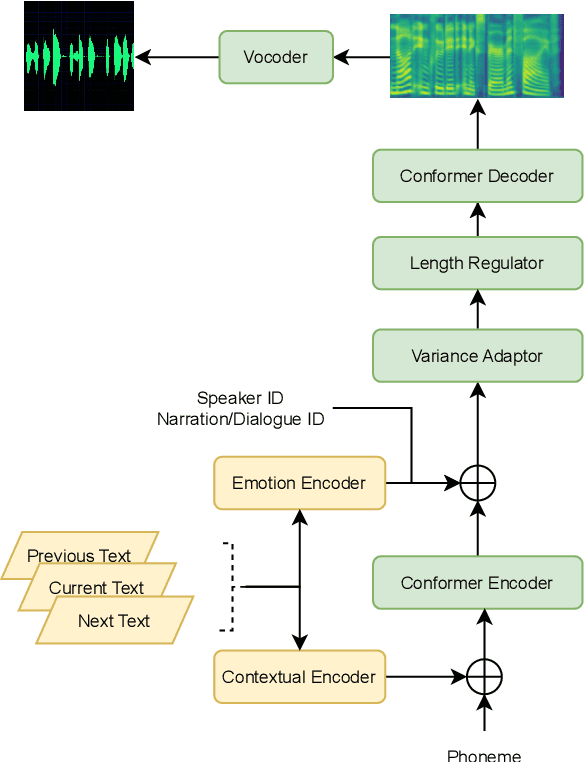
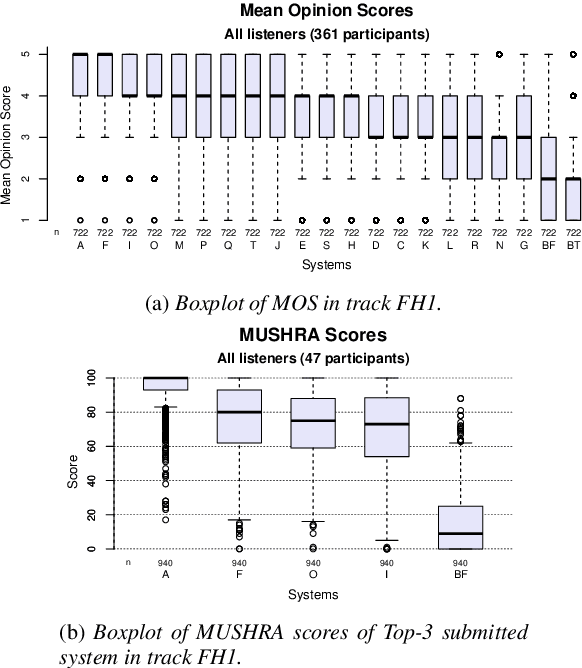
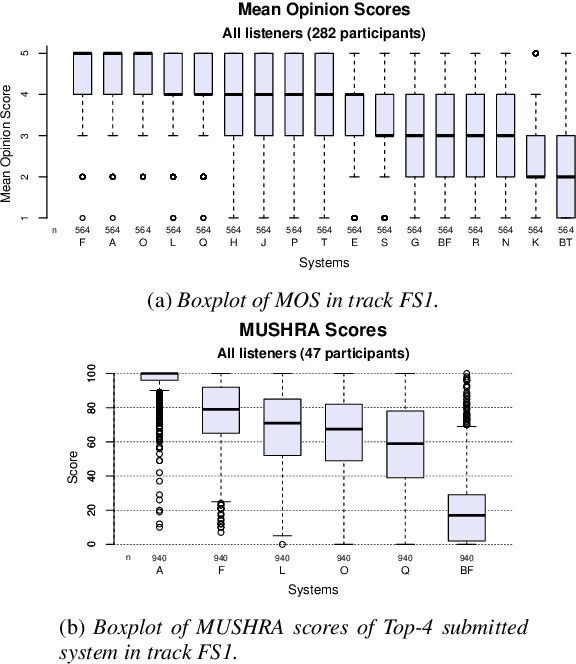
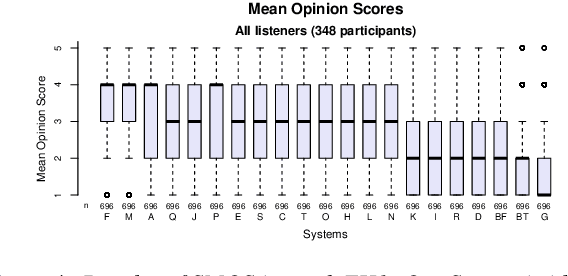
In this paper, we present MuLanTTS, the Microsoft end-to-end neural text-to-speech (TTS) system designed for the Blizzard Challenge 2023. About 50 hours of audiobook corpus for French TTS as hub task and another 2 hours of speaker adaptation as spoke task are released to build synthesized voices for different test purposes including sentences, paragraphs, homographs, lists, etc. Building upon DelightfulTTS, we adopt contextual and emotion encoders to adapt the audiobook data to enrich beyond sentences for long-form prosody and dialogue expressiveness. Regarding the recording quality, we also apply denoise algorithms and long audio processing for both corpora. For the hub task, only the 50-hour single speaker data is used for building the TTS system, while for the spoke task, a multi-speaker source model is used for target speaker fine tuning. MuLanTTS achieves mean scores of quality assessment 4.3 and 4.5 in the respective tasks, statistically comparable with natural speech while keeping good similarity according to similarity assessment. The excellent and similarity in this year's new and dense statistical evaluation show the effectiveness of our proposed system in both tasks.
A Survey on Online User Aggression: Content Detection and Behavioural Analysis on Social Media Platforms
Nov 15, 2023The rise of social media platforms has led to an increase in cyber-aggressive behavior, encompassing a broad spectrum of hostile behavior, including cyberbullying, online harassment, and the dissemination of offensive and hate speech. These behaviors have been associated with significant societal consequences, ranging from online anonymity to real-world outcomes such as depression, suicidal tendencies, and, in some instances, offline violence. Recognizing the societal risks associated with unchecked aggressive content, this paper delves into the field of Aggression Content Detection and Behavioral Analysis of Aggressive Users, aiming to bridge the gap between disparate studies. In this paper, we analyzed the diversity of definitions and proposed a unified cyber-aggression definition. We examine the comprehensive process of Aggression Content Detection, spanning from dataset creation, feature selection and extraction, and detection algorithm development. Further, we review studies on Behavioral Analysis of Aggression that explore the influencing factors, consequences, and patterns associated with cyber-aggressive behavior. This systematic literature review is a cross-examination of content detection and behavioral analysis in the realm of cyber-aggression. The integrated investigation reveals the effectiveness of incorporating sociological insights into computational techniques for preventing cyber-aggressive behavior. Finally, the paper concludes by identifying research gaps and encouraging further progress in the unified domain of socio-computational aggressive behavior analysis.
Investigating the Emergent Audio Classification Ability of ASR Foundation Models
Nov 15, 2023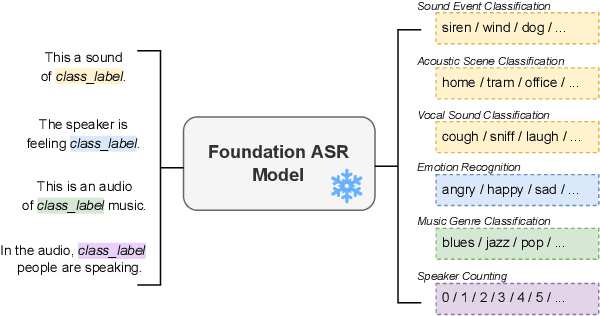
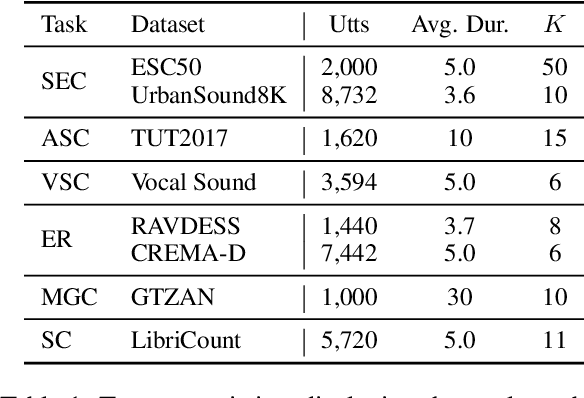


Text and vision foundation models can perform many tasks in a zero-shot setting, a desirable property that enables these systems to be applied in general and low-resource settings. However, there has been significantly less work on the zero-shot abilities of ASR foundation models, with these systems typically fine-tuned to specific tasks or constrained to applications that match their training criterion and data annotation. In this work we investigate the ability of Whisper and MMS, ASR foundation models trained primarily for speech recognition, to perform zero-shot audio classification. We use simple template-based text prompts at the decoder and use the resulting decoding probabilities to generate zero-shot predictions. Without training the model on extra data or adding any new parameters, we demonstrate that Whisper shows promising zero-shot classification performance on a range of 8 audio-classification datasets, outperforming existing state-of-the-art zero-shot baseline's accuracy by an average of 9%. One important step to unlock the emergent ability is debiasing, where a simple unsupervised reweighting method of the class probabilities yields consistent significant performance gains. We further show that performance increases with model size, implying that as ASR foundation models scale up, they may exhibit improved zero-shot performance.
SALTTS: Leveraging Self-Supervised Speech Representations for improved Text-to-Speech Synthesis
Aug 02, 2023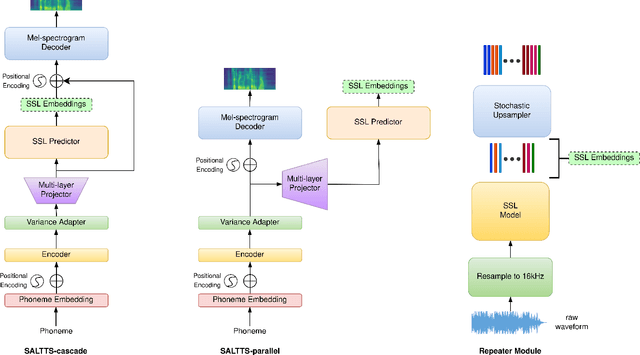
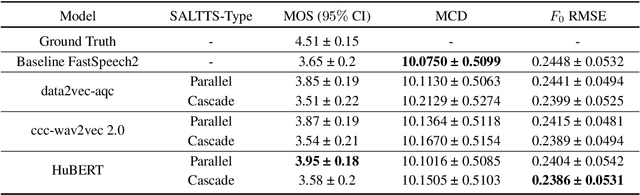
While FastSpeech2 aims to integrate aspects of speech such as pitch, energy, and duration as conditional inputs, it still leaves scope for richer representations. As a part of this work, we leverage representations from various Self-Supervised Learning (SSL) models to enhance the quality of the synthesized speech. In particular, we pass the FastSpeech2 encoder's length-regulated outputs through a series of encoder layers with the objective of reconstructing the SSL representations. In the SALTTS-parallel implementation, the representations from this second encoder are used for an auxiliary reconstruction loss with the SSL features. The SALTTS-cascade implementation, however, passes these representations through the decoder in addition to having the reconstruction loss. The richness of speech characteristics from the SSL features reflects in the output speech quality, with the objective and subjective evaluation measures of the proposed approach outperforming the baseline FastSpeech2.
Unimodal Aggregation for CTC-based Speech Recognition
Sep 15, 2023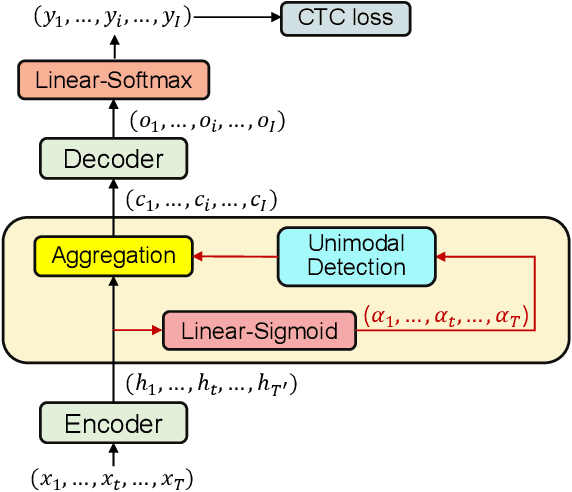
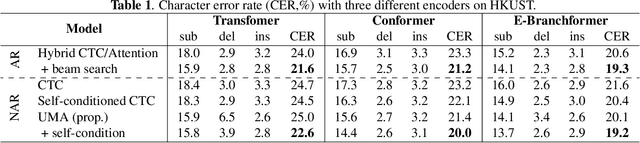
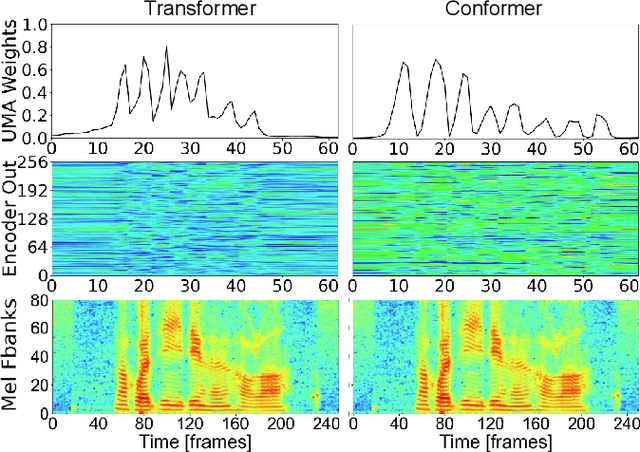
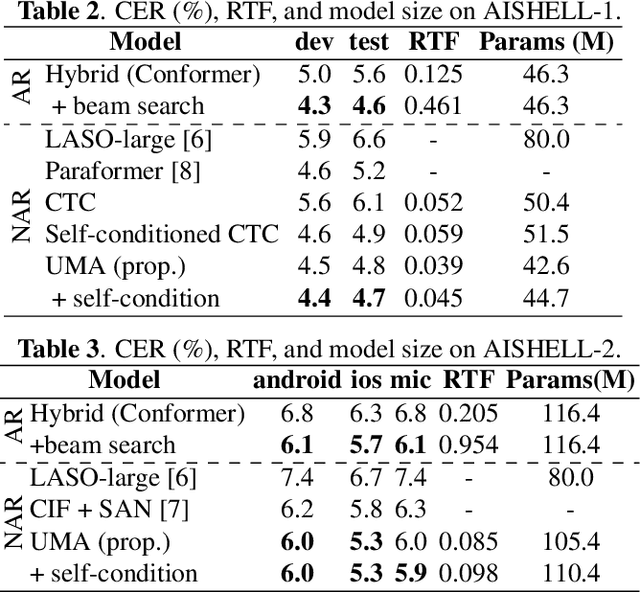
This paper works on non-autoregressive automatic speech recognition. A unimodal aggregation (UMA) is proposed to segment and integrate the feature frames that belong to the same text token, and thus to learn better feature representations for text tokens. The frame-wise features and weights are both derived from an encoder. Then, the feature frames with unimodal weights are integrated and further processed by a decoder. Connectionist temporal classification (CTC) loss is applied for training. Compared to the regular CTC, the proposed method learns better feature representations and shortens the sequence length, resulting in lower recognition error and computational complexity. Experiments on three Mandarin datasets show that UMA demonstrates superior or comparable performance to other advanced non-autoregressive methods, such as self-conditioned CTC. Moreover, by integrating self-conditioned CTC into the proposed framework, the performance can be further noticeably improved.
Whisper-MCE: Whisper Model Finetuned for Better Performance with Mixed Languages
Oct 27, 2023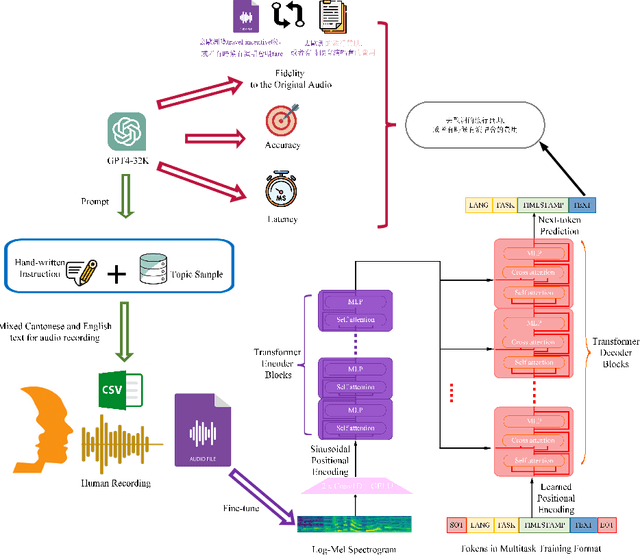
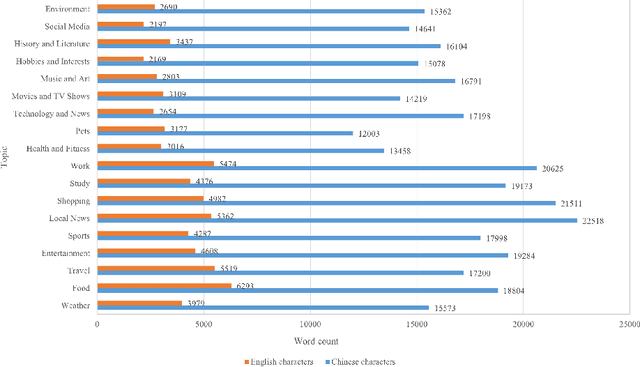
Recently Whisper has approached human-level robustness and accuracy in English automatic speech recognition (ASR), while in minor language and mixed language speech recognition, there remains a compelling need for further improvement. In this work, we present the impressive results of Whisper-MCE, our finetuned Whisper model, which was trained using our self-collected dataset, Mixed Cantonese and English audio dataset (MCE). Meanwhile, considering word error rate (WER) poses challenges when it comes to evaluating its effectiveness in minor language and mixed-language contexts, we present a novel rating mechanism. By comparing our model to the baseline whisper-large-v2 model, we demonstrate its superior ability to accurately capture the content of the original audio, achieve higher recognition accuracy, and exhibit faster recognition speed. Notably, our model outperforms other existing models in the specific task of recognizing mixed language.
SPGM: Prioritizing Local Features for enhanced speech separation performance
Sep 22, 2023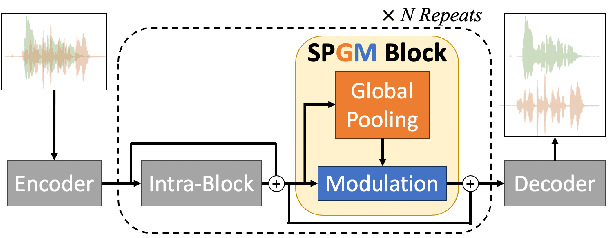
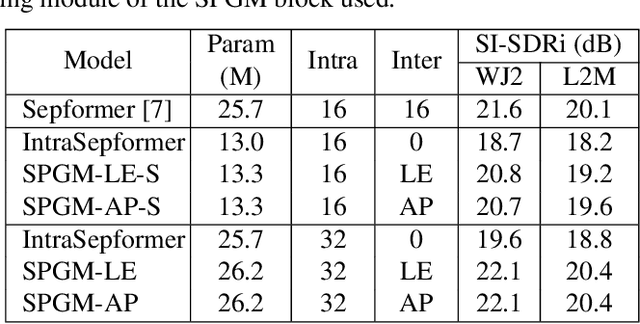
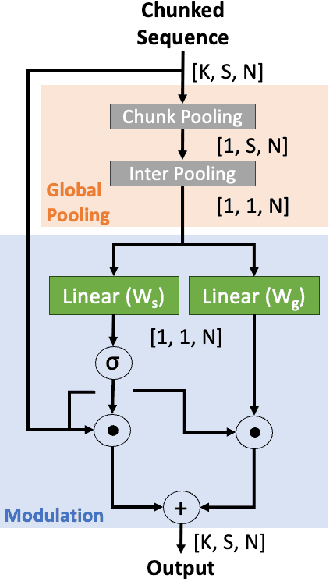
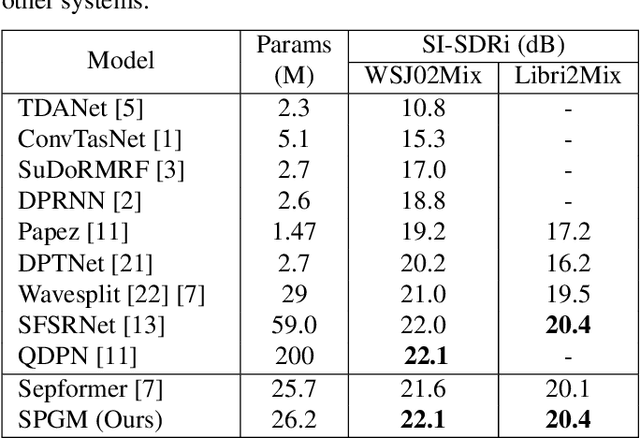
Dual-path is a popular architecture for speech separation models (e.g. Sepformer) which splits long sequences into overlapping chunks for its intra- and inter-blocks that separately model intra-chunk local features and inter-chunk global relationships. However, it has been found that inter-blocks, which comprise half a dual-path model's parameters, contribute minimally to performance. Thus, we propose the Single-Path Global Modulation (SPGM) block to replace inter-blocks. SPGM is named after its structure consisting of a parameter-free global pooling module followed by a modulation module comprising only 2% of the model's total parameters. The SPGM block allows all transformer layers in the model to be dedicated to local feature modelling, making the overall model single-path. SPGM achieves 22.1 dB SI-SDRi on WSJ0-2Mix and 20.4 dB SI-SDRi on Libri2Mix, exceeding the performance of Sepformer by 0.5 dB and 0.3 dB respectively and matches the performance of recent SOTA models with up to 8 times fewer parameters.
Diversity-based core-set selection for text-to-speech with linguistic and acoustic features
Sep 15, 2023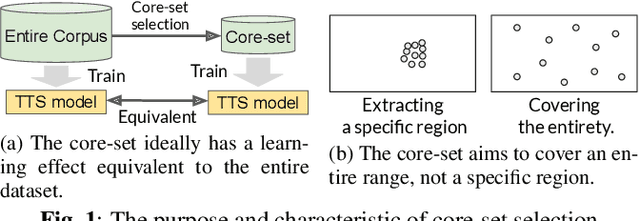
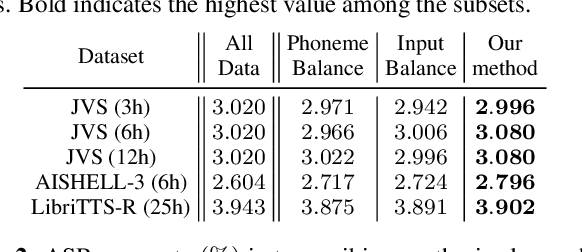
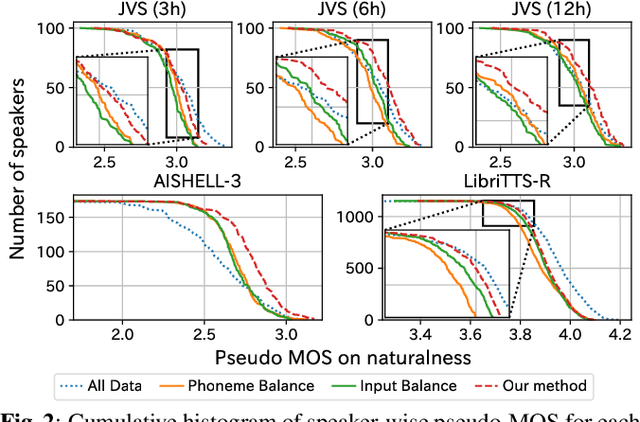
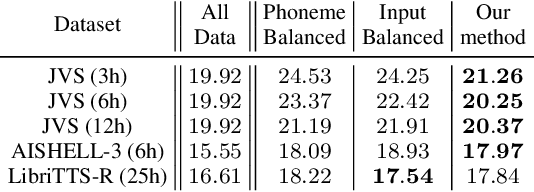
This paper proposes a method for extracting a lightweight subset from a text-to-speech (TTS) corpus ensuring synthetic speech quality. In recent years, methods have been proposed for constructing large-scale TTS corpora by collecting diverse data from massive sources such as audiobooks and YouTube. Although these methods have gained significant attention for enhancing the expressive capabilities of TTS systems, they often prioritize collecting vast amounts of data without considering practical constraints like storage capacity and computation time in training, which limits the available data quantity. Consequently, the need arises to efficiently collect data within these volume constraints. To address this, we propose a method for selecting the core subset~(known as \textit{core-set}) from a TTS corpus on the basis of a \textit{diversity metric}, which measures the degree to which a subset encompasses a wide range. Experimental results demonstrate that our proposed method performs significantly better than the baseline phoneme-balanced data selection across language and corpus size.