 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Real-time Detection of AI-Generated Speech for DeepFake Voice Conversion
Aug 24, 2023
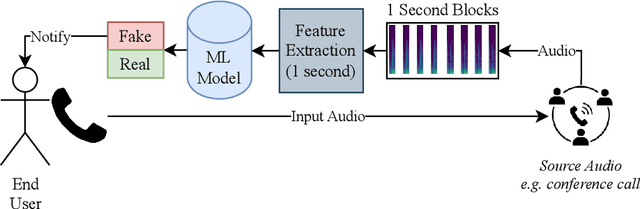

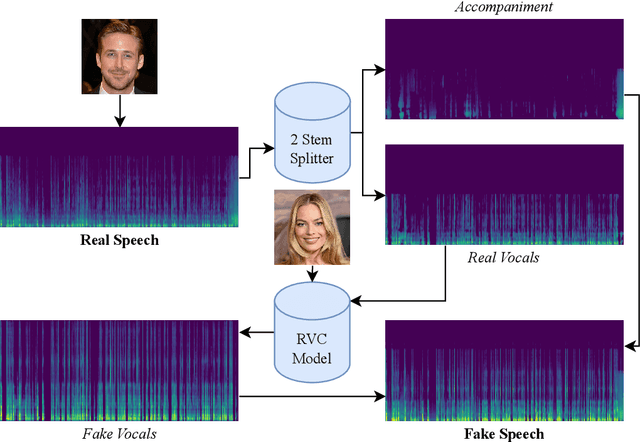
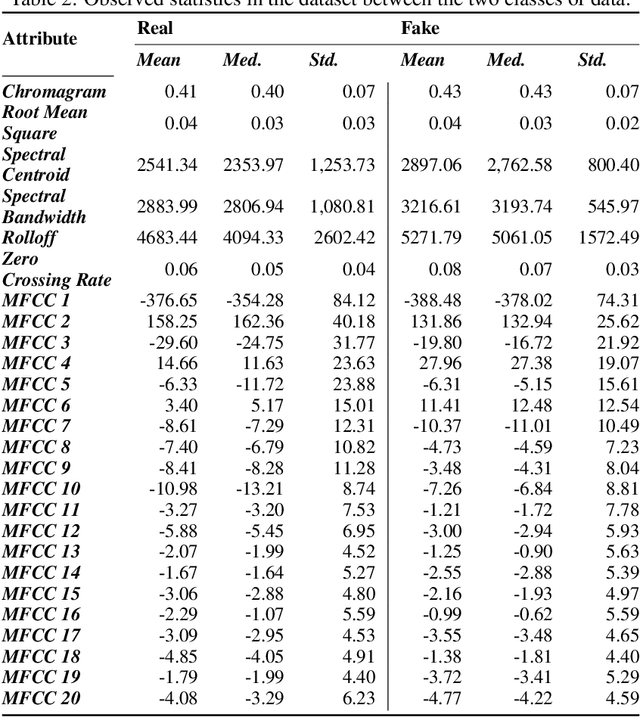
There are growing implications surrounding generative AI in the speech domain that enable voice cloning and real-time voice conversion from one individual to another. This technology poses a significant ethical threat and could lead to breaches of privacy and misrepresentation, thus there is an urgent need for real-time detection of AI-generated speech for DeepFake Voice Conversion. To address the above emerging issues, the DEEP-VOICE dataset is generated in this study, comprised of real human speech from eight well-known figures and their speech converted to one another using Retrieval-based Voice Conversion. Presenting as a binary classification problem of whether the speech is real or AI-generated, statistical analysis of temporal audio features through t-testing reveals that there are significantly different distributions. Hyperparameter optimisation is implemented for machine learning models to identify the source of speech. Following the training of 208 individual machine learning models over 10-fold cross validation, it is found that the Extreme Gradient Boosting model can achieve an average classification accuracy of 99.3% and can classify speech in real-time, at around 0.004 milliseconds given one second of speech. All data generated for this study is released publicly for future research on AI speech detection.
Understanding Self-Supervised Learning of Speech Representation via Invariance and Redundancy Reduction
Sep 07, 2023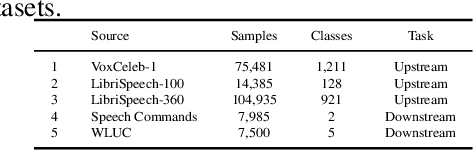
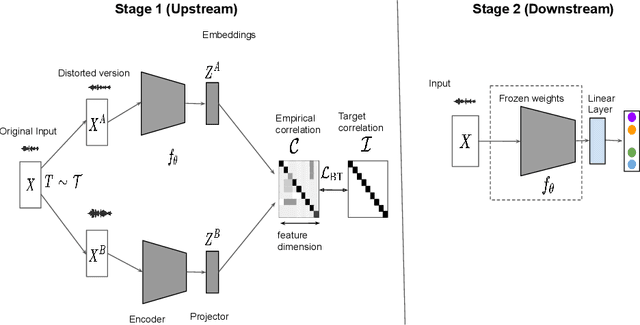
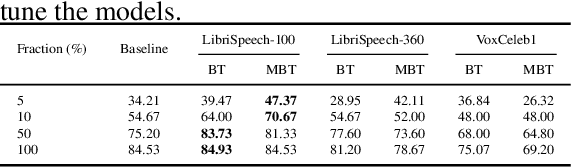
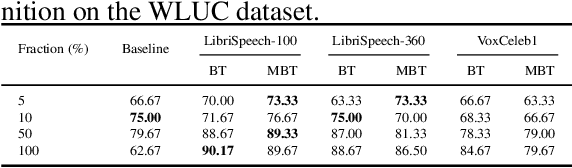
The choice of the objective function is crucial in emerging high-quality representations from self-supervised learning. This paper investigates how different formulations of the Barlow Twins (BT) objective impact downstream task performance for speech data. We propose Modified Barlow Twins (MBT) with normalized latents to enforce scale-invariance and evaluate on speaker identification, gender recognition and keyword spotting tasks. Our results show MBT improves representation generalization over original BT, especially when fine-tuning with limited target data. This highlights the importance of designing objectives that encourage invariant and transferable representations. Our analysis provides insights into how the BT learning objective can be tailored to produce speech representations that excel when adapted to new downstream tasks. This study is an important step towards developing reusable self-supervised speech representations.
Added Toxicity Mitigation at Inference Time for Multimodal and Massively Multilingual Translation
Nov 11, 2023Added toxicity in the context of translation refers to the fact of producing a translation output with more toxicity than there exists in the input. In this paper, we present MinTox which is a novel pipeline to identify added toxicity and mitigate this issue which works at inference time. MinTox uses a toxicity detection classifier which is multimodal (speech and text) and works in languages at scale. The mitigation method is applied to languages at scale and directly in text outputs. MinTox is applied to SEAMLESSM4T, which is the latest multimodal and massively multilingual machine translation system. For this system, MinTox achieves significant added toxicity mitigation across domains, modalities and language directions. MinTox manages to approximately filter out from 25% to 95% of added toxicity (depending on the modality and domain) while keeping translation quality.
Target Speech Extraction with Conditional Diffusion Model
Aug 17, 2023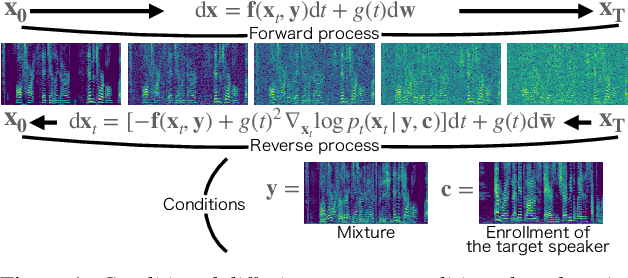
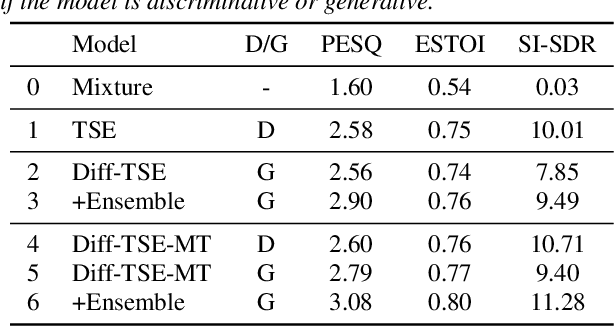
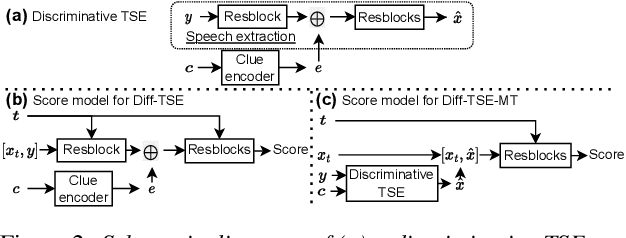
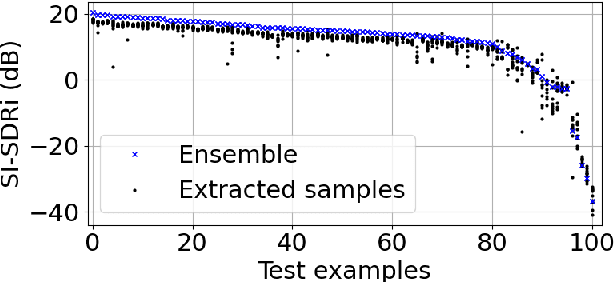
Diffusion model-based speech enhancement has received increased attention since it can generate very natural enhanced signals and generalizes well to unseen conditions. Diffusion models have been explored for several sub-tasks of speech enhancement, such as speech denoising, dereverberation, and source separation. In this paper, we investigate their use for target speech extraction (TSE), which consists of estimating the clean speech signal of a target speaker in a mixture of multi-talkers. TSE is realized by conditioning the extraction process on a clue identifying the target speaker. We show we can realize TSE using a conditional diffusion model conditioned on the clue. Besides, we introduce ensemble inference to reduce potential extraction errors caused by the diffusion process. In experiments on Libri2mix corpus, we show that the proposed diffusion model-based TSE combined with ensemble inference outperforms a comparable TSE system trained discriminatively.
The CHiME-7 Challenge: System Description and Performance of NeMo Team's DASR System
Oct 18, 2023We present the NVIDIA NeMo team's multi-channel speech recognition system for the 7th CHiME Challenge Distant Automatic Speech Recognition (DASR) Task, focusing on the development of a multi-channel, multi-speaker speech recognition system tailored to transcribe speech from distributed microphones and microphone arrays. The system predominantly comprises of the following integral modules: the Speaker Diarization Module, Multi-channel Audio Front-End Processing Module, and the ASR Module. These components collectively establish a cascading system, meticulously processing multi-channel and multi-speaker audio input. Moreover, this paper highlights the comprehensive optimization process that significantly enhanced our system's performance. Our team's submission is largely based on NeMo toolkits and will be publicly available.
The Broad Impact of Feature Imitation: Neural Enhancements Across Financial, Speech, and Physiological Domains
Sep 21, 2023Initialization of neural network weights plays a pivotal role in determining their performance. Feature Imitating Networks (FINs) offer a novel strategy by initializing weights to approximate specific closed-form statistical features, setting a promising foundation for deep learning architectures. While the applicability of FINs has been chiefly tested in biomedical domains, this study extends its exploration into other time series datasets. Three different experiments are conducted in this study to test the applicability of imitating Tsallis entropy for performance enhancement: Bitcoin price prediction, speech emotion recognition, and chronic neck pain detection. For the Bitcoin price prediction, models embedded with FINs reduced the root mean square error by around 1000 compared to the baseline. In the speech emotion recognition task, the FIN-augmented model increased classification accuracy by over 3 percent. Lastly, in the CNP detection experiment, an improvement of about 7 percent was observed compared to established classifiers. These findings validate the broad utility and potency of FINs in diverse applications.
Visual Speech Recognition for Low-resource Languages with Automatic Labels From Whisper Model
Sep 15, 2023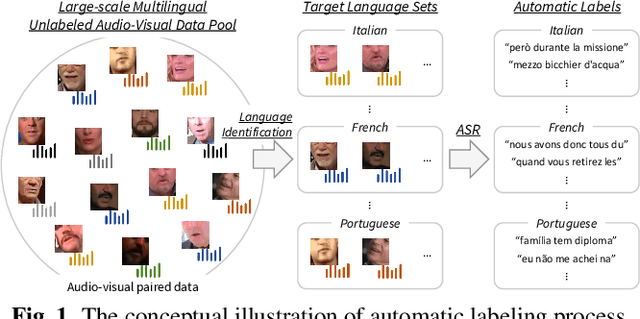
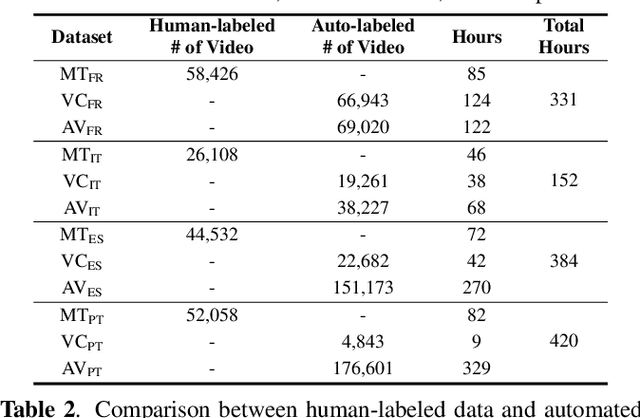
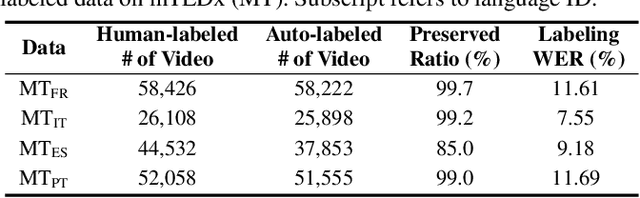
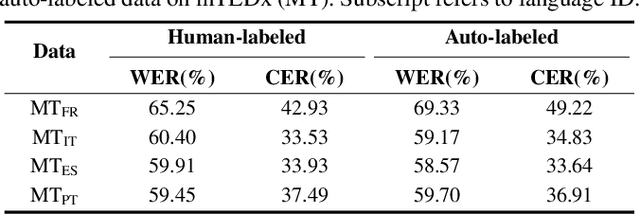
This paper proposes a powerful Visual Speech Recognition (VSR) method for multiple languages, especially for low-resource languages that have a limited number of labeled data. Different from previous methods that tried to improve the VSR performance for the target language by using knowledge learned from other languages, we explore whether we can increase the amount of training data itself for the different languages without human intervention. To this end, we employ a Whisper model which can conduct both language identification and audio-based speech recognition. It serves to filter data of the desired languages and transcribe labels from the unannotated, multilingual audio-visual data pool. By comparing the performances of VSR models trained on automatic labels and the human-annotated labels, we show that we can achieve similar VSR performance to that of human-annotated labels even without utilizing human annotations. Through the automated labeling process, we label large-scale unlabeled multilingual databases, VoxCeleb2 and AVSpeech, producing 1,002 hours of data for four low VSR resource languages, French, Italian, Spanish, and Portuguese. With the automatic labels, we achieve new state-of-the-art performance on mTEDx in four languages, significantly surpassing the previous methods. The automatic labels are available online: https://github.com/JeongHun0716/Visual-Speech-Recognition-for-Low-Resource-Languages
Detecting and Correcting Hate Speech in Multimodal Memes with Large Visual Language Model
Nov 12, 2023Recently, large language models (LLMs) have taken the spotlight in natural language processing. Further, integrating LLMs with vision enables the users to explore more emergent abilities in multimodality. Visual language models (VLMs), such as LLaVA, Flamingo, or GPT-4, have demonstrated impressive performance on various visio-linguistic tasks. Consequently, there are enormous applications of large models that could be potentially used on social media platforms. Despite that, there is a lack of related work on detecting or correcting hateful memes with VLMs. In this work, we study the ability of VLMs on hateful meme detection and hateful meme correction tasks with zero-shot prompting. From our empirical experiments, we show the effectiveness of the pretrained LLaVA model and discuss its strengths and weaknesses in these tasks.
End-to-End real time tracking of children's reading with pointer network
Oct 17, 2023In this work, we explore how a real time reading tracker can be built efficiently for children's voices. While previously proposed reading trackers focused on ASR-based cascaded approaches, we propose a fully end-to-end model making it less prone to lags in voice tracking. We employ a pointer network that directly learns to predict positions in the ground truth text conditioned on the streaming speech. To train this pointer network, we generate ground truth training signals by using forced alignment between the read speech and the text being read on the training set. Exploring different forced alignment models, we find a neural attention based model is at least as close in alignment accuracy to the Montreal Forced Aligner, but surprisingly is a better training signal for the pointer network. Our results are reported on one adult speech data (TIMIT) and two children's speech datasets (CMU Kids and Reading Races). Our best model can accurately track adult speech with 87.8% accuracy and the much harder and disfluent children's speech with 77.1% accuracy on CMU Kids data and a 65.3% accuracy on the Reading Races dataset.
A Study on Prosodic Entrainment in Relation to Therapist Empathy in Counseling Conversation
Oct 22, 2023Counseling is carried out as spoken conversation between a therapist and a client. The empathy level expressed by the therapist is considered an important index of the quality of counseling and often assessed by an observer or the client. This research investigates the entrainment of speech prosody in relation to subjectively rated empathy. Experimental results show that the entrainment of intensity is more influential to empathy observation than that of pitch or speech rate in client-therapist interaction. The observer and the client have different perceptions of therapist empathy with the same entrained phenomena in pitch and intensity. The client's intention to make adjustment on pitch variation and intensity of speech is considered an indicator of the client's perception of counseling quality.