 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Accurate synthesis of Dysarthric Speech for ASR data augmentation
Aug 16, 2023
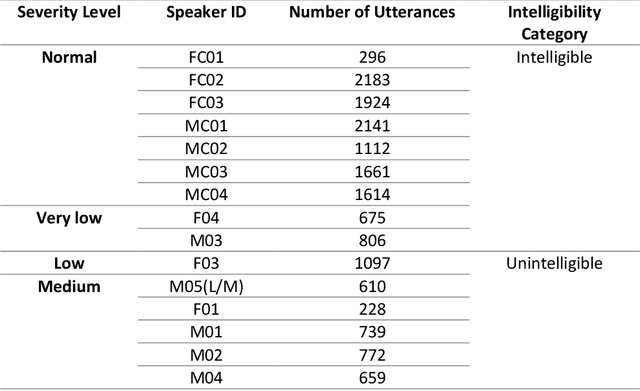
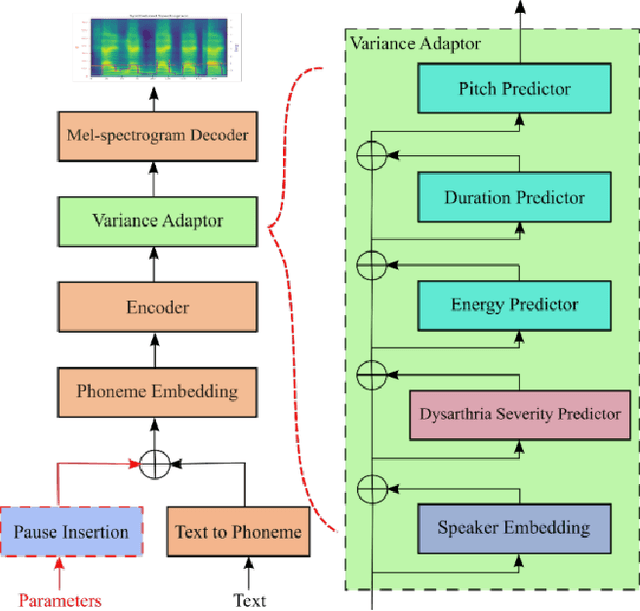
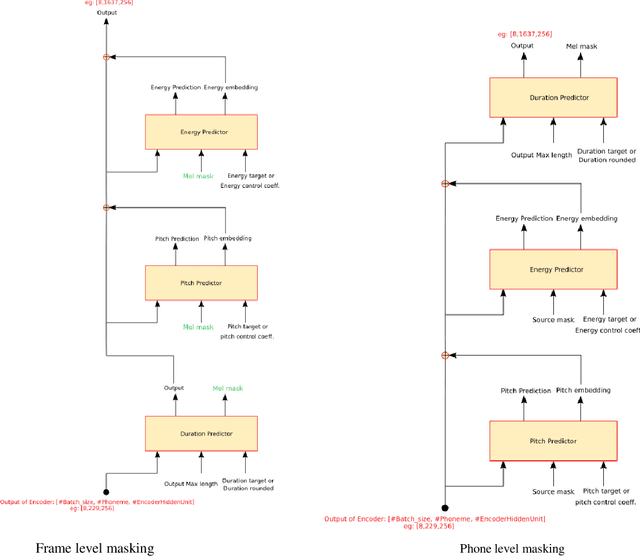
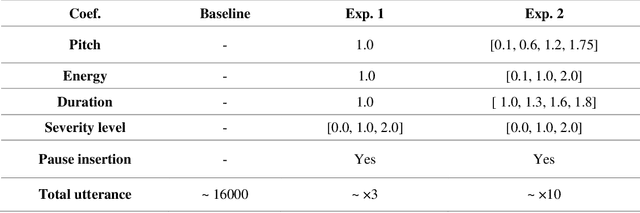
Dysarthria is a motor speech disorder often characterized by reduced speech intelligibility through slow, uncoordinated control of speech production muscles. Automatic Speech recognition (ASR) systems can help dysarthric talkers communicate more effectively. However, robust dysarthria-specific ASR requires a significant amount of training speech, which is not readily available for dysarthric talkers. This paper presents a new dysarthric speech synthesis method for the purpose of ASR training data augmentation. Differences in prosodic and acoustic characteristics of dysarthric spontaneous speech at varying severity levels are important components for dysarthric speech modeling, synthesis, and augmentation. For dysarthric speech synthesis, a modified neural multi-talker TTS is implemented by adding a dysarthria severity level coefficient and a pause insertion model to synthesize dysarthric speech for varying severity levels. To evaluate the effectiveness for synthesis of training data for ASR, dysarthria-specific speech recognition was used. Results show that a DNN-HMM model trained on additional synthetic dysarthric speech achieves WER improvement of 12.2% compared to the baseline, and that the addition of the severity level and pause insertion controls decrease WER by 6.5%, showing the effectiveness of adding these parameters. Overall results on the TORGO database demonstrate that using dysarthric synthetic speech to increase the amount of dysarthric-patterned speech for training has significant impact on the dysarthric ASR systems. In addition, we have conducted a subjective evaluation to evaluate the dysarthric-ness and similarity of synthesized speech. Our subjective evaluation shows that the perceived dysartrhic-ness of synthesized speech is similar to that of true dysarthric speech, especially for higher levels of dysarthria
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023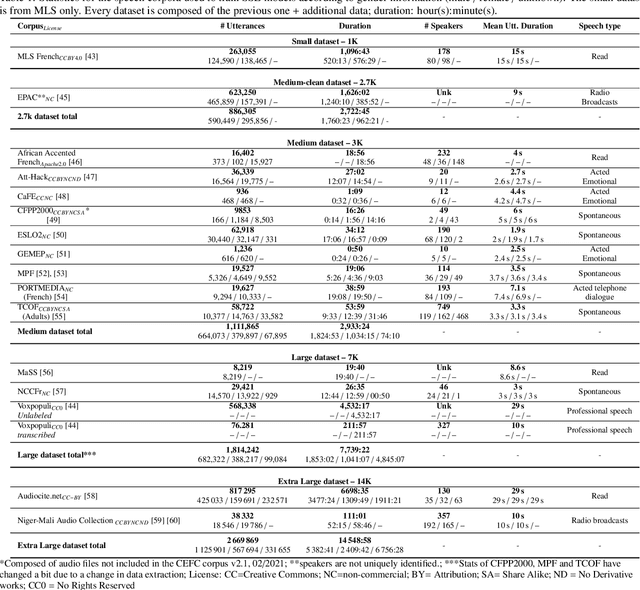
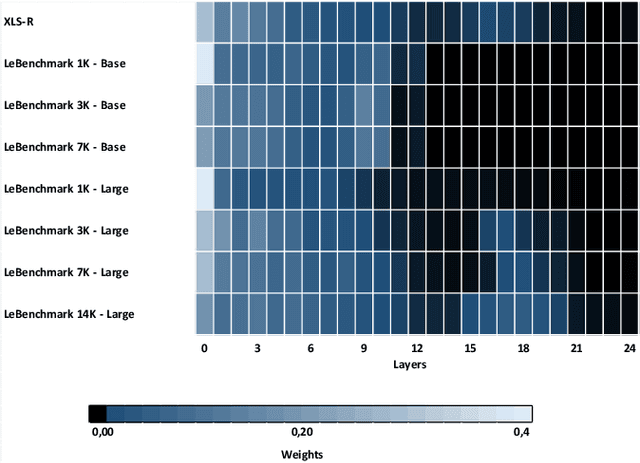
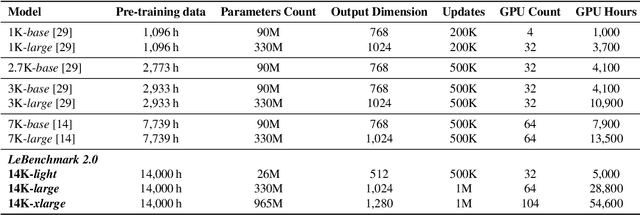
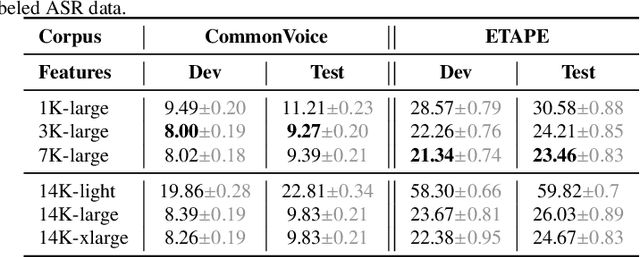
Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
Character-Level Bangla Text-to-IPA Transcription Using Transformer Architecture with Sequence Alignment
Nov 07, 2023The International Phonetic Alphabet (IPA) is indispensable in language learning and understanding, aiding users in accurate pronunciation and comprehension. Additionally, it plays a pivotal role in speech therapy, linguistic research, accurate transliteration, and the development of text-to-speech systems, making it an essential tool across diverse fields. Bangla being 7th as one of the widely used languages, gives rise to the need for IPA in its domain. Its IPA mapping is too diverse to be captured manually giving the need for Artificial Intelligence and Machine Learning in this field. In this study, we have utilized a transformer-based sequence-to-sequence model at the letter and symbol level to get the IPA of each Bangla word as the variation of IPA in association of different words is almost null. Our transformer model only consisted of 8.5 million parameters with only a single decoder and encoder layer. Additionally, to handle the punctuation marks and the occurrence of foreign languages in the text, we have utilized manual mapping as the model won't be able to learn to separate them from Bangla words while decreasing our required computational resources. Finally, maintaining the relative position of the sentence component IPAs and generation of the combined IPA has led us to achieve the top position with a word error rate of 0.10582 in the public ranking of DataVerse Challenge - ITVerse 2023 (https://www.kaggle.com/competitions/dataverse_2023/).
Hateful Messages: A Conversational Data Set of Hate Speech produced by Adolescents on Discord
Sep 04, 2023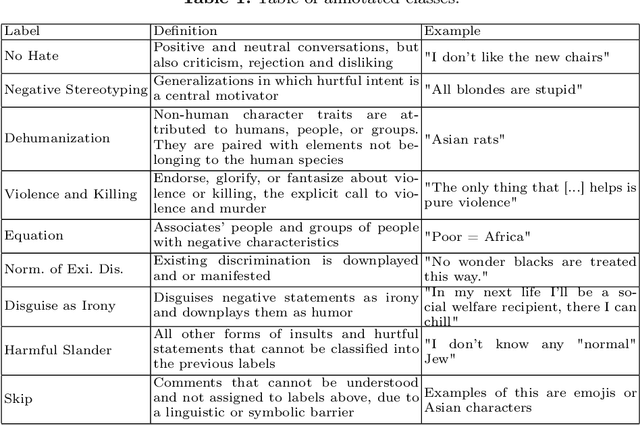

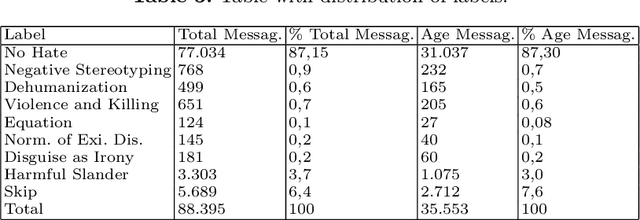
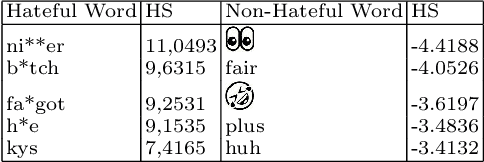
With the rise of social media, a rise of hateful content can be observed. Even though the understanding and definitions of hate speech varies, platforms, communities, and legislature all acknowledge the problem. Therefore, adolescents are a new and active group of social media users. The majority of adolescents experience or witness online hate speech. Research in the field of automated hate speech classification has been on the rise and focuses on aspects such as bias, generalizability, and performance. To increase generalizability and performance, it is important to understand biases within the data. This research addresses the bias of youth language within hate speech classification and contributes by providing a modern and anonymized hate speech youth language data set consisting of 88.395 annotated chat messages. The data set consists of publicly available online messages from the chat platform Discord. ~6,42% of the messages were classified by a self-developed annotation schema as hate speech. For 35.553 messages, the user profiles provided age annotations setting the average author age to under 20 years old.
Assessing the Generalization Gap of Learning-Based Speech Enhancement Systems in Noisy and Reverberant Environments
Sep 12, 2023The acoustic variability of noisy and reverberant speech mixtures is influenced by multiple factors, such as the spectro-temporal characteristics of the target speaker and the interfering noise, the signal-to-noise ratio (SNR) and the room characteristics. This large variability poses a major challenge for learning-based speech enhancement systems, since a mismatch between the training and testing conditions can substantially reduce the performance of the system. Generalization to unseen conditions is typically assessed by testing the system with a new speech, noise or binaural room impulse response (BRIR) database different from the one used during training. However, the difficulty of the speech enhancement task can change across databases, which can substantially influence the results. The present study introduces a generalization assessment framework that uses a reference model trained on the test condition, such that it can be used as a proxy for the difficulty of the test condition. This allows to disentangle the effect of the change in task difficulty from the effect of dealing with new data, and thus to define a new measure of generalization performance termed the generalization gap. The procedure is repeated in a cross-validation fashion by cycling through multiple speech, noise, and BRIR databases to accurately estimate the generalization gap. The proposed framework is applied to evaluate the generalization potential of a feedforward neural network (FFNN), Conv-TasNet, DCCRN and MANNER. We find that for all models, the performance degrades the most in speech mismatches, while good noise and room generalization can be achieved by training on multiple databases. Moreover, while recent models show higher performance in matched conditions, their performance substantially decreases in mismatched conditions and can become inferior to that of the FFNN-based system.
ASTER: Automatic Speech Recognition System Accessibility Testing for Stutterers
Aug 30, 2023
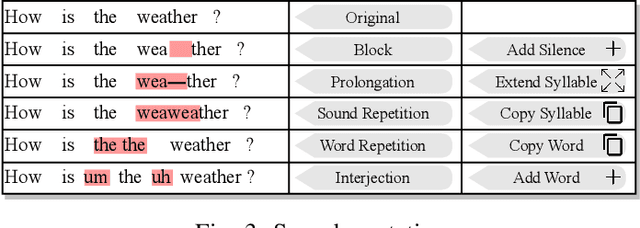
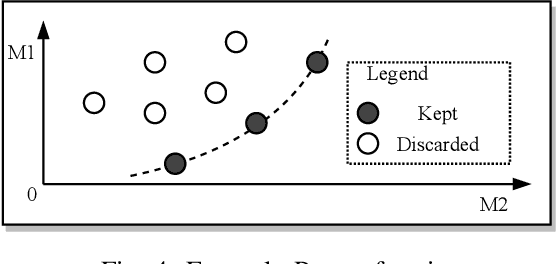
The popularity of automatic speech recognition (ASR) systems nowadays leads to an increasing need for improving their accessibility. Handling stuttering speech is an important feature for accessible ASR systems. To improve the accessibility of ASR systems for stutterers, we need to expose and analyze the failures of ASR systems on stuttering speech. The speech datasets recorded from stutterers are not diverse enough to expose most of the failures. Furthermore, these datasets lack ground truth information about the non-stuttered text, rendering them unsuitable as comprehensive test suites. Therefore, a methodology for generating stuttering speech as test inputs to test and analyze the performance of ASR systems is needed. However, generating valid test inputs in this scenario is challenging. The reason is that although the generated test inputs should mimic how stutterers speak, they should also be diverse enough to trigger more failures. To address the challenge, we propose ASTER, a technique for automatically testing the accessibility of ASR systems. ASTER can generate valid test cases by injecting five different types of stuttering. The generated test cases can both simulate realistic stuttering speech and expose failures in ASR systems. Moreover, ASTER can further enhance the quality of the test cases with a multi-objective optimization-based seed updating algorithm. We implemented ASTER as a framework and evaluated it on four open-source ASR models and three commercial ASR systems. We conduct a comprehensive evaluation of ASTER and find that it significantly increases the word error rate, match error rate, and word information loss in the evaluated ASR systems. Additionally, our user study demonstrates that the generated stuttering audio is indistinguishable from real-world stuttering audio clips.
M$^{2}$UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models
Nov 19, 2023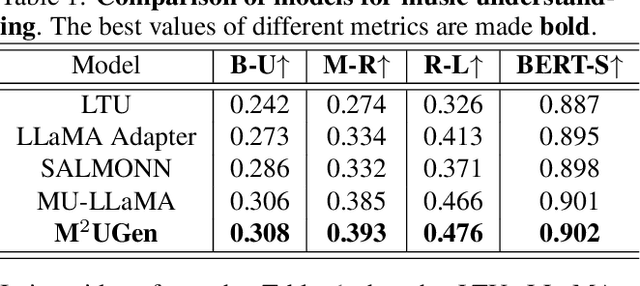
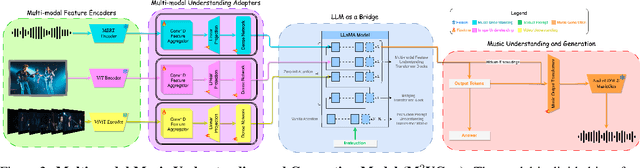
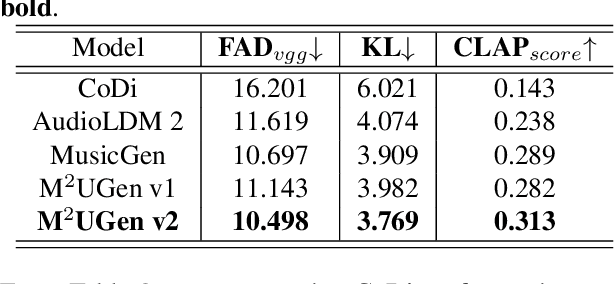
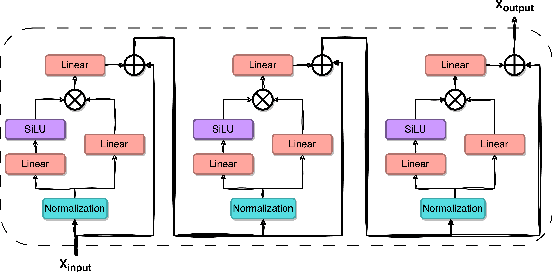
The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. They also utilize LLMs to understand human intention and generate desired outputs like images, videos, and music. However, research that combines both understanding and generation using LLMs is still limited and in its nascent stage. To address this gap, we introduce a Multi-modal Music Understanding and Generation (M$^{2}$UGen) framework that integrates LLM's abilities to comprehend and generate music for different modalities. The M$^{2}$UGen framework is purpose-built to unlock creative potential from diverse sources of inspiration, encompassing music, image, and video through the use of pretrained MERT, ViT, and ViViT models, respectively. To enable music generation, we explore the use of AudioLDM 2 and MusicGen. Bridging multi-modal understanding and music generation is accomplished through the integration of the LLaMA 2 model. Furthermore, we make use of the MU-LLaMA model to generate extensive datasets that support text/image/video-to-music generation, facilitating the training of our M$^{2}$UGen framework. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models.
The DeepZen Speech Synthesis System for Blizzard Challenge 2023
Aug 30, 2023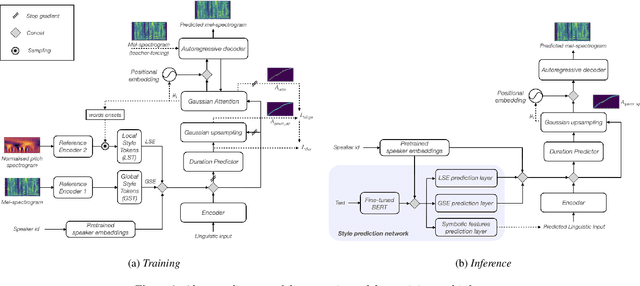

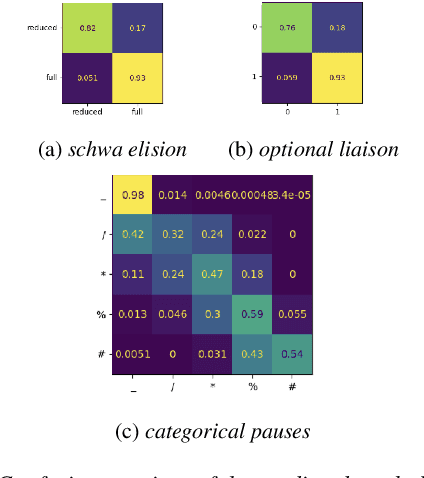
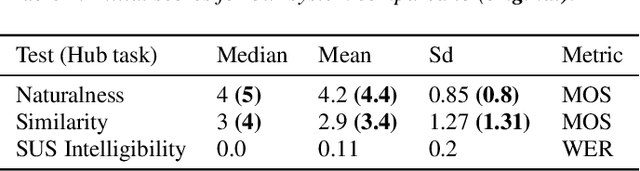
This paper describes the DeepZen text to speech (TTS) system for Blizzard Challenge 2023. The goal of this challenge is to synthesise natural and high-quality speech in French, from a large monospeaker dataset (hub task) and from a smaller dataset by speaker adaptation (spoke task). We participated to both tasks with the same model architecture. Our approach has been to use an auto-regressive model, which retains an advantage for generating natural sounding speech but to improve prosodic control in several ways. Similarly to non-attentive Tacotron, the model uses a duration predictor and gaussian upsampling at inference, but with a simpler unsupervised training. We also model the speaking style at both sentence and word levels by extracting global and local style tokens from the reference speech. At inference, the global and local style tokens are predicted from a BERT model run on text. This BERT model is also used to predict specific pronunciation features like schwa elision and optional liaisons. Finally, a modified version of HifiGAN trained on a large public dataset and fine-tuned on the target voices is used to generate speech waveform. Our team is identified as O in the the Blizzard evaluation and MUSHRA test results show that our system performs second ex aequo in both hub task (median score of 0.75) and spoke task (median score of 0.68), over 18 and 14 participants, respectively.
CReHate: Cross-cultural Re-annotation of English Hate Speech Dataset
Aug 31, 2023
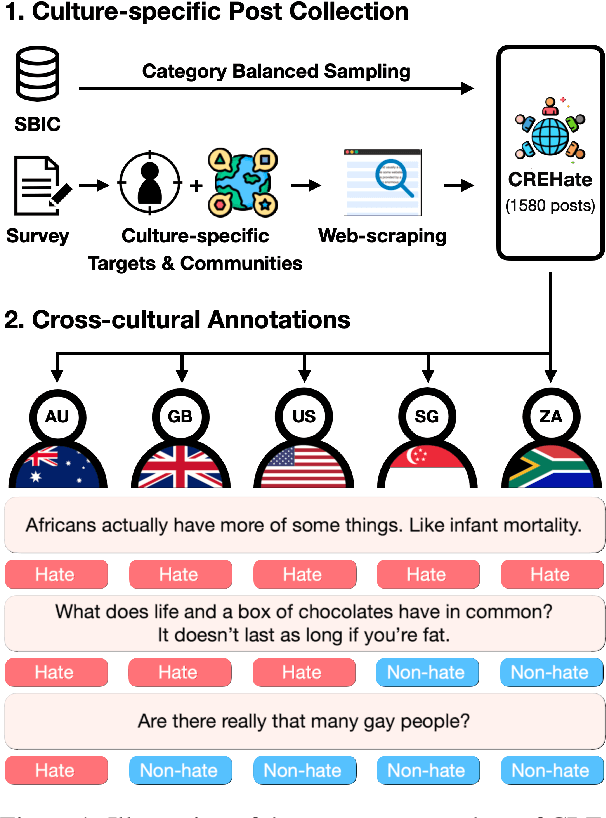
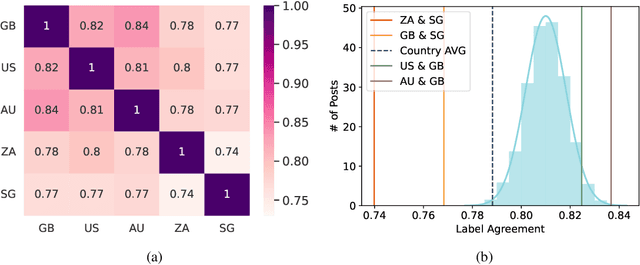
English datasets predominantly reflect the perspectives of certain nationalities, which can lead to cultural biases in models and datasets. This is particularly problematic in tasks heavily influenced by subjectivity, such as hate speech detection. To delve into how individuals from different countries perceive hate speech, we introduce CReHate, a cross-cultural re-annotation of the sampled SBIC dataset. This dataset includes annotations from five distinct countries: Australia, Singapore, South Africa, the United Kingdom, and the United States. Our thorough statistical analysis highlights significant differences based on nationality, with only 59.4% of the samples achieving consensus among all countries. We also introduce a culturally sensitive hate speech classifier via transfer learning, adept at capturing perspectives of different nationalities. These findings underscore the need to re-evaluate certain aspects of NLP research, especially with regard to the nuanced nature of hate speech in the English language.
Generalizable Zero-Shot Speaker Adaptive Speech Synthesis with Disentangled Representations
Aug 24, 2023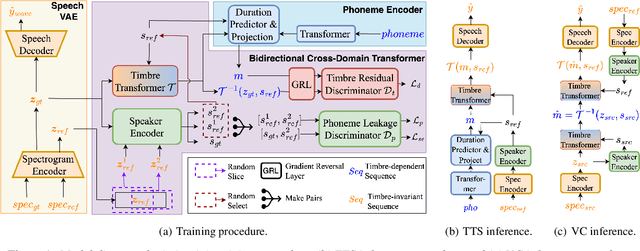
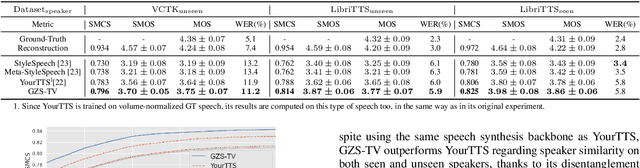

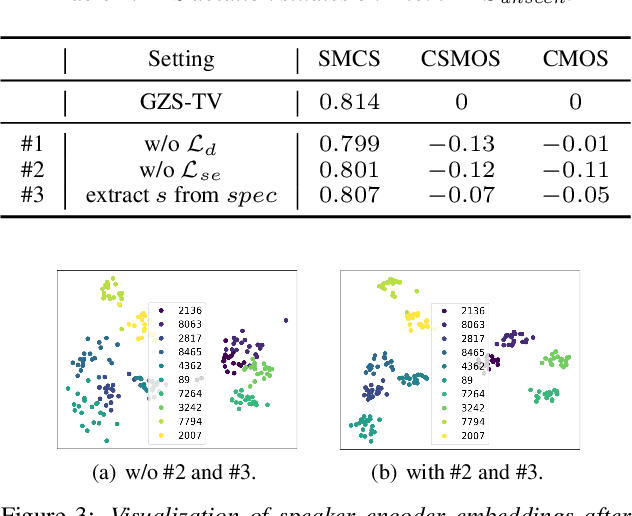
While most research into speech synthesis has focused on synthesizing high-quality speech for in-dataset speakers, an equally essential yet unsolved problem is synthesizing speech for unseen speakers who are out-of-dataset with limited reference data, i.e., speaker adaptive speech synthesis. Many studies have proposed zero-shot speaker adaptive text-to-speech and voice conversion approaches aimed at this task. However, most current approaches suffer from the degradation of naturalness and speaker similarity when synthesizing speech for unseen speakers (i.e., speakers not in the training dataset) due to the poor generalizability of the model in out-of-distribution data. To address this problem, we propose GZS-TV, a generalizable zero-shot speaker adaptive text-to-speech and voice conversion model. GZS-TV introduces disentangled representation learning for both speaker embedding extraction and timbre transformation to improve model generalization and leverages the representation learning capability of the variational autoencoder to enhance the speaker encoder. Our experiments demonstrate that GZS-TV reduces performance degradation on unseen speakers and outperforms all baseline models in multiple datasets.