 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Influence Scores at Scale for Efficient Language Data Sampling
Nov 27, 2023
Modern ML systems ingest data aggregated from diverse sources, such as synthetic, human-annotated, and live customer traffic. Understanding \textit{which} examples are important to the performance of a learning algorithm is crucial for efficient model training. Recently, a growing body of literature has given rise to various "influence scores," which use training artifacts such as model confidence or checkpointed gradients to identify important subsets of data. However, these methods have primarily been developed in computer vision settings, and it remains unclear how well they generalize to language-based tasks using pretrained models. In this paper, we explore the applicability of influence scores in language classification tasks. We evaluate a diverse subset of these scores on the SNLI dataset by quantifying accuracy changes in response to pruning training data through random and influence-score-based sampling. We then stress-test one of the scores -- "variance of gradients" (VoG) from Agarwal et al. (2022) -- in an NLU model stack that was exposed to dynamic user speech patterns in a voice assistant type of setting. Our experiments demonstrate that in many cases, encoder-based language models can be finetuned on roughly 50% of the original data without degradation in performance metrics. Along the way, we summarize lessons learned from applying out-of-the-box implementations of influence scores, quantify the effects of noisy and class-imbalanced data, and offer recommendations on score-based sampling for better accuracy and training efficiency.
Multi-teacher Distillation for Multilingual Spelling Correction
Nov 20, 2023Accurate spelling correction is a critical step in modern search interfaces, especially in an era of mobile devices and speech-to-text interfaces. For services that are deployed around the world, this poses a significant challenge for multilingual NLP: spelling errors need to be caught and corrected in all languages, and even in queries that use multiple languages. In this paper, we tackle this challenge using multi-teacher distillation. On our approach, a monolingual teacher model is trained for each language/locale, and these individual models are distilled into a single multilingual student model intended to serve all languages/locales. In experiments using open-source data as well as user data from a worldwide search service, we show that this leads to highly effective spelling correction models that can meet the tight latency requirements of deployed services.
Multi-Scale Sub-Band Constant-Q Transform Discriminator for High-Fidelity Vocoder
Nov 25, 2023Generative Adversarial Network (GAN) based vocoders are superior in inference speed and synthesis quality when reconstructing an audible waveform from an acoustic representation. This study focuses on improving the discriminator to promote GAN-based vocoders. Most existing time-frequency-representation-based discriminators are rooted in Short-Time Fourier Transform (STFT), whose time-frequency resolution in a spectrogram is fixed, making it incompatible with signals like singing voices that require flexible attention for different frequency bands. Motivated by that, our study utilizes the Constant-Q Transform (CQT), which owns dynamic resolution among frequencies, contributing to a better modeling ability in pitch accuracy and harmonic tracking. Specifically, we propose a Multi-Scale Sub-Band CQT (MS-SB-CQT) Discriminator, which operates on the CQT spectrogram at multiple scales and performs sub-band processing according to different octaves. Experiments conducted on both speech and singing voices confirm the effectiveness of our proposed method. Moreover, we also verified that the CQT-based and the STFT-based discriminators could be complementary under joint training. Specifically, enhanced by the proposed MS-SB-CQT and the existing MS-STFT Discriminators, the MOS of HiFi-GAN can be boosted from 3.27 to 3.87 for seen singers and from 3.40 to 3.78 for unseen singers.
Let There Be Sound: Reconstructing High Quality Speech from Silent Videos
Aug 29, 2023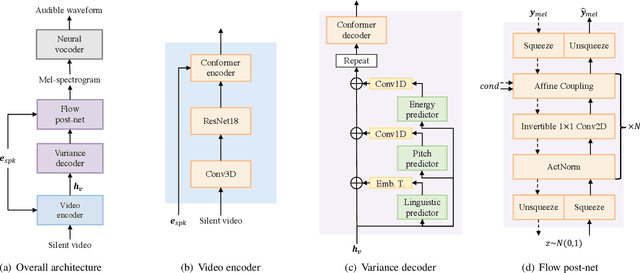
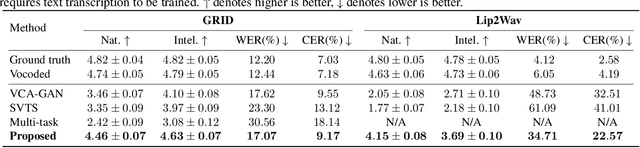
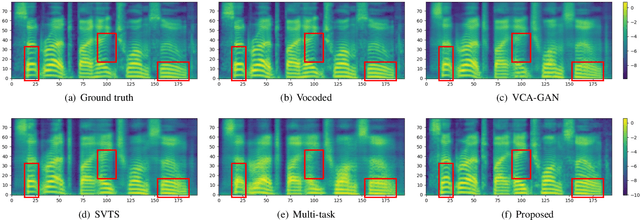
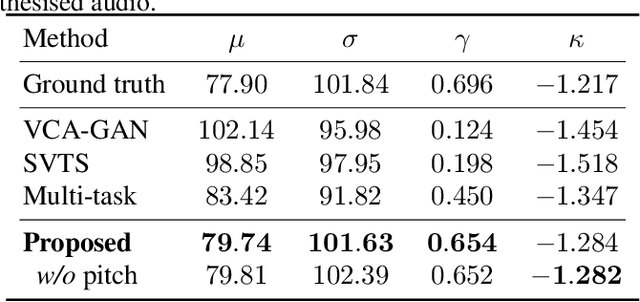
The goal of this work is to reconstruct high quality speech from lip motions alone, a task also known as lip-to-speech. A key challenge of lip-to-speech systems is the one-to-many mapping caused by (1) the existence of homophenes and (2) multiple speech variations, resulting in a mispronounced and over-smoothed speech. In this paper, we propose a novel lip-to-speech system that significantly improves the generation quality by alleviating the one-to-many mapping problem from multiple perspectives. Specifically, we incorporate (1) self-supervised speech representations to disambiguate homophenes, and (2) acoustic variance information to model diverse speech styles. Additionally, to better solve the aforementioned problem, we employ a flow based post-net which captures and refines the details of the generated speech. We perform extensive experiments and demonstrate that our method achieves the generation quality close to that of real human utterance, outperforming existing methods in terms of speech naturalness and intelligibility by a large margin. Synthesised samples are available at the anonymous demo page: https://mm.kaist.ac.kr/projects/LTBS.
ChatGPT in the context of precision agriculture data analytics
Nov 10, 2023In this study we argue that integrating ChatGPT into the data processing pipeline of automated sensors in precision agriculture has the potential to bring several benefits and enhance various aspects of modern farming practices. Policy makers often face a barrier when they need to get informed about the situation in vast agricultural fields to reach to decisions. They depend on the close collaboration between agricultural experts in the field, data analysts, and technology providers to create interdisciplinary teams that cannot always be secured on demand or establish effective communication across these diverse domains to respond in real-time. In this work we argue that the speech recognition input modality of ChatGPT provides a more intuitive and natural way for policy makers to interact with the database of the server of an agricultural data processing system to which a large, dispersed network of automated insect traps and sensors probes reports. The large language models map the speech input to text, allowing the user to form its own version of unconstrained verbal query, raising the barrier of having to learn and adapt oneself to a specific data analytics software. The output of the language model can interact through Python code and Pandas with the entire database, visualize the results and use speech synthesis to engage the user in an iterative and refining discussion related to the data. We show three ways of how ChatGPT can interact with the database of the remote server to which a dispersed network of different modalities (optical counters, vibration recordings, pictures, and video), report. We examine the potential and the validity of the response of ChatGPT in analyzing, and interpreting agricultural data, providing real time insights and recommendations to stakeholders
Topological Data Mapping of Online Hate Speech, Misinformation, and General Mental Health: A Large Language Model Based Study
Sep 22, 2023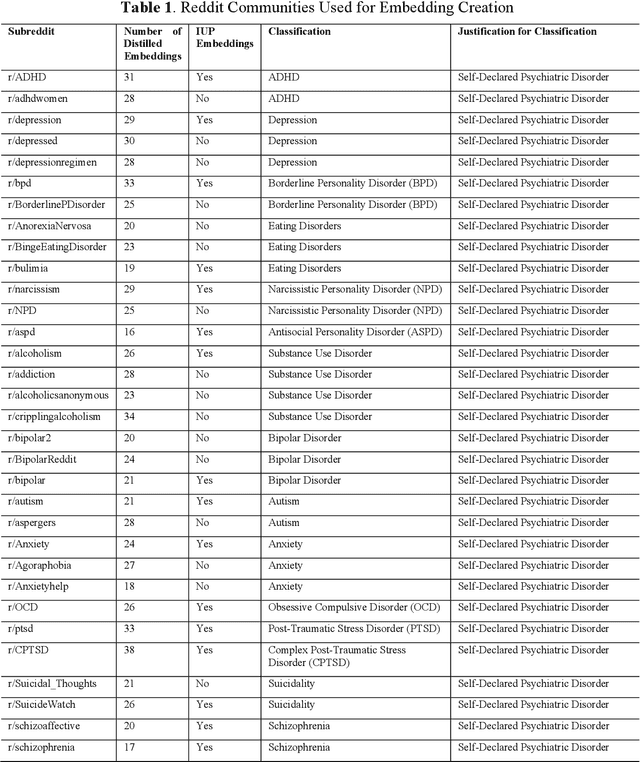
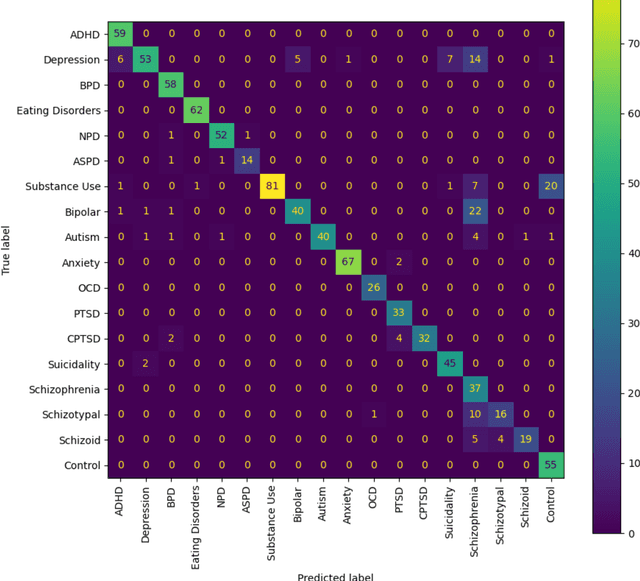
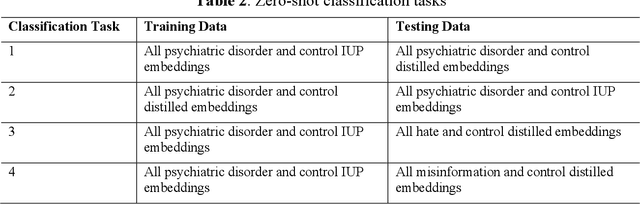
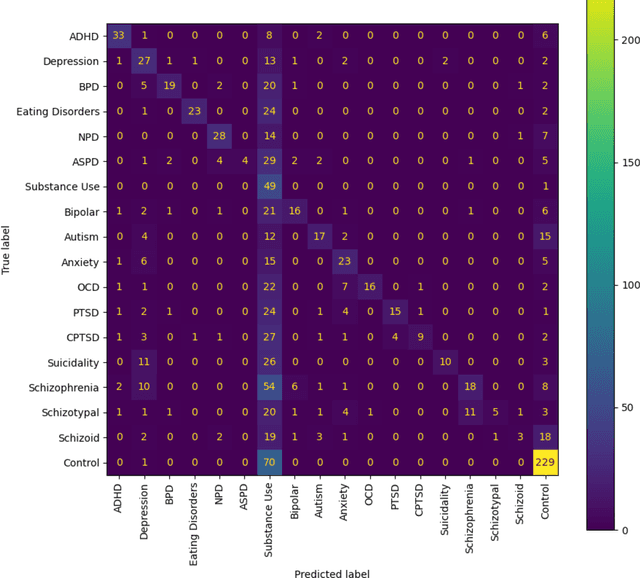
The advent of social media has led to an increased concern over its potential to propagate hate speech and misinformation, which, in addition to contributing to prejudice and discrimination, has been suspected of playing a role in increasing social violence and crimes in the United States. While literature has shown the existence of an association between posting hate speech and misinformation online and certain personality traits of posters, the general relationship and relevance of online hate speech/misinformation in the context of overall psychological wellbeing of posters remain elusive. One difficulty lies in the lack of adequate data analytics tools capable of adequately analyzing the massive amount of social media posts to uncover the underlying hidden links. Recent progresses in machine learning and large language models such as ChatGPT have made such an analysis possible. In this study, we collected thousands of posts from carefully selected communities on the social media site Reddit. We then utilized OpenAI's GPT3 to derive embeddings of these posts, which are high-dimensional real-numbered vectors that presumably represent the hidden semantics of posts. We then performed various machine-learning classifications based on these embeddings in order to understand the role of hate speech/misinformation in various communities. Finally, a topological data analysis (TDA) was applied to the embeddings to obtain a visual map connecting online hate speech, misinformation, various psychiatric disorders, and general mental health.
Syn-Att: Synthetic Speech Attribution via Semi-Supervised Unknown Multi-Class Ensemble of CNNs
Sep 15, 2023With the huge technological advances introduced by deep learning in audio & speech processing, many novel synthetic speech techniques achieved incredible realistic results. As these methods generate realistic fake human voices, they can be used in malicious acts such as people imitation, fake news, spreading, spoofing, media manipulations, etc. Hence, the ability to detect synthetic or natural speech has become an urgent necessity. Moreover, being able to tell which algorithm has been used to generate a synthetic speech track can be of preeminent importance to track down the culprit. In this paper, a novel strategy is proposed to attribute a synthetic speech track to the generator that is used to synthesize it. The proposed detector transforms the audio into log-mel spectrogram, extracts features using CNN, and classifies it between five known and unknown algorithms, utilizing semi-supervision and ensemble to improve its robustness and generalizability significantly. The proposed detector is validated on two evaluation datasets consisting of a total of 18,000 weakly perturbed (Eval 1) & 10,000 strongly perturbed (Eval 2) synthetic speeches. The proposed method outperforms other top teams in accuracy by 12-13% on Eval 2 and 1-2% on Eval 1, in the IEEE SP Cup challenge at ICASSP 2022.
NoLACE: Improving Low-Complexity Speech Codec Enhancement Through Adaptive Temporal Shaping
Sep 25, 2023Speech codec enhancement methods are designed to remove distortions added by speech codecs. While classical methods are very low in complexity and add zero delay, their effectiveness is rather limited. Compared to that, DNN-based methods deliver higher quality but they are typically high in complexity and/or require delay. The recently proposed Linear Adaptive Coding Enhancer (LACE) addresses this problem by combining DNNs with classical long-term/short-term postfiltering resulting in a causal low-complexity model. A short-coming of the LACE model is, however, that quality quickly saturates when the model size is scaled up. To mitigate this problem, we propose a novel adatpive temporal shaping module that adds high temporal resolution to the LACE model resulting in the Non-Linear Adaptive Coding Enhancer (NoLACE). We adapt NoLACE to enhance the Opus codec and show that NoLACE significantly outperforms both the Opus baseline and an enlarged LACE model at 6, 9 and 12 kb/s. We also show that LACE and NoLACE are well-behaved when used with an ASR system.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 21, 2023Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
Iterative Shallow Fusion of Backward Language Model for End-to-End Speech Recognition
Oct 17, 2023We propose a new shallow fusion (SF) method to exploit an external backward language model (BLM) for end-to-end automatic speech recognition (ASR). The BLM has complementary characteristics with a forward language model (FLM), and the effectiveness of their combination has been confirmed by rescoring ASR hypotheses as post-processing. In the proposed SF, we iteratively apply the BLM to partial ASR hypotheses in the backward direction (i.e., from the possible next token to the start symbol) during decoding, substituting the newly calculated BLM scores for the scores calculated at the last iteration. To enhance the effectiveness of this iterative SF (ISF), we train a partial sentence-aware BLM (PBLM) using reversed text data including partial sentences, considering the framework of ISF. In experiments using an attention-based encoder-decoder ASR system, we confirmed that ISF using the PBLM shows comparable performance with SF using the FLM. By performing ISF, early pruning of prospective hypotheses can be prevented during decoding, and we can obtain a performance improvement compared to applying the PBLM as post-processing. Finally, we confirmed that, by combining SF and ISF, further performance improvement can be obtained thanks to the complementarity of the FLM and PBLM.