 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Expressive paragraph text-to-speech synthesis with multi-step variational autoencoder
Aug 29, 2023
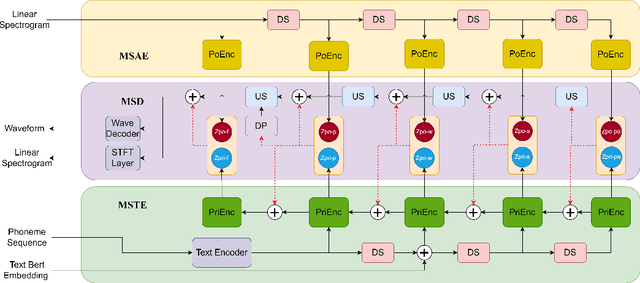
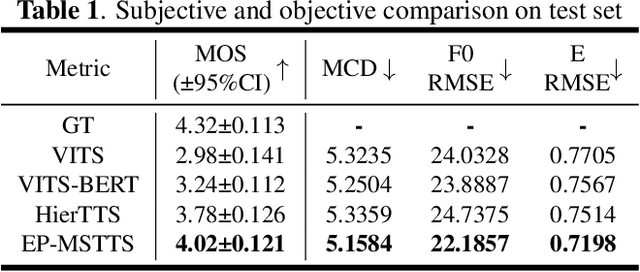
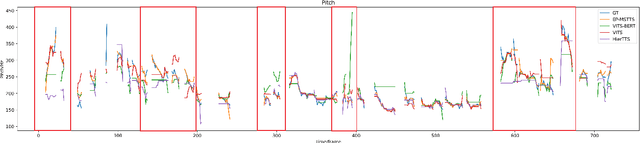
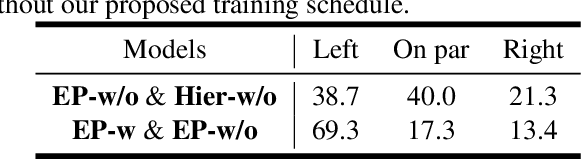
Neural networks have been able to generate high-quality single-sentence speech with substantial expressiveness. However, it remains a challenge concerning paragraph-level speech synthesis due to the need for coherent acoustic features while delivering fluctuating speech styles. Meanwhile, training these models directly on over-length speech leads to a deterioration in the quality of synthesis speech. To address these problems, we propose a high-quality and expressive paragraph speech synthesis system with a multi-step variational autoencoder. Specifically, we employ multi-step latent variables to capture speech information at different grammatical levels before utilizing these features in parallel to generate speech waveform. We also propose a three-step training method to improve the decoupling ability. Our model was trained on a single-speaker French audiobook corpus released at Blizzard Challenge 2023. Experimental results underscore the significant superiority of our system over baseline models.
Modelling prospective memory and resilient situated communications via Wizard of Oz
Nov 09, 2023This abstract presents a scenario for human-robot action in a home setting involving an older adult and a robot. The scenario is designed to explore the envisioned modelling of memory for communication with a socially assistive robots (SAR). The scenario will enable the gathering of data on failures of speech technology and human-robot communication involving shared memory that may occur during daily activities such as a music-listening activity.
Speech Emotion Recognition with Distilled Prosodic and Linguistic Affect Representations
Sep 09, 2023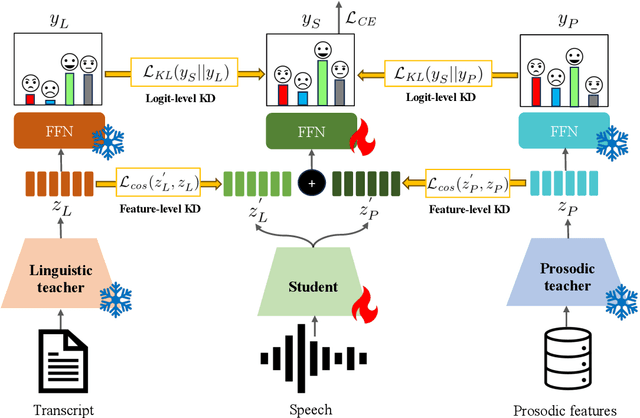
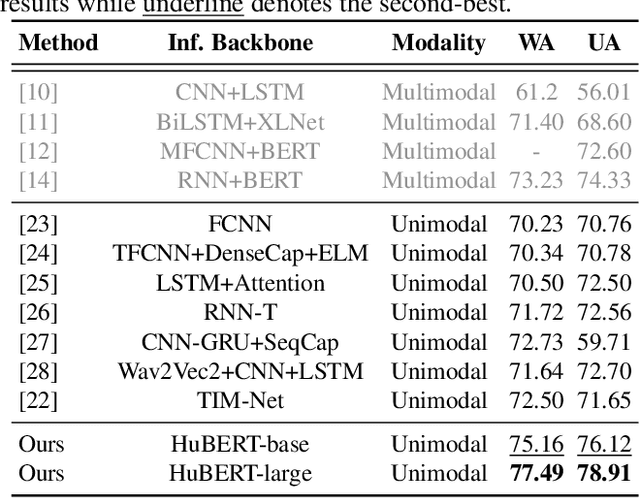
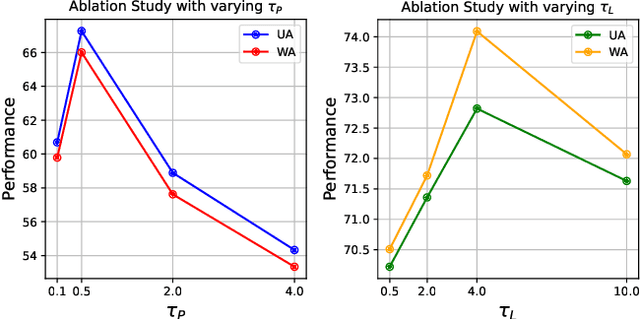
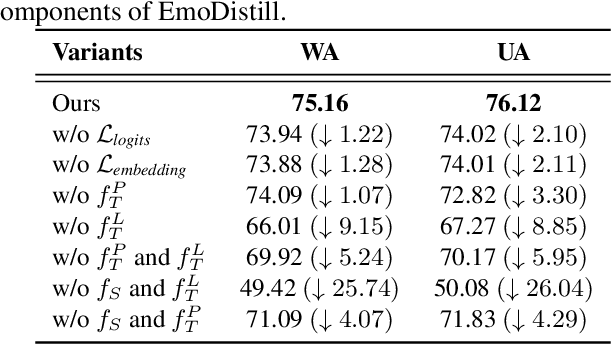
We propose EmoDistill, a novel speech emotion recognition (SER) framework that leverages cross-modal knowledge distillation during training to learn strong linguistic and prosodic representations of emotion from speech. During inference, our method only uses a stream of speech signals to perform unimodal SER thus reducing computation overhead and avoiding run-time transcription and prosodic feature extraction errors. During training, our method distills information at both embedding and logit levels from a pair of pre-trained Prosodic and Linguistic teachers that are fine-tuned for SER. Experiments on the IEMOCAP benchmark demonstrate that our method outperforms other unimodal and multimodal techniques by a considerable margin, and achieves state-of-the-art performance of 77.49% unweighted accuracy and 78.91% weighted accuracy. Detailed ablation studies demonstrate the impact of each component of our method.
Brain-Driven Representation Learning Based on Diffusion Model
Nov 14, 2023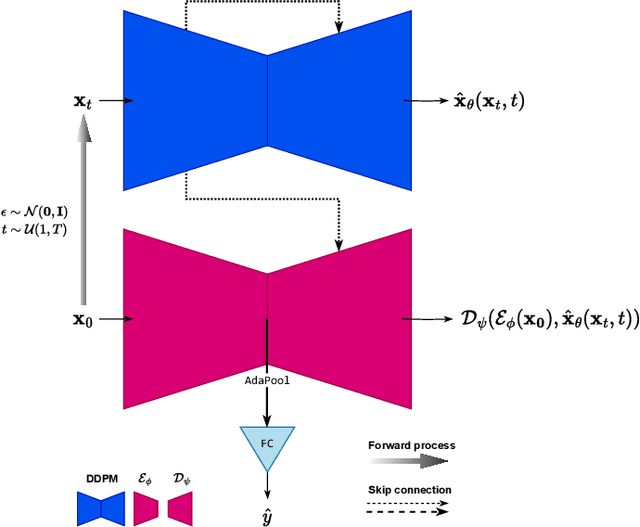


Interpreting EEG signals linked to spoken language presents a complex challenge, given the data's intricate temporal and spatial attributes, as well as the various noise factors. Denoising diffusion probabilistic models (DDPMs), which have recently gained prominence in diverse areas for their capabilities in representation learning, are explored in our research as a means to address this issue. Using DDPMs in conjunction with a conditional autoencoder, our new approach considerably outperforms traditional machine learning algorithms and established baseline models in accuracy. Our results highlight the potential of DDPMs as a sophisticated computational method for the analysis of speech-related EEG signals. This could lead to significant advances in brain-computer interfaces tailored for spoken communication.
IruMozhi: Automatically classifying diglossia in Tamil
Nov 13, 2023Tamil, a Dravidian language of South Asia, is a highly diglossic language with two very different registers in everyday use: Literary Tamil (preferred in writing and formal communication) and Spoken Tamil (confined to speech and informal media). Spoken Tamil is under-supported in modern NLP systems. In this paper, we release IruMozhi, a human-annotated dataset of parallel text in Literary and Spoken Tamil. We train classifiers on the task of identifying which variety a text belongs to. We use these models to gauge the availability of pretraining data in Spoken Tamil, to audit the composition of existing labelled datasets for Tamil, and to encourage future work on the variety.
Rep2wav: Noise Robust text-to-speech Using self-supervised representations
Aug 28, 2023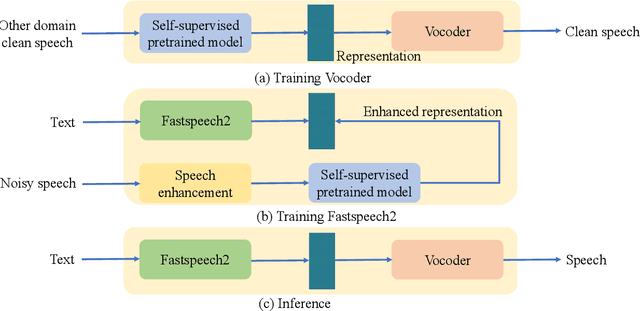


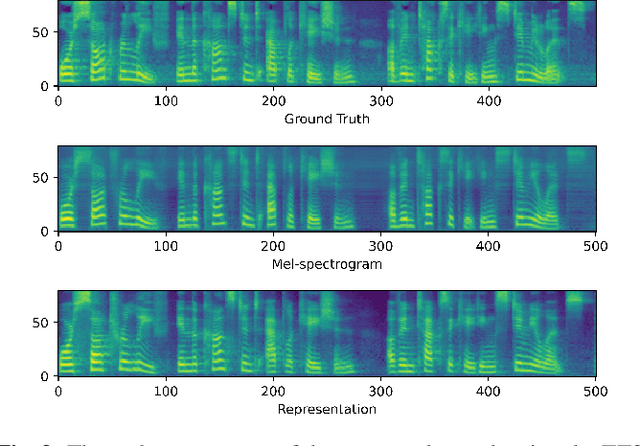
Benefiting from the development of deep learning, text-to-speech (TTS) techniques using clean speech have achieved significant performance improvements. The data collected from real scenes often contain noise and generally needs to be denoised by speech enhancement models. Noise-robust TTS models are often trained using the enhanced speech, which thus suffer from speech distortion and background noise that affect the quality of the synthesized speech. Meanwhile, it was shown that self-supervised pre-trained models exhibit excellent noise robustness on many speech tasks, implying that the learned representation has a better tolerance for noise perturbations. In this work, we therefore explore pre-trained models to improve the noise robustness of TTS models. Based on HIFI-GAN we first propose a representation-to-waveform vocoder, which aims to learn to map the representation of pre-trained models to the waveform. We then propose a text-to-representation Fastspeech2 model, which aims to learn to map text to pre-trained model representations. Experimental results on the LJSpeech and LibriTTS datasets show that our method outperforms those using speech enhancement methods in both subjective and objective metrics. Audio samples are available at: https://zqs01.github.io/rep2wav/.
REDS: Resource-Efficient Deep Subnetworks for Dynamic Resource Constraints
Nov 22, 2023Deep models deployed on edge devices frequently encounter resource variability, which arises from fluctuating energy levels, timing constraints, or prioritization of other critical tasks within the system. State-of-the-art machine learning pipelines generate resource-agnostic models, not capable to adapt at runtime. In this work we introduce Resource-Efficient Deep Subnetworks (REDS) to tackle model adaptation to variable resources. In contrast to the state-of-the-art, REDS use structured sparsity constructively by exploiting permutation invariance of neurons, which allows for hardware-specific optimizations. Specifically, REDS achieve computational efficiency by (1) skipping sequential computational blocks identified by a novel iterative knapsack optimizer, and (2) leveraging simple math to re-arrange the order of operations in REDS computational graph to take advantage of the data cache. REDS support conventional deep networks frequently deployed on the edge and provide computational benefits even for small and simple networks. We evaluate REDS on six benchmark architectures trained on the Google Speech Commands, FMNIST and CIFAR10 datasets, and test on four off-the-shelf mobile and embedded hardware platforms. We provide a theoretical result and empirical evidence for REDS outstanding performance in terms of submodels' test set accuracy, and demonstrate an adaptation time in response to dynamic resource constraints of under 40$\mu$s, utilizing a 2-layer fully-connected network on Arduino Nano 33 BLE Sense.
Overview of the HASOC Subtrack at FIRE 2023: Identification of Tokens Contributing to Explicit Hate in English by Span Detection
Nov 16, 2023As hate speech continues to proliferate on the web, it is becoming increasingly important to develop computational methods to mitigate it. Reactively, using black-box models to identify hateful content can perplex users as to why their posts were automatically flagged as hateful. On the other hand, proactive mitigation can be achieved by suggesting rephrasing before a post is made public. However, both mitigation techniques require information about which part of a post contains the hateful aspect, i.e., what spans within a text are responsible for conveying hate. Better detection of such spans can significantly reduce explicitly hateful content on the web. To further contribute to this research area, we organized HateNorm at HASOC-FIRE 2023, focusing on explicit span detection in English Tweets. A total of 12 teams participated in the competition, with the highest macro-F1 observed at 0.58.
DurIAN-E: Duration Informed Attention Network For Expressive Text-to-Speech Synthesis
Sep 22, 2023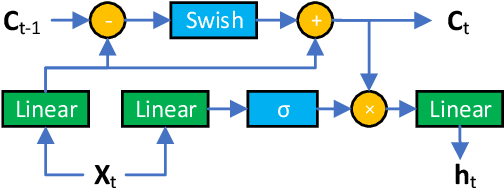

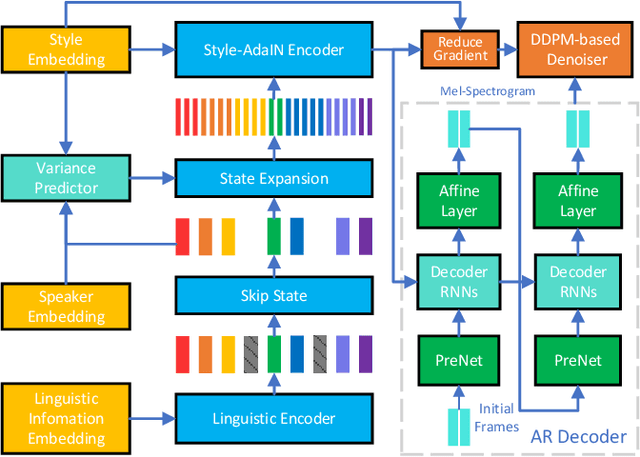
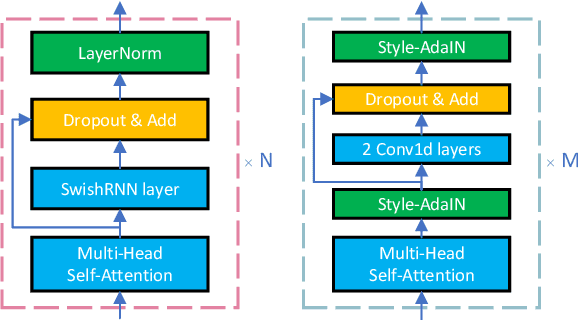
This paper introduces an improved duration informed attention neural network (DurIAN-E) for expressive and high-fidelity text-to-speech (TTS) synthesis. Inherited from the original DurIAN model, an auto-regressive model structure in which the alignments between the input linguistic information and the output acoustic features are inferred from a duration model is adopted. Meanwhile the proposed DurIAN-E utilizes multiple stacked SwishRNN-based Transformer blocks as linguistic encoders. Style-Adaptive Instance Normalization (SAIN) layers are exploited into frame-level encoders to improve the modeling ability of expressiveness. A denoiser incorporating both denoising diffusion probabilistic model (DDPM) for mel-spectrograms and SAIN modules is conducted to further improve the synthetic speech quality and expressiveness. Experimental results prove that the proposed expressive TTS model in this paper can achieve better performance than the state-of-the-art approaches in both subjective mean opinion score (MOS) and preference tests.
EMOCONV-DIFF: Diffusion-based Speech Emotion Conversion for Non-parallel and In-the-wild Data
Sep 14, 2023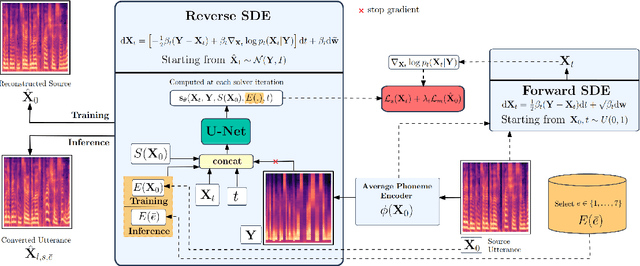
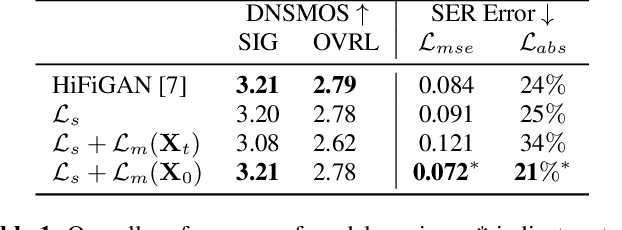
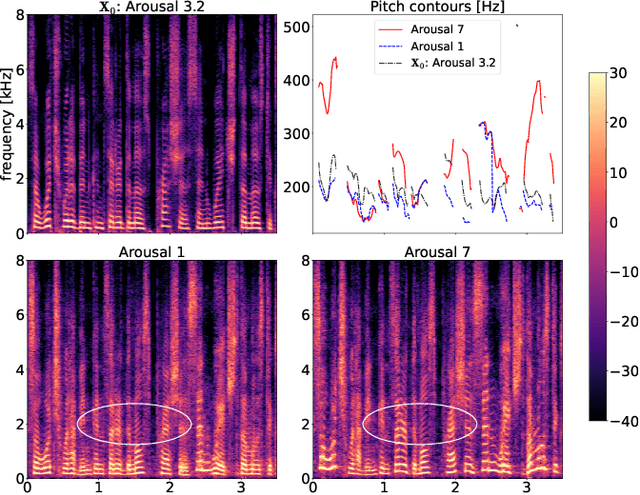
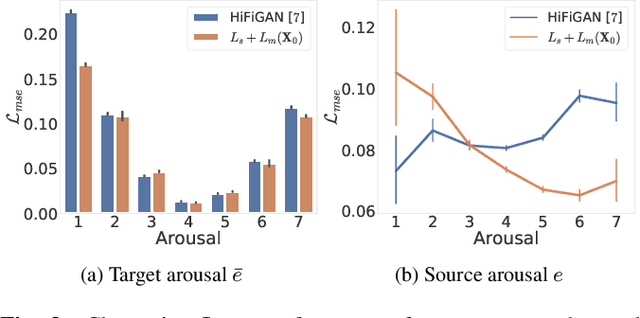
Speech emotion conversion is the task of converting the expressed emotion of a spoken utterance to a target emotion while preserving the lexical content and speaker identity. While most existing works in speech emotion conversion rely on acted-out datasets and parallel data samples, in this work we specifically focus on more challenging in-the-wild scenarios and do not rely on parallel data. To this end, we propose a diffusion-based generative model for speech emotion conversion, the EmoConv-Diff, that is trained to reconstruct an input utterance while also conditioning on its emotion. Subsequently, at inference, a target emotion embedding is employed to convert the emotion of the input utterance to the given target emotion. As opposed to performing emotion conversion on categorical representations, we use a continuous arousal dimension to represent emotions while also achieving intensity control. We validate the proposed methodology on a large in-the-wild dataset, the MSP-Podcast v1.10. Our results show that the proposed diffusion model is indeed capable of synthesizing speech with a controllable target emotion. Crucially, the proposed approach shows improved performance along the extreme values of arousal and thereby addresses a common challenge in the speech emotion conversion literature.