 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 21, 2023
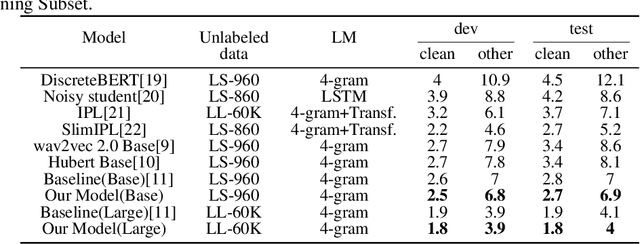
Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
ChatGPT in the context of precision agriculture data analytics
Nov 10, 2023In this study we argue that integrating ChatGPT into the data processing pipeline of automated sensors in precision agriculture has the potential to bring several benefits and enhance various aspects of modern farming practices. Policy makers often face a barrier when they need to get informed about the situation in vast agricultural fields to reach to decisions. They depend on the close collaboration between agricultural experts in the field, data analysts, and technology providers to create interdisciplinary teams that cannot always be secured on demand or establish effective communication across these diverse domains to respond in real-time. In this work we argue that the speech recognition input modality of ChatGPT provides a more intuitive and natural way for policy makers to interact with the database of the server of an agricultural data processing system to which a large, dispersed network of automated insect traps and sensors probes reports. The large language models map the speech input to text, allowing the user to form its own version of unconstrained verbal query, raising the barrier of having to learn and adapt oneself to a specific data analytics software. The output of the language model can interact through Python code and Pandas with the entire database, visualize the results and use speech synthesis to engage the user in an iterative and refining discussion related to the data. We show three ways of how ChatGPT can interact with the database of the remote server to which a dispersed network of different modalities (optical counters, vibration recordings, pictures, and video), report. We examine the potential and the validity of the response of ChatGPT in analyzing, and interpreting agricultural data, providing real time insights and recommendations to stakeholders
Kid-Whisper: Towards Bridging the Performance Gap in Automatic Speech Recognition for Children VS. Adults
Sep 12, 2023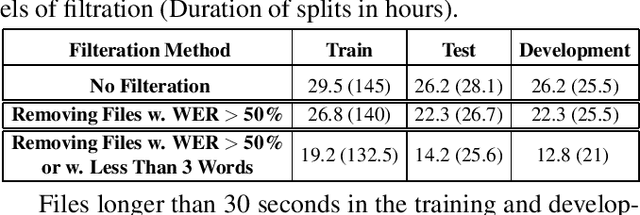
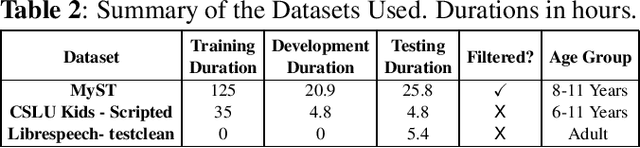
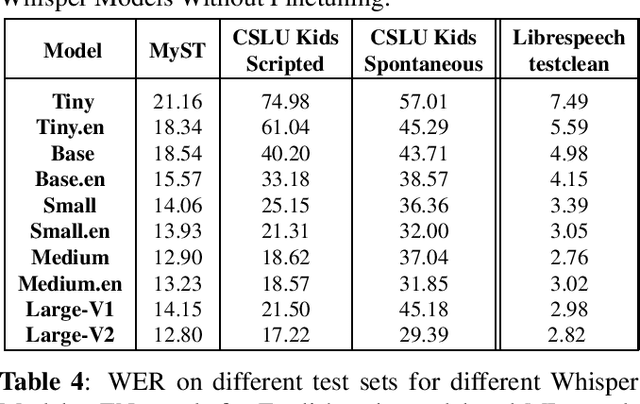
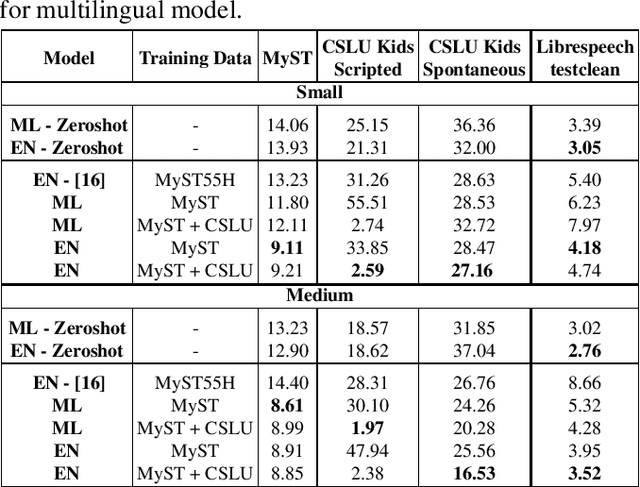
Recent advancements in Automatic Speech Recognition (ASR) systems, exemplified by Whisper, have demonstrated the potential of these systems to approach human-level performance given sufficient data. However, this progress doesn't readily extend to ASR for children due to the limited availability of suitable child-specific databases and the distinct characteristics of children's speech. A recent study investigated leveraging the My Science Tutor (MyST) children's speech corpus to enhance Whisper's performance in recognizing children's speech. This paper builds on these findings by enhancing the utility of the MyST dataset through more efficient data preprocessing. We also highlight important challenges towards improving children's ASR performance. The results showcase the viable and efficient integration of Whisper for effective children's speech recognition.
Spiking Structured State Space Model for Monaural Speech Enhancement
Sep 07, 2023
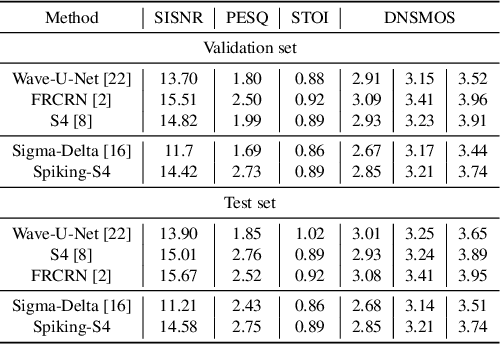

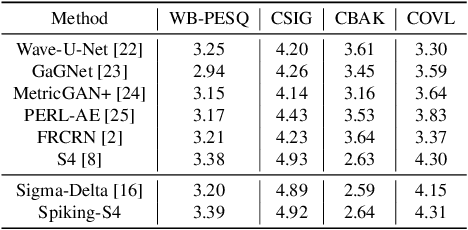
Speech enhancement seeks to extract clean speech from noisy signals. Traditional deep learning methods face two challenges: efficiently using information in long speech sequences and high computational costs. To address these, we introduce the Spiking Structured State Space Model (Spiking-S4). This approach merges the energy efficiency of Spiking Neural Networks (SNN) with the long-range sequence modeling capabilities of Structured State Space Models (S4), offering a compelling solution. Evaluation on the DNS Challenge and VoiceBank+Demand Datasets confirms that Spiking-S4 rivals existing Artificial Neural Network (ANN) methods but with fewer computational resources, as evidenced by reduced parameters and Floating Point Operations (FLOPs).
DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-speech Generation
Sep 13, 2023In the Text-to-speech(TTS) task, the latent diffusion model has excellent fidelity and generalization, but its expensive resource consumption and slow inference speed have always been a challenging. This paper proposes Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation(DCTTS). The following contributions are made by DCTTS: 1) The TTS diffusion model based on discrete space significantly lowers the computational consumption of the diffusion model and improves sampling speed; 2) The contrastive learning method based on discrete space is used to enhance the alignment connection between speech and text and improve sampling quality; and 3) It uses an efficient text encoder to simplify the model's parameters and increase computational efficiency. The experimental results demonstrate that the approach proposed in this paper has outstanding speech synthesis quality and sampling speed while significantly reducing the resource consumption of diffusion model. The synthesized samples are available at https://github.com/lawtherWu/DCTTS.
Echotune: A Modular Extractor Leveraging the Variable-Length Nature of Speech in ASR Tasks
Sep 14, 2023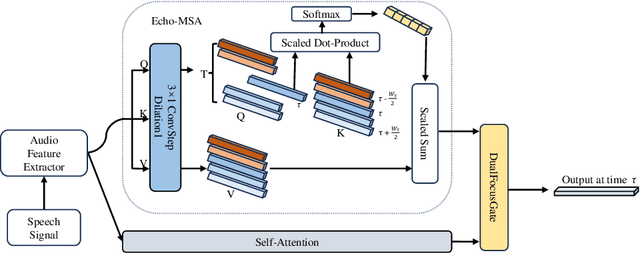
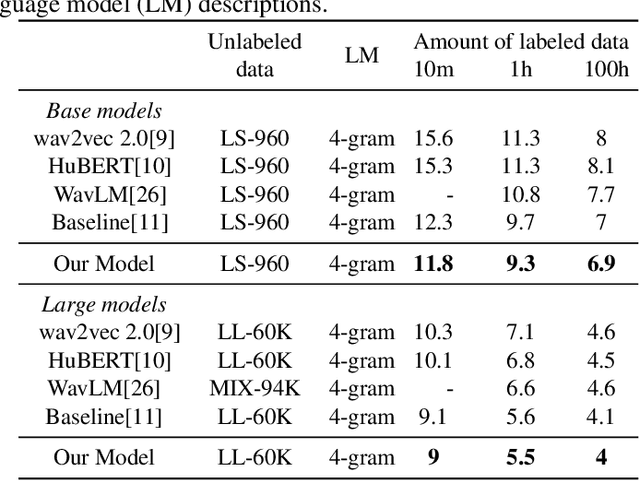
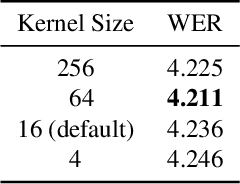
The Transformer architecture has proven to be highly effective for Automatic Speech Recognition (ASR) tasks, becoming a foundational component for a plethora of research in the domain. Historically, many approaches have leaned on fixed-length attention windows, which becomes problematic for varied speech samples in duration and complexity, leading to data over-smoothing and neglect of essential long-term connectivity. Addressing this limitation, we introduce Echo-MSA, a nimble module equipped with a variable-length attention mechanism that accommodates a range of speech sample complexities and durations. This module offers the flexibility to extract speech features across various granularities, spanning from frames and phonemes to words and discourse. The proposed design captures the variable length feature of speech and addresses the limitations of fixed-length attention. Our evaluation leverages a parallel attention architecture complemented by a dynamic gating mechanism that amalgamates traditional attention with the Echo-MSA module output. Empirical evidence from our study reveals that integrating Echo-MSA into the primary model's training regime significantly enhances the word error rate (WER) performance, all while preserving the intrinsic stability of the original model.
RoDia: A New Dataset for Romanian Dialect Identification from Speech
Sep 06, 2023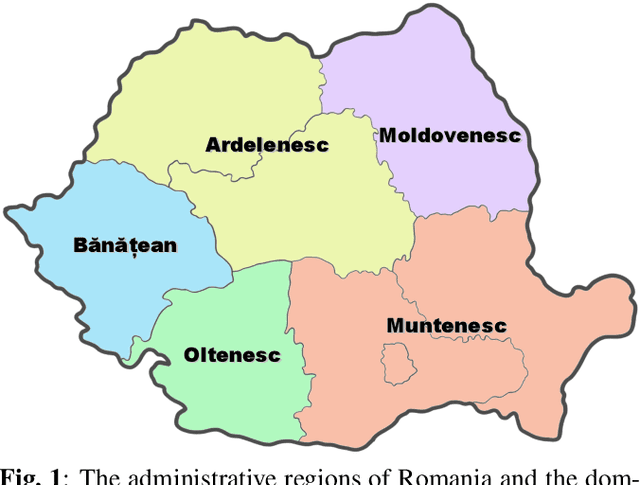
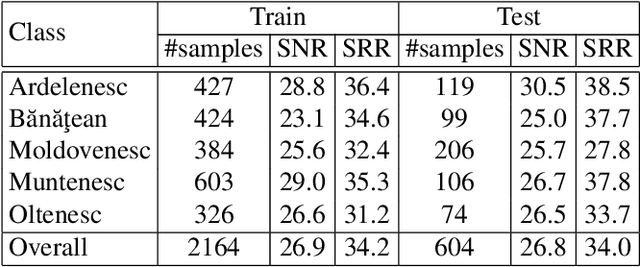
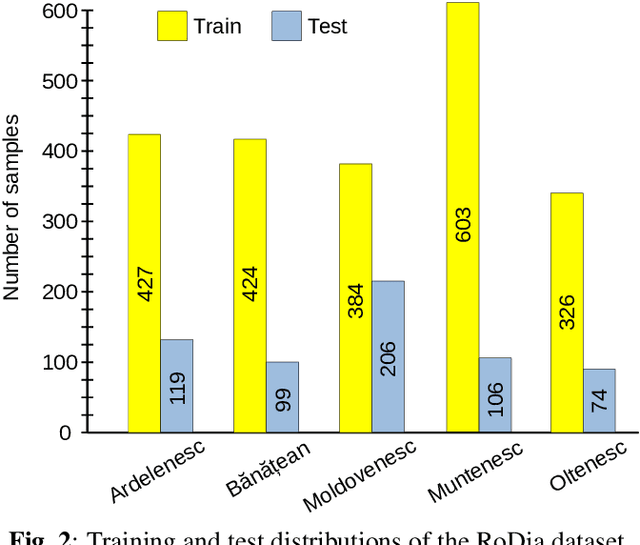

Dialect identification is a critical task in speech processing and language technology, enhancing various applications such as speech recognition, speaker verification, and many others. While most research studies have been dedicated to dialect identification in widely spoken languages, limited attention has been given to dialect identification in low-resource languages, such as Romanian. To address this research gap, we introduce RoDia, the first dataset for Romanian dialect identification from speech. The RoDia dataset includes a varied compilation of speech samples from five distinct regions of Romania, covering both urban and rural environments, totaling 2 hours of manually annotated speech data. Along with our dataset, we introduce a set of competitive models to be used as baselines for future research. The top scoring model achieves a macro F1 score of 59.83% and a micro F1 score of 62.08%, indicating that the task is challenging. We thus believe that RoDia is a valuable resource that will stimulate research aiming to address the challenges of Romanian dialect identification. We publicly release our dataset and code at https://github.com/codrut2/RoDia.
The Multimodal Information Based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
Sep 15, 2023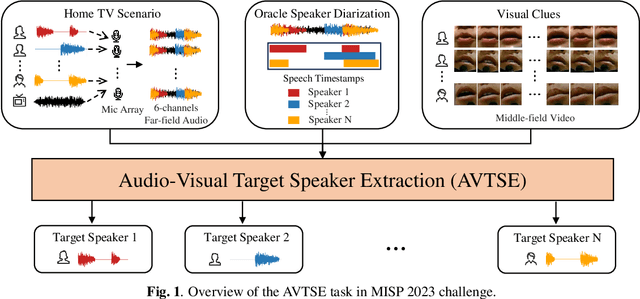
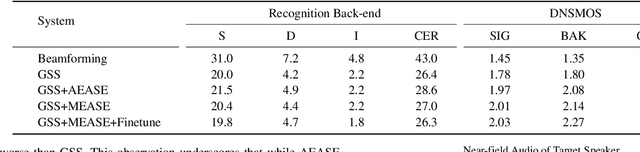
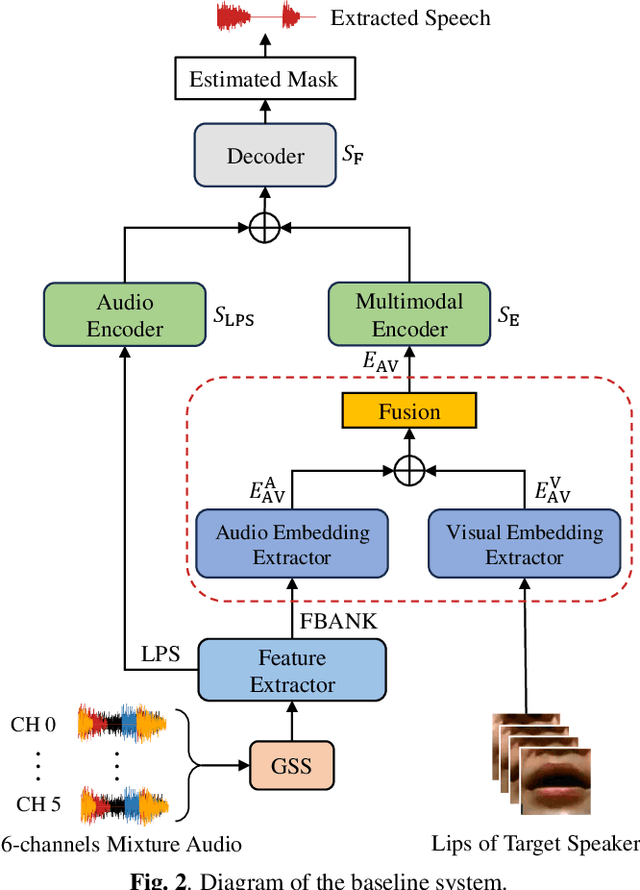
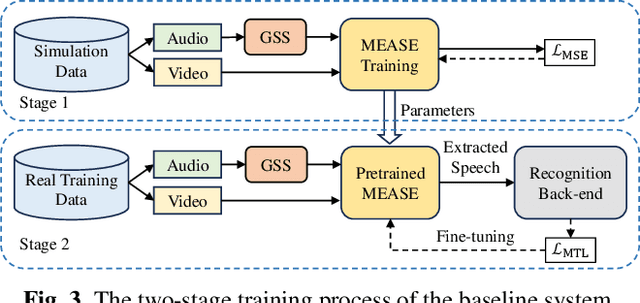
Previous Multimodal Information based Speech Processing (MISP) challenges mainly focused on audio-visual speech recognition (AVSR) with commendable success. However, the most advanced back-end recognition systems often hit performance limits due to the complex acoustic environments. This has prompted a shift in focus towards the Audio-Visual Target Speaker Extraction (AVTSE) task for the MISP 2023 challenge in ICASSP 2024 Signal Processing Grand Challenges. Unlike existing audio-visual speech enhance-ment challenges primarily focused on simulation data, the MISP 2023 challenge uniquely explores how front-end speech processing, combined with visual clues, impacts back-end tasks in real-world scenarios. This pioneering effort aims to set the first benchmark for the AVTSE task, offering fresh insights into enhancing the ac-curacy of back-end speech recognition systems through AVTSE in challenging and real acoustic environments. This paper delivers a thorough overview of the task setting, dataset, and baseline system of the MISP 2023 challenge. It also includes an in-depth analysis of the challenges participants may encounter. The experimental results highlight the demanding nature of this task, and we look forward to the innovative solutions participants will bring forward.
Reduce, Reuse, Recycle: Is Perturbed Data better than Other Language augmentation for Low Resource Self-Supervised Speech Models
Sep 22, 2023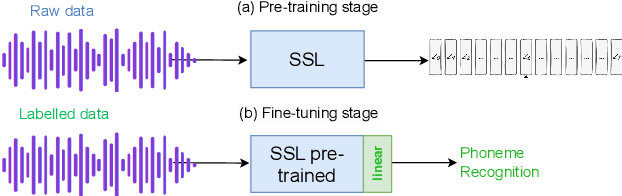
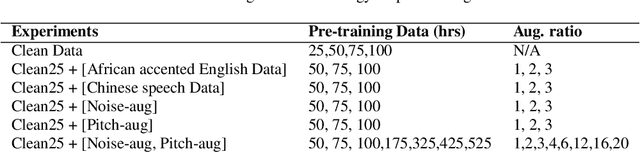
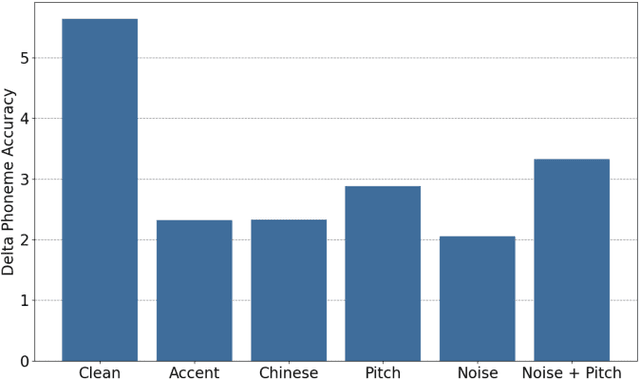
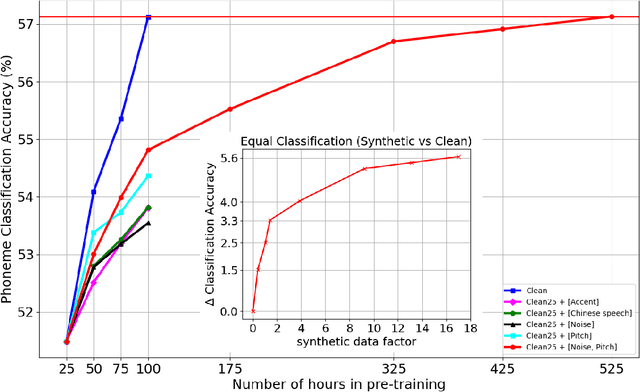
Self-supervised representation learning (SSRL) has improved the performance on downstream phoneme recognition versus supervised models. Training SSRL models requires a large amount of pre-training data and this poses a challenge for low resource languages. A common approach is transferring knowledge from other languages. Instead, we propose to use audio augmentation to pre-train SSRL models in a low resource condition and evaluate phoneme recognition as downstream task. We performed a systematic comparison of augmentation techniques, namely: pitch variation, noise addition, accented target-language speech and other language speech. We found combined augmentations (noise/pitch) was the best augmentation strategy outperforming accent and language knowledge transfer. We compared the performance with various quantities and types of pre-training data. We examined the scaling factor of augmented data to achieve equivalent performance to models pre-trained with target domain speech. Our findings suggest that for resource constrained languages, in-domain synthetic augmentation can outperform knowledge transfer from accented or other language speech.
Dynamic-SUPERB: Towards A Dynamic, Collaborative, and Comprehensive Instruction-Tuning Benchmark for Speech
Sep 18, 2023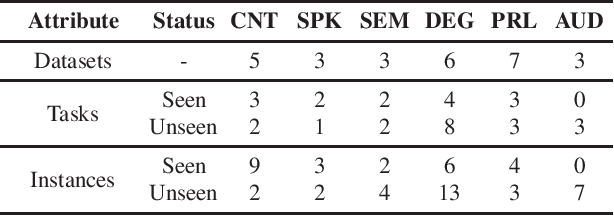
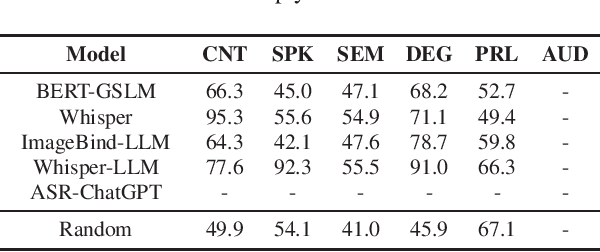
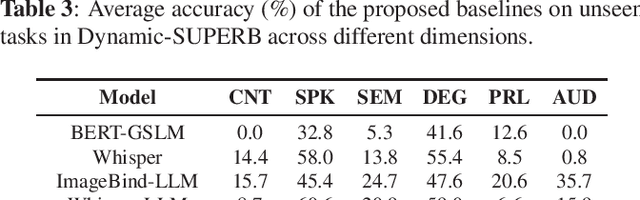
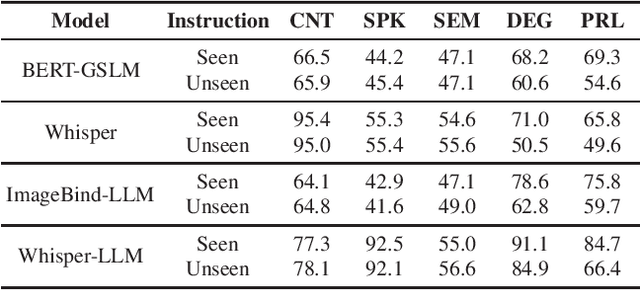
Text language models have shown remarkable zero-shot capability in generalizing to unseen tasks when provided with well-formulated instructions. However, existing studies in speech processing primarily focus on limited or specific tasks. Moreover, the lack of standardized benchmarks hinders a fair comparison across different approaches. Thus, we present Dynamic-SUPERB, a benchmark designed for building universal speech models capable of leveraging instruction tuning to perform multiple tasks in a zero-shot fashion. To achieve comprehensive coverage of diverse speech tasks and harness instruction tuning, we invite the community to collaborate and contribute, facilitating the dynamic growth of the benchmark. To initiate, Dynamic-SUPERB features 55 evaluation instances by combining 33 tasks and 22 datasets. This spans a broad spectrum of dimensions, providing a comprehensive platform for evaluation. Additionally, we propose several approaches to establish benchmark baselines. These include the utilization of speech models, text language models, and the multimodal encoder. Evaluation results indicate that while these baselines perform reasonably on seen tasks, they struggle with unseen ones. We also conducted an ablation study to assess the robustness and seek improvements in the performance. We release all materials to the public and welcome researchers to collaborate on the project, advancing technologies in the field together.