 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Ensembling Multilingual Pre-Trained Models for Predicting Multi-Label Regression Emotion Share from Speech
Sep 20, 2023


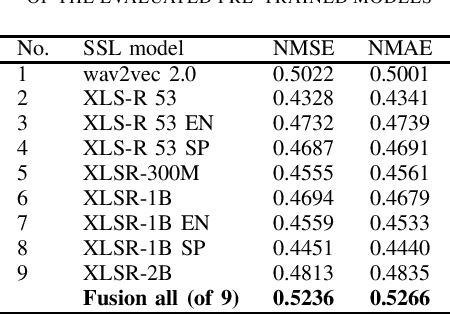
Speech emotion recognition has evolved from research to practical applications. Previous studies of emotion recognition from speech have focused on developing models on certain datasets like IEMOCAP. The lack of data in the domain of emotion modeling emerges as a challenge to evaluate models in the other dataset, as well as to evaluate speech emotion recognition models that work in a multilingual setting. This paper proposes an ensemble learning to fuse results of pre-trained models for emotion share recognition from speech. The models were chosen to accommodate multilingual data from English and Spanish. The results show that ensemble learning can improve the performance of the baseline model with a single model and the previous best model from the late fusion. The performance is measured using the Spearman rank correlation coefficient since the task is a regression problem with ranking values. A Spearman rank correlation coefficient of 0.537 is reported for the test set, while for the development set, the score is 0.524. These scores are higher than the previous study of a fusion method from monolingual data, which achieved scores of 0.476 for the test and 0.470 for the development.
Explaining Speech Classification Models via Word-Level Audio Segments and Paralinguistic Features
Sep 14, 2023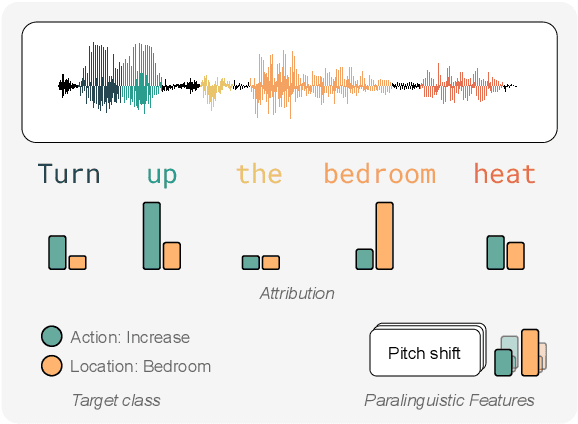

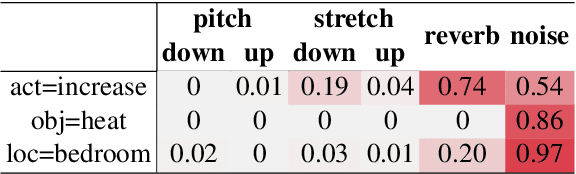
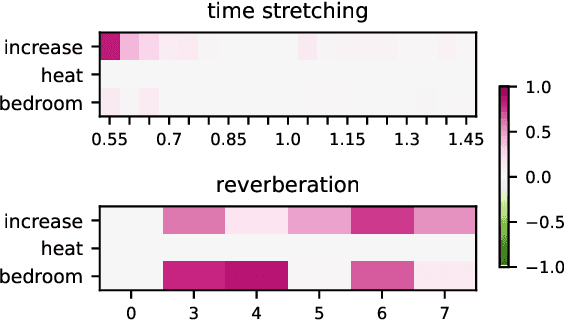
Recent advances in eXplainable AI (XAI) have provided new insights into how models for vision, language, and tabular data operate. However, few approaches exist for understanding speech models. Existing work focuses on a few spoken language understanding (SLU) tasks, and explanations are difficult to interpret for most users. We introduce a new approach to explain speech classification models. We generate easy-to-interpret explanations via input perturbation on two information levels. 1) Word-level explanations reveal how each word-related audio segment impacts the outcome. 2) Paralinguistic features (e.g., prosody and background noise) answer the counterfactual: ``What would the model prediction be if we edited the audio signal in this way?'' We validate our approach by explaining two state-of-the-art SLU models on two speech classification tasks in English and Italian. Our findings demonstrate that the explanations are faithful to the model's inner workings and plausible to humans. Our method and findings pave the way for future research on interpreting speech models.
Deep Complex U-Net with Conformer for Audio-Visual Speech Enhancement
Sep 20, 2023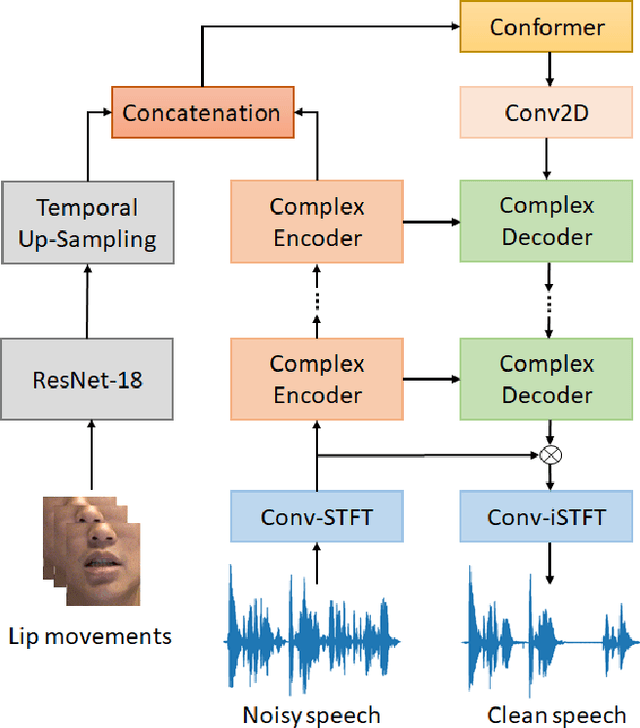
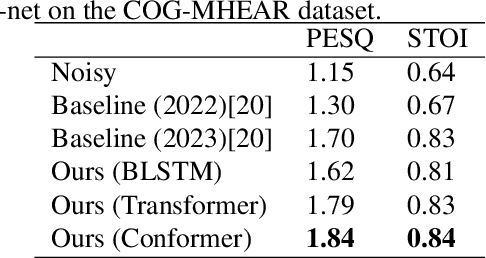

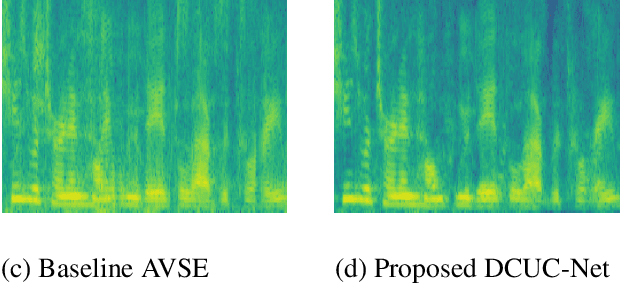
Recent studies have increasingly acknowledged the advantages of incorporating visual data into speech enhancement (SE) systems. In this paper, we introduce a novel audio-visual SE approach, termed DCUC-Net (deep complex U-Net with conformer network). The proposed DCUC-Net leverages complex domain features and a stack of conformer blocks. The encoder and decoder of DCUC-Net are designed using a complex U-Net-based framework. The audio and visual signals are processed using a complex encoder and a ResNet-18 model, respectively. These processed signals are then fused using the conformer blocks and transformed into enhanced speech waveforms via a complex decoder. The conformer blocks consist of a combination of self-attention mechanisms and convolutional operations, enabling DCUC-Net to effectively capture both global and local audio-visual dependencies. Our experimental results demonstrate the effectiveness of DCUC-Net, as it outperforms the baseline model from the COG-MHEAR AVSE Challenge 2023 by a notable margin of 0.14 in terms of PESQ. Additionally, the proposed DCUC-Net performs comparably to a state-of-the-art model and outperforms all other compared models on the Taiwan Mandarin speech with video (TMSV) dataset.
Towards Practical and Efficient Image-to-Speech Captioning with Vision-Language Pre-training and Multi-modal Tokens
Sep 15, 2023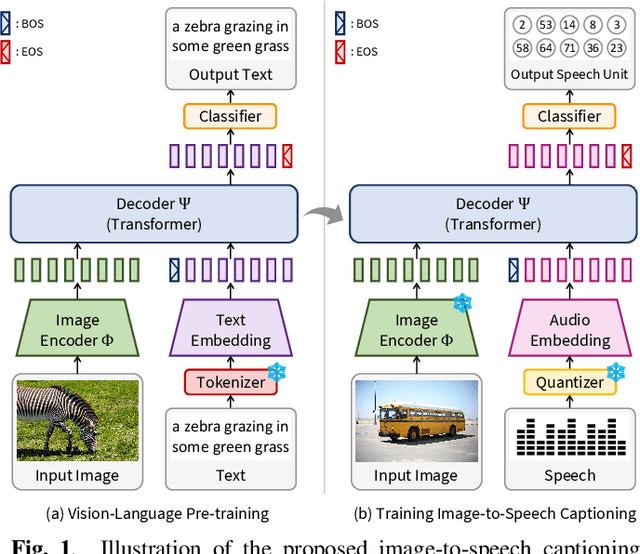

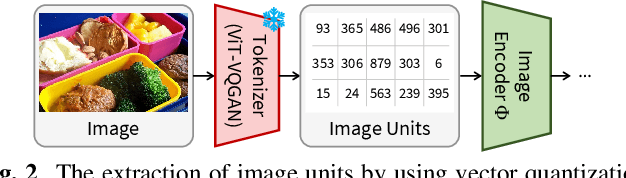

In this paper, we propose methods to build a powerful and efficient Image-to-Speech captioning (Im2Sp) model. To this end, we start with importing the rich knowledge related to image comprehension and language modeling from a large-scale pre-trained vision-language model into Im2Sp. We set the output of the proposed Im2Sp as discretized speech units, i.e., the quantized speech features of a self-supervised speech model. The speech units mainly contain linguistic information while suppressing other characteristics of speech. This allows us to incorporate the language modeling capability of the pre-trained vision-language model into the spoken language modeling of Im2Sp. With the vision-language pre-training strategy, we set new state-of-the-art Im2Sp performances on two widely used benchmark databases, COCO and Flickr8k. Then, we further improve the efficiency of the Im2Sp model. Similar to the speech unit case, we convert the original image into image units, which are derived through vector quantization of the raw image. With these image units, we can drastically reduce the required data storage for saving image data to just 0.8% when compared to the original image data in terms of bits. Demo page: https://ms-dot-k.github.io/Image-to-Speech-Captioning.
TokenSplit: Using Discrete Speech Representations for Direct, Refined, and Transcript-Conditioned Speech Separation and Recognition
Aug 21, 2023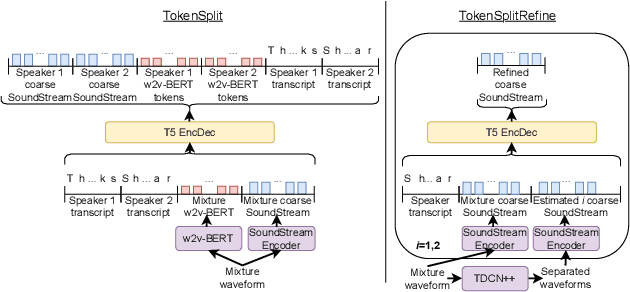
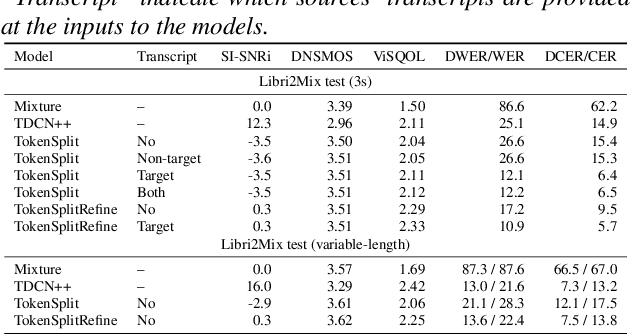
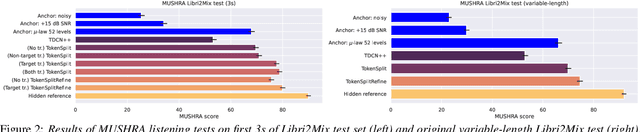
We present TokenSplit, a speech separation model that acts on discrete token sequences. The model is trained on multiple tasks simultaneously: separate and transcribe each speech source, and generate speech from text. The model operates on transcripts and audio token sequences and achieves multiple tasks through masking of inputs. The model is a sequence-to-sequence encoder-decoder model that uses the Transformer architecture. We also present a "refinement" version of the model that predicts enhanced audio tokens from the audio tokens of speech separated by a conventional separation model. Using both objective metrics and subjective MUSHRA listening tests, we show that our model achieves excellent performance in terms of separation, both with or without transcript conditioning. We also measure the automatic speech recognition (ASR) performance and provide audio samples of speech synthesis to demonstrate the additional utility of our model.
Evaluating Self-Supervised Speech Representations for Indigenous American Languages
Oct 05, 2023The application of self-supervision to speech representation learning has garnered significant interest in recent years, due to its scalability to large amounts of unlabeled data. However, much progress, both in terms of pre-training and downstream evaluation, has remained concentrated in monolingual models that only consider English. Few models consider other languages, and even fewer consider indigenous ones. In our submission to the New Language Track of the ASRU 2023 ML-SUPERB Challenge, we present an ASR corpus for Quechua, an indigenous South American Language. We benchmark the efficacy of large SSL models on Quechua, along with 6 other indigenous languages such as Guarani and Bribri, on low-resource ASR. Our results show surprisingly strong performance by state-of-the-art SSL models, showing the potential generalizability of large-scale models to real-world data.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 21, 2023Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
Folding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition
Sep 21, 2023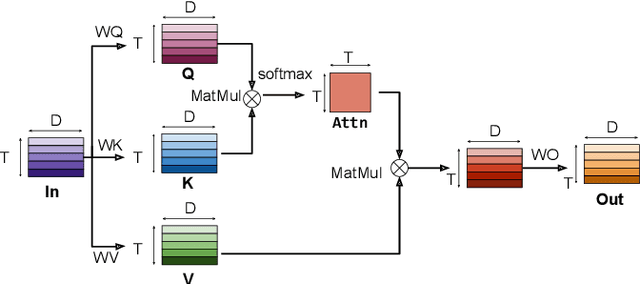
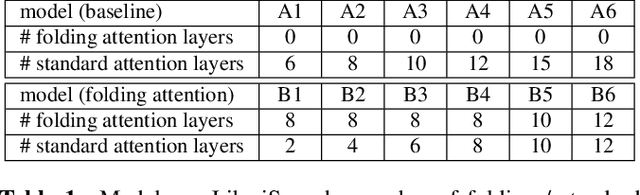
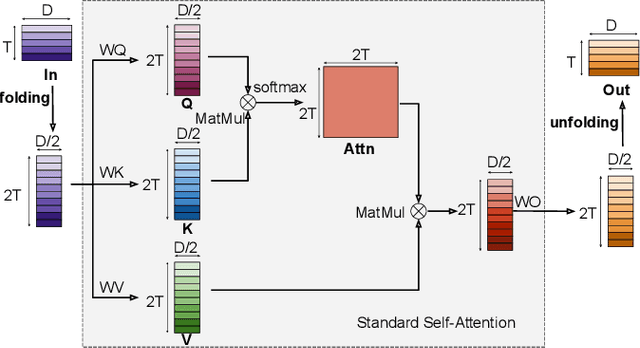
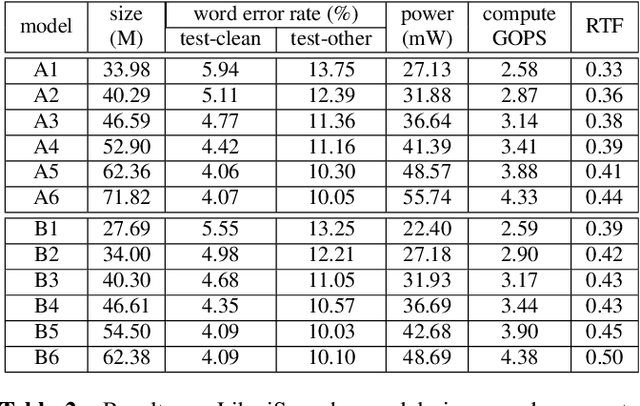
Transformer-based models excel in speech recognition. Existing efforts to optimize Transformer inference, typically for long-context applications, center on simplifying attention score calculations. However, streaming speech recognition models usually process a limited number of tokens each time, making attention score calculation less of a bottleneck. Instead, the bottleneck lies in the linear projection layers of multi-head attention and feedforward networks, constituting a substantial portion of the model size and contributing significantly to computation, memory, and power usage. To address this bottleneck, we propose folding attention, a technique targeting these linear layers, significantly reducing model size and improving memory and power efficiency. Experiments on on-device Transformer-based streaming speech recognition models show that folding attention reduces model size (and corresponding memory consumption) by up to 24% and power consumption by up to 23%, all without compromising model accuracy or computation overhead.
Improving Stability in Simultaneous Speech Translation: A Revision-Controllable Decoding Approach
Oct 06, 2023Simultaneous Speech-to-Text translation serves a critical role in real-time crosslingual communication. Despite the advancements in recent years, challenges remain in achieving stability in the translation process, a concern primarily manifested in the flickering of partial results. In this paper, we propose a novel revision-controllable method designed to address this issue. Our method introduces an allowed revision window within the beam search pruning process to screen out candidate translations likely to cause extensive revisions, leading to a substantial reduction in flickering and, crucially, providing the capability to completely eliminate flickering. The experiments demonstrate the proposed method can significantly improve the decoding stability without compromising substantially on the translation quality.
Incremental Blockwise Beam Search for Simultaneous Speech Translation with Controllable Quality-Latency Tradeoff
Sep 20, 2023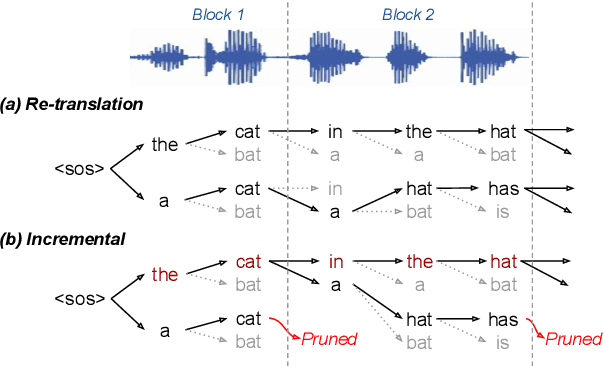
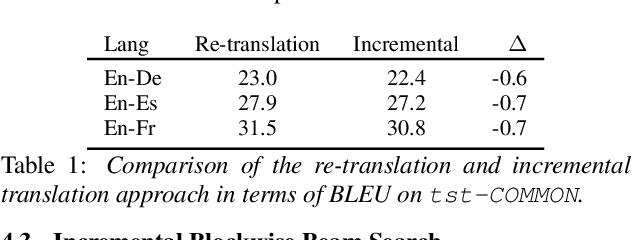
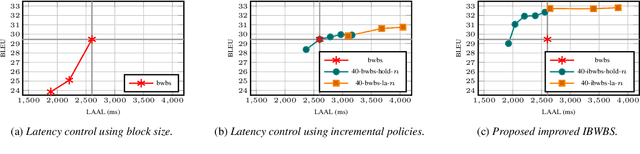
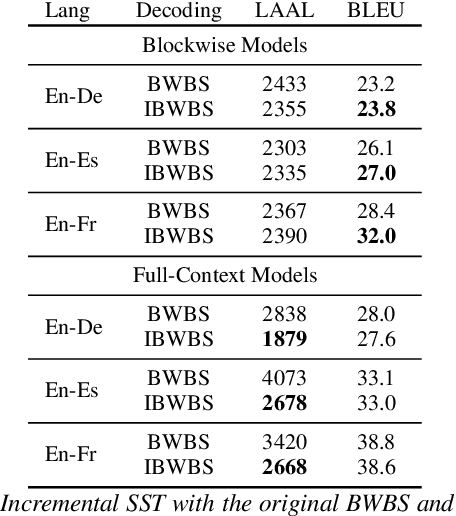
Blockwise self-attentional encoder models have recently emerged as one promising end-to-end approach to simultaneous speech translation. These models employ a blockwise beam search with hypothesis reliability scoring to determine when to wait for more input speech before translating further. However, this method maintains multiple hypotheses until the entire speech input is consumed -- this scheme cannot directly show a single \textit{incremental} translation to users. Further, this method lacks mechanisms for \textit{controlling} the quality vs. latency tradeoff. We propose a modified incremental blockwise beam search incorporating local agreement or hold-$n$ policies for quality-latency control. We apply our framework to models trained for online or offline translation and demonstrate that both types can be effectively used in online mode. Experimental results on MuST-C show 0.6-3.6 BLEU improvement without changing latency or 0.8-1.4 s latency improvement without changing quality.
* Accepted at INTERSPEECH 2023