 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
LLaSM: Large Language and Speech Model
Aug 30, 2023
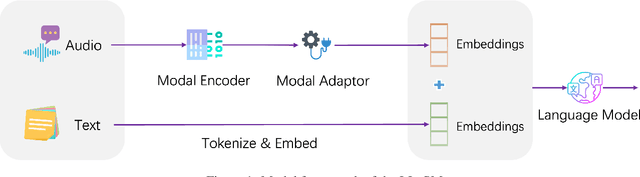
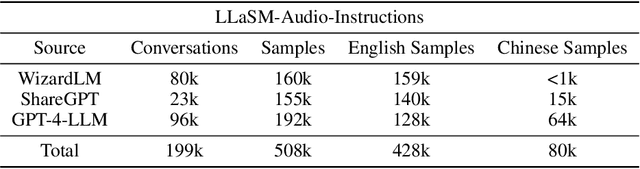

Multi-modal large language models have garnered significant interest recently. Though, most of the works focus on vision-language multi-modal models providing strong capabilities in following vision-and-language instructions. However, we claim that speech is also an important modality through which humans interact with the world. Hence, it is crucial for a general-purpose assistant to be able to follow multi-modal speech-and-language instructions. In this work, we propose Large Language and Speech Model (LLaSM). LLaSM is an end-to-end trained large multi-modal speech-language model with cross-modal conversational abilities, capable of following speech-and-language instructions. Our early experiments show that LLaSM demonstrates a more convenient and natural way for humans to interact with artificial intelligence. Specifically, we also release a large Speech Instruction Following dataset LLaSM-Audio-Instructions. Code and demo are available at https://github.com/LinkSoul-AI/LLaSM and https://huggingface.co/spaces/LinkSoul/LLaSM. The LLaSM-Audio-Instructions dataset is available at https://huggingface.co/datasets/LinkSoul/LLaSM-Audio-Instructions.
Hierarchical attention interpretation: an interpretable speech-level transformer for bi-modal depression detection
Sep 23, 2023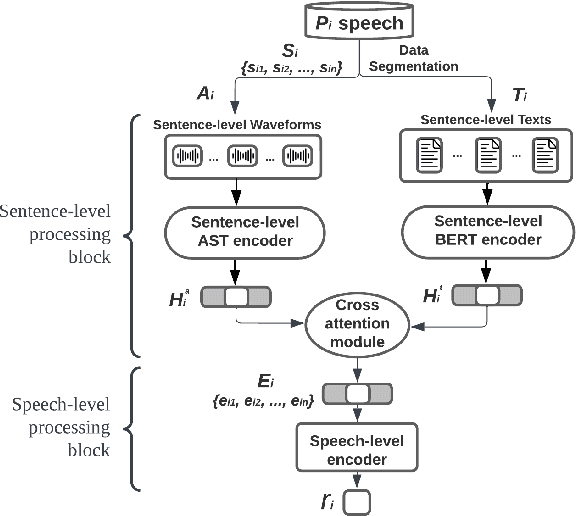

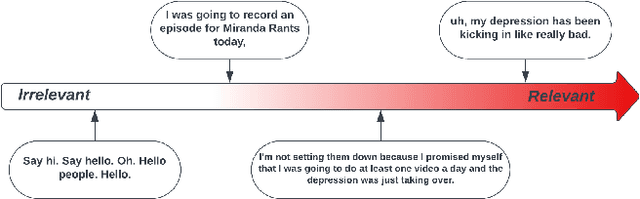

Depression is a common mental disorder. Automatic depression detection tools using speech, enabled by machine learning, help early screening of depression. This paper addresses two limitations that may hinder the clinical implementations of such tools: noise resulting from segment-level labelling and a lack of model interpretability. We propose a bi-modal speech-level transformer to avoid segment-level labelling and introduce a hierarchical interpretation approach to provide both speech-level and sentence-level interpretations, based on gradient-weighted attention maps derived from all attention layers to track interactions between input features. We show that the proposed model outperforms a model that learns at a segment level ($p$=0.854, $r$=0.947, $F1$=0.947 compared to $p$=0.732, $r$=0.808, $F1$=0.768). For model interpretation, using one true positive sample, we show which sentences within a given speech are most relevant to depression detection; and which text tokens and Mel-spectrogram regions within these sentences are most relevant to depression detection. These interpretations allow clinicians to verify the validity of predictions made by depression detection tools, promoting their clinical implementations.
Discriminative Speech Recognition Rescoring with Pre-trained Language Models
Oct 10, 2023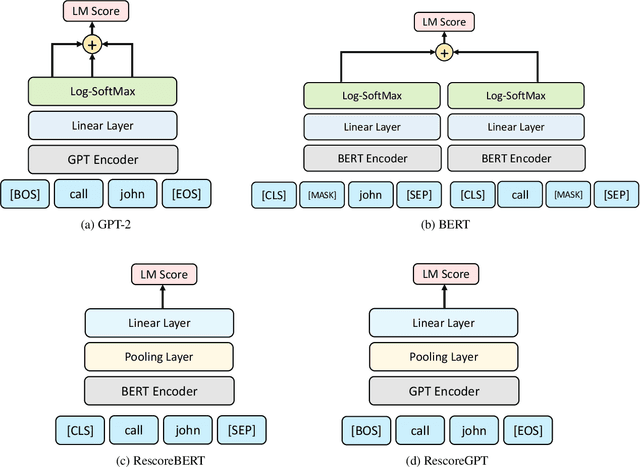
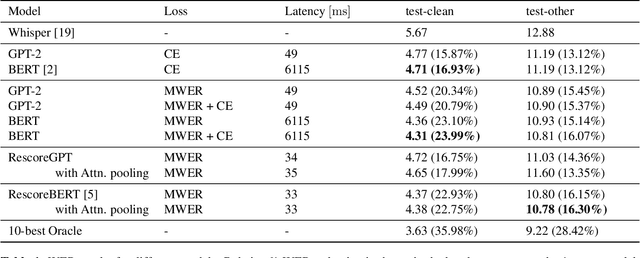
Second pass rescoring is a critical component of competitive automatic speech recognition (ASR) systems. Large language models have demonstrated their ability in using pre-trained information for better rescoring of ASR hypothesis. Discriminative training, directly optimizing the minimum word-error-rate (MWER) criterion typically improves rescoring. In this study, we propose and explore several discriminative fine-tuning schemes for pre-trained LMs. We propose two architectures based on different pooling strategies of output embeddings and compare with probability based MWER. We conduct detailed comparisons between pre-trained causal and bidirectional LMs in discriminative settings. Experiments on LibriSpeech demonstrate that all MWER training schemes are beneficial, giving additional gains upto 8.5\% WER. Proposed pooling variants achieve lower latency while retaining most improvements. Finally, our study concludes that bidirectionality is better utilized with discriminative training.
How To Build Competitive Multi-gender Speech Translation Models For Controlling Speaker Gender Translation
Oct 23, 2023When translating from notional gender languages (e.g., English) into grammatical gender languages (e.g., Italian), the generated translation requires explicit gender assignments for various words, including those referring to the speaker. When the source sentence does not convey the speaker's gender, speech translation (ST) models either rely on the possibly-misleading vocal traits of the speaker or default to the masculine gender, the most frequent in existing training corpora. To avoid such biased and not inclusive behaviors, the gender assignment of speaker-related expressions should be guided by externally-provided metadata about the speaker's gender. While previous work has shown that the most effective solution is represented by separate, dedicated gender-specific models, the goal of this paper is to achieve the same results by integrating the speaker's gender metadata into a single "multi-gender" neural ST model, easier to maintain. Our experiments demonstrate that a single multi-gender model outperforms gender-specialized ones when trained from scratch (with gender accuracy gains up to 12.9 for feminine forms), while fine-tuning from existing ST models does not lead to competitive results.
Churn Prediction via Multimodal Fusion Learning:Integrating Customer Financial Literacy, Voice, and Behavioral Data
Dec 03, 2023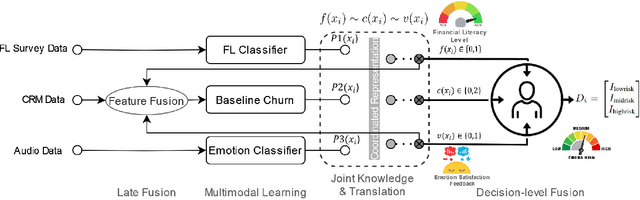
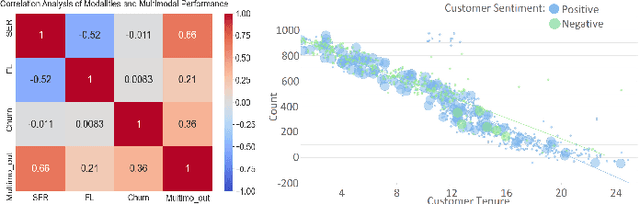
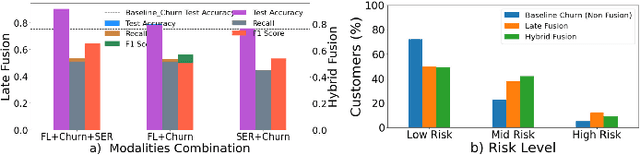
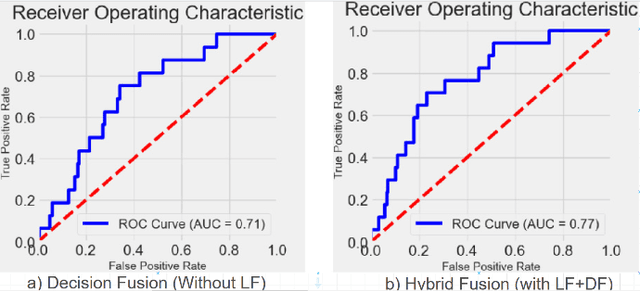
In todays competitive landscape, businesses grapple with customer retention. Churn prediction models, although beneficial, often lack accuracy due to the reliance on a single data source. The intricate nature of human behavior and high dimensional customer data further complicate these efforts. To address these concerns, this paper proposes a multimodal fusion learning model for identifying customer churn risk levels in financial service providers. Our multimodal approach integrates customer sentiments financial literacy (FL) level, and financial behavioral data, enabling more accurate and bias-free churn prediction models. The proposed FL model utilizes a SMOGN COREG supervised model to gauge customer FL levels from their financial data. The baseline churn model applies an ensemble artificial neural network and oversampling techniques to predict churn propensity in high-dimensional financial data. We also incorporate a speech emotion recognition model employing a pre-trained CNN-VGG16 to recognize customer emotions based on pitch, energy, and tone. To integrate these diverse features while retaining unique insights, we introduced late and hybrid fusion techniques that complementary boost coordinated multimodal co learning. Robust metrics were utilized to evaluate the proposed multimodal fusion model and hence the approach validity, including mean average precision and macro-averaged F1 score. Our novel approach demonstrates a marked improvement in churn prediction, achieving a test accuracy of 91.2%, a Mean Average Precision (MAP) score of 66, and a Macro-Averaged F1 score of 54 through the proposed hybrid fusion learning technique compared with late fusion and baseline models. Furthermore, the analysis demonstrates a positive correlation between negative emotions, low FL scores, and high-risk customers.
Quantifying the redundancy between prosody and text
Nov 28, 2023Prosody -- the suprasegmental component of speech, including pitch, loudness, and tempo -- carries critical aspects of meaning. However, the relationship between the information conveyed by prosody vs. by the words themselves remains poorly understood. We use large language models (LLMs) to estimate how much information is redundant between prosody and the words themselves. Using a large spoken corpus of English audiobooks, we extract prosodic features aligned to individual words and test how well they can be predicted from LLM embeddings, compared to non-contextual word embeddings. We find a high degree of redundancy between the information carried by the words and prosodic information across several prosodic features, including intensity, duration, pauses, and pitch contours. Furthermore, a word's prosodic information is redundant with both the word itself and the context preceding as well as following it. Still, we observe that prosodic features can not be fully predicted from text, suggesting that prosody carries information above and beyond the words. Along with this paper, we release a general-purpose data processing pipeline for quantifying the relationship between linguistic information and extra-linguistic features.
VoxArabica: A Robust Dialect-Aware Arabic Speech Recognition System
Oct 17, 2023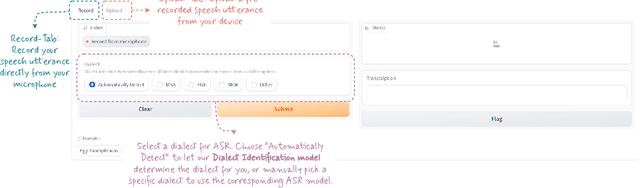

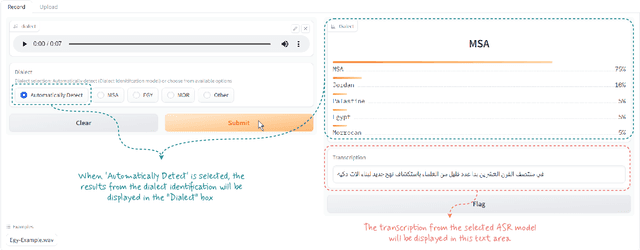
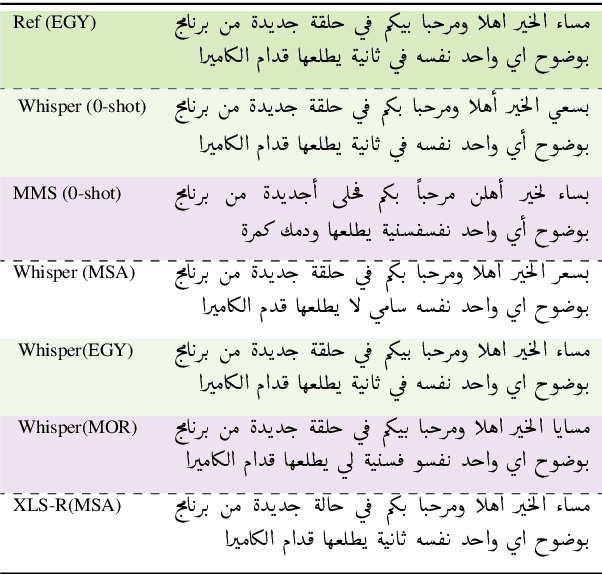
Arabic is a complex language with many varieties and dialects spoken by over 450 millions all around the world. Due to the linguistic diversity and variations, it is challenging to build a robust and generalized ASR system for Arabic. In this work, we address this gap by developing and demoing a system, dubbed VoxArabica, for dialect identification (DID) as well as automatic speech recognition (ASR) of Arabic. We train a wide range of models such as HuBERT (DID), Whisper, and XLS-R (ASR) in a supervised setting for Arabic DID and ASR tasks. Our DID models are trained to identify 17 different dialects in addition to MSA. We finetune our ASR models on MSA, Egyptian, Moroccan, and mixed data. Additionally, for the remaining dialects in ASR, we provide the option to choose various models such as Whisper and MMS in a zero-shot setting. We integrate these models into a single web interface with diverse features such as audio recording, file upload, model selection, and the option to raise flags for incorrect outputs. Overall, we believe VoxArabica will be useful for a wide range of audiences concerned with Arabic research. Our system is currently running at https://cdce-206-12-100-168.ngrok.io/.
Efficient Multi-Channel Speech Enhancement with Spherical Harmonics Injection for Directional Encoding
Sep 19, 2023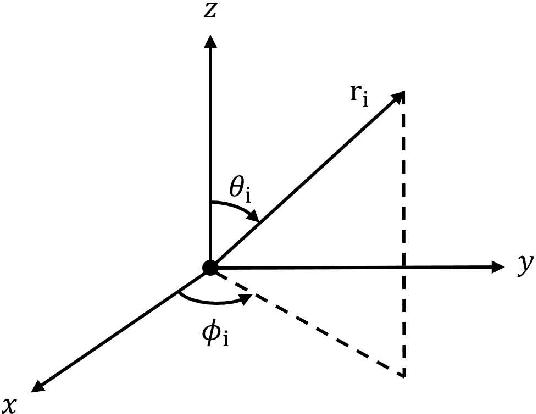

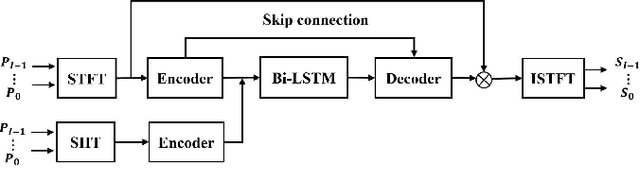

Multi-channel speech enhancement extracts speech using multiple microphones that capture spatial cues. Effectively utilizing directional information is key for multi-channel enhancement. Deep learning shows great potential on multi-channel speech enhancement and often takes short-time Fourier Transform (STFT) as inputs directly. To fully leverage the spatial information, we introduce a method using spherical harmonics transform (SHT) coefficients as auxiliary model inputs. These coefficients concisely represent spatial distributions. Specifically, our model has two encoders, one for the STFT and another for the SHT. By fusing both encoders in the decoder to estimate the enhanced STFT, we effectively incorporate spatial context. Evaluations on TIMIT under varying noise and reverberation show our model outperforms established benchmarks. Remarkably, this is achieved with fewer computations and parameters. By leveraging spherical harmonics to incorporate directional cues, our model efficiently improves the performance of the multi-channel speech enhancement.
GRASS: Unified Generation Model for Speech Semantic Understanding
Sep 06, 2023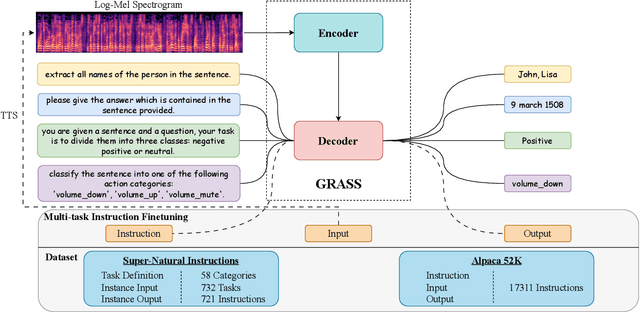
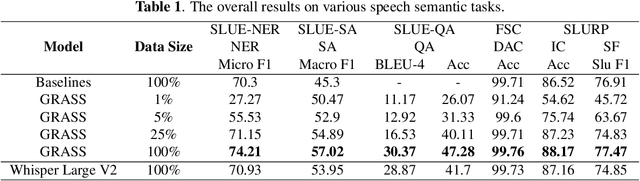

This paper explores the instruction fine-tuning technique for speech semantic understanding by introducing a unified end-to-end (E2E) framework that generates semantic labels conditioned on a task-related prompt for audio data. We pre-train the model using large and diverse data, where instruction-speech pairs are constructed via a text-to-speech (TTS) system. Extensive experiments demonstrate that our proposed model significantly outperforms state-of-the-art (SOTA) models after fine-tuning downstream tasks. Furthermore, the proposed model achieves competitive performance in zero-shot and few-shot scenarios. To facilitate future work on instruction fine-tuning for speech-to-semantic tasks, we release our instruction dataset and code.
Foundation Model Assisted Automatic Speech Emotion Recognition: Transcribing, Annotating, and Augmenting
Sep 15, 2023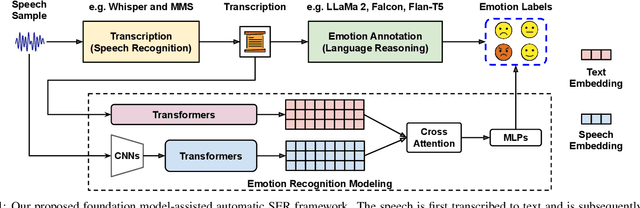
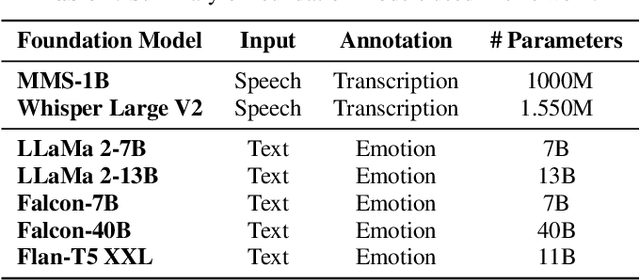
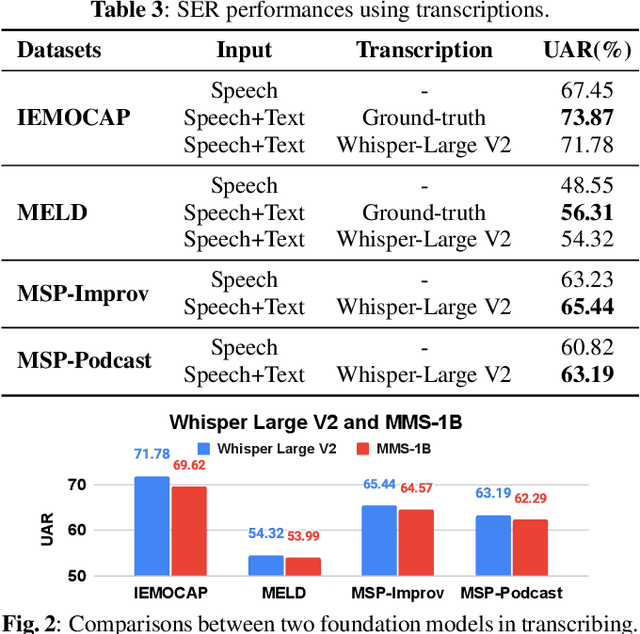
Significant advances are being made in speech emotion recognition (SER) using deep learning models. Nonetheless, training SER systems remains challenging, requiring both time and costly resources. Like many other machine learning tasks, acquiring datasets for SER requires substantial data annotation efforts, including transcription and labeling. These annotation processes present challenges when attempting to scale up conventional SER systems. Recent developments in foundational models have had a tremendous impact, giving rise to applications such as ChatGPT. These models have enhanced human-computer interactions including bringing unique possibilities for streamlining data collection in fields like SER. In this research, we explore the use of foundational models to assist in automating SER from transcription and annotation to augmentation. Our study demonstrates that these models can generate transcriptions to enhance the performance of SER systems that rely solely on speech data. Furthermore, we note that annotating emotions from transcribed speech remains a challenging task. However, combining outputs from multiple LLMs enhances the quality of annotations. Lastly, our findings suggest the feasibility of augmenting existing speech emotion datasets by annotating unlabeled speech samples.