 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Spatial Diarization for Meeting Transcription with Ad-Hoc Acoustic Sensor Networks
Nov 27, 2023
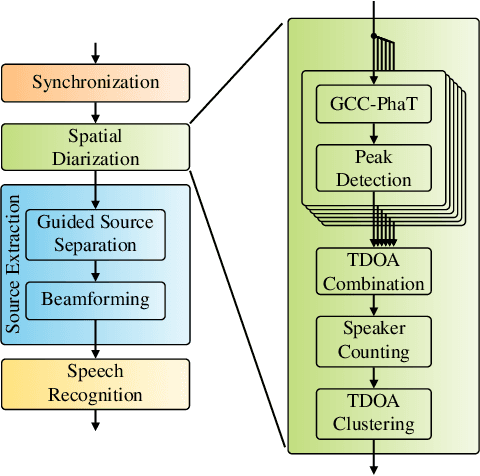
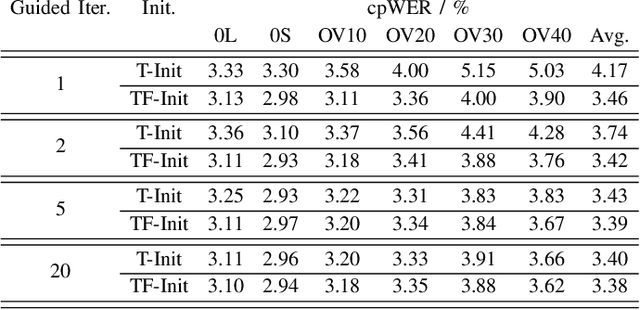
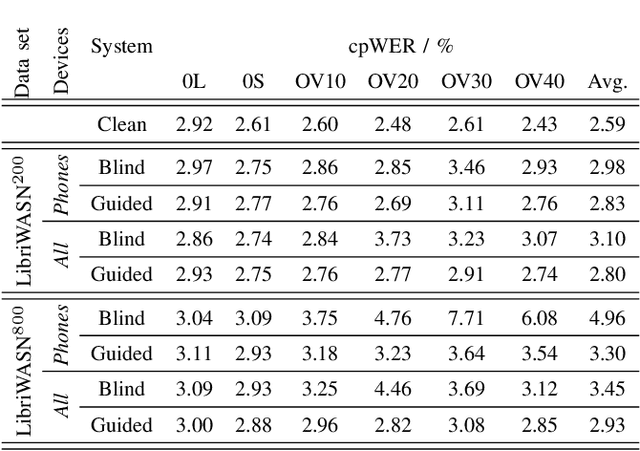
We propose a diarization system, that estimates "who spoke when" based on spatial information, to be used as a front-end of a meeting transcription system running on the signals gathered from an acoustic sensor network (ASN). Although the spatial distribution of the microphones is advantageous, exploiting the spatial diversity for diarization and signal enhancement is challenging, because the microphones' positions are typically unknown, and the recorded signals are initially unsynchronized in general. Here, we approach these issues by first blindly synchronizing the signals and then estimating time differences of arrival (TDOAs). The TDOA information is exploited to estimate the speakers' activity, even in the presence of multiple speakers being simultaneously active. This speaker activity information serves as a guide for a spatial mixture model, on which basis the individual speaker's signals are extracted via beamforming. Finally, the extracted signals are forwarded to a speech recognizer. Additionally, a novel initialization scheme for spatial mixture models based on the TDOA estimates is proposed. Experiments conducted on real recordings from the LibriWASN data set have shown that our proposed system is advantageous compared to a system using a spatial mixture model, which does not make use of external diarization information.
AV2Wav: Diffusion-Based Re-synthesis from Continuous Self-supervised Features for Audio-Visual Speech Enhancement
Sep 14, 2023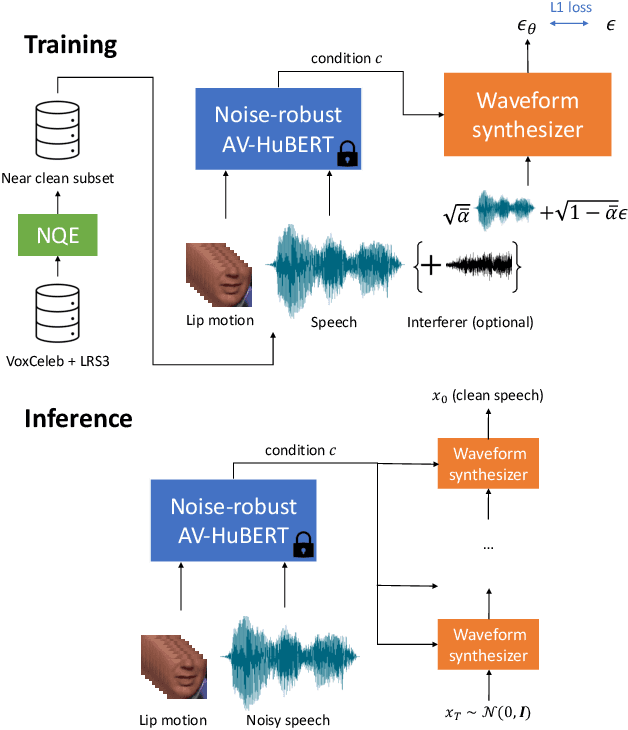
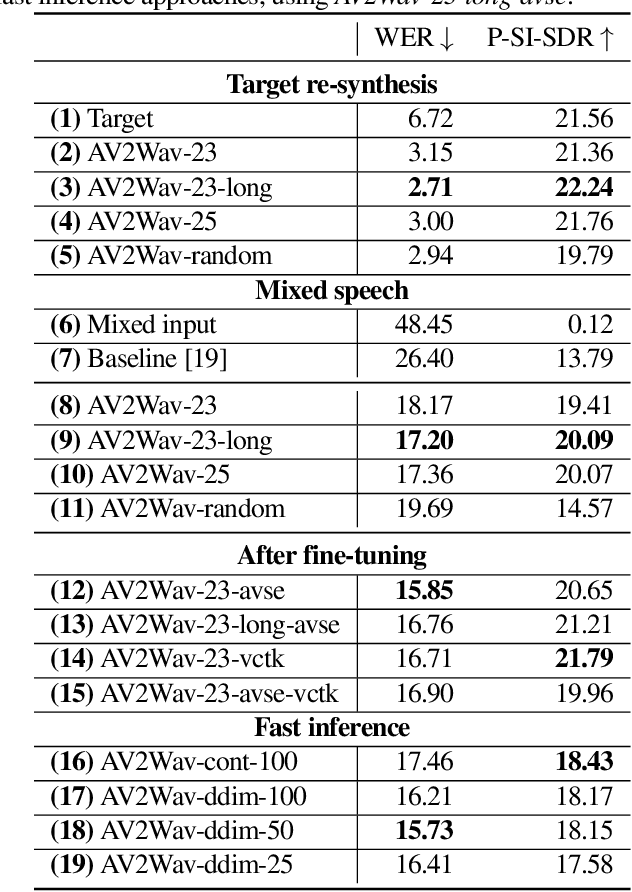

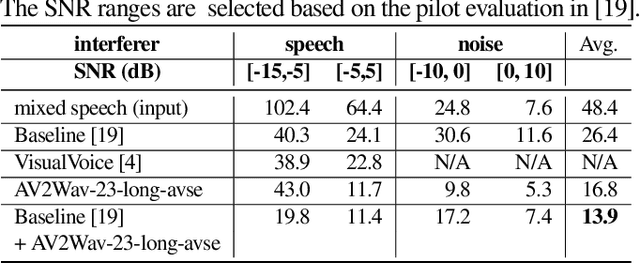
Speech enhancement systems are typically trained using pairs of clean and noisy speech. In audio-visual speech enhancement (AVSE), there is not as much ground-truth clean data available; most audio-visual datasets are collected in real-world environments with background noise and reverberation, hampering the development of AVSE. In this work, we introduce AV2Wav, a resynthesis-based audio-visual speech enhancement approach that can generate clean speech despite the challenges of real-world training data. We obtain a subset of nearly clean speech from an audio-visual corpus using a neural quality estimator, and then train a diffusion model on this subset to generate waveforms conditioned on continuous speech representations from AV-HuBERT with noise-robust training. We use continuous rather than discrete representations to retain prosody and speaker information. With this vocoding task alone, the model can perform speech enhancement better than a masking-based baseline. We further fine-tune the diffusion model on clean/noisy utterance pairs to improve the performance. Our approach outperforms a masking-based baseline in terms of both automatic metrics and a human listening test and is close in quality to the target speech in the listening test. Audio samples can be found at https://home.ttic.edu/~jcchou/demo/avse/avse_demo.html.
A-JEPA: Joint-Embedding Predictive Architecture Can Listen
Nov 28, 2023This paper presents that the masked-modeling principle driving the success of large foundational vision models can be effectively applied to audio by making predictions in a latent space. We introduce Audio-based Joint-Embedding Predictive Architecture (A-JEPA), a simple extension method for self-supervised learning from the audio spectrum. Following the design of I-JEPA, our A-JEPA encodes visible audio spectrogram patches with a curriculum masking strategy via context encoder, and predicts the representations of regions sampled at well-designed locations. The target representations of those regions are extracted by the exponential moving average of context encoder, \emph{i.e.}, target encoder, on the whole spectrogram. We find it beneficial to transfer random block masking into time-frequency aware masking in a curriculum manner, considering the complexity of highly correlated in local time and frequency in audio spectrograms. To enhance contextual semantic understanding and robustness, we fine-tune the encoder with a regularized masking on target datasets, instead of input dropping or zero. Empirically, when built with Vision Transformers structure, we find A-JEPA to be highly scalable and sets new state-of-the-art performance on multiple audio and speech classification tasks, outperforming other recent models that use externally supervised pre-training.
Decoding Emotions: A comprehensive Multilingual Study of Speech Models for Speech Emotion Recognition
Aug 17, 2023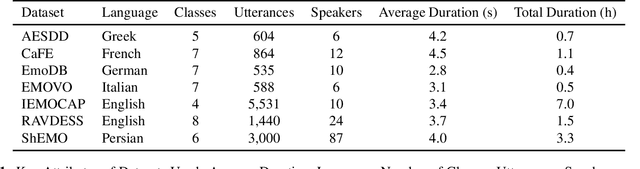
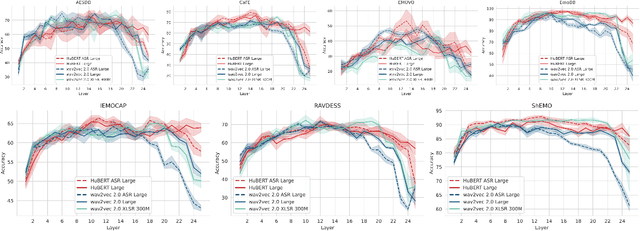
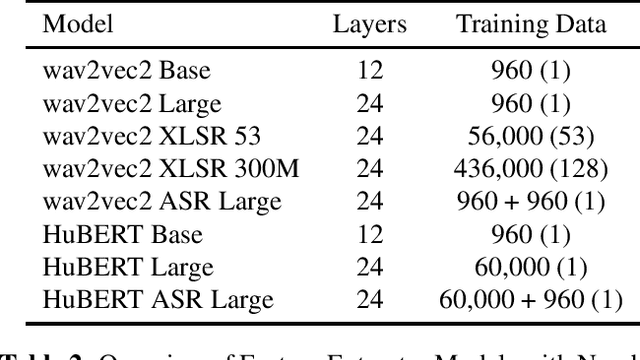
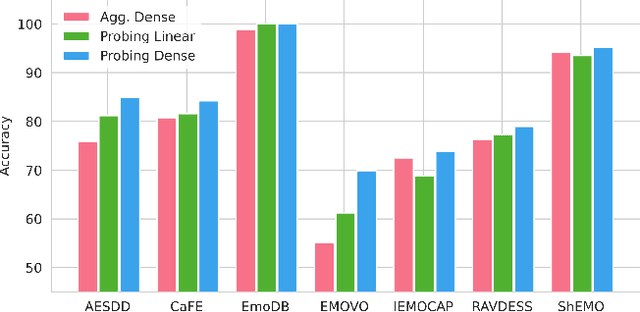
Recent advancements in transformer-based speech representation models have greatly transformed speech processing. However, there has been limited research conducted on evaluating these models for speech emotion recognition (SER) across multiple languages and examining their internal representations. This article addresses these gaps by presenting a comprehensive benchmark for SER with eight speech representation models and six different languages. We conducted probing experiments to gain insights into inner workings of these models for SER. We find that using features from a single optimal layer of a speech model reduces the error rate by 32\% on average across seven datasets when compared to systems where features from all layers of speech models are used. We also achieve state-of-the-art results for German and Persian languages. Our probing results indicate that the middle layers of speech models capture the most important emotional information for speech emotion recognition.
Unifying Robustness and Fidelity: A Comprehensive Study of Pretrained Generative Methods for Speech Enhancement in Adverse Conditions
Sep 16, 2023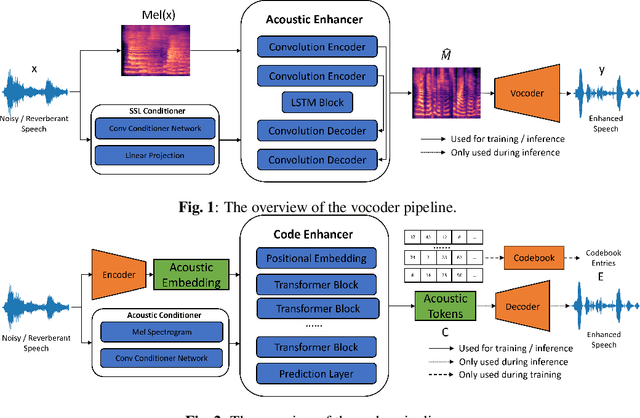

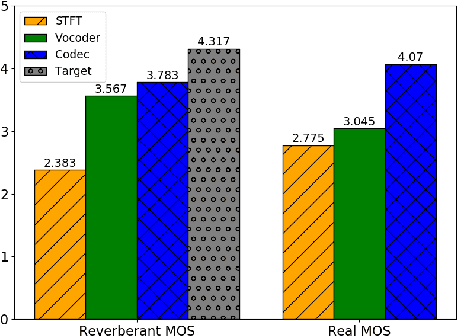
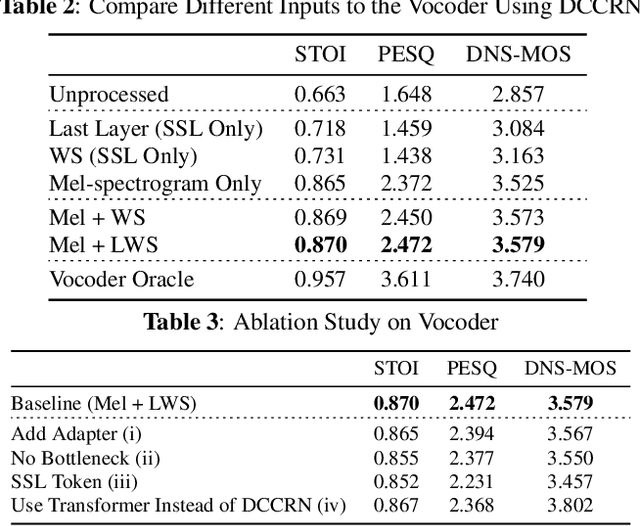
Enhancing speech signal quality in adverse acoustic environments is a persistent challenge in speech processing. Existing deep learning based enhancement methods often struggle to effectively remove background noise and reverberation in real-world scenarios, hampering listening experiences. To address these challenges, we propose a novel approach that uses pre-trained generative methods to resynthesize clean, anechoic speech from degraded inputs. This study leverages pre-trained vocoder or codec models to synthesize high-quality speech while enhancing robustness in challenging scenarios. Generative methods effectively handle information loss in speech signals, resulting in regenerated speech that has improved fidelity and reduced artifacts. By harnessing the capabilities of pre-trained models, we achieve faithful reproduction of the original speech in adverse conditions. Experimental evaluations on both simulated datasets and realistic samples demonstrate the effectiveness and robustness of our proposed methods. Especially by leveraging codec, we achieve superior subjective scores for both simulated and realistic recordings. The generated speech exhibits enhanced audio quality, reduced background noise, and reverberation. Our findings highlight the potential of pre-trained generative techniques in speech processing, particularly in scenarios where traditional methods falter. Demos are available at https://whmrtm.github.io/SoundResynthesis.
Effect of Attention and Self-Supervised Speech Embeddings on Non-Semantic Speech Tasks
Aug 28, 2023Human emotion understanding is pivotal in making conversational technology mainstream. We view speech emotion understanding as a perception task which is a more realistic setting. With varying contexts (languages, demographics, etc.) different share of people perceive the same speech segment as a non-unanimous emotion. As part of the ACM Multimedia 2023 Computational Paralinguistics ChallengE (ComParE) in the EMotion Share track, we leverage their rich dataset of multilingual speakers and multi-label regression target of 'emotion share' or perception of that emotion. We demonstrate that the training scheme of different foundation models dictates their effectiveness for tasks beyond speech recognition, especially for non-semantic speech tasks like emotion understanding. This is a very complex task due to multilingual speakers, variability in the target labels, and inherent imbalance in the regression dataset. Our results show that HuBERT-Large with a self-attention-based light-weight sequence model provides 4.6% improvement over the reported baseline.
Evaluating Self-Supervised Speech Representations for Indigenous American Languages
Oct 08, 2023The application of self-supervision to speech representation learning has garnered significant interest in recent years, due to its scalability to large amounts of unlabeled data. However, much progress, both in terms of pre-training and downstream evaluation, has remained concentrated in monolingual models that only consider English. Few models consider other languages, and even fewer consider indigenous ones. In our submission to the New Language Track of the ASRU 2023 ML-SUPERB Challenge, we present an ASR corpus for Quechua, an indigenous South American Language. We benchmark the efficacy of large SSL models on Quechua, along with 6 other indigenous languages such as Guarani and Bribri, on low-resource ASR. Our results show surprisingly strong performance by state-of-the-art SSL models, showing the potential generalizability of large-scale models to real-world data.
VaSAB: The variable size adaptive information bottleneck for disentanglement on speech and singing voice
Oct 05, 2023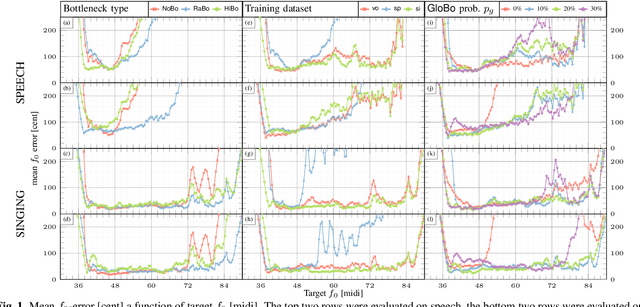
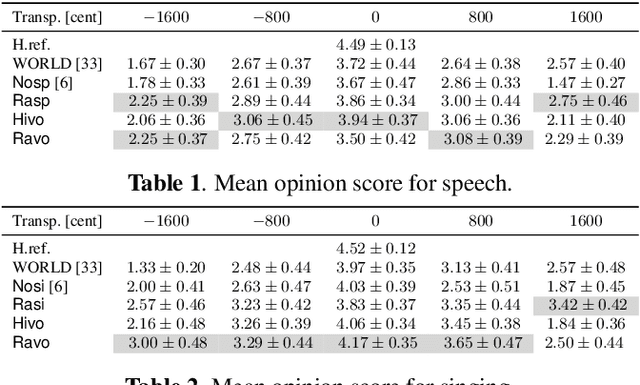
The information bottleneck auto-encoder is a tool for disentanglement commonly used for voice transformation. The successful disentanglement relies on the right choice of bottleneck size. Previous bottleneck auto-encoders created the bottleneck by the dimension of the latent space or through vector quantization and had no means to change the bottleneck size of a specific model. As the bottleneck removes information from the disentangled representation, the choice of bottleneck size is a trade-off between disentanglement and synthesis quality. We propose to build the information bottleneck using dropout which allows us to change the bottleneck through the dropout rate and investigate adapting the bottleneck size depending on the context. We experimentally explore into using the adaptive bottleneck for pitch transformation and demonstrate that the adaptive bottleneck leads to improved disentanglement of the F0 parameter for both, speech and singing voice leading to improved synthesis quality. Using the variable bottleneck size, we were able to achieve disentanglement for singing voice including extremely high pitches and create a universal voice model, that works on both speech and singing voice with improved synthesis quality.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 24, 2023Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
Rep2wav: Noise Robust text-to-speech Using self-supervised representations
Sep 04, 2023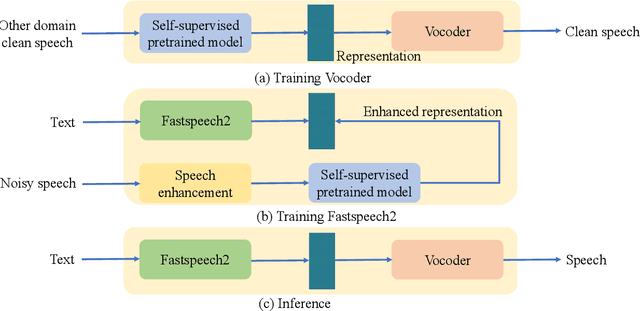


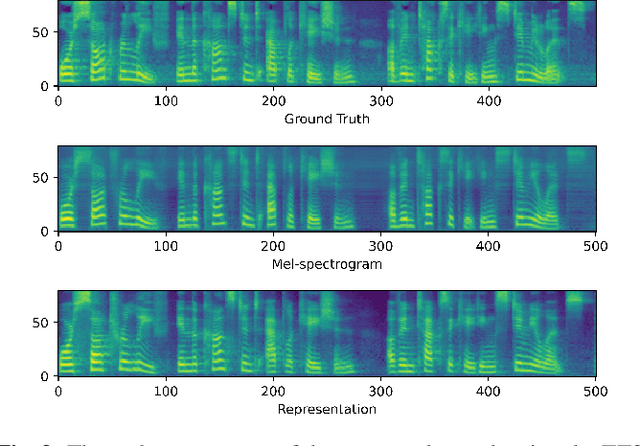
Benefiting from the development of deep learning, text-to-speech (TTS) techniques using clean speech have achieved significant performance improvements. The data collected from real scenes often contains noise and generally needs to be denoised by speech enhancement models. Noise-robust TTS models are often trained using the enhanced speech, which thus suffer from speech distortion and background noise that affect the quality of the synthesized speech. Meanwhile, it was shown that self-supervised pre-trained models exhibit excellent noise robustness on many speech tasks, implying that the learned representation has a better tolerance for noise perturbations. In this work, we therefore explore pre-trained models to improve the noise robustness of TTS models. Based on HiFi-GAN, we first propose a representation-to-waveform vocoder, which aims to learn to map the representation of pre-trained models to the waveform. We then propose a text-to-representation FastSpeech2 model, which aims to learn to map text to pre-trained model representations. Experimental results on the LJSpeech and LibriTTS datasets show that our method outperforms those using speech enhancement methods in both subjective and objective metrics. Audio samples are available at: https://zqs01.github.io/rep2wav.