 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
LLaSM: Large Language and Speech Model
Aug 30, 2023
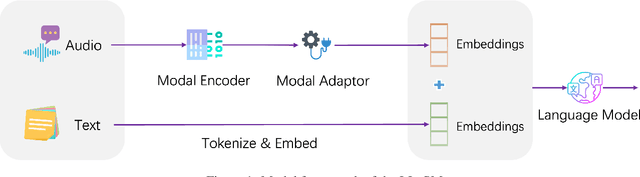
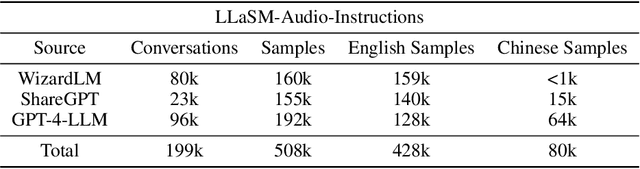

Multi-modal large language models have garnered significant interest recently. Though, most of the works focus on vision-language multi-modal models providing strong capabilities in following vision-and-language instructions. However, we claim that speech is also an important modality through which humans interact with the world. Hence, it is crucial for a general-purpose assistant to be able to follow multi-modal speech-and-language instructions. In this work, we propose Large Language and Speech Model (LLaSM). LLaSM is an end-to-end trained large multi-modal speech-language model with cross-modal conversational abilities, capable of following speech-and-language instructions. Our early experiments show that LLaSM demonstrates a more convenient and natural way for humans to interact with artificial intelligence. Specifically, we also release a large Speech Instruction Following dataset LLaSM-Audio-Instructions. Code and demo are available at https://github.com/LinkSoul-AI/LLaSM and https://huggingface.co/spaces/LinkSoul/LLaSM. The LLaSM-Audio-Instructions dataset is available at https://huggingface.co/datasets/LinkSoul/LLaSM-Audio-Instructions.
Foundation Model Assisted Automatic Speech Emotion Recognition: Transcribing, Annotating, and Augmenting
Sep 15, 2023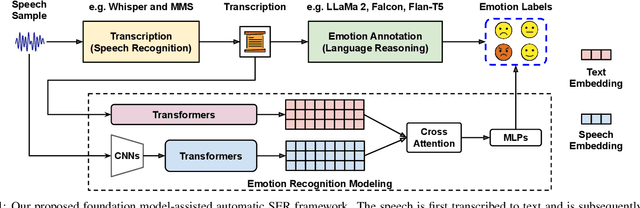
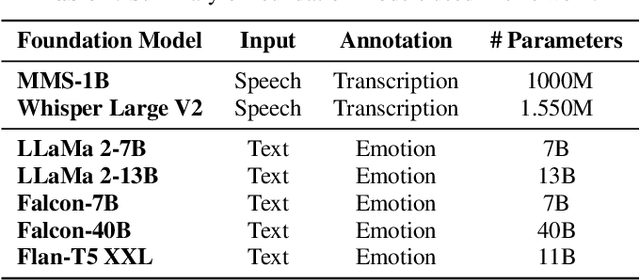
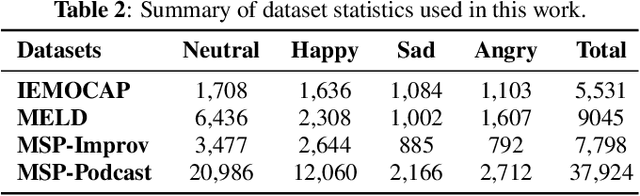
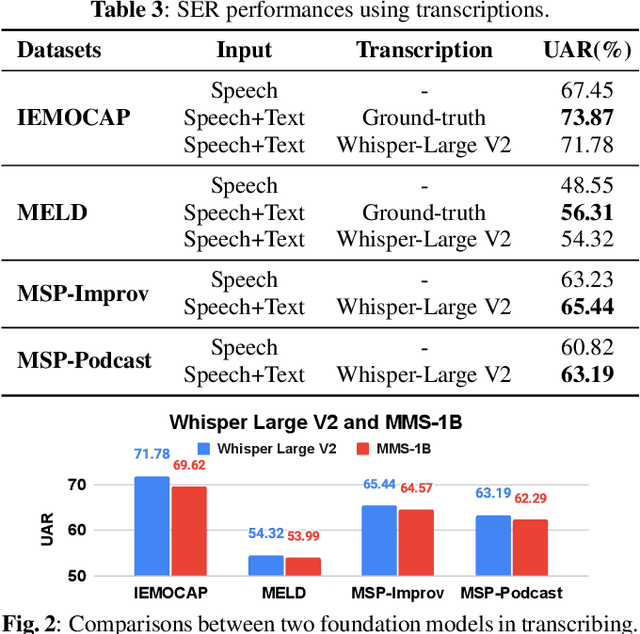
Significant advances are being made in speech emotion recognition (SER) using deep learning models. Nonetheless, training SER systems remains challenging, requiring both time and costly resources. Like many other machine learning tasks, acquiring datasets for SER requires substantial data annotation efforts, including transcription and labeling. These annotation processes present challenges when attempting to scale up conventional SER systems. Recent developments in foundational models have had a tremendous impact, giving rise to applications such as ChatGPT. These models have enhanced human-computer interactions including bringing unique possibilities for streamlining data collection in fields like SER. In this research, we explore the use of foundational models to assist in automating SER from transcription and annotation to augmentation. Our study demonstrates that these models can generate transcriptions to enhance the performance of SER systems that rely solely on speech data. Furthermore, we note that annotating emotions from transcribed speech remains a challenging task. However, combining outputs from multiple LLMs enhances the quality of annotations. Lastly, our findings suggest the feasibility of augmenting existing speech emotion datasets by annotating unlabeled speech samples.
Improved Contextual Recognition In Automatic Speech Recognition Systems By Semantic Lattice Rescoring
Oct 17, 2023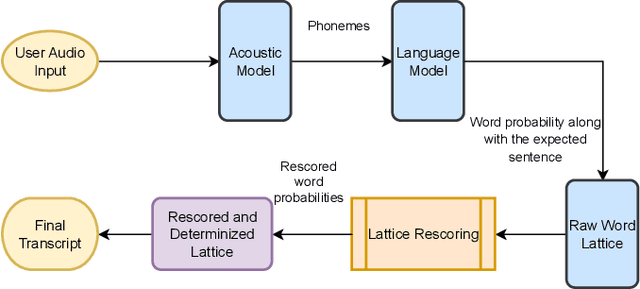
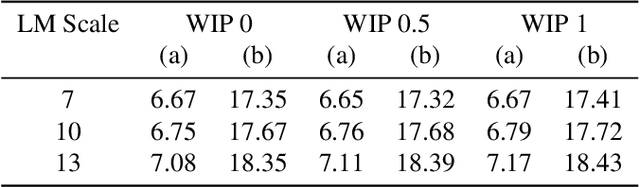
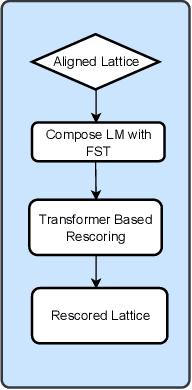
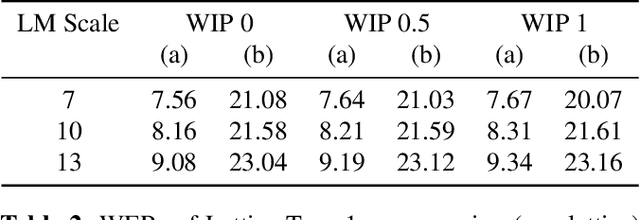
Automatic Speech Recognition (ASR) has witnessed a profound research interest. Recent breakthroughs have given ASR systems different prospects such as faithfully transcribing spoken language, which is a pivotal advancement in building conversational agents. However, there is still an imminent challenge of accurately discerning context-dependent words and phrases. In this work, we propose a novel approach for enhancing contextual recognition within ASR systems via semantic lattice processing leveraging the power of deep learning models in accurately delivering spot-on transcriptions across a wide variety of vocabularies and speaking styles. Our solution consists of using Hidden Markov Models and Gaussian Mixture Models (HMM-GMM) along with Deep Neural Networks (DNN) models integrating both language and acoustic modeling for better accuracy. We infused our network with the use of a transformer-based model to properly rescore the word lattice achieving remarkable capabilities with a palpable reduction in Word Error Rate (WER). We demonstrate the effectiveness of our proposed framework on the LibriSpeech dataset with empirical analyses.
Enhancing End-to-End Conversational Speech Translation Through Target Language Context Utilization
Sep 27, 2023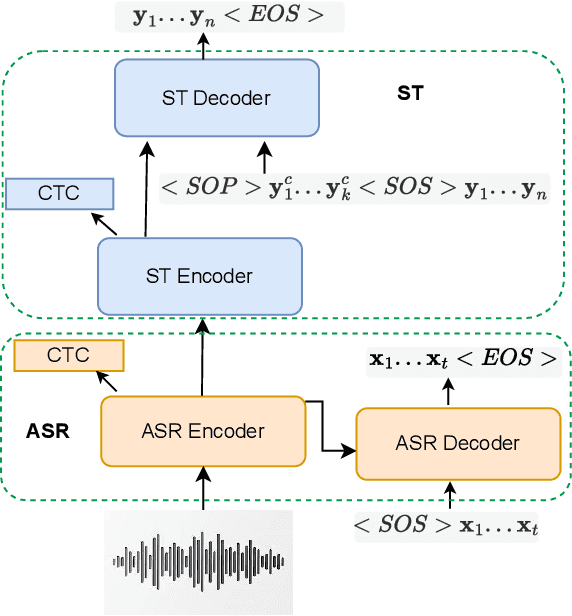
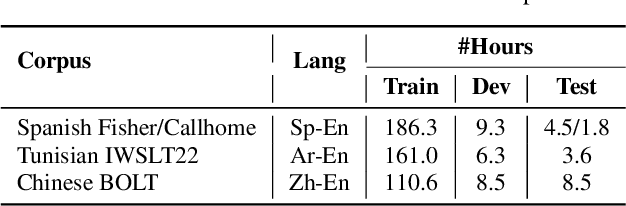
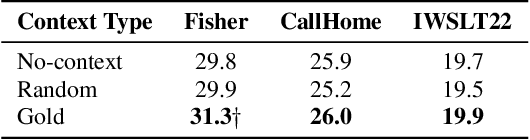
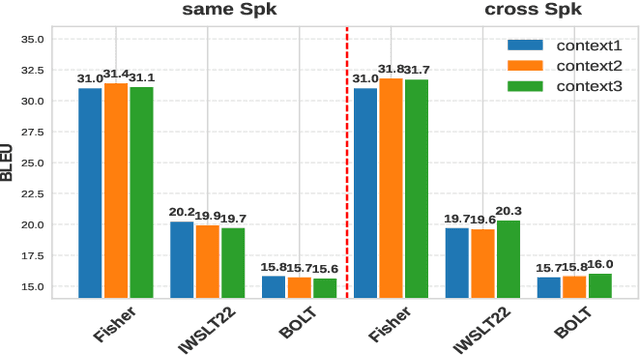
Incorporating longer context has been shown to benefit machine translation, but the inclusion of context in end-to-end speech translation (E2E-ST) remains under-studied. To bridge this gap, we introduce target language context in E2E-ST, enhancing coherence and overcoming memory constraints of extended audio segments. Additionally, we propose context dropout to ensure robustness to the absence of context, and further improve performance by adding speaker information. Our proposed contextual E2E-ST outperforms the isolated utterance-based E2E-ST approach. Lastly, we demonstrate that in conversational speech, contextual information primarily contributes to capturing context style, as well as resolving anaphora and named entities.
GRASS: Unified Generation Model for Speech Semantic Understanding
Sep 06, 2023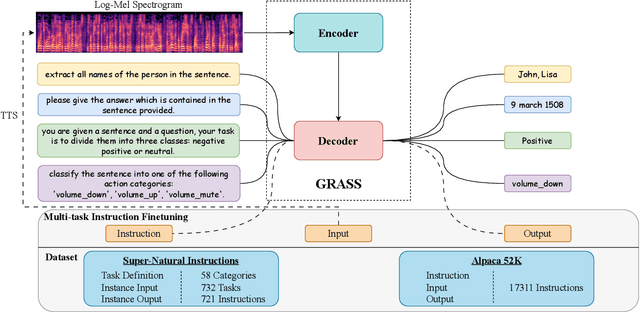
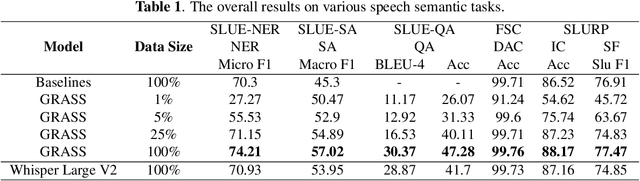

This paper explores the instruction fine-tuning technique for speech semantic understanding by introducing a unified end-to-end (E2E) framework that generates semantic labels conditioned on a task-related prompt for audio data. We pre-train the model using large and diverse data, where instruction-speech pairs are constructed via a text-to-speech (TTS) system. Extensive experiments demonstrate that our proposed model significantly outperforms state-of-the-art (SOTA) models after fine-tuning downstream tasks. Furthermore, the proposed model achieves competitive performance in zero-shot and few-shot scenarios. To facilitate future work on instruction fine-tuning for speech-to-semantic tasks, we release our instruction dataset and code.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 24, 2023Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
Keyword Augmented Retrieval: Novel framework for Information Retrieval integrated with speech interface
Oct 06, 2023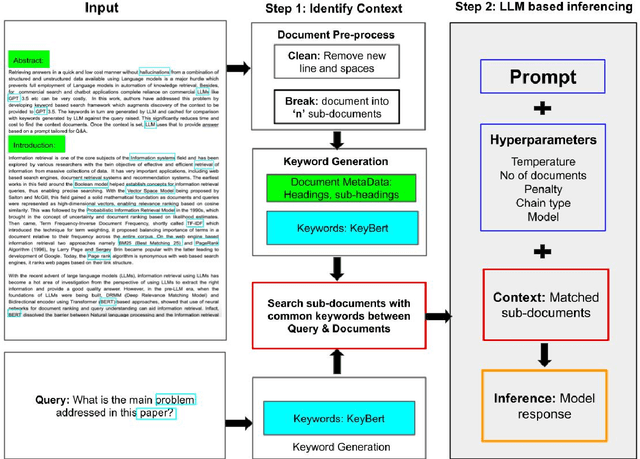
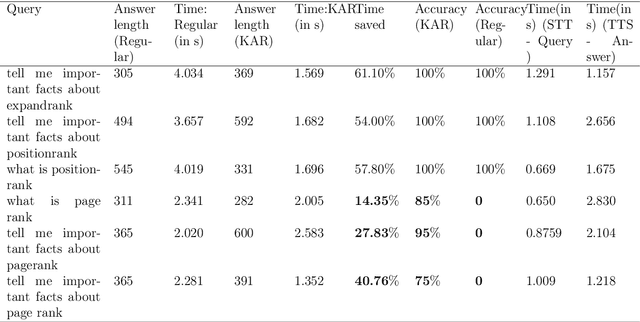
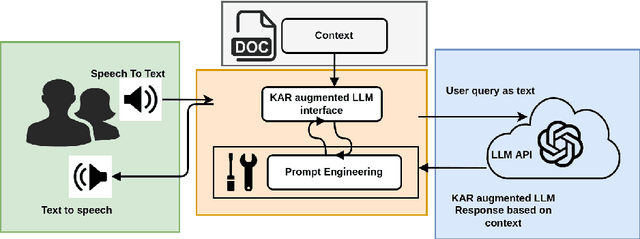
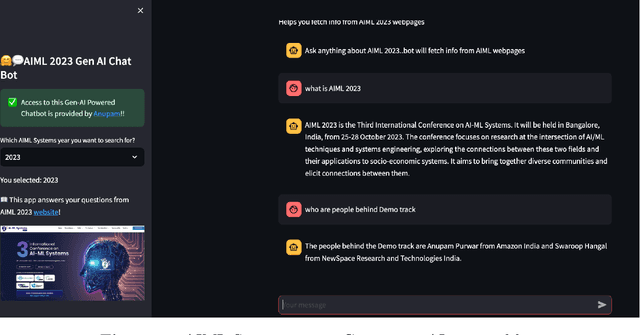
Retrieving answers in a quick and low cost manner without hallucinations from a combination of structured and unstructured data using Language models is a major hurdle which prevents employment of Language models in knowledge retrieval automation. This becomes accentuated when one wants to integrate a speech interface. Besides, for commercial search and chatbot applications, complete reliance on commercial large language models (LLMs) like GPT 3.5 etc. can be very costly. In this work, authors have addressed this problem by first developing a keyword based search framework which augments discovery of the context to be provided to the large language model. The keywords in turn are generated by LLM and cached for comparison with keywords generated by LLM against the query raised. This significantly reduces time and cost to find the context within documents. Once the context is set, LLM uses that to provide answers based on a prompt tailored for Q&A. This research work demonstrates that use of keywords in context identification reduces the overall inference time and cost of information retrieval. Given this reduction in inference time and cost with the keyword augmented retrieval framework, a speech based interface for user input and response readout was integrated. This allowed a seamless interaction with the language model.
Utilizing Whisper to Enhance Multi-Branched Speech Intelligibility Prediction Model for Hearing Aids
Sep 18, 2023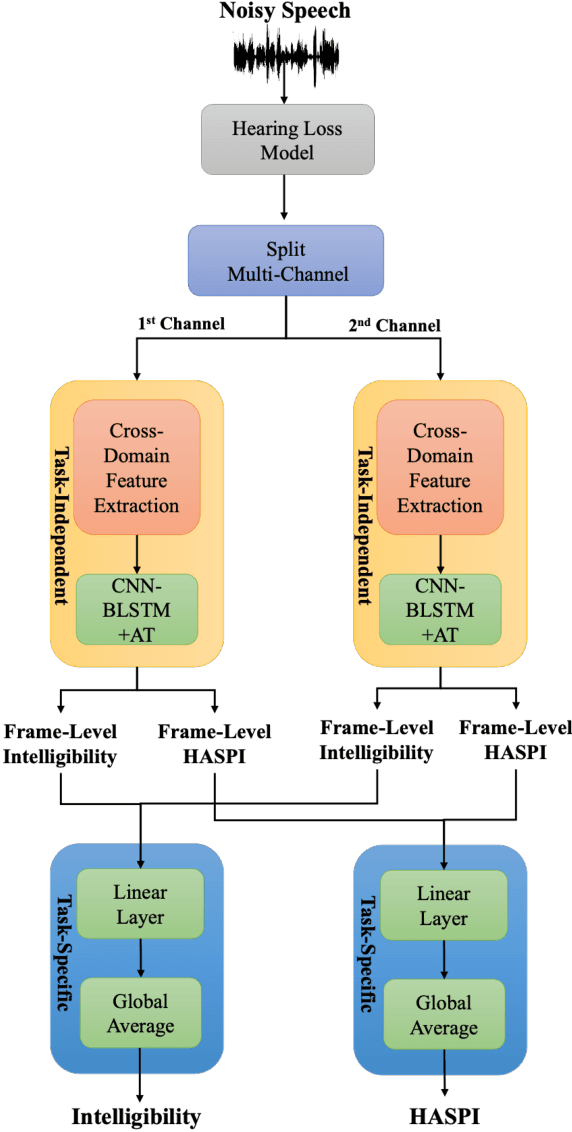
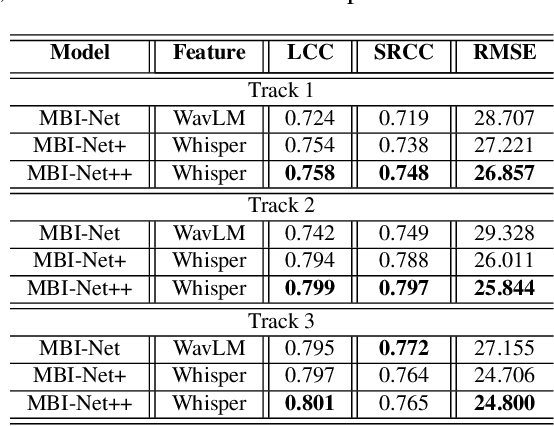
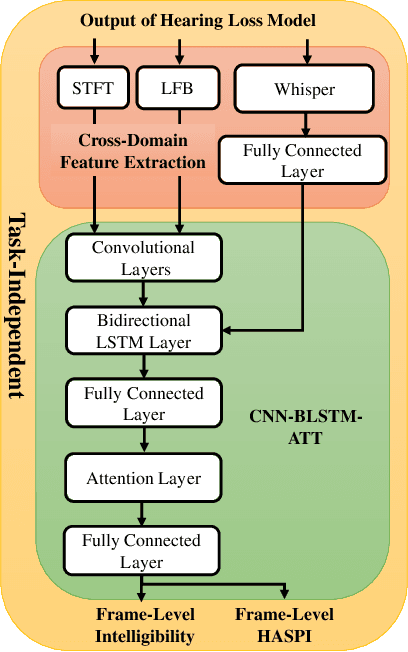
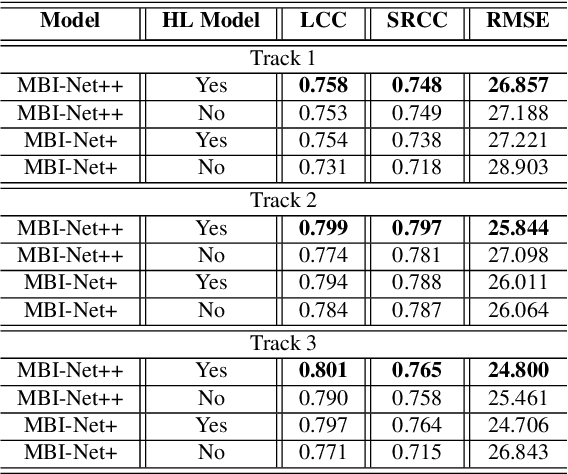
Automated assessment of speech intelligibility in hearing aid (HA) devices is of great importance. Our previous work introduced a non-intrusive multi-branched speech intelligibility prediction model called MBI-Net, which achieved top performance in the Clarity Prediction Challenge 2022. Based on the promising results of the MBI-Net model, we aim to further enhance its performance by leveraging Whisper embeddings to enrich acoustic features. In this study, we propose two improved models, namely MBI-Net+ and MBI-Net++. MBI-Net+ maintains the same model architecture as MBI-Net, but replaces self-supervised learning (SSL) speech embeddings with Whisper embeddings to deploy cross-domain features. On the other hand, MBI-Net++ further employs a more elaborate design, incorporating an auxiliary task to predict frame-level and utterance-level scores of the objective speech intelligibility metric HASPI (Hearing Aid Speech Perception Index) and multi-task learning. Experimental results confirm that both MBI-Net++ and MBI-Net+ achieve better prediction performance than MBI-Net in terms of multiple metrics, and MBI-Net++ is better than MBI-Net+.
RoDia: A New Dataset for Romanian Dialect Identification from Speech
Sep 12, 2023
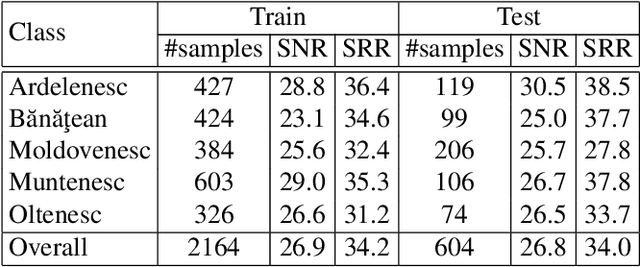
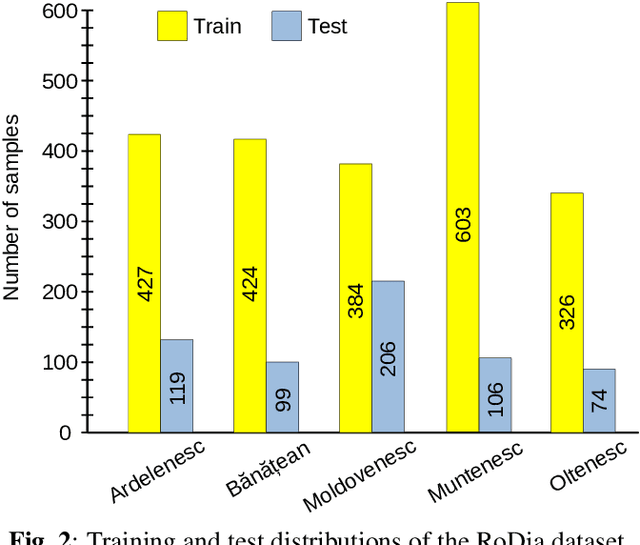

Dialect identification is a critical task in speech processing and language technology, enhancing various applications such as speech recognition, speaker verification, and many others. While most research studies have been dedicated to dialect identification in widely spoken languages, limited attention has been given to dialect identification in low-resource languages, such as Romanian. To address this research gap, we introduce RoDia, the first dataset for Romanian dialect identification from speech. The RoDia dataset includes a varied compilation of speech samples from five distinct regions of Romania, covering both urban and rural environments, totaling 2 hours of manually annotated speech data. Along with our dataset, we introduce a set of competitive models to be used as baselines for future research. The top scoring model achieves a macro F1 score of 59.83% and a micro F1 score of 62.08%, indicating that the task is challenging. We thus believe that RoDia is a valuable resource that will stimulate research aiming to address the challenges of Romanian dialect identification. We publicly release our dataset and code at https://github.com/codrut2/RoDia.
Towards Joint Modeling of Dialogue Response and Speech Synthesis based on Large Language Model
Sep 20, 2023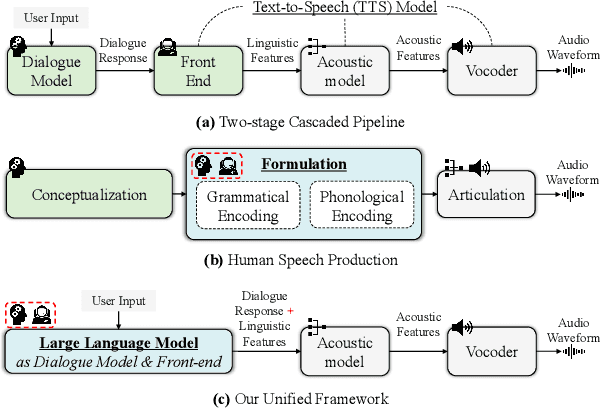
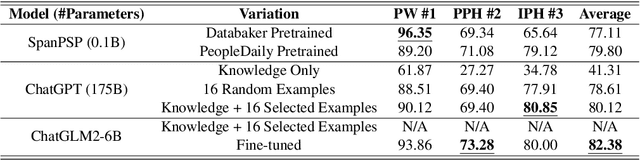
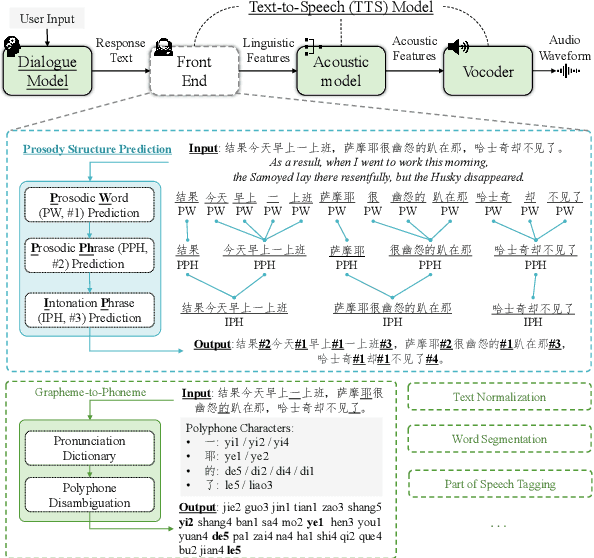
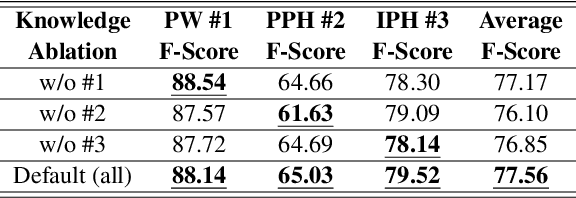
This paper explores the potential of constructing an AI spoken dialogue system that "thinks how to respond" and "thinks how to speak" simultaneously, which more closely aligns with the human speech production process compared to the current cascade pipeline of independent chatbot and Text-to-Speech (TTS) modules. We hypothesize that Large Language Models (LLMs) with billions of parameters possess significant speech understanding capabilities and can jointly model dialogue responses and linguistic features. We conduct two sets of experiments: 1) Prosodic structure prediction, a typical front-end task in TTS, demonstrating the speech understanding ability of LLMs, and 2) Further integrating dialogue response and a wide array of linguistic features using a unified encoding format. Our results indicate that the LLM-based approach is a promising direction for building unified spoken dialogue systems.