 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
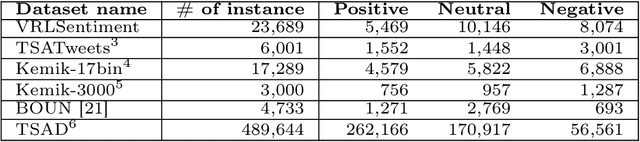
Hate speech detection in algerian dialect using deep learning
Sep 20, 2023
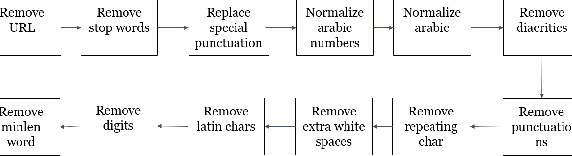
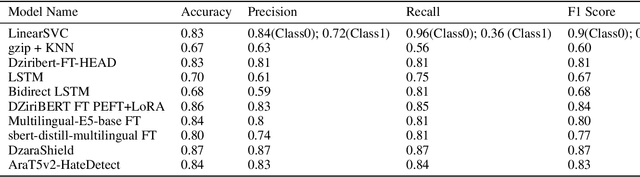
With the proliferation of hate speech on social networks under different formats, such as abusive language, cyberbullying, and violence, etc., people have experienced a significant increase in violence, putting them in uncomfortable situations and threats. Plenty of efforts have been dedicated in the last few years to overcome this phenomenon to detect hate speech in different structured languages like English, French, Arabic, and others. However, a reduced number of works deal with Arabic dialects like Tunisian, Egyptian, and Gulf, mainly the Algerian ones. To fill in the gap, we propose in this work a complete approach for detecting hate speech on online Algerian messages. Many deep learning architectures have been evaluated on the corpus we created from some Algerian social networks (Facebook, YouTube, and Twitter). This corpus contains more than 13.5K documents in Algerian dialect written in Arabic, labeled as hateful or non-hateful. Promising results are obtained, which show the efficiency of our approach.
Speech Audio Synthesis from Tagged MRI and Non-Negative Matrix Factorization via Plastic Transformer
Sep 26, 2023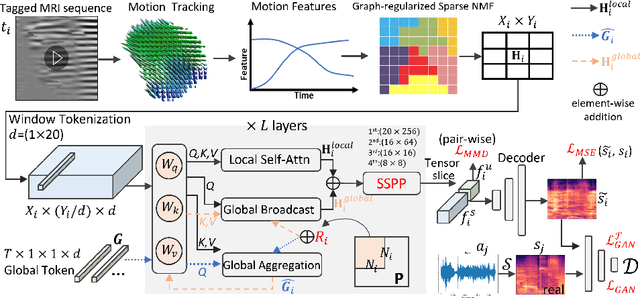
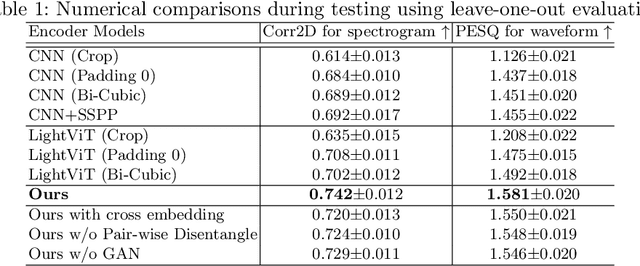
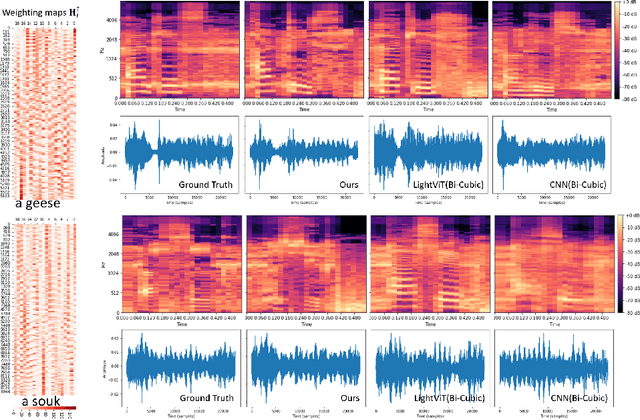
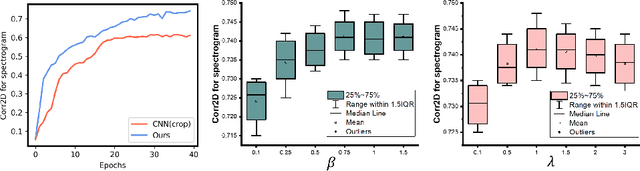
The tongue's intricate 3D structure, comprising localized functional units, plays a crucial role in the production of speech. When measured using tagged MRI, these functional units exhibit cohesive displacements and derived quantities that facilitate the complex process of speech production. Non-negative matrix factorization-based approaches have been shown to estimate the functional units through motion features, yielding a set of building blocks and a corresponding weighting map. Investigating the link between weighting maps and speech acoustics can offer significant insights into the intricate process of speech production. To this end, in this work, we utilize two-dimensional spectrograms as a proxy representation, and develop an end-to-end deep learning framework for translating weighting maps to their corresponding audio waveforms. Our proposed plastic light transformer (PLT) framework is based on directional product relative position bias and single-level spatial pyramid pooling, thus enabling flexible processing of weighting maps with variable size to fixed-size spectrograms, without input information loss or dimension expansion. Additionally, our PLT framework efficiently models the global correlation of wide matrix input. To improve the realism of our generated spectrograms with relatively limited training samples, we apply pair-wise utterance consistency with Maximum Mean Discrepancy constraint and adversarial training. Experimental results on a dataset of 29 subjects speaking two utterances demonstrated that our framework is able to synthesize speech audio waveforms from weighting maps, outperforming conventional convolution and transformer models.
How To Build Competitive Multi-gender Speech Translation Models For Controlling Speaker Gender Translation
Oct 23, 2023When translating from notional gender languages (e.g., English) into grammatical gender languages (e.g., Italian), the generated translation requires explicit gender assignments for various words, including those referring to the speaker. When the source sentence does not convey the speaker's gender, speech translation (ST) models either rely on the possibly-misleading vocal traits of the speaker or default to the masculine gender, the most frequent in existing training corpora. To avoid such biased and not inclusive behaviors, the gender assignment of speaker-related expressions should be guided by externally-provided metadata about the speaker's gender. While previous work has shown that the most effective solution is represented by separate, dedicated gender-specific models, the goal of this paper is to achieve the same results by integrating the speaker's gender metadata into a single "multi-gender" neural ST model, easier to maintain. Our experiments demonstrate that a single multi-gender model outperforms gender-specialized ones when trained from scratch (with gender accuracy gains up to 12.9 for feminine forms), while fine-tuning from existing ST models does not lead to competitive results.
A Unified Framework for Multimodal, Multi-Part Human Motion Synthesis
Nov 28, 2023The field has made significant progress in synthesizing realistic human motion driven by various modalities. Yet, the need for different methods to animate various body parts according to different control signals limits the scalability of these techniques in practical scenarios. In this paper, we introduce a cohesive and scalable approach that consolidates multimodal (text, music, speech) and multi-part (hand, torso) human motion generation. Our methodology unfolds in several steps: We begin by quantizing the motions of diverse body parts into separate codebooks tailored to their respective domains. Next, we harness the robust capabilities of pre-trained models to transcode multimodal signals into a shared latent space. We then translate these signals into discrete motion tokens by iteratively predicting subsequent tokens to form a complete sequence. Finally, we reconstruct the continuous actual motion from this tokenized sequence. Our method frames the multimodal motion generation challenge as a token prediction task, drawing from specialized codebooks based on the modality of the control signal. This approach is inherently scalable, allowing for the easy integration of new modalities. Extensive experiments demonstrated the effectiveness of our design, emphasizing its potential for broad application.
TurkishBERTweet: Fast and Reliable Large Language Model for Social Media Analysis
Nov 29, 2023
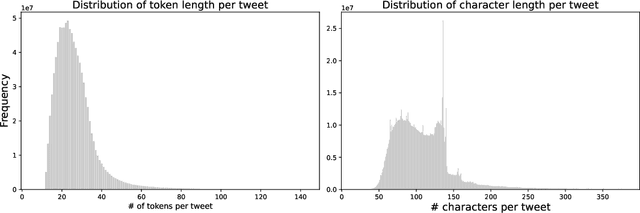
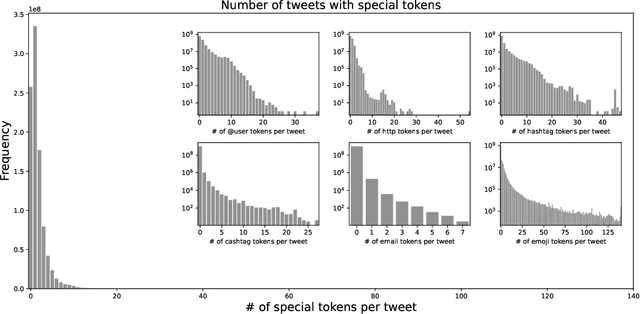
Turkish is one of the most popular languages in the world. Wide us of this language on social media platforms such as Twitter, Instagram, or Tiktok and strategic position of the country in the world politics makes it appealing for the social network researchers and industry. To address this need, we introduce TurkishBERTweet, the first large scale pre-trained language model for Turkish social media built using almost 900 million tweets. The model shares the same architecture as base BERT model with smaller input length, making TurkishBERTweet lighter than BERTurk and can have significantly lower inference time. We trained our model using the same approach for RoBERTa model and evaluated on two text classification tasks: Sentiment Classification and Hate Speech Detection. We demonstrate that TurkishBERTweet outperforms the other available alternatives on generalizability and its lower inference time gives significant advantage to process large-scale datasets. We also compared our models with the commercial OpenAI solutions in terms of cost and performance to demonstrate TurkishBERTweet is scalable and cost-effective solution. As part of our research, we released TurkishBERTweet and fine-tuned LoRA adapters for the mentioned tasks under the MIT License to facilitate future research and applications on Turkish social media. Our TurkishBERTweet model is available at: https://github.com/ViralLab/TurkishBERTweet
End-to-End Speech Recognition Contextualization with Large Language Models
Sep 19, 2023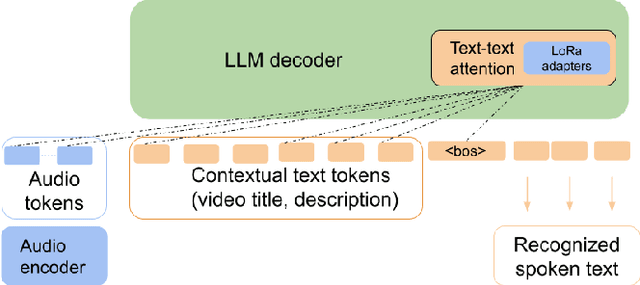

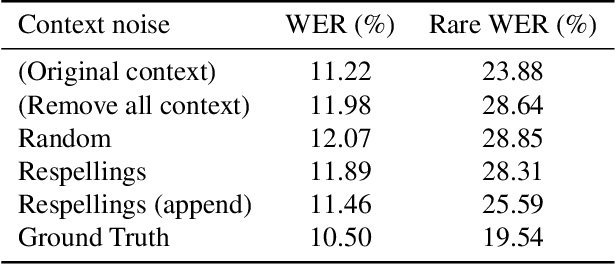

In recent years, Large Language Models (LLMs) have garnered significant attention from the research community due to their exceptional performance and generalization capabilities. In this paper, we introduce a novel method for contextualizing speech recognition models incorporating LLMs. Our approach casts speech recognition as a mixed-modal language modeling task based on a pretrained LLM. We provide audio features, along with optional text tokens for context, to train the system to complete transcriptions in a decoder-only fashion. As a result, the system is implicitly incentivized to learn how to leverage unstructured contextual information during training. Our empirical results demonstrate a significant improvement in performance, with a 6% WER reduction when additional textual context is provided. Moreover, we find that our method performs competitively and improve by 7.5% WER overall and 17% WER on rare words against a baseline contextualized RNN-T system that has been trained on more than twenty five times larger speech dataset. Overall, we demonstrate that by only adding a handful number of trainable parameters via adapters, we can unlock contextualized speech recognition capability for the pretrained LLM while keeping the same text-only input functionality.
VoxArabica: A Robust Dialect-Aware Arabic Speech Recognition System
Oct 17, 2023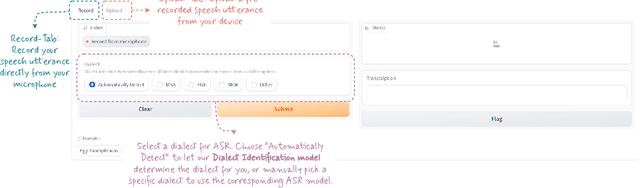

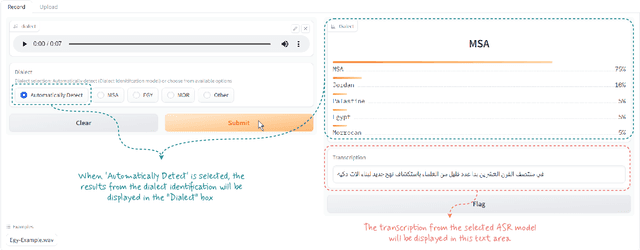
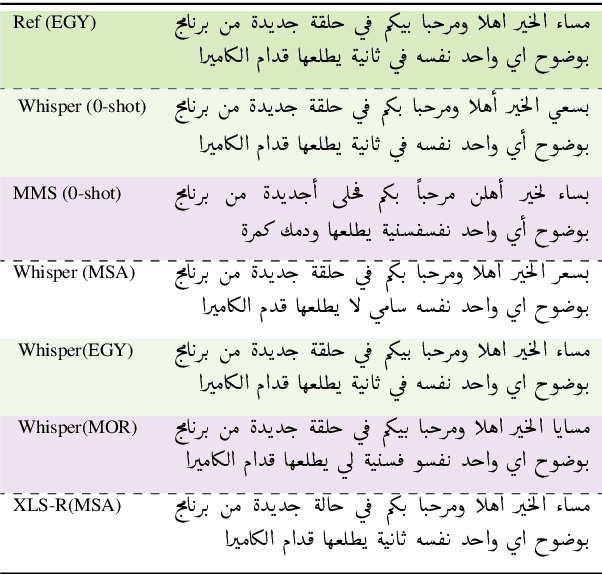
Arabic is a complex language with many varieties and dialects spoken by over 450 millions all around the world. Due to the linguistic diversity and variations, it is challenging to build a robust and generalized ASR system for Arabic. In this work, we address this gap by developing and demoing a system, dubbed VoxArabica, for dialect identification (DID) as well as automatic speech recognition (ASR) of Arabic. We train a wide range of models such as HuBERT (DID), Whisper, and XLS-R (ASR) in a supervised setting for Arabic DID and ASR tasks. Our DID models are trained to identify 17 different dialects in addition to MSA. We finetune our ASR models on MSA, Egyptian, Moroccan, and mixed data. Additionally, for the remaining dialects in ASR, we provide the option to choose various models such as Whisper and MMS in a zero-shot setting. We integrate these models into a single web interface with diverse features such as audio recording, file upload, model selection, and the option to raise flags for incorrect outputs. Overall, we believe VoxArabica will be useful for a wide range of audiences concerned with Arabic research. Our system is currently running at https://cdce-206-12-100-168.ngrok.io/.
Discriminative Speech Recognition Rescoring with Pre-trained Language Models
Oct 10, 2023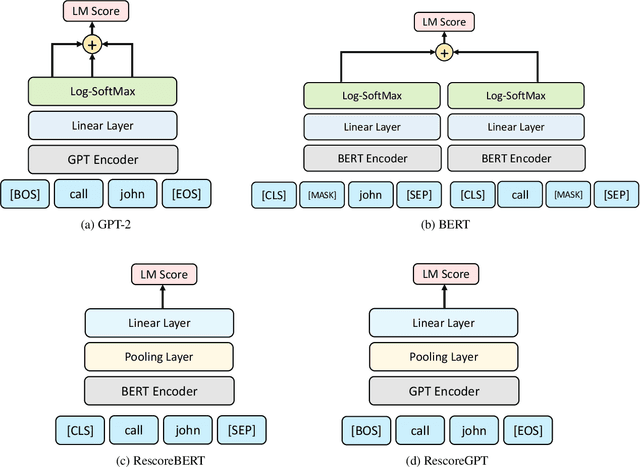
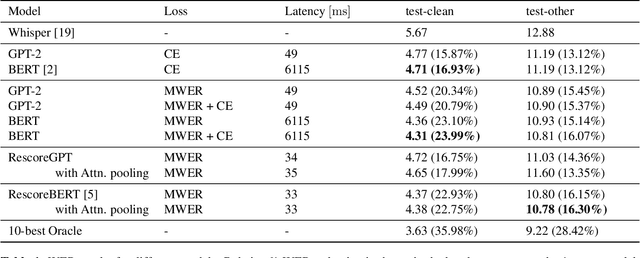
Second pass rescoring is a critical component of competitive automatic speech recognition (ASR) systems. Large language models have demonstrated their ability in using pre-trained information for better rescoring of ASR hypothesis. Discriminative training, directly optimizing the minimum word-error-rate (MWER) criterion typically improves rescoring. In this study, we propose and explore several discriminative fine-tuning schemes for pre-trained LMs. We propose two architectures based on different pooling strategies of output embeddings and compare with probability based MWER. We conduct detailed comparisons between pre-trained causal and bidirectional LMs in discriminative settings. Experiments on LibriSpeech demonstrate that all MWER training schemes are beneficial, giving additional gains upto 8.5\% WER. Proposed pooling variants achieve lower latency while retaining most improvements. Finally, our study concludes that bidirectionality is better utilized with discriminative training.
A Study on Incorporating Whisper for Robust Speech Assessment
Sep 22, 2023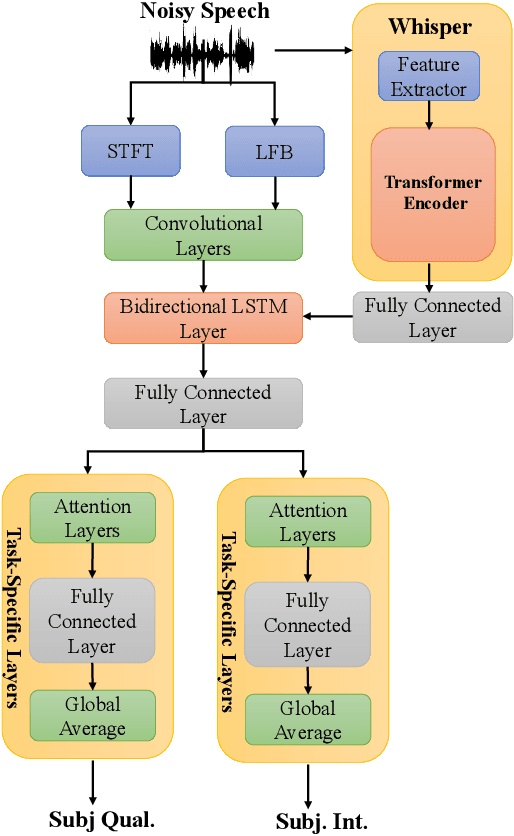
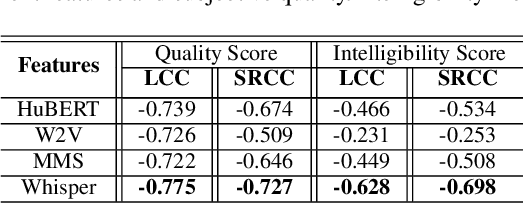
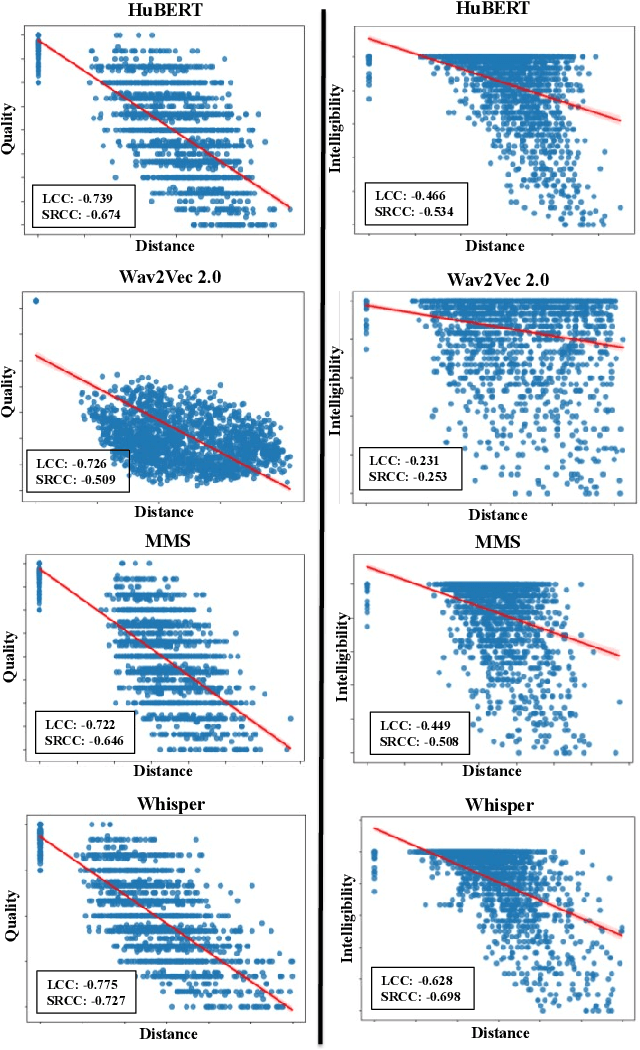
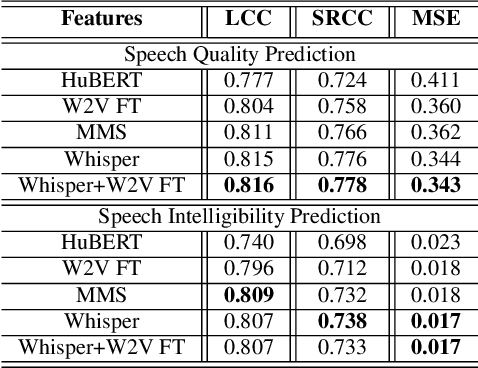
This research introduces an enhanced version of the multi-objective speech assessment model, called MOSA-Net+, by leveraging the acoustic features from large pre-trained weakly supervised models, namely Whisper, to create embedding features. The first part of this study investigates the correlation between the embedding features of Whisper and two self-supervised learning (SSL) models with subjective quality and intelligibility scores. The second part evaluates the effectiveness of Whisper in deploying a more robust speech assessment model. Third, the possibility of combining representations from Whisper and SSL models while deploying MOSA-Net+ is analyzed. The experimental results reveal that Whisper's embedding features correlate more strongly with subjective quality and intelligibility than other SSL's embedding features, contributing to more accurate prediction performance achieved by MOSA-Net+. Moreover, combining the embedding features from Whisper and SSL models only leads to marginal improvement. As compared to MOSA-Net and other SSL-based speech assessment models, MOSA-Net+ yields notable improvements in estimating subjective quality and intelligibility scores across all evaluation metrics. We further tested MOSA-Net+ on Track 3 of the VoiceMOS Challenge 2023 and obtained the top-ranked performance.
VoiceLDM: Text-to-Speech with Environmental Context
Sep 24, 2023This paper presents VoiceLDM, a model designed to produce audio that accurately follows two distinct natural language text prompts: the description prompt and the content prompt. The former provides information about the overall environmental context of the audio, while the latter conveys the linguistic content. To achieve this, we adopt a text-to-audio (TTA) model based on latent diffusion models and extend its functionality to incorporate an additional content prompt as a conditional input. By utilizing pretrained contrastive language-audio pretraining (CLAP) and Whisper, VoiceLDM is trained on large amounts of real-world audio without manual annotations or transcriptions. Additionally, we employ dual classifier-free guidance to further enhance the controllability of VoiceLDM. Experimental results demonstrate that VoiceLDM is capable of generating plausible audio that aligns well with both input conditions, even surpassing the speech intelligibility of the ground truth audio on the AudioCaps test set. Furthermore, we explore the text-to-speech (TTS) and zero-shot text-to-audio capabilities of VoiceLDM and show that it achieves competitive results. Demos and code are available at https://voiceldm.github.io.