 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Instructing Hierarchical Tasks to Robots by Verbal Commands
Nov 30, 2023
Natural language is an effective tool for communication, as information can be expressed in different ways and at different levels of complexity. Verbal commands, utilized for instructing robot tasks, can therefor replace traditional robot programming techniques, and provide a more expressive means to assign actions and enable collaboration. However, the challenge of utilizing speech for robot programming is how actions and targets can be grounded to physical entities in the world. In addition, to be time-efficient, a balance needs to be found between fine- and course-grained commands and natural language phrases. In this work we provide a framework for instructing tasks to robots by verbal commands. The framework includes functionalities for single commands to actions and targets, as well as longer-term sequences of actions, thereby providing a hierarchical structure to the robot tasks. Experimental evaluation demonstrates the functionalities of the framework by human collaboration with a robot in different tasks, with different levels of complexity. The tools are provided open-source at https://petim44.github.io/voice-jogger/
Weak Alignment Supervision from Hybrid Model Improves End-to-end ASR
Nov 30, 2023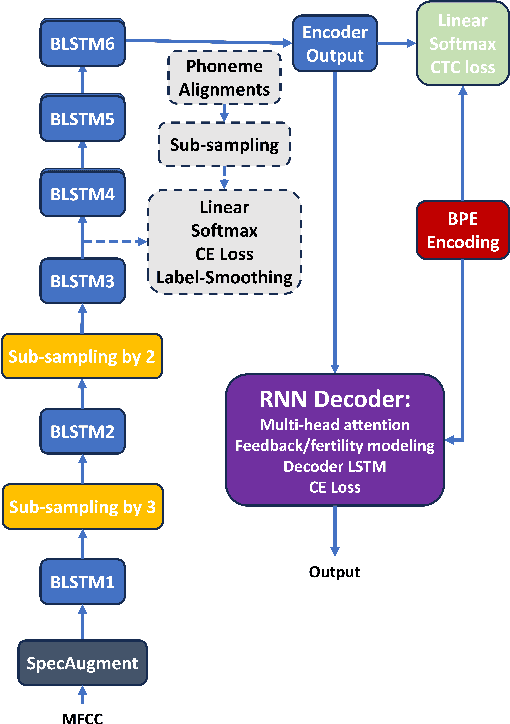
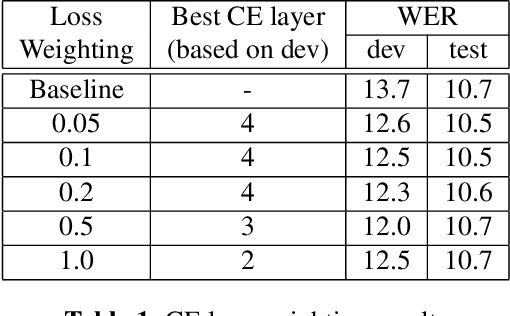
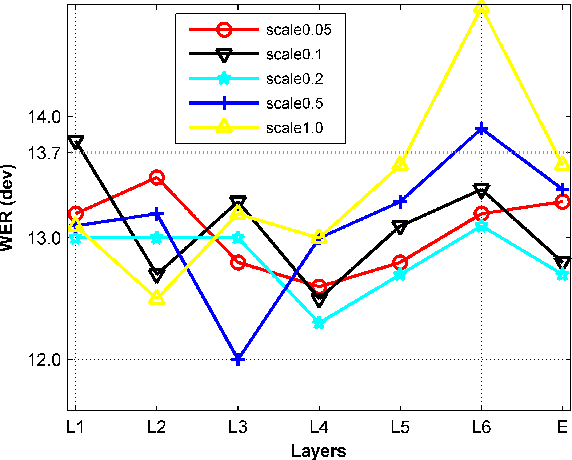

In this paper, we aim to create weak alignment supervision from an existing hybrid system to aid the end-to-end modeling of automatic speech recognition. Towards this end, we use the existing hybrid ASR system to produce triphone alignments of the training audios. We then create a cross-entropy loss at a certain layer of the encoder using the derived alignments. In contrast to the general one-hot cross-entropy losses, here we use a cross-entropy loss with a label smoothing parameter to regularize the supervision. As a comparison, we also conduct the experiments with one-hot cross-entropy losses and CTC losses with loss weighting. The results show that placing the weak alignment supervision with the label smoothing parameter of 0.5 at the third encoder layer outperforms the other two approaches and leads to about 5\% relative WER reduction on the TED-LIUM 2 dataset over the baseline. We see similar improvements when applying the method out-of-the-box on a Tagalog end-to-end ASR system.
Fast Word Error Rate Estimation Using Self-Supervised Representations For Speech And Text
Oct 12, 2023The quality of automatic speech recognition (ASR) is typically measured by word error rate (WER). WER estimation is a task aiming to predict the WER of an ASR system, given a speech utterance and a transcription. This task has gained increasing attention while advanced ASR systems are trained on large amounts of data. In this case, WER estimation becomes necessary in many scenarios, for example, selecting training data with unknown transcription quality or estimating the testing performance of an ASR system without ground truth transcriptions. Facing large amounts of data, the computation efficiency of a WER estimator becomes essential in practical applications. However, previous works usually did not consider it as a priority. In this paper, a Fast WER estimator (Fe-WER) using self-supervised learning representation (SSLR) is introduced. The estimator is built upon SSLR aggregated by average pooling. The results show that Fe-WER outperformed the e-WER3 baseline relatively by 19.69% and 7.16% on Ted-Lium3 in both evaluation metrics of root mean square error and Pearson correlation coefficient, respectively. Moreover, the estimation weighted by duration was 10.43% when the target was 10.88%. Lastly, the inference speed was about 4x in terms of a real-time factor.
LC4SV: A Denoising Framework Learning to Compensate for Unseen Speaker Verification Models
Nov 28, 2023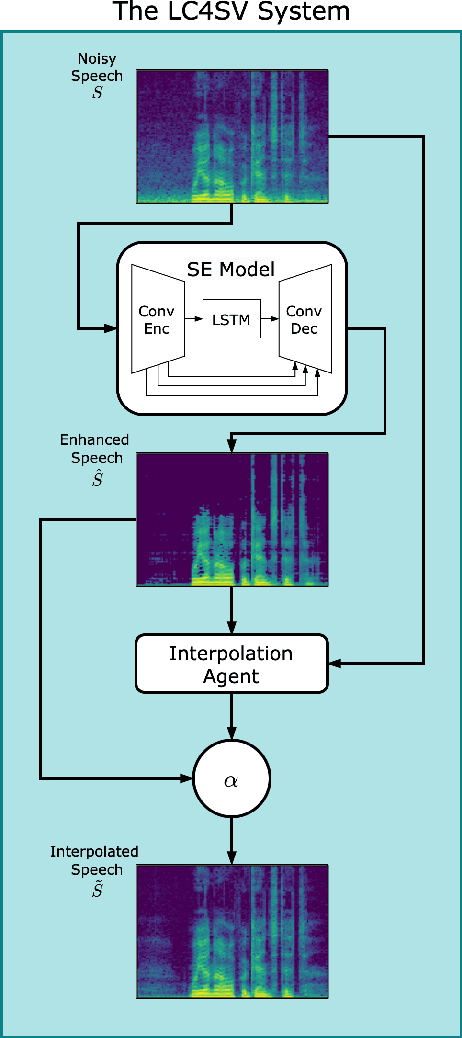
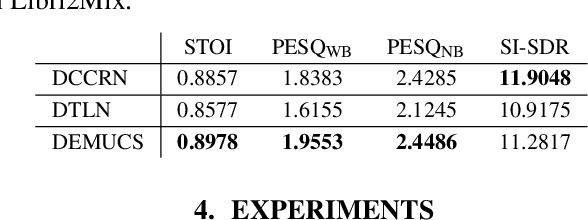
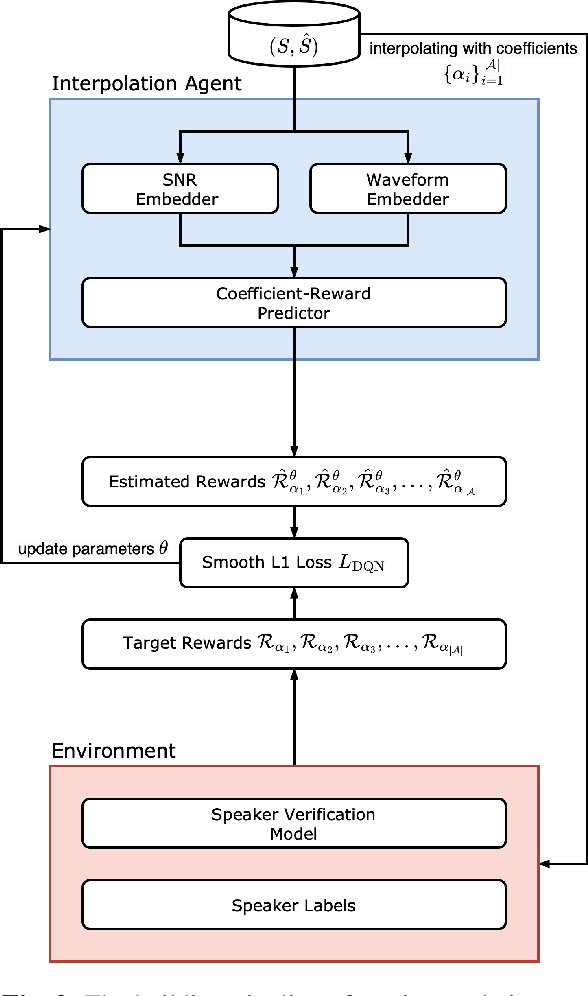
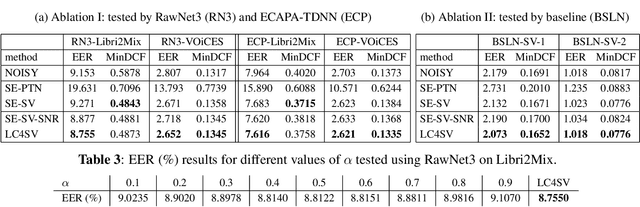
The performance of speaker verification (SV) models may drop dramatically in noisy environments. A speech enhancement (SE) module can be used as a front-end strategy. However, existing SE methods may fail to bring performance improvements to downstream SV systems due to artifacts in the predicted signals of SE models. To compensate for artifacts, we propose a generic denoising framework named LC4SV, which can serve as a pre-processor for various unknown downstream SV models. In LC4SV, we employ a learning-based interpolation agent to automatically generate the appropriate coefficients between the enhanced signal and its noisy input to improve SV performance in noisy environments. Our experimental results demonstrate that LC4SV consistently improves the performance of various unseen SV systems. To the best of our knowledge, this work is the first attempt to develop a learning-based interpolation scheme aiming at improving SV performance in noisy environments.
Learning Speech Representation From Contrastive Token-Acoustic Pretraining
Sep 06, 2023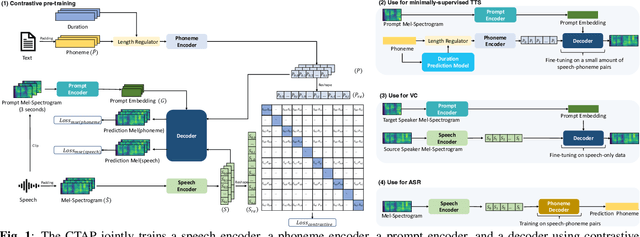
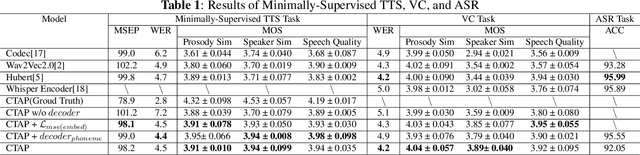
For fine-grained generation and recognition tasks such as minimally-supervised text-to-speech (TTS), voice conversion (VC), and automatic speech recognition (ASR), the intermediate representations extracted from speech should serve as a "bridge" between text and acoustic information, containing information from both modalities. The semantic content is emphasized, while the paralinguistic information such as speaker identity and acoustic details should be de-emphasized. However, existing methods for extracting fine-grained intermediate representations from speech suffer from issues of excessive redundancy and dimension explosion. Contrastive learning is a good method for modeling intermediate representations from two modalities. However, existing contrastive learning methods in the audio field focus on extracting global descriptive information for downstream audio classification tasks, making them unsuitable for TTS, VC, and ASR tasks. To address these issues, we propose a method named "Contrastive Token-Acoustic Pretraining (CTAP)", which uses two encoders to bring phoneme and speech into a joint multimodal space, learning how to connect phoneme and speech at the frame level. The CTAP model is trained on 210k speech and phoneme text pairs, achieving minimally-supervised TTS, VC, and ASR. The proposed CTAP method offers a promising solution for fine-grained generation and recognition downstream tasks in speech processing.
Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model
Dec 02, 2023The big language model represented by ChatGPT has had a disruptive impact on the field of artificial intelligence. But it mainly focuses on Natural language processing, speech recognition, machine learning and natural-language understanding. This paper innovatively applies the big language model to the field of intelligent decision-making, places the big language model in the decision-making center, and constructs an agent architecture with the big language model as the core. Based on this, it further proposes a two-layer agent task planning, issues and executes decision commands through the interaction of natural language, and carries out simulation verification through the wargame simulation environment. Through the game confrontation simulation experiment, it is found that the intelligent decision-making ability of the big language model is significantly stronger than the commonly used reinforcement learning AI and rule AI, and the intelligence, understandability and generalization are all better. And through experiments, it was found that the intelligence of the large language model is closely related to prompt. This work also extends the large language model from previous human-computer interaction to the field of intelligent decision-making, which has important reference value and significance for the development of intelligent decision-making.
Layer-Adapted Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition
Oct 06, 2023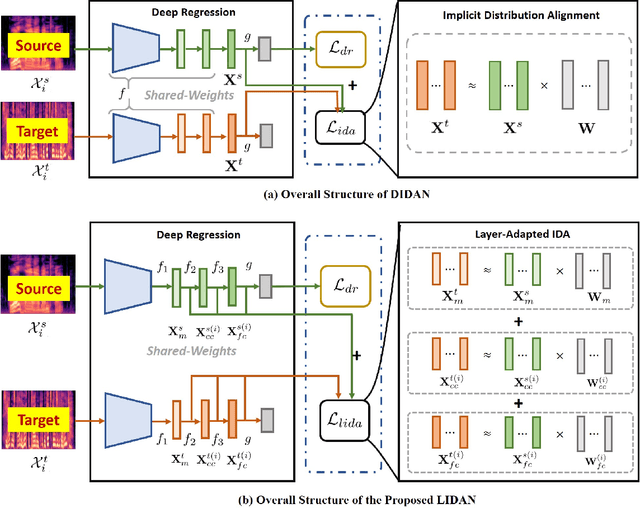

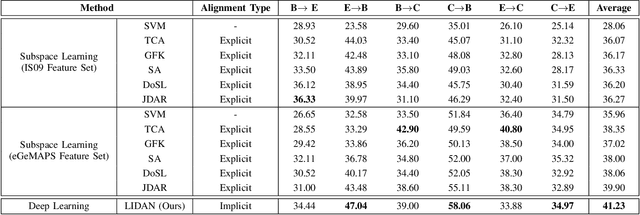
In this paper, we propose a new unsupervised domain adaptation (DA) method called layer-adapted implicit distribution alignment networks (LIDAN) to address the challenge of cross-corpus speech emotion recognition (SER). LIDAN extends our previous ICASSP work, deep implicit distribution alignment networks (DIDAN), whose key contribution lies in the introduction of a novel regularization term called implicit distribution alignment (IDA). This term allows DIDAN trained on source (training) speech samples to remain applicable to predicting emotion labels for target (testing) speech samples, regardless of corpus variance in cross-corpus SER. To further enhance this method, we extend IDA to layer-adapted IDA (LIDA), resulting in LIDAN. This layer-adpated extention consists of three modified IDA terms that consider emotion labels at different levels of granularity. These terms are strategically arranged within different fully connected layers in LIDAN, aligning with the increasing emotion-discriminative abilities with respect to the layer depth. This arrangement enables LIDAN to more effectively learn emotion-discriminative and corpus-invariant features for SER across various corpora compared to DIDAN. It is also worthy to mention that unlike most existing methods that rely on estimating statistical moments to describe pre-assumed explicit distributions, both IDA and LIDA take a different approach. They utilize an idea of target sample reconstruction to directly bridge the feature distribution gap without making assumptions about their distribution type. As a result, DIDAN and LIDAN can be viewed as implicit cross-corpus SER methods. To evaluate LIDAN, we conducted extensive cross-corpus SER experiments on EmoDB, eNTERFACE, and CASIA corpora. The experimental results demonstrate that LIDAN surpasses recent state-of-the-art explicit unsupervised DA methods in tackling cross-corpus SER tasks.
Attention or Convolution: Transformer Encoders in Audio Language Models for Inference Efficiency
Nov 05, 2023In this paper, we show that a simple self-supervised pre-trained audio model can achieve comparable inference efficiency to more complicated pre-trained models with speech transformer encoders. These speech transformers rely on mixing convolutional modules with self-attention modules. They achieve state-of-the-art performance on ASR with top efficiency. We first show that employing these speech transformers as an encoder significantly improves the efficiency of pre-trained audio models as well. However, our study shows that we can achieve comparable efficiency with advanced self-attention solely. We demonstrate that this simpler approach is particularly beneficial with a low-bit weight quantization technique of a neural network to improve efficiency. We hypothesize that it prevents propagating the errors between different quantized modules compared to recent speech transformers mixing quantized convolution and the quantized self-attention modules.
Average Token Delay: A Duration-aware Latency Metric for Simultaneous Translation
Nov 27, 2023Simultaneous translation is a task in which the translation begins before the end of an input speech segment. Its evaluation should be conducted based on latency in addition to quality, and for users, the smallest possible amount of latency is preferable. Most existing metrics measure latency based on the start timings of partial translations and ignore their duration. This means such metrics do not penalize the latency caused by long translation output, which delays the comprehension of users and subsequent translations. In this work, we propose a novel latency evaluation metric for simultaneous translation called \emph{Average Token Delay} (ATD) that focuses on the duration of partial translations. We demonstrate its effectiveness through analyses simulating user-side latency based on Ear-Voice Span (EVS). In our experiment, ATD had the highest correlation with EVS among baseline latency metrics under most conditions.
Overview of the VLSP 2022 -- Abmusu Shared Task: A Data Challenge for Vietnamese Abstractive Multi-document Summarization
Nov 27, 2023This paper reports the overview of the VLSP 2022 - Vietnamese abstractive multi-document summarization (Abmusu) shared task for Vietnamese News. This task is hosted at the 9$^{th}$ annual workshop on Vietnamese Language and Speech Processing (VLSP 2022). The goal of Abmusu shared task is to develop summarization systems that could create abstractive summaries automatically for a set of documents on a topic. The model input is multiple news documents on the same topic, and the corresponding output is a related abstractive summary. In the scope of Abmusu shared task, we only focus on Vietnamese news summarization and build a human-annotated dataset of 1,839 documents in 600 clusters, collected from Vietnamese news in 8 categories. Participated models are evaluated and ranked in terms of \texttt{ROUGE2-F1} score, the most typical evaluation metric for document summarization problem.