 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Wav2vec-based Detection and Severity Level Classification of Dysarthria from Speech
Sep 25, 2023
Automatic detection and severity level classification of dysarthria directly from acoustic speech signals can be used as a tool in medical diagnosis. In this work, the pre-trained wav2vec 2.0 model is studied as a feature extractor to build detection and severity level classification systems for dysarthric speech. The experiments were carried out with the popularly used UA-speech database. In the detection experiments, the results revealed that the best performance was obtained using the embeddings from the first layer of the wav2vec model that yielded an absolute improvement of 1.23% in accuracy compared to the best performing baseline feature (spectrogram). In the studied severity level classification task, the results revealed that the embeddings from the final layer gave an absolute improvement of 10.62% in accuracy compared to the best baseline features (mel-frequency cepstral coefficients).
LanSER: Language-Model Supported Speech Emotion Recognition
Sep 07, 2023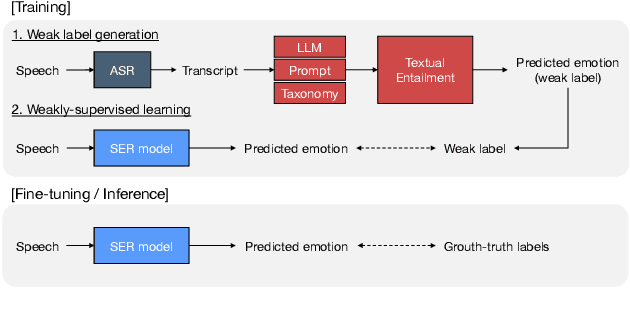


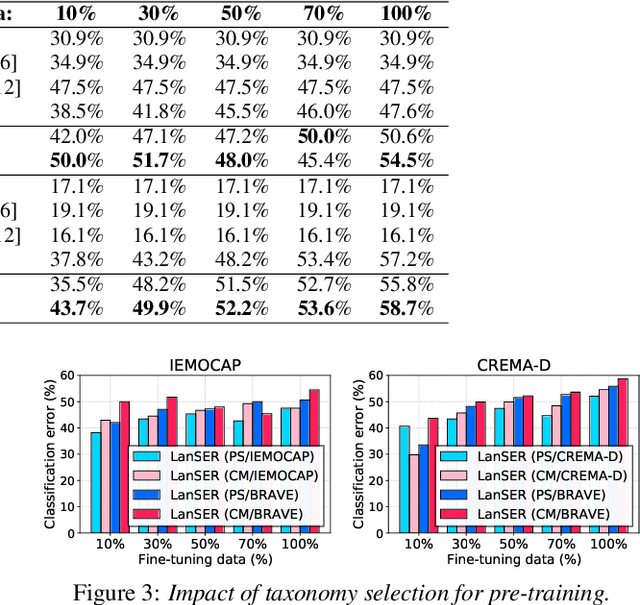
Speech emotion recognition (SER) models typically rely on costly human-labeled data for training, making scaling methods to large speech datasets and nuanced emotion taxonomies difficult. We present LanSER, a method that enables the use of unlabeled data by inferring weak emotion labels via pre-trained large language models through weakly-supervised learning. For inferring weak labels constrained to a taxonomy, we use a textual entailment approach that selects an emotion label with the highest entailment score for a speech transcript extracted via automatic speech recognition. Our experimental results show that models pre-trained on large datasets with this weak supervision outperform other baseline models on standard SER datasets when fine-tuned, and show improved label efficiency. Despite being pre-trained on labels derived only from text, we show that the resulting representations appear to model the prosodic content of speech.
* Presented at INTERSPEECH 2023
Crowdotic: A Privacy-Preserving Hospital Waiting Room Crowd Density Estimation with Non-speech Audio
Sep 20, 2023

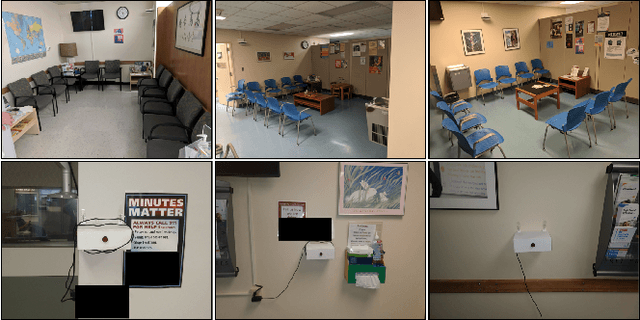
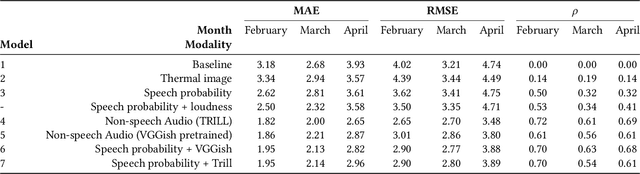
Privacy-preserving crowd density analysis finds application across a wide range of scenarios, substantially enhancing smart building operation and management while upholding privacy expectations in various spaces. We propose a non-speech audio-based approach for crowd analytics, leveraging a transformer-based model. Our results demonstrate that non-speech audio alone can be used to conduct such analysis with remarkable accuracy. To the best of our knowledge, this is the first time when non-speech audio signals are proposed for predicting occupancy. As far as we know, there has been no other similar approach of its kind prior to this. To accomplish this, we deployed our sensor-based platform in the waiting room of a large hospital with IRB approval over a period of several months to capture non-speech audio and thermal images for the training and evaluation of our models. The proposed non-speech-based approach outperformed the thermal camera-based model and all other baselines. In addition to demonstrating superior performance without utilizing speech audio, we conduct further analysis using differential privacy techniques to provide additional privacy guarantees. Overall, our work demonstrates the viability of employing non-speech audio data for accurate occupancy estimation, while also ensuring the exclusion of speech-related content and providing robust privacy protections through differential privacy guarantees.
Noise robust speech emotion recognition with signal-to-noise ratio adapting speech enhancement
Sep 03, 2023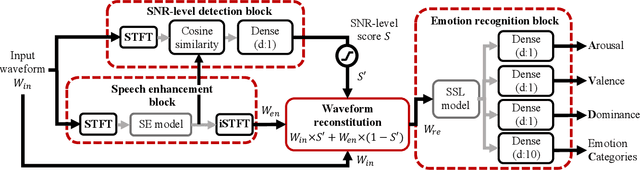

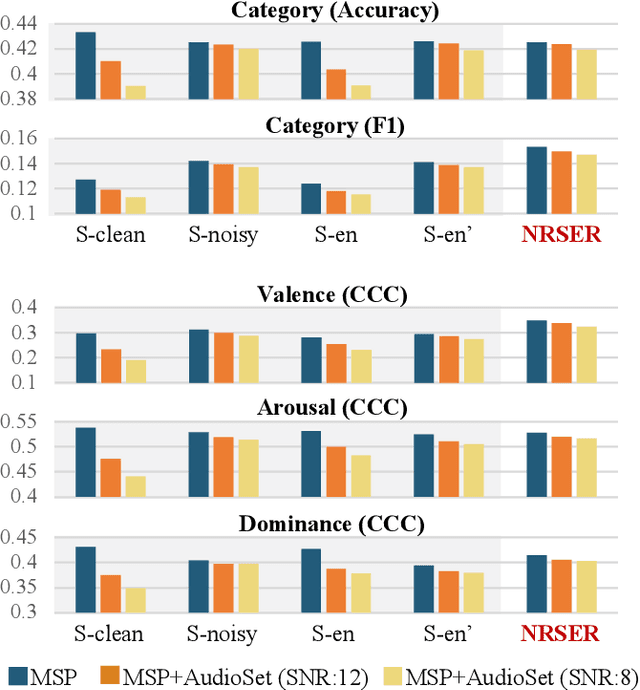
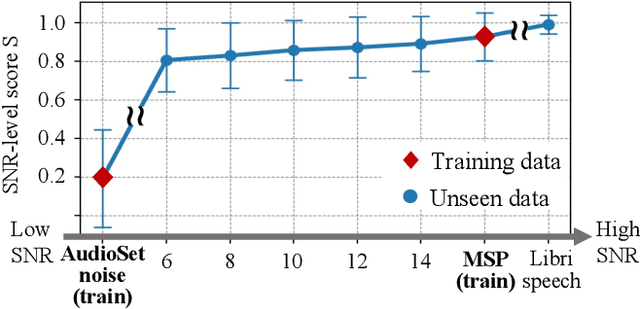
Speech emotion recognition (SER) often experiences reduced performance due to background noise. In addition, making a prediction on signals with only background noise could undermine user trust in the system. In this study, we propose a Noise Robust Speech Emotion Recognition system, NRSER. NRSER employs speech enhancement (SE) to effectively reduce the noise in input signals. Then, the signal-to-noise-ratio (SNR)-level detection structure and waveform reconstitution strategy are introduced to reduce the negative impact of SE on speech signals with no or little background noise. Our experimental results show that NRSER can effectively improve the noise robustness of the SER system, including preventing the system from making emotion recognition on signals consisting solely of background noise. Moreover, the proposed SNR-level detection structure can be used individually for tasks such as data selection.
Bridging the Gaps of Both Modality and Language: Synchronous Bilingual CTC for Speech Translation and Speech Recognition
Sep 21, 2023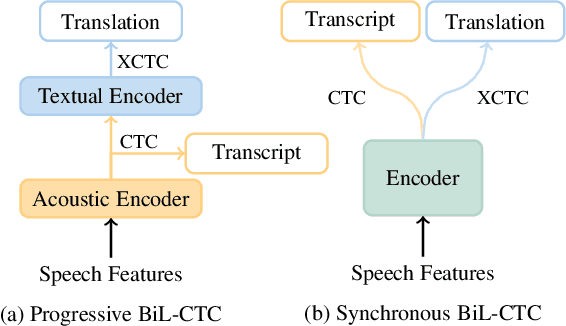
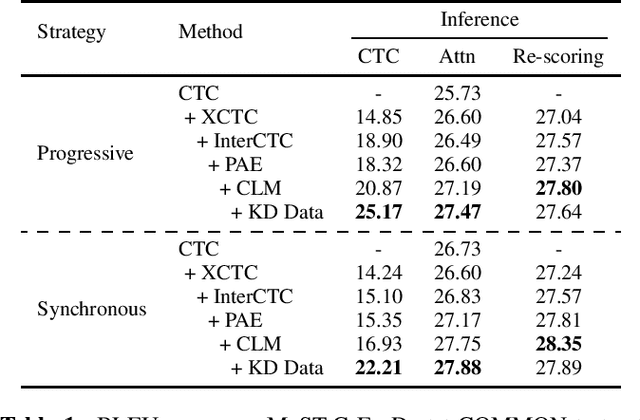
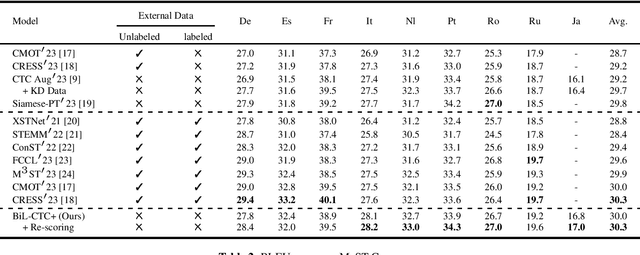
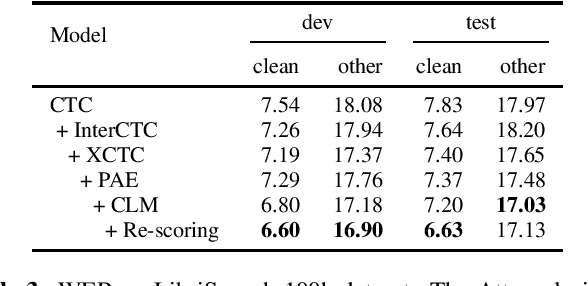
In this study, we present synchronous bilingual Connectionist Temporal Classification (CTC), an innovative framework that leverages dual CTC to bridge the gaps of both modality and language in the speech translation (ST) task. Utilizing transcript and translation as concurrent objectives for CTC, our model bridges the gap between audio and text as well as between source and target languages. Building upon the recent advances in CTC application, we develop an enhanced variant, BiL-CTC+, that establishes new state-of-the-art performances on the MuST-C ST benchmarks under resource-constrained scenarios. Intriguingly, our method also yields significant improvements in speech recognition performance, revealing the effect of cross-lingual learning on transcription and demonstrating its broad applicability. The source code is available at https://github.com/xuchennlp/S2T.
Beyond Boundaries: A Comprehensive Survey of Transferable Attacks on AI Systems
Nov 20, 2023Artificial Intelligence (AI) systems such as autonomous vehicles, facial recognition, and speech recognition systems are increasingly integrated into our daily lives. However, despite their utility, these AI systems are vulnerable to a wide range of attacks such as adversarial, backdoor, data poisoning, membership inference, model inversion, and model stealing attacks. In particular, numerous attacks are designed to target a particular model or system, yet their effects can spread to additional targets, referred to as transferable attacks. Although considerable efforts have been directed toward developing transferable attacks, a holistic understanding of the advancements in transferable attacks remains elusive. In this paper, we comprehensively explore learning-based attacks from the perspective of transferability, particularly within the context of cyber-physical security. We delve into different domains -- the image, text, graph, audio, and video domains -- to highlight the ubiquitous and pervasive nature of transferable attacks. This paper categorizes and reviews the architecture of existing attacks from various viewpoints: data, process, model, and system. We further examine the implications of transferable attacks in practical scenarios such as autonomous driving, speech recognition, and large language models (LLMs). Additionally, we outline the potential research directions to encourage efforts in exploring the landscape of transferable attacks. This survey offers a holistic understanding of the prevailing transferable attacks and their impacts across different domains.
PARK: Parkinson's Analysis with Remote Kinetic-tasks
Nov 21, 2023We present a web-based framework to screen for Parkinson's disease (PD) by allowing users to perform neurological tests in their homes. Our web framework guides the users to complete three tasks involving speech, facial expression, and finger movements. The task videos are analyzed to classify whether the users show signs of PD. We present the results in an easy-to-understand manner, along with personalized resources to further access to treatment and care. Our framework is accessible by any major web browser, improving global access to neurological care.
Continuous Modeling of the Denoising Process for Speech Enhancement Based on Deep Learning
Sep 17, 2023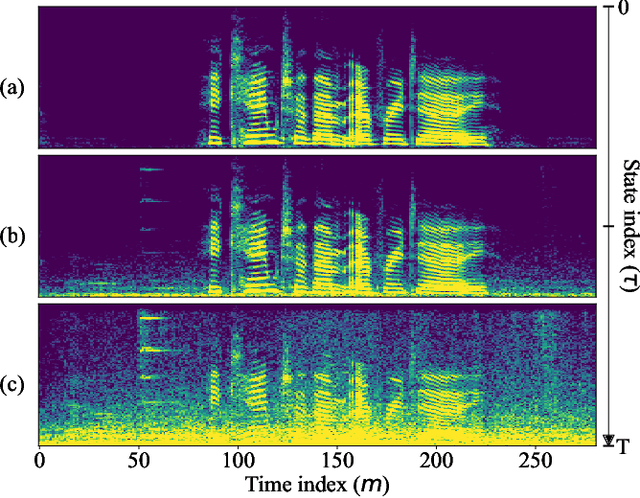
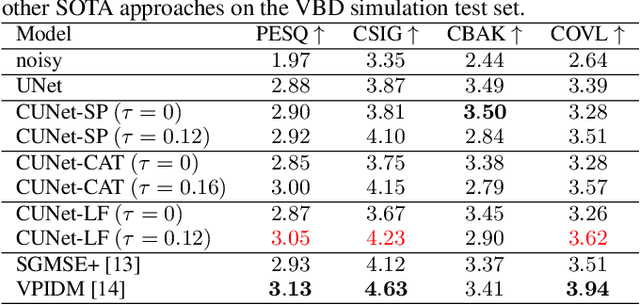
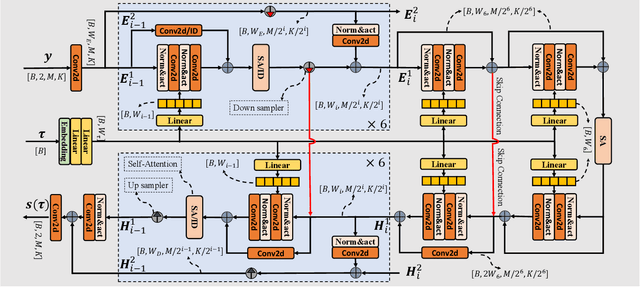
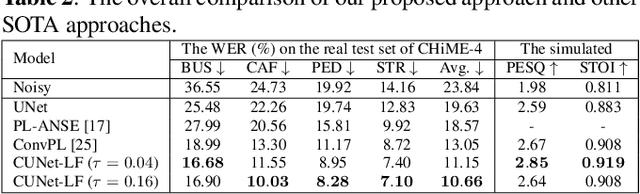
In this paper, we explore a continuous modeling approach for deep-learning-based speech enhancement, focusing on the denoising process. We use a state variable to indicate the denoising process. The starting state is noisy speech and the ending state is clean speech. The noise component in the state variable decreases with the change of the state index until the noise component is 0. During training, a UNet-like neural network learns to estimate every state variable sampled from the continuous denoising process. In testing, we introduce a controlling factor as an embedding, ranging from zero to one, to the neural network, allowing us to control the level of noise reduction. This approach enables controllable speech enhancement and is adaptable to various application scenarios. Experimental results indicate that preserving a small amount of noise in the clean target benefits speech enhancement, as evidenced by improvements in both objective speech measures and automatic speech recognition performance.
Synthetic Speaking Children -- Why We Need Them and How to Make Them
Nov 08, 2023Contemporary Human Computer Interaction (HCI) research relies primarily on neural network models for machine vision and speech understanding of a system user. Such models require extensively annotated training datasets for optimal performance and when building interfaces for users from a vulnerable population such as young children, GDPR introduces significant complexities in data collection, management, and processing. Motivated by the training needs of an Edge AI smart toy platform this research explores the latest advances in generative neural technologies and provides a working proof of concept of a controllable data generation pipeline for speech driven facial training data at scale. In this context, we demonstrate how StyleGAN2 can be finetuned to create a gender balanced dataset of children's faces. This dataset includes a variety of controllable factors such as facial expressions, age variations, facial poses, and even speech-driven animations with realistic lip synchronization. By combining generative text to speech models for child voice synthesis and a 3D landmark based talking heads pipeline, we can generate highly realistic, entirely synthetic, talking child video clips. These video clips can provide valuable, and controllable, synthetic training data for neural network models, bridging the gap when real data is scarce or restricted due to privacy regulations.
Audio-Visual Active Speaker Extraction for Sparsely Overlapped Multi-talker Speech
Sep 15, 2023Target speaker extraction aims to extract the speech of a specific speaker from a multi-talker mixture as specified by an auxiliary reference. Most studies focus on the scenario where the target speech is highly overlapped with the interfering speech. However, this scenario only accounts for a small percentage of real-world conversations. In this paper, we aim at the sparsely overlapped scenarios in which the auxiliary reference needs to perform two tasks simultaneously: detect the activity of the target speaker and disentangle the active speech from any interfering speech. We propose an audio-visual speaker extraction model named ActiveExtract, which leverages speaking activity from audio-visual active speaker detection (ASD). The ASD directly provides the frame-level activity of the target speaker, while its intermediate feature representation is trained to discriminate speech-lip synchronization that could be used for speaker disentanglement. Experimental results show our model outperforms baselines across various overlapping ratios, achieving an average improvement of more than 4 dB in terms of SI-SNR.