 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
LAE-ST-MoE: Boosted Language-Aware Encoder Using Speech Translation Auxiliary Task for E2E Code-switching ASR
Oct 07, 2023
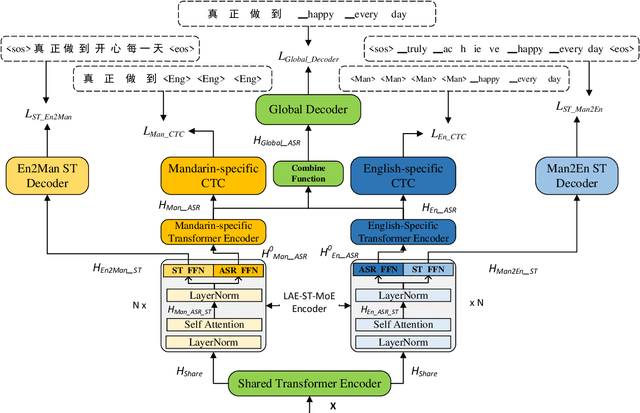
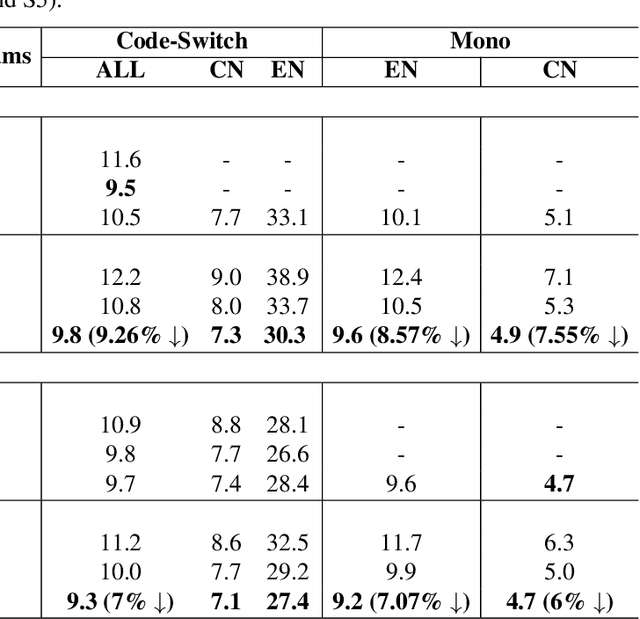
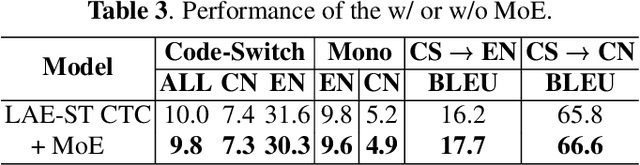
Recently, to mitigate the confusion between different languages in code-switching (CS) automatic speech recognition (ASR), the conditionally factorized models, such as the language-aware encoder (LAE), explicitly disregard the contextual information between different languages. However, this information may be helpful for ASR modeling. To alleviate this issue, we propose the LAE-ST-MoE framework. It incorporates speech translation (ST) tasks into LAE and utilizes ST to learn the contextual information between different languages. It introduces a task-based mixture of expert modules, employing separate feed-forward networks for the ASR and ST tasks. Experimental results on the ASRU 2019 Mandarin-English CS challenge dataset demonstrate that, compared to the LAE-based CTC, the LAE-ST-MoE model achieves a 9.26% mix error reduction on the CS test with the same decoding parameter. Moreover, the well-trained LAE-ST-MoE model can perform ST tasks from CS speech to Mandarin or English text.
Enhancing Code-switching Speech Recognition with Interactive Language Biases
Sep 29, 2023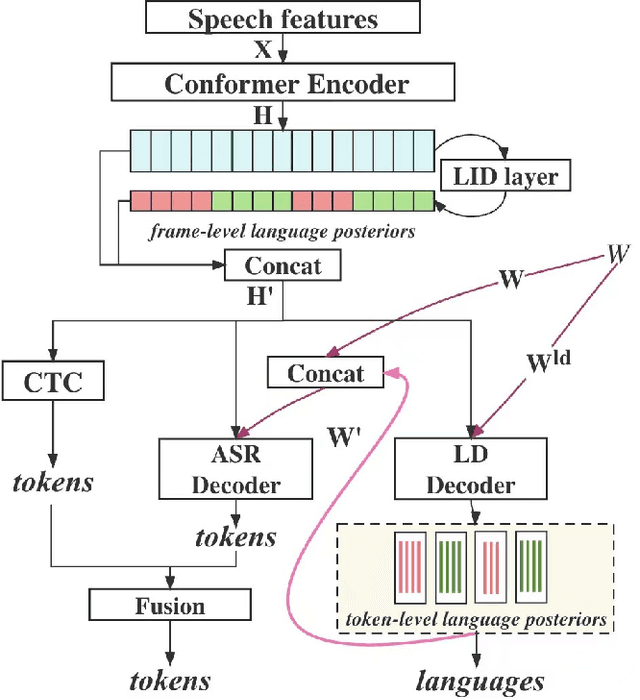

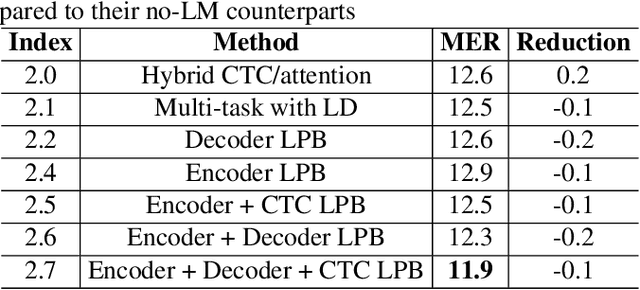
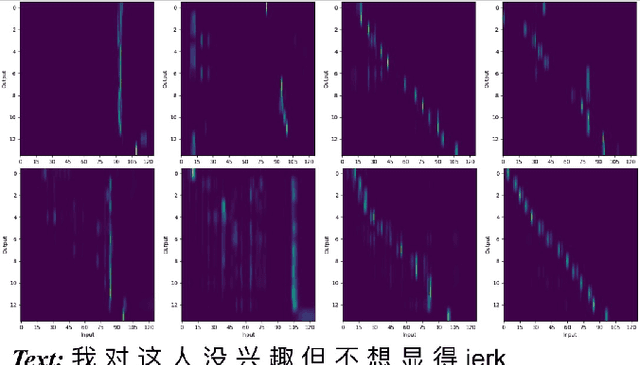
Languages usually switch within a multilingual speech signal, especially in a bilingual society. This phenomenon is referred to as code-switching (CS), making automatic speech recognition (ASR) challenging under a multilingual scenario. We propose to improve CS-ASR by biasing the hybrid CTC/attention ASR model with multi-level language information comprising frame- and token-level language posteriors. The interaction between various resolutions of language biases is subsequently explored in this work. We conducted experiments on datasets from the ASRU 2019 code-switching challenge. Compared to the baseline, the proposed interactive language biases (ILB) method achieves higher performance and ablation studies highlight the effects of different language biases and their interactions. In addition, the results presented indicate that language bias implicitly enhances internal language modeling, leading to performance degradation after employing an external language model.
OpenVoice: Versatile Instant Voice Cloning
Dec 03, 2023We introduce OpenVoice, a versatile voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field: 1) Flexible Voice Style Control. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. The voice styles are not directly copied from and constrained by the style of the reference speaker. Previous approaches lacked the ability to flexibly manipulate voice styles after cloning. 2) Zero-Shot Cross-Lingual Voice Cloning. OpenVoice achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set. Unlike previous approaches, which typically require extensive massive-speaker multi-lingual (MSML) dataset for all languages, OpenVoice can clone voices into a new language without any massive-speaker training data for that language. OpenVoice is also computationally efficient, costing tens of times less than commercially available APIs that offer even inferior performance. To foster further research in the field, we have made the source code and trained model publicly accessible. We also provide qualitative results in our demo website. Prior to its public release, our internal version of OpenVoice was used tens of millions of times by users worldwide between May and October 2023, serving as the backend of MyShell.ai.
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Sep 30, 2023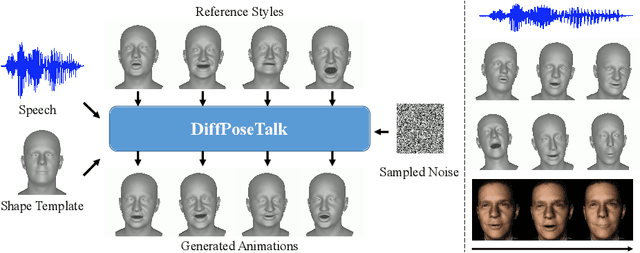
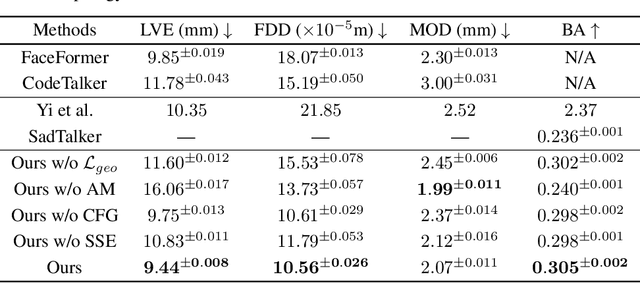
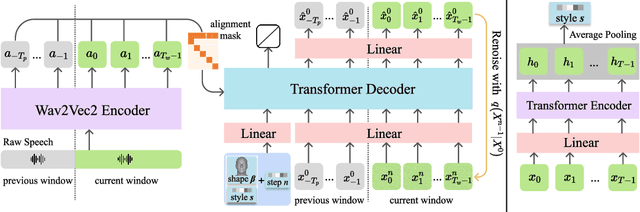
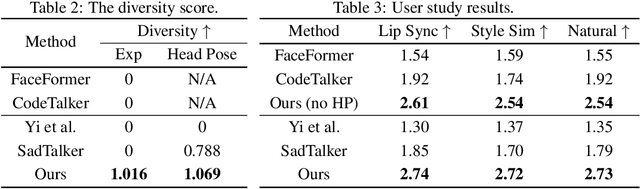
The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.
Long-Form Speech Translation through Segmentation with Finite-State Decoding Constraints on Large Language Models
Oct 23, 2023
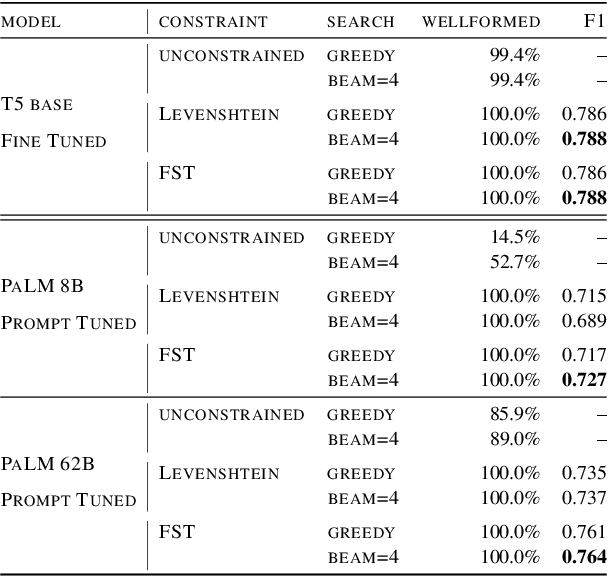

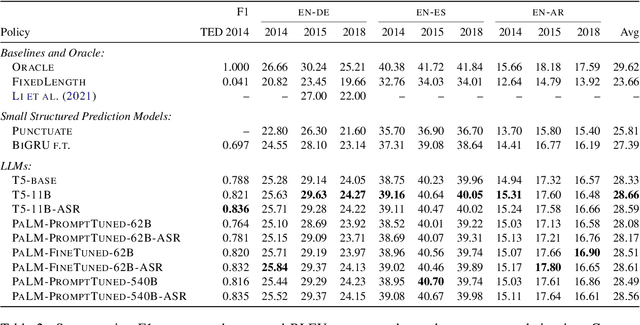
One challenge in speech translation is that plenty of spoken content is long-form, but short units are necessary for obtaining high-quality translations. To address this mismatch, we adapt large language models (LLMs) to split long ASR transcripts into segments that can be independently translated so as to maximize the overall translation quality. We overcome the tendency of hallucination in LLMs by incorporating finite-state constraints during decoding; these eliminate invalid outputs without requiring additional training. We discover that LLMs are adaptable to transcripts containing ASR errors through prompt-tuning or fine-tuning. Relative to a state-of-the-art automatic punctuation baseline, our best LLM improves the average BLEU by 2.9 points for English-German, English-Spanish, and English-Arabic TED talk translation in 9 test sets, just by improving segmentation.
DiariST: Streaming Speech Translation with Speaker Diarization
Sep 14, 2023End-to-end speech translation (ST) for conversation recordings involves several under-explored challenges such as speaker diarization (SD) without accurate word time stamps and handling of overlapping speech in a streaming fashion. In this work, we propose DiariST, the first streaming ST and SD solution. It is built upon a neural transducer-based streaming ST system and integrates token-level serialized output training and t-vector, which were originally developed for multi-talker speech recognition. Due to the absence of evaluation benchmarks in this area, we develop a new evaluation dataset, DiariST-AliMeeting, by translating the reference Chinese transcriptions of the AliMeeting corpus into English. We also propose new metrics, called speaker-agnostic BLEU and speaker-attributed BLEU, to measure the ST quality while taking SD accuracy into account. Our system achieves a strong ST and SD capability compared to offline systems based on Whisper, while performing streaming inference for overlapping speech. To facilitate the research in this new direction, we release the evaluation data, the offline baseline systems, and the evaluation code.
Towards Universal Speech Discrete Tokens: A Case Study for ASR and TTS
Sep 14, 2023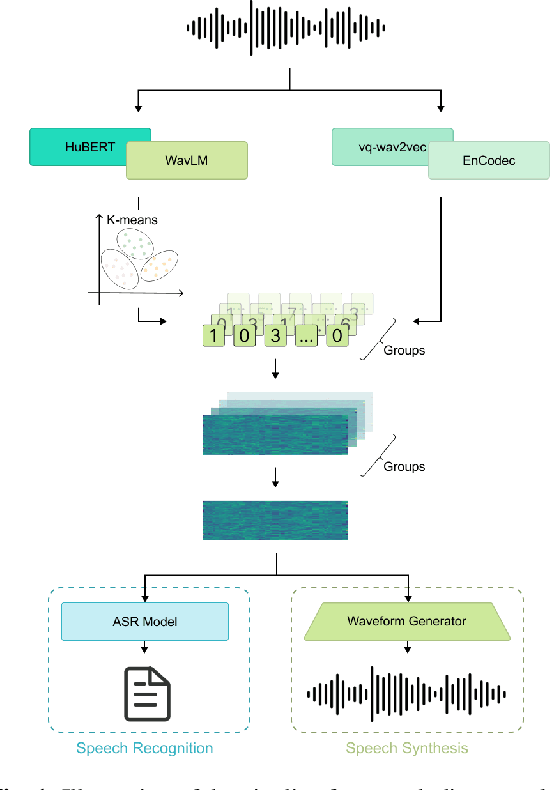
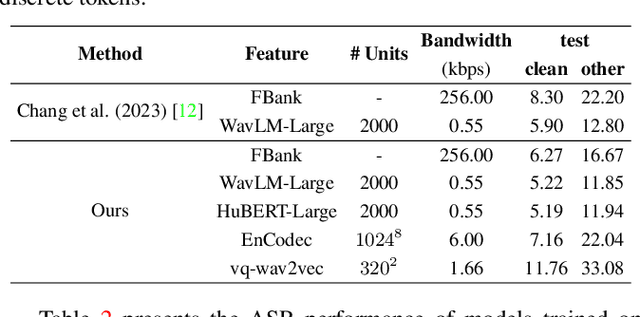

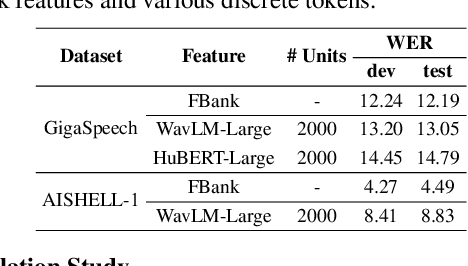
Self-supervised learning (SSL) proficiency in speech-related tasks has driven research into utilizing discrete tokens for speech tasks like recognition and translation, which offer lower storage requirements and great potential to employ natural language processing techniques. However, these studies, mainly single-task focused, faced challenges like overfitting and performance degradation in speech recognition tasks, often at the cost of sacrificing performance in multi-task scenarios. This study presents a comprehensive comparison and optimization of discrete tokens generated by various leading SSL models in speech recognition and synthesis tasks. We aim to explore the universality of speech discrete tokens across multiple speech tasks. Experimental results demonstrate that discrete tokens achieve comparable results against systems trained on FBank features in speech recognition tasks and outperform mel-spectrogram features in speech synthesis in subjective and objective metrics. These findings suggest that universal discrete tokens have enormous potential in various speech-related tasks. Our work is open-source and publicly available to facilitate research in this direction.
Long-Form End-to-End Speech Translation via Latent Alignment Segmentation
Sep 20, 2023Current simultaneous speech translation models can process audio only up to a few seconds long. Contemporary datasets provide an oracle segmentation into sentences based on human-annotated transcripts and translations. However, the segmentation into sentences is not available in the real world. Current speech segmentation approaches either offer poor segmentation quality or have to trade latency for quality. In this paper, we propose a novel segmentation approach for a low-latency end-to-end speech translation. We leverage the existing speech translation encoder-decoder architecture with ST CTC and show that it can perform the segmentation task without supervision or additional parameters. To the best of our knowledge, our method is the first that allows an actual end-to-end simultaneous speech translation, as the same model is used for translation and segmentation at the same time. On a diverse set of language pairs and in- and out-of-domain data, we show that the proposed approach achieves state-of-the-art quality at no additional computational cost.
Attention or Convolution: Transformer Encoders in Audio Language Models for Inference Efficiency
Nov 05, 2023In this paper, we show that a simple self-supervised pre-trained audio model can achieve comparable inference efficiency to more complicated pre-trained models with speech transformer encoders. These speech transformers rely on mixing convolutional modules with self-attention modules. They achieve state-of-the-art performance on ASR with top efficiency. We first show that employing these speech transformers as an encoder significantly improves the efficiency of pre-trained audio models as well. However, our study shows that we can achieve comparable efficiency with advanced self-attention solely. We demonstrate that this simpler approach is particularly beneficial with a low-bit weight quantization technique of a neural network to improve efficiency. We hypothesize that it prevents propagating the errors between different quantized modules compared to recent speech transformers mixing quantized convolution and the quantized self-attention modules.
Fast Word Error Rate Estimation Using Self-Supervised Representations For Speech And Text
Oct 12, 2023The quality of automatic speech recognition (ASR) is typically measured by word error rate (WER). WER estimation is a task aiming to predict the WER of an ASR system, given a speech utterance and a transcription. This task has gained increasing attention while advanced ASR systems are trained on large amounts of data. In this case, WER estimation becomes necessary in many scenarios, for example, selecting training data with unknown transcription quality or estimating the testing performance of an ASR system without ground truth transcriptions. Facing large amounts of data, the computation efficiency of a WER estimator becomes essential in practical applications. However, previous works usually did not consider it as a priority. In this paper, a Fast WER estimator (Fe-WER) using self-supervised learning representation (SSLR) is introduced. The estimator is built upon SSLR aggregated by average pooling. The results show that Fe-WER outperformed the e-WER3 baseline relatively by 19.69% and 7.16% on Ted-Lium3 in both evaluation metrics of root mean square error and Pearson correlation coefficient, respectively. Moreover, the estimation weighted by duration was 10.43% when the target was 10.88%. Lastly, the inference speed was about 4x in terms of a real-time factor.