 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised Accent Adaptation Through Masked Language Model Correction Of Discrete Self-Supervised Speech Units
Sep 25, 2023

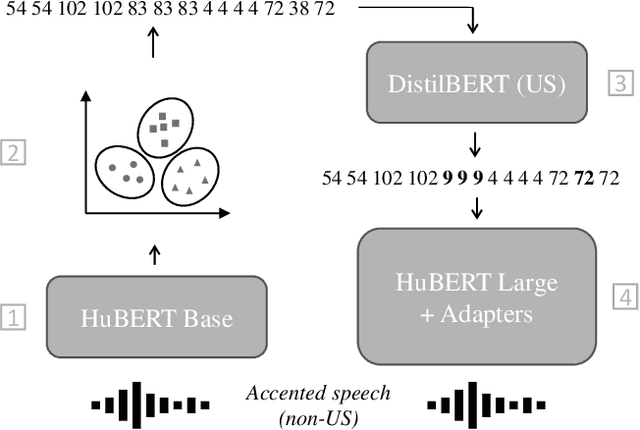


Self-supervised pre-trained speech models have strongly improved speech recognition, yet they are still sensitive to domain shifts and accented or atypical speech. Many of these models rely on quantisation or clustering to learn discrete acoustic units. We propose to correct the discovered discrete units for accented speech back to a standard pronunciation in an unsupervised manner. A masked language model is trained on discrete units from a standard accent and iteratively corrects an accented token sequence by masking unexpected cluster sequences and predicting their common variant. Small accent adapter blocks are inserted in the pre-trained model and fine-tuned by predicting the corrected clusters, which leads to an increased robustness of the pre-trained model towards a target accent, and this without supervision. We are able to improve a state-of-the-art HuBERT Large model on a downstream accented speech recognition task by altering the training regime with the proposed method.
The VoiceMOS Challenge 2023: Zero-shot Subjective Speech Quality Prediction for Multiple Domains
Oct 05, 2023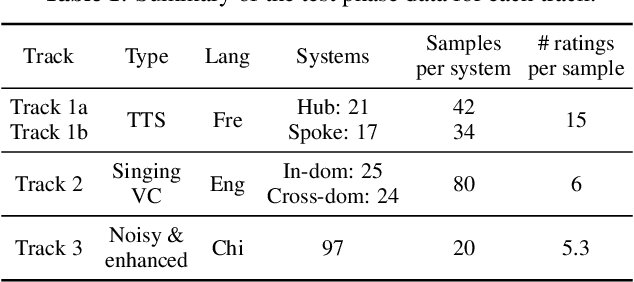
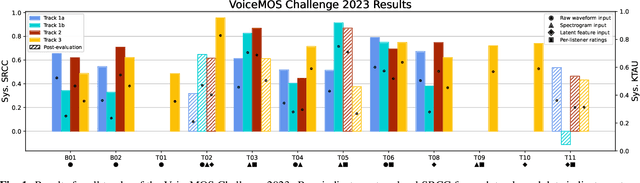
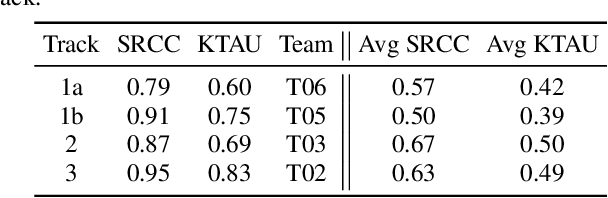
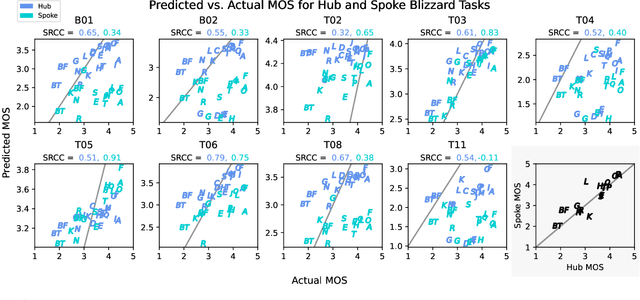
We present the second edition of the VoiceMOS Challenge, a scientific event that aims to promote the study of automatic prediction of the mean opinion score (MOS) of synthesized and processed speech. This year, we emphasize real-world and challenging zero-shot out-of-domain MOS prediction with three tracks for three different voice evaluation scenarios. Ten teams from industry and academia in seven different countries participated. Surprisingly, we found that the two sub-tracks of French text-to-speech synthesis had large differences in their predictability, and that singing voice-converted samples were not as difficult to predict as we had expected. Use of diverse datasets and listener information during training appeared to be successful approaches.
LAE-ST-MoE: Boosted Language-Aware Encoder Using Speech Translation Auxiliary Task for E2E Code-switching ASR
Oct 07, 2023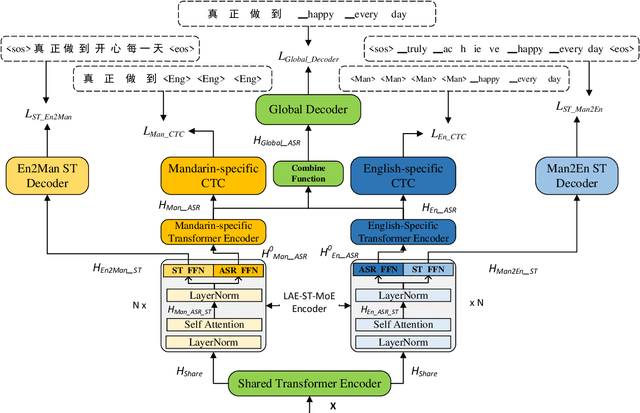
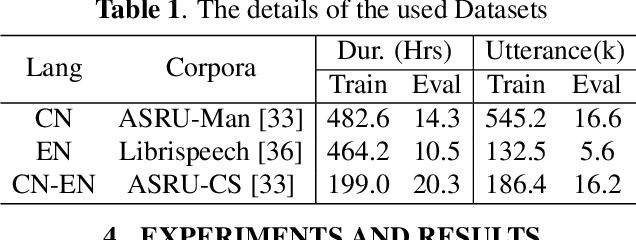
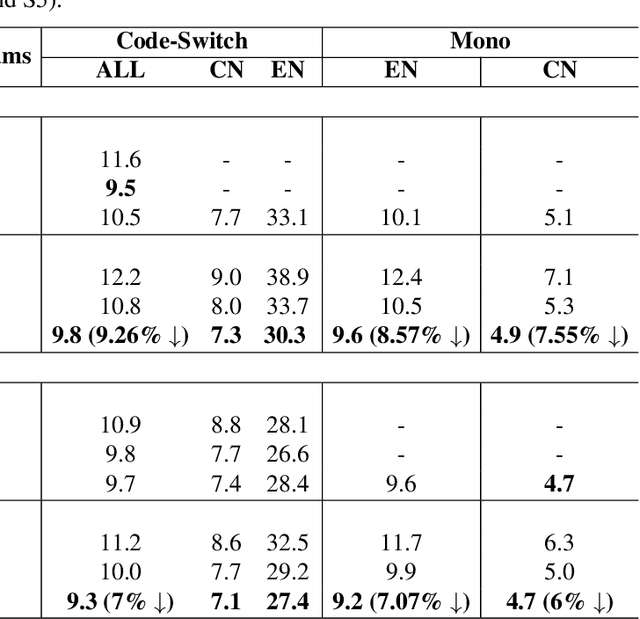
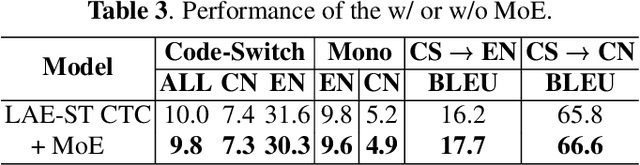
Recently, to mitigate the confusion between different languages in code-switching (CS) automatic speech recognition (ASR), the conditionally factorized models, such as the language-aware encoder (LAE), explicitly disregard the contextual information between different languages. However, this information may be helpful for ASR modeling. To alleviate this issue, we propose the LAE-ST-MoE framework. It incorporates speech translation (ST) tasks into LAE and utilizes ST to learn the contextual information between different languages. It introduces a task-based mixture of expert modules, employing separate feed-forward networks for the ASR and ST tasks. Experimental results on the ASRU 2019 Mandarin-English CS challenge dataset demonstrate that, compared to the LAE-based CTC, the LAE-ST-MoE model achieves a 9.26% mix error reduction on the CS test with the same decoding parameter. Moreover, the well-trained LAE-ST-MoE model can perform ST tasks from CS speech to Mandarin or English text.
Enhancing Code-switching Speech Recognition with Interactive Language Biases
Sep 29, 2023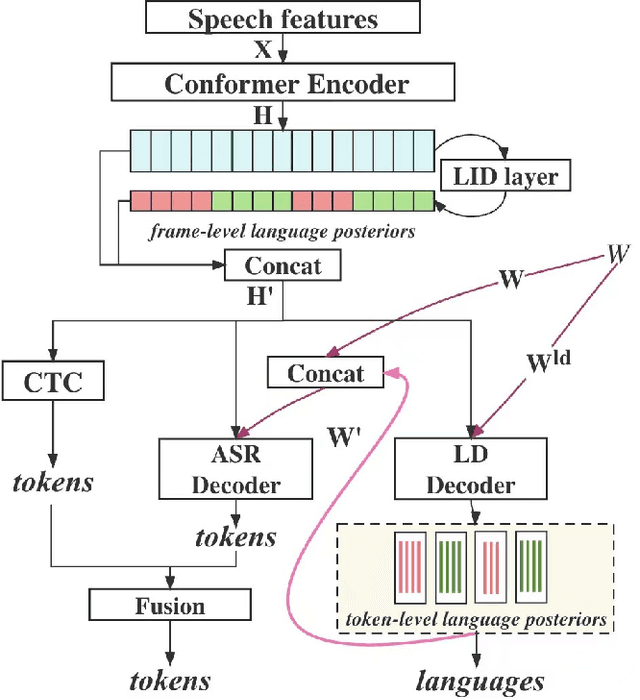

Languages usually switch within a multilingual speech signal, especially in a bilingual society. This phenomenon is referred to as code-switching (CS), making automatic speech recognition (ASR) challenging under a multilingual scenario. We propose to improve CS-ASR by biasing the hybrid CTC/attention ASR model with multi-level language information comprising frame- and token-level language posteriors. The interaction between various resolutions of language biases is subsequently explored in this work. We conducted experiments on datasets from the ASRU 2019 code-switching challenge. Compared to the baseline, the proposed interactive language biases (ILB) method achieves higher performance and ablation studies highlight the effects of different language biases and their interactions. In addition, the results presented indicate that language bias implicitly enhances internal language modeling, leading to performance degradation after employing an external language model.
Instructing Hierarchical Tasks to Robots by Verbal Commands
Nov 30, 2023Natural language is an effective tool for communication, as information can be expressed in different ways and at different levels of complexity. Verbal commands, utilized for instructing robot tasks, can therefor replace traditional robot programming techniques, and provide a more expressive means to assign actions and enable collaboration. However, the challenge of utilizing speech for robot programming is how actions and targets can be grounded to physical entities in the world. In addition, to be time-efficient, a balance needs to be found between fine- and course-grained commands and natural language phrases. In this work we provide a framework for instructing tasks to robots by verbal commands. The framework includes functionalities for single commands to actions and targets, as well as longer-term sequences of actions, thereby providing a hierarchical structure to the robot tasks. Experimental evaluation demonstrates the functionalities of the framework by human collaboration with a robot in different tasks, with different levels of complexity. The tools are provided open-source at https://petim44.github.io/voice-jogger/
Weak Alignment Supervision from Hybrid Model Improves End-to-end ASR
Nov 30, 2023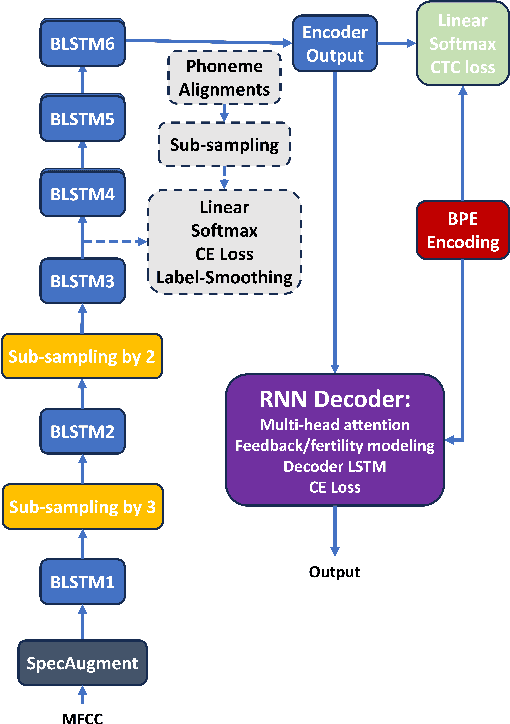
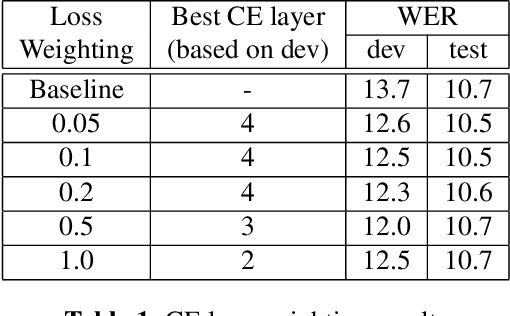
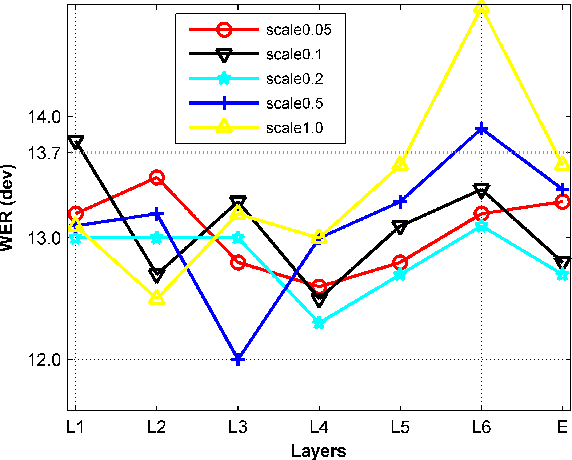

In this paper, we aim to create weak alignment supervision from an existing hybrid system to aid the end-to-end modeling of automatic speech recognition. Towards this end, we use the existing hybrid ASR system to produce triphone alignments of the training audios. We then create a cross-entropy loss at a certain layer of the encoder using the derived alignments. In contrast to the general one-hot cross-entropy losses, here we use a cross-entropy loss with a label smoothing parameter to regularize the supervision. As a comparison, we also conduct the experiments with one-hot cross-entropy losses and CTC losses with loss weighting. The results show that placing the weak alignment supervision with the label smoothing parameter of 0.5 at the third encoder layer outperforms the other two approaches and leads to about 5\% relative WER reduction on the TED-LIUM 2 dataset over the baseline. We see similar improvements when applying the method out-of-the-box on a Tagalog end-to-end ASR system.
On the Relevance of Phoneme Duration Variability of Synthesized Training Data for Automatic Speech Recognition
Oct 12, 2023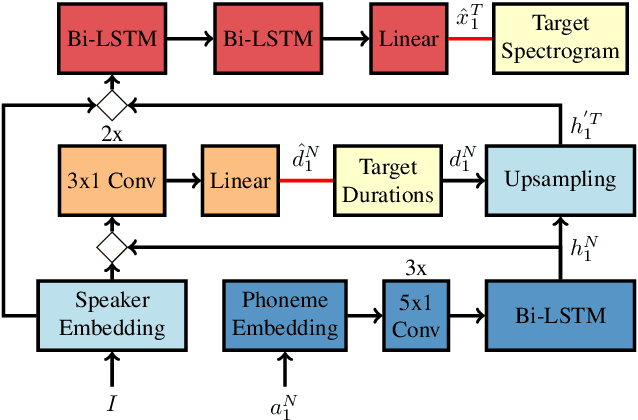
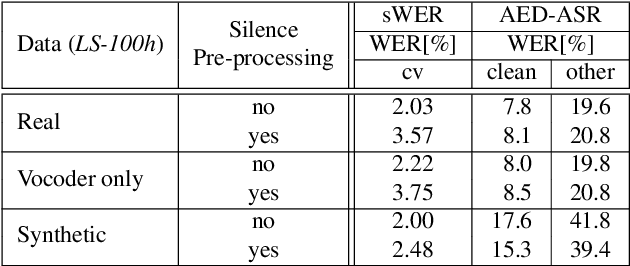
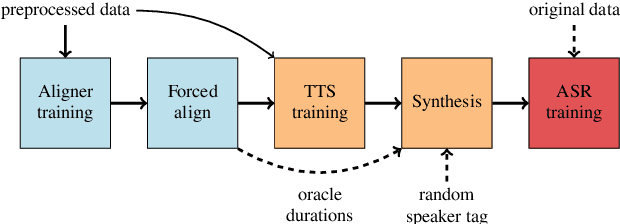
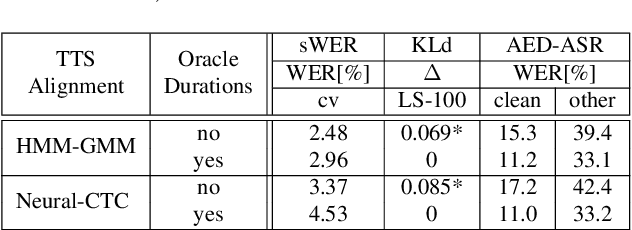
Synthetic data generated by text-to-speech (TTS) systems can be used to improve automatic speech recognition (ASR) systems in low-resource or domain mismatch tasks. It has been shown that TTS-generated outputs still do not have the same qualities as real data. In this work we focus on the temporal structure of synthetic data and its relation to ASR training. By using a novel oracle setup we show how much the degradation of synthetic data quality is influenced by duration modeling in non-autoregressive (NAR) TTS. To get reference phoneme durations we use two common alignment methods, a hidden Markov Gaussian-mixture model (HMM-GMM) aligner and a neural connectionist temporal classification (CTC) aligner. Using a simple algorithm based on random walks we shift phoneme duration distributions of the TTS system closer to real durations, resulting in an improvement of an ASR system using synthetic data in a semi-supervised setting.
DiariST: Streaming Speech Translation with Speaker Diarization
Sep 14, 2023End-to-end speech translation (ST) for conversation recordings involves several under-explored challenges such as speaker diarization (SD) without accurate word time stamps and handling of overlapping speech in a streaming fashion. In this work, we propose DiariST, the first streaming ST and SD solution. It is built upon a neural transducer-based streaming ST system and integrates token-level serialized output training and t-vector, which were originally developed for multi-talker speech recognition. Due to the absence of evaluation benchmarks in this area, we develop a new evaluation dataset, DiariST-AliMeeting, by translating the reference Chinese transcriptions of the AliMeeting corpus into English. We also propose new metrics, called speaker-agnostic BLEU and speaker-attributed BLEU, to measure the ST quality while taking SD accuracy into account. Our system achieves a strong ST and SD capability compared to offline systems based on Whisper, while performing streaming inference for overlapping speech. To facilitate the research in this new direction, we release the evaluation data, the offline baseline systems, and the evaluation code.
Towards Universal Speech Discrete Tokens: A Case Study for ASR and TTS
Sep 14, 2023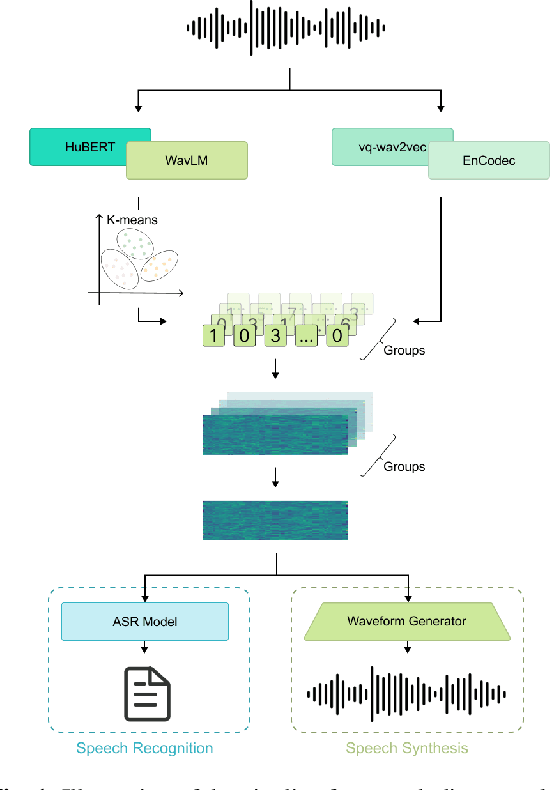
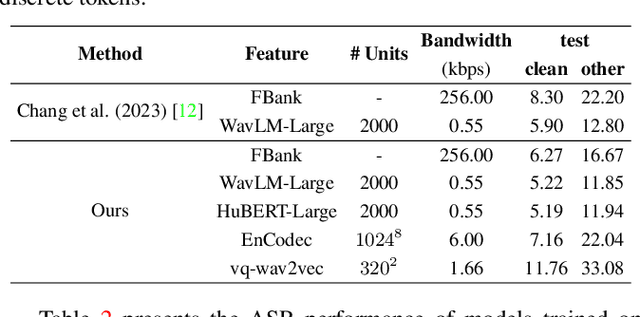

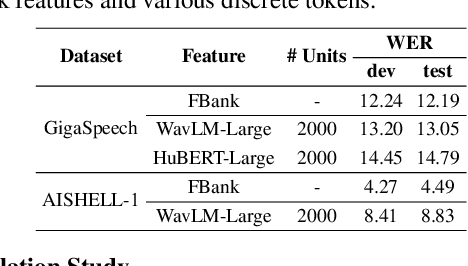
Self-supervised learning (SSL) proficiency in speech-related tasks has driven research into utilizing discrete tokens for speech tasks like recognition and translation, which offer lower storage requirements and great potential to employ natural language processing techniques. However, these studies, mainly single-task focused, faced challenges like overfitting and performance degradation in speech recognition tasks, often at the cost of sacrificing performance in multi-task scenarios. This study presents a comprehensive comparison and optimization of discrete tokens generated by various leading SSL models in speech recognition and synthesis tasks. We aim to explore the universality of speech discrete tokens across multiple speech tasks. Experimental results demonstrate that discrete tokens achieve comparable results against systems trained on FBank features in speech recognition tasks and outperform mel-spectrogram features in speech synthesis in subjective and objective metrics. These findings suggest that universal discrete tokens have enormous potential in various speech-related tasks. Our work is open-source and publicly available to facilitate research in this direction.
LC4SV: A Denoising Framework Learning to Compensate for Unseen Speaker Verification Models
Nov 28, 2023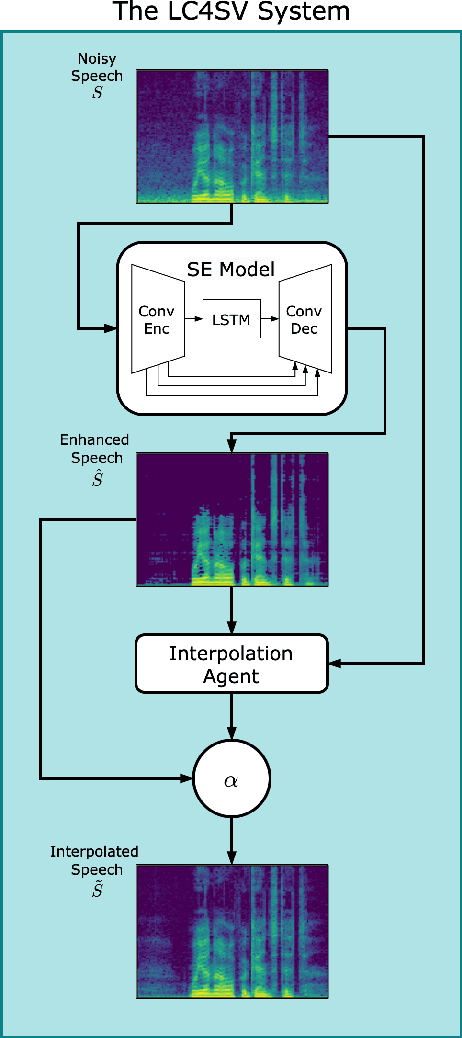
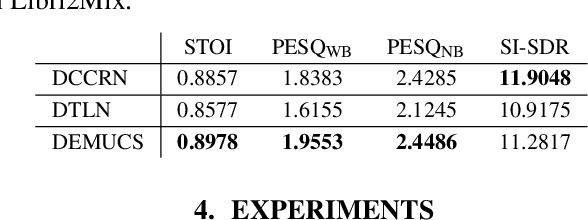
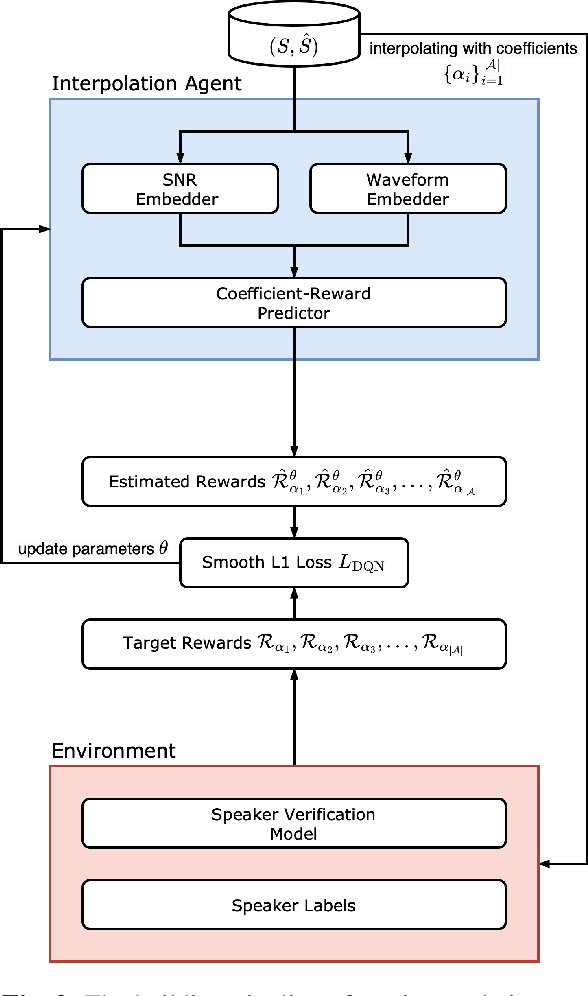
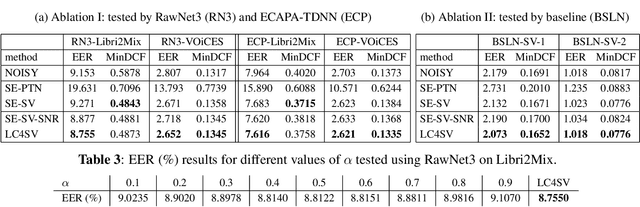
The performance of speaker verification (SV) models may drop dramatically in noisy environments. A speech enhancement (SE) module can be used as a front-end strategy. However, existing SE methods may fail to bring performance improvements to downstream SV systems due to artifacts in the predicted signals of SE models. To compensate for artifacts, we propose a generic denoising framework named LC4SV, which can serve as a pre-processor for various unknown downstream SV models. In LC4SV, we employ a learning-based interpolation agent to automatically generate the appropriate coefficients between the enhanced signal and its noisy input to improve SV performance in noisy environments. Our experimental results demonstrate that LC4SV consistently improves the performance of various unseen SV systems. To the best of our knowledge, this work is the first attempt to develop a learning-based interpolation scheme aiming at improving SV performance in noisy environments.