 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
The VoiceMOS Challenge 2023: Zero-shot Subjective Speech Quality Prediction for Multiple Domains
Oct 07, 2023
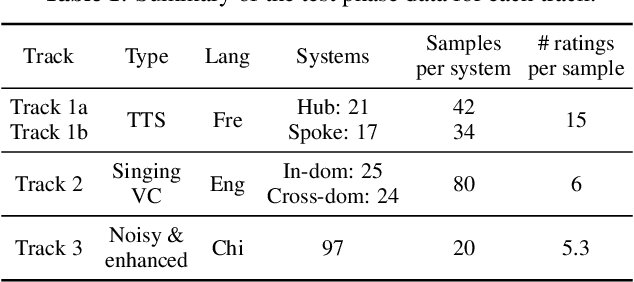
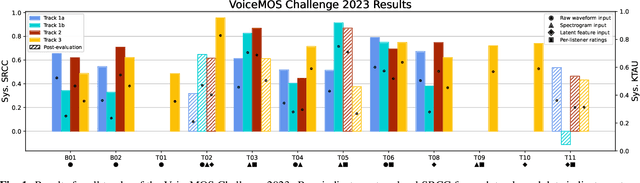
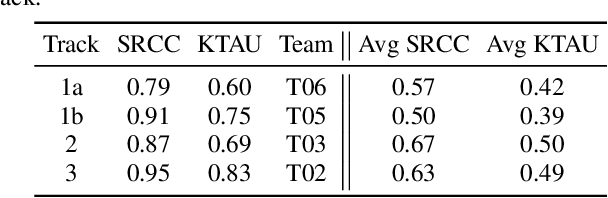
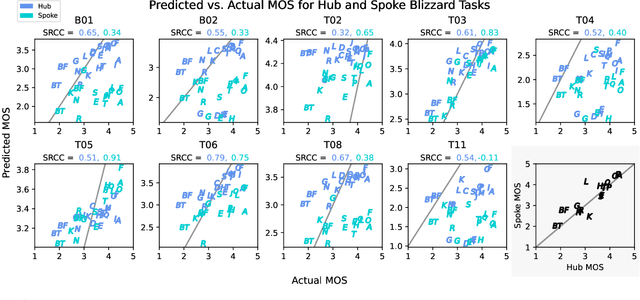
We present the second edition of the VoiceMOS Challenge, a scientific event that aims to promote the study of automatic prediction of the mean opinion score (MOS) of synthesized and processed speech. This year, we emphasize real-world and challenging zero-shot out-of-domain MOS prediction with three tracks for three different voice evaluation scenarios. Ten teams from industry and academia in seven different countries participated. Surprisingly, we found that the two sub-tracks of French text-to-speech synthesis had large differences in their predictability, and that singing voice-converted samples were not as difficult to predict as we had expected. Use of diverse datasets and listener information during training appeared to be successful approaches.
GRASS: Unified Generation Model for Speech-to-Semantic Tasks
Sep 11, 2023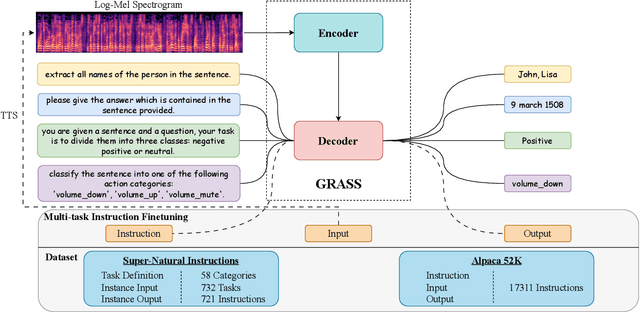
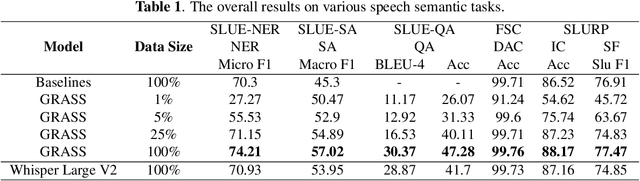

This paper explores the instruction fine-tuning technique for speech-to-semantic tasks by introducing a unified end-to-end (E2E) framework that generates target text conditioned on a task-related prompt for audio data. We pre-train the model using large and diverse data, where instruction-speech pairs are constructed via a text-to-speech (TTS) system. Extensive experiments demonstrate that our proposed model achieves state-of-the-art (SOTA) results on many benchmarks covering speech named entity recognition, speech sentiment analysis, speech question answering, and more, after fine-tuning. Furthermore, the proposed model achieves competitive performance in zero-shot and few-shot scenarios. To facilitate future work on instruction fine-tuning for speech-to-semantic tasks, we release our instruction dataset and code.
Speech-Gesture GAN: Gesture Generation for Robots and Embodied Agents
Sep 17, 2023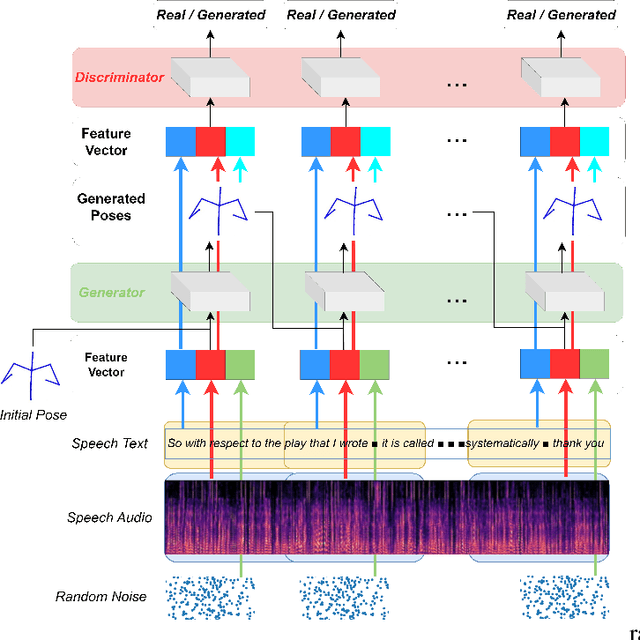
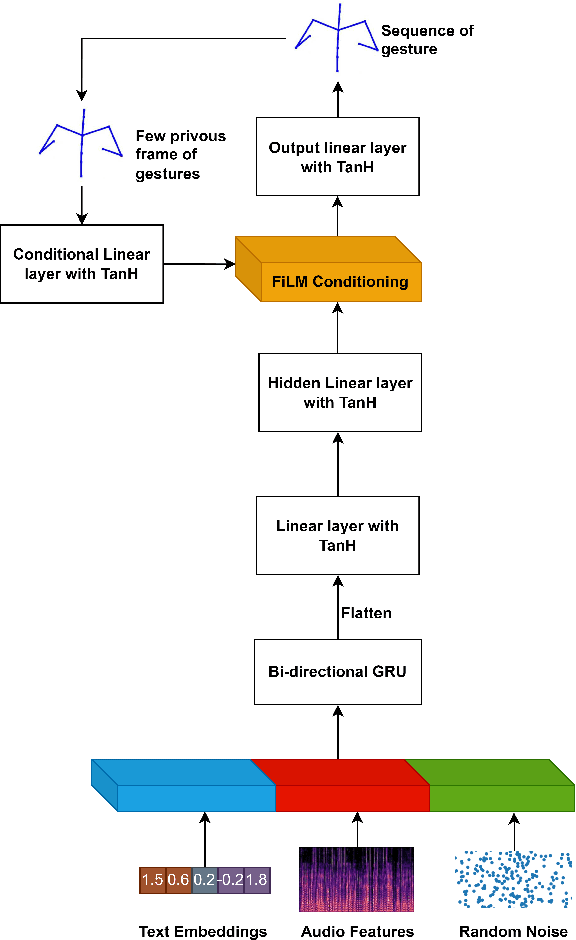
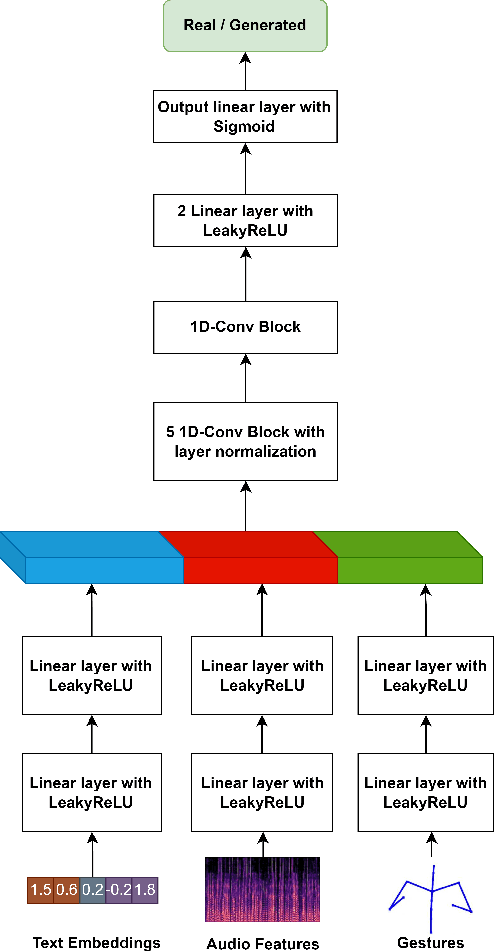

Embodied agents, in the form of virtual agents or social robots, are rapidly becoming more widespread. In human-human interactions, humans use nonverbal behaviours to convey their attitudes, feelings, and intentions. Therefore, this capability is also required for embodied agents in order to enhance the quality and effectiveness of their interactions with humans. In this paper, we propose a novel framework that can generate sequences of joint angles from the speech text and speech audio utterances. Based on a conditional Generative Adversarial Network (GAN), our proposed neural network model learns the relationships between the co-speech gestures and both semantic and acoustic features from the speech input. In order to train our neural network model, we employ a public dataset containing co-speech gestures with corresponding speech audio utterances, which were captured from a single male native English speaker. The results from both objective and subjective evaluations demonstrate the efficacy of our gesture-generation framework for Robots and Embodied Agents.
Study of speaker localization under dynamic and reverberant environments
Nov 28, 2023Speaker localization in a reverberant environment is a fundamental problem in audio signal processing. Many solutions have been developed to tackle this problem. However, previous algorithms typically assume a stationary environment in which both the microphone array and the sound sources are not moving. With the emergence of wearable microphone arrays, acoustic scenes have become dynamic with moving sources and arrays. This calls for algorithms that perform well in dynamic environments. In this article, we study the performance of a speaker localization algorithm in such an environment. The study is based on the recently published EasyCom speech dataset recorded in reverberant and noisy environments using a wearable array on glasses. Although the localization algorithm performs well in static environments, its performance degraded substantially when used on the EasyCom dataset. The paper presents performance analysis and proposes methods for improvement.
Sparsely Shared LoRA on Whisper for Child Speech Recognition
Sep 21, 2023Whisper is a powerful automatic speech recognition (ASR) model. Nevertheless, its zero-shot performance on low-resource speech requires further improvement. Child speech, as a representative type of low-resource speech, is leveraged for adaptation. Recently, parameter-efficient fine-tuning (PEFT) in NLP was shown to be comparable and even better than full fine-tuning, while only needing to tune a small set of trainable parameters. However, current PEFT methods have not been well examined for their effectiveness on Whisper. In this paper, only parameter composition types of PEFT approaches such as LoRA and Bitfit are investigated as they do not bring extra inference costs. Different popular PEFT methods are examined. Particularly, we compare LoRA and AdaLoRA and figure out the learnable rank coefficient is a good design. Inspired by the sparse rank distribution allocated by AdaLoRA, a novel PEFT approach Sparsely Shared LoRA (S2-LoRA) is proposed. The two low-rank decomposed matrices are globally shared. Each weight matrix only has to maintain its specific rank coefficients that are constrained to be sparse. Experiments on low-resource Chinese child speech show that with much fewer trainable parameters, S2-LoRA can achieve comparable in-domain adaptation performance to AdaLoRA and exhibit better generalization ability on out-of-domain data. In addition, the rank distribution automatically learned by S2-LoRA is found to have similar patterns to AdaLoRA's allocation.
Partial Rank Similarity Minimization Method for Quality MOS Prediction of Unseen Speech Synthesis Systems in Zero-Shot and Semi-supervised setting
Oct 08, 2023This paper introduces a novel objective function for quality mean opinion score (MOS) prediction of unseen speech synthesis systems. The proposed function measures the similarity of relative positions of predicted MOS values, in a mini-batch, rather than the actual MOS values. That is the partial rank similarity is measured (PRS) rather than the individual MOS values as with the L1 loss. Our experiments on out-of-domain speech synthesis systems demonstrate that the PRS outperforms L1 loss in zero-shot and semi-supervised settings, exhibiting stronger correlation with ground truth. These findings highlight the importance of considering rank order, as done by PRS, when training MOS prediction models. We also argue that mean squared error and linear correlation coefficient metrics may be unreliable for evaluating MOS prediction models. In conclusion, PRS-trained models provide a robust framework for evaluating speech quality and offer insights for developing high-quality speech synthesis systems. Code and models are available at github.com/nii-yamagishilab/partial_rank_similarity/
Correction Focused Language Model Training for Speech Recognition
Oct 17, 2023Language models (LMs) have been commonly adopted to boost the performance of automatic speech recognition (ASR) particularly in domain adaptation tasks. Conventional way of LM training treats all the words in corpora equally, resulting in suboptimal improvements in ASR performance. In this work, we introduce a novel correction focused LM training approach which aims to prioritize ASR fallible words. The word-level ASR fallibility score, representing the likelihood of ASR mis-recognition, is defined and shaped as a prior word distribution to guide the LM training. To enable correction focused training with text-only corpora, large language models (LLMs) are employed as fallibility score predictors and text generators through multi-task fine-tuning. Experimental results for domain adaptation tasks demonstrate the effectiveness of our proposed method. Compared with conventional LMs, correction focused training achieves up to relatively 5.5% word error rate (WER) reduction in sufficient text scenarios. In insufficient text scenarios, LM training with LLM-generated text achieves up to relatively 13% WER reduction, while correction focused training further obtains up to relatively 6% WER reduction.
Weak Alignment Supervision from Hybrid Model Improves End-to-end ASR
Nov 30, 2023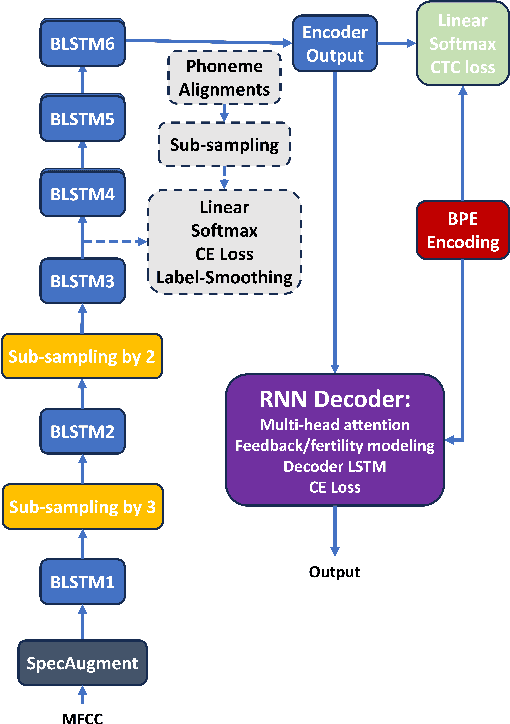
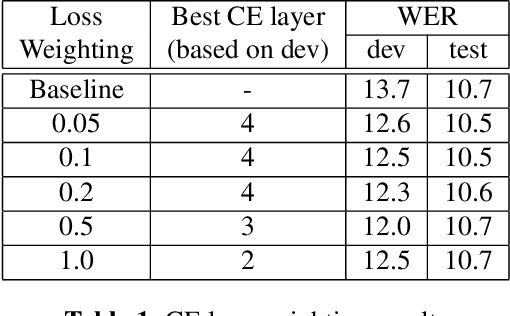
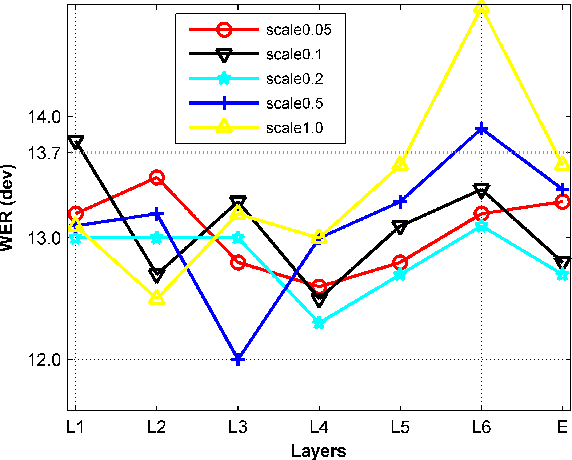

In this paper, we aim to create weak alignment supervision from an existing hybrid system to aid the end-to-end modeling of automatic speech recognition. Towards this end, we use the existing hybrid ASR system to produce triphone alignments of the training audios. We then create a cross-entropy loss at a certain layer of the encoder using the derived alignments. In contrast to the general one-hot cross-entropy losses, here we use a cross-entropy loss with a label smoothing parameter to regularize the supervision. As a comparison, we also conduct the experiments with one-hot cross-entropy losses and CTC losses with loss weighting. The results show that placing the weak alignment supervision with the label smoothing parameter of 0.5 at the third encoder layer outperforms the other two approaches and leads to about 5\% relative WER reduction on the TED-LIUM 2 dataset over the baseline. We see similar improvements when applying the method out-of-the-box on a Tagalog end-to-end ASR system.
Instructing Hierarchical Tasks to Robots by Verbal Commands
Nov 30, 2023Natural language is an effective tool for communication, as information can be expressed in different ways and at different levels of complexity. Verbal commands, utilized for instructing robot tasks, can therefor replace traditional robot programming techniques, and provide a more expressive means to assign actions and enable collaboration. However, the challenge of utilizing speech for robot programming is how actions and targets can be grounded to physical entities in the world. In addition, to be time-efficient, a balance needs to be found between fine- and course-grained commands and natural language phrases. In this work we provide a framework for instructing tasks to robots by verbal commands. The framework includes functionalities for single commands to actions and targets, as well as longer-term sequences of actions, thereby providing a hierarchical structure to the robot tasks. Experimental evaluation demonstrates the functionalities of the framework by human collaboration with a robot in different tasks, with different levels of complexity. The tools are provided open-source at https://petim44.github.io/voice-jogger/
Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model
Dec 02, 2023The big language model represented by ChatGPT has had a disruptive impact on the field of artificial intelligence. But it mainly focuses on Natural language processing, speech recognition, machine learning and natural-language understanding. This paper innovatively applies the big language model to the field of intelligent decision-making, places the big language model in the decision-making center, and constructs an agent architecture with the big language model as the core. Based on this, it further proposes a two-layer agent task planning, issues and executes decision commands through the interaction of natural language, and carries out simulation verification through the wargame simulation environment. Through the game confrontation simulation experiment, it is found that the intelligent decision-making ability of the big language model is significantly stronger than the commonly used reinforcement learning AI and rule AI, and the intelligence, understandability and generalization are all better. And through experiments, it was found that the intelligence of the large language model is closely related to prompt. This work also extends the large language model from previous human-computer interaction to the field of intelligent decision-making, which has important reference value and significance for the development of intelligent decision-making.