 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
VoxArabica: A Robust Dialect-Aware Arabic Speech Recognition System
Oct 25, 2023
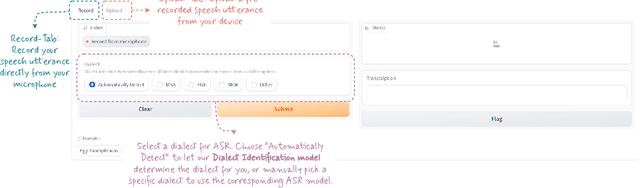

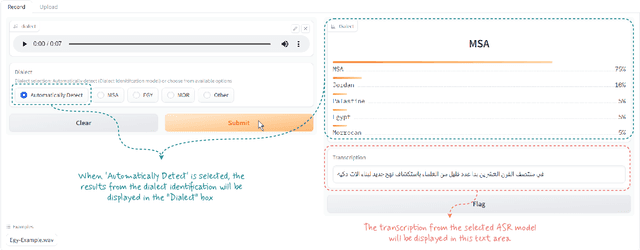
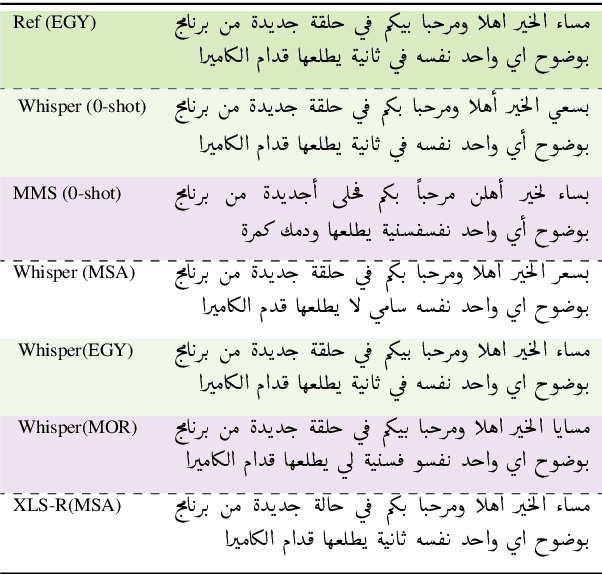
Arabic is a complex language with many varieties and dialects spoken by over 450 millions all around the world. Due to the linguistic diversity and variations, it is challenging to build a robust and generalized ASR system for Arabic. In this work, we address this gap by developing and demoing a system, dubbed VoxArabica, for dialect identification (DID) as well as automatic speech recognition (ASR) of Arabic. We train a wide range of models such as HuBERT (DID), Whisper, and XLS-R (ASR) in a supervised setting for Arabic DID and ASR tasks. Our DID models are trained to identify 17 different dialects in addition to MSA. We finetune our ASR models on MSA, Egyptian, Moroccan, and mixed data. Additionally, for the remaining dialects in ASR, we provide the option to choose various models such as Whisper and MMS in a zero-shot setting. We integrate these models into a single web interface with diverse features such as audio recording, file upload, model selection, and the option to raise flags for incorrect outputs. Overall, we believe VoxArabica will be useful for a wide range of audiences concerned with Arabic research. Our system is currently running at https://cdce-206-12-100-168.ngrok.io/.
Fast-HuBERT: An Efficient Training Framework for Self-Supervised Speech Representation Learning
Sep 29, 2023Recent years have witnessed significant advancements in self-supervised learning (SSL) methods for speech-processing tasks. Various speech-based SSL models have been developed and present promising performance on a range of downstream tasks including speech recognition. However, existing speech-based SSL models face a common dilemma in terms of computational cost, which might hinder their potential application and in-depth academic research. To address this issue, we first analyze the computational cost of different modules during HuBERT pre-training and then introduce a stack of efficiency optimizations, which is named Fast-HuBERT in this paper. The proposed Fast-HuBERT can be trained in 1.1 days with 8 V100 GPUs on the Librispeech 960h benchmark, without performance degradation, resulting in a 5.2x speedup, compared to the original implementation. Moreover, we explore two well-studied techniques in the Fast-HuBERT and demonstrate consistent improvements as reported in previous work.
RTFS-Net: Recurrent time-frequency modelling for efficient audio-visual speech separation
Sep 29, 2023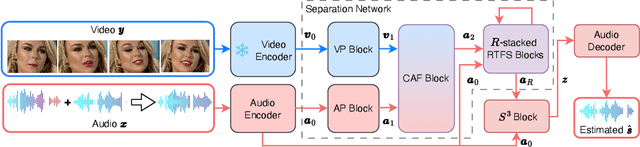
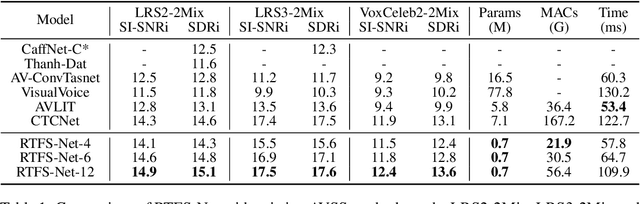
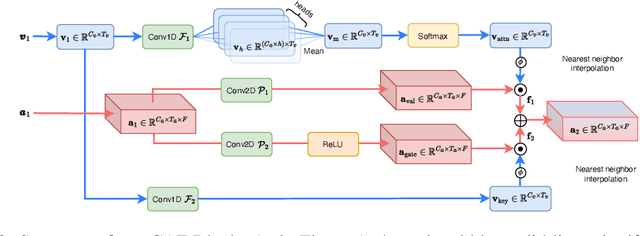

Audio-visual speech separation methods aim to integrate different modalities to generate high-quality separated speech, thereby enhancing the performance of downstream tasks such as speech recognition. Most existing state-of-the-art (SOTA) models operate in the time domain. However, their overly simplistic approach to modeling acoustic features often necessitates larger and more computationally intensive models in order to achieve SOTA performance. In this paper, we present a novel time-frequency domain audio-visual speech separation method: Recurrent Time-Frequency Separation Network (RTFS-Net), which applies its algorithms on the complex time-frequency bins yielded by the Short-Time Fourier Transform. We model and capture the time and frequency dimensions of the audio independently using a multi-layered RNN along each dimension. Furthermore, we introduce a unique attention-based fusion technique for the efficient integration of audio and visual information, and a new mask separation approach that takes advantage of the intrinsic spectral nature of the acoustic features for a clearer separation. RTFS-Net outperforms the previous SOTA method using only 10% of the parameters and 18% of the MACs. This is the first time-frequency domain audio-visual speech separation method to outperform all contemporary time-domain counterparts.
One-Class Knowledge Distillation for Spoofing Speech Detection
Sep 15, 2023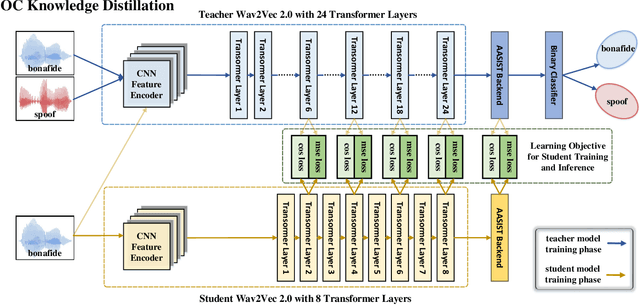

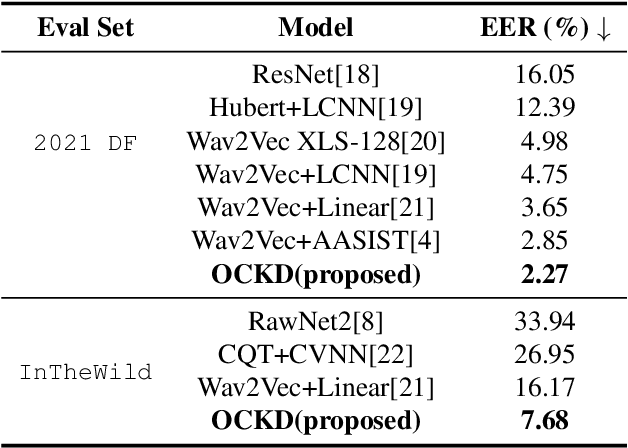
The detection of spoofing speech generated by unseen algorithms remains an unresolved challenge. One reason for the lack of generalization ability is traditional detecting systems follow the binary classification paradigm, which inherently assumes the possession of prior knowledge of spoofing speech. One-class methods attempt to learn the distribution of bonafide speech and are inherently suited to the task where spoofing speech exhibits significant differences. However, training a one-class system using only bonafide speech is challenging. In this paper, we introduce a teacher-student framework to provide guidance for the training of a one-class model. The proposed one-class knowledge distillation method outperforms other state-of-the-art methods on the ASVspoof 21DF dataset and InTheWild dataset, which demonstrates its superior generalization ability.
High-Fidelity Speech Synthesis with Minimal Supervision: All Using Diffusion Models
Sep 27, 2023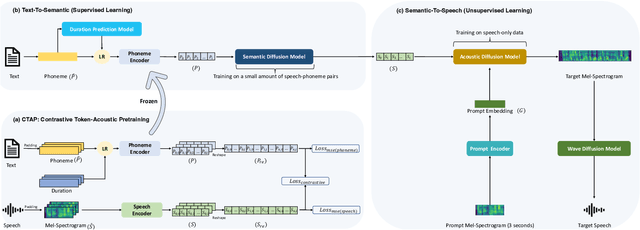
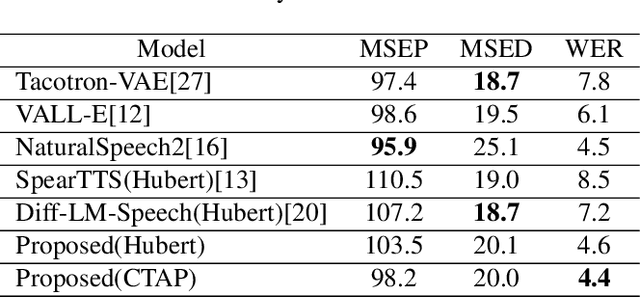
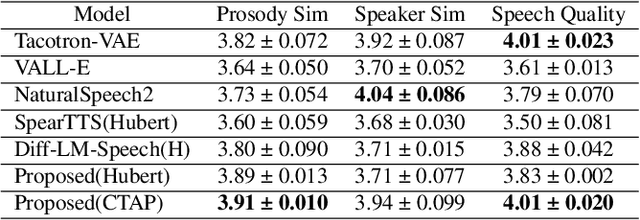
Text-to-speech (TTS) methods have shown promising results in voice cloning, but they require a large number of labeled text-speech pairs. Minimally-supervised speech synthesis decouples TTS by combining two types of discrete speech representations(semantic \& acoustic) and using two sequence-to-sequence tasks to enable training with minimal supervision. However, existing methods suffer from information redundancy and dimension explosion in semantic representation, and high-frequency waveform distortion in discrete acoustic representation. Autoregressive frameworks exhibit typical instability and uncontrollability issues. And non-autoregressive frameworks suffer from prosodic averaging caused by duration prediction models. To address these issues, we propose a minimally-supervised high-fidelity speech synthesis method, where all modules are constructed based on the diffusion models. The non-autoregressive framework enhances controllability, and the duration diffusion model enables diversified prosodic expression. Contrastive Token-Acoustic Pretraining (CTAP) is used as an intermediate semantic representation to solve the problems of information redundancy and dimension explosion in existing semantic coding methods. Mel-spectrogram is used as the acoustic representation. Both semantic and acoustic representations are predicted by continuous variable regression tasks to solve the problem of high-frequency fine-grained waveform distortion. Experimental results show that our proposed method outperforms the baseline method. We provide audio samples on our website.
Active Learning Based Fine-Tuning Framework for Speech Emotion Recognition
Sep 30, 2023Speech emotion recognition (SER) has drawn increasing attention for its applications in human-machine interaction. However, existing SER methods ignore the information gap between the pre-training speech recognition task and the downstream SER task, leading to sub-optimal performance. Moreover, they require much time to fine-tune on each specific speech dataset, restricting their effectiveness in real-world scenes with large-scale noisy data. To address these issues, we propose an active learning (AL) based Fine-Tuning framework for SER that leverages task adaptation pre-training (TAPT) and AL methods to enhance performance and efficiency. Specifically, we first use TAPT to minimize the information gap between the pre-training and the downstream task. Then, AL methods are used to iteratively select a subset of the most informative and diverse samples for fine-tuning, reducing time consumption. Experiments demonstrate that using only 20\%pt. samples improves 8.45\%pt. accuracy and reduces 79\%pt. time consumption.
ReFlow-TTS: A Rectified Flow Model for High-fidelity Text-to-Speech
Sep 29, 2023
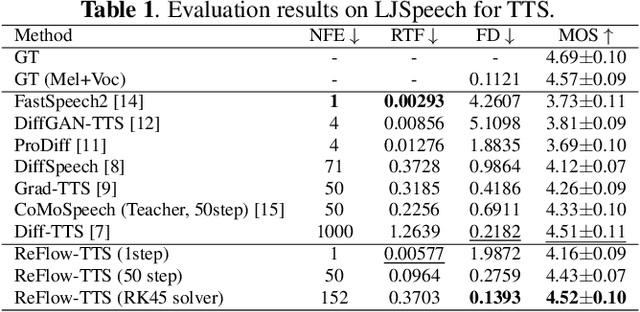
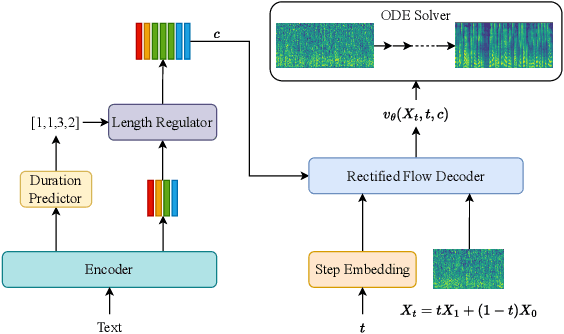

The diffusion models including Denoising Diffusion Probabilistic Models (DDPM) and score-based generative models have demonstrated excellent performance in speech synthesis tasks. However, its effectiveness comes at the cost of numerous sampling steps, resulting in prolonged sampling time required to synthesize high-quality speech. This drawback hinders its practical applicability in real-world scenarios. In this paper, we introduce ReFlow-TTS, a novel rectified flow based method for speech synthesis with high-fidelity. Specifically, our ReFlow-TTS is simply an Ordinary Differential Equation (ODE) model that transports Gaussian distribution to the ground-truth Mel-spectrogram distribution by straight line paths as much as possible. Furthermore, our proposed approach enables high-quality speech synthesis with a single sampling step and eliminates the need for training a teacher model. Our experiments on LJSpeech Dataset show that our ReFlow-TTS method achieves the best performance compared with other diffusion based models. And the ReFlow-TTS with one step sampling achieves competitive performance compared with existing one-step TTS models.
Speech collage: code-switched audio generation by collaging monolingual corpora
Sep 27, 2023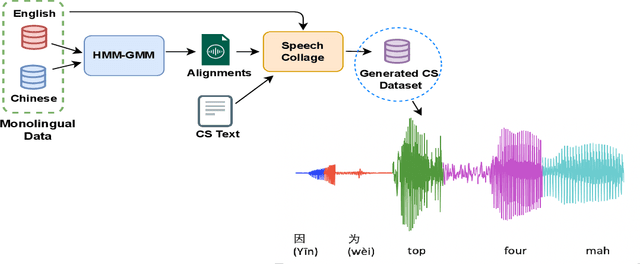
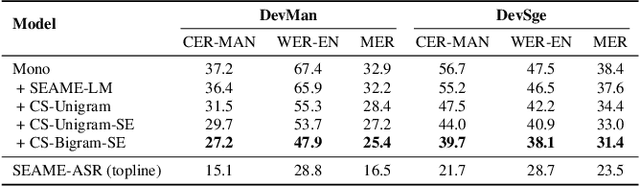
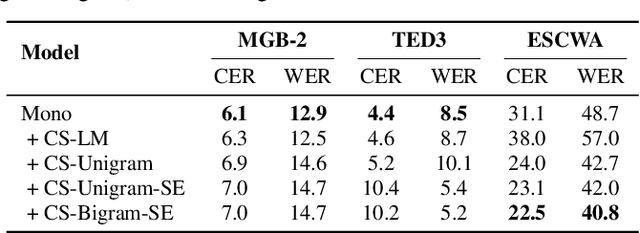
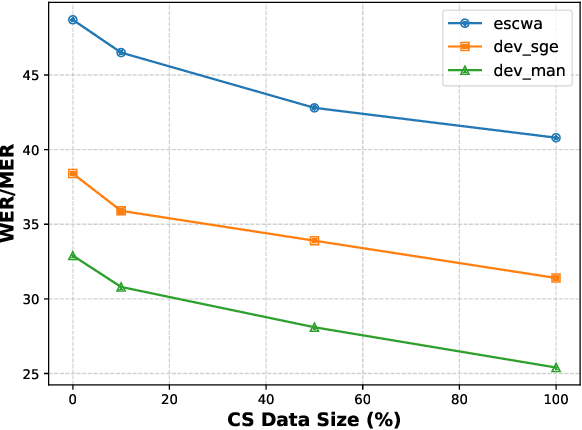
Designing effective automatic speech recognition (ASR) systems for Code-Switching (CS) often depends on the availability of the transcribed CS resources. To address data scarcity, this paper introduces Speech Collage, a method that synthesizes CS data from monolingual corpora by splicing audio segments. We further improve the smoothness quality of audio generation using an overlap-add approach. We investigate the impact of generated data on speech recognition in two scenarios: using in-domain CS text and a zero-shot approach with synthesized CS text. Empirical results highlight up to 34.4% and 16.2% relative reductions in Mixed-Error Rate and Word-Error Rate for in-domain and zero-shot scenarios, respectively. Lastly, we demonstrate that CS augmentation bolsters the model's code-switching inclination and reduces its monolingual bias.
Electrolaryngeal Speech Intelligibility Enhancement Through Robust Linguistic Encoders
Sep 18, 2023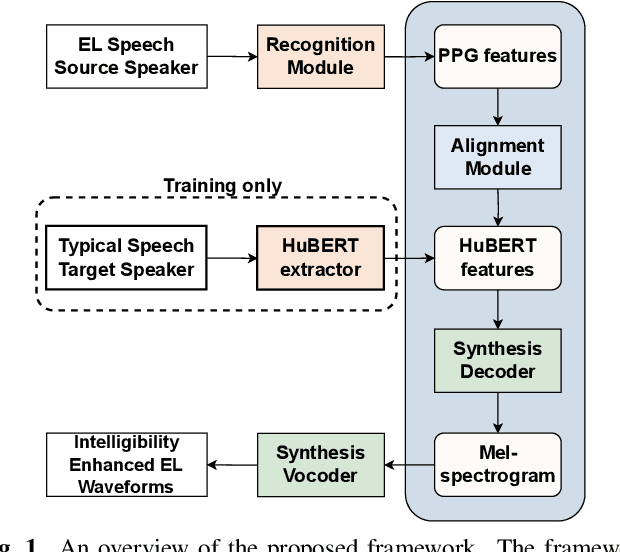

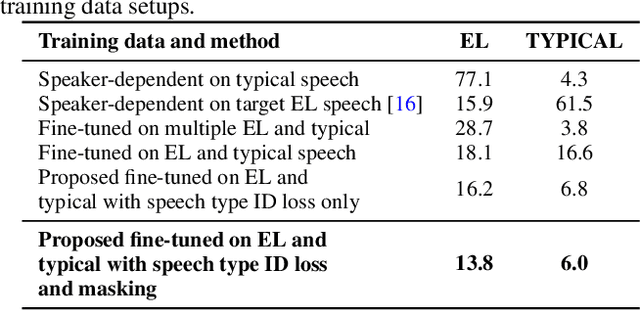

We propose a novel framework for electrolaryngeal speech intelligibility enhancement through the use of robust linguistic encoders. Pretraining and fine-tuning approaches have proven to work well in this task, but in most cases, various mismatches, such as the speech type mismatch (electrolaryngeal vs. typical) or a speaker mismatch between the datasets used in each stage, can deteriorate the conversion performance of this framework. To resolve this issue, we propose a linguistic encoder robust enough to project both EL and typical speech in the same latent space, while still being able to extract accurate linguistic information, creating a unified representation to reduce the speech type mismatch. Furthermore, we introduce HuBERT output features to the proposed framework for reducing the speaker mismatch, making it possible to effectively use a large-scale parallel dataset during pretraining. We show that compared to the conventional framework using mel-spectrogram input and output features, using the proposed framework enables the model to synthesize more intelligible and naturally sounding speech, as shown by a significant 16% improvement in character error rate and 0.83 improvement in naturalness score.
Cross-Utterance Conditioned VAE for Speech Generation
Sep 08, 2023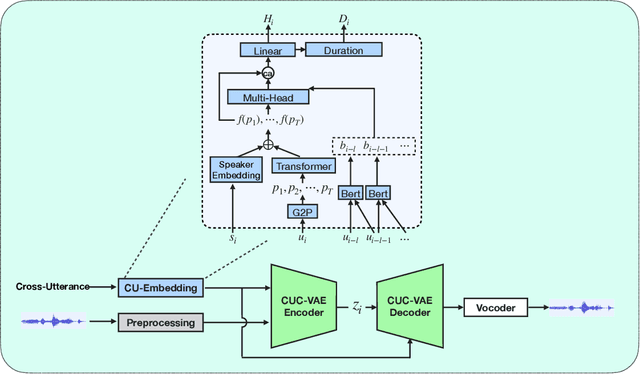
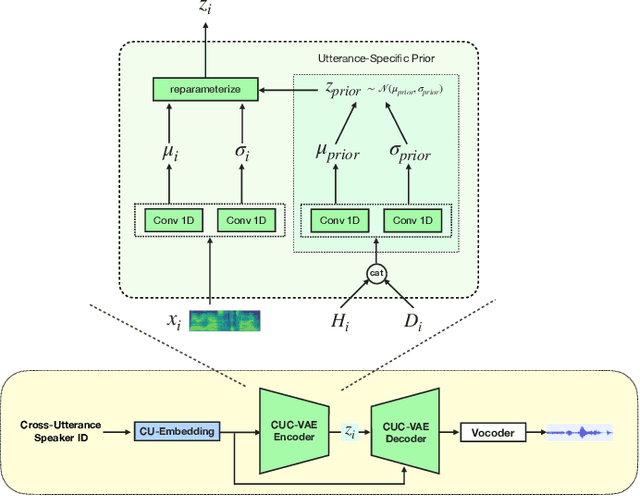
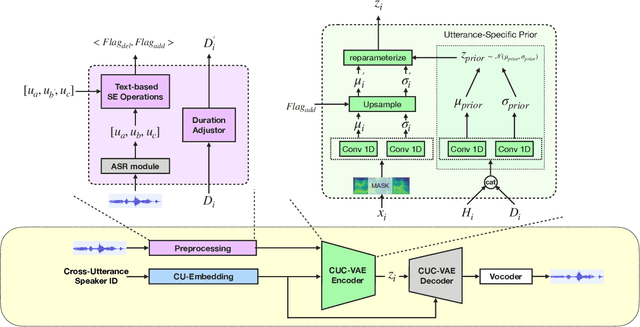

Speech synthesis systems powered by neural networks hold promise for multimedia production, but frequently face issues with producing expressive speech and seamless editing. In response, we present the Cross-Utterance Conditioned Variational Autoencoder speech synthesis (CUC-VAE S2) framework to enhance prosody and ensure natural speech generation. This framework leverages the powerful representational capabilities of pre-trained language models and the re-expression abilities of variational autoencoders (VAEs). The core component of the CUC-VAE S2 framework is the cross-utterance CVAE, which extracts acoustic, speaker, and textual features from surrounding sentences to generate context-sensitive prosodic features, more accurately emulating human prosody generation. We further propose two practical algorithms tailored for distinct speech synthesis applications: CUC-VAE TTS for text-to-speech and CUC-VAE SE for speech editing. The CUC-VAE TTS is a direct application of the framework, designed to generate audio with contextual prosody derived from surrounding texts. On the other hand, the CUC-VAE SE algorithm leverages real mel spectrogram sampling conditioned on contextual information, producing audio that closely mirrors real sound and thereby facilitating flexible speech editing based on text such as deletion, insertion, and replacement. Experimental results on the LibriTTS datasets demonstrate that our proposed models significantly enhance speech synthesis and editing, producing more natural and expressive speech.