 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
DiaPer: End-to-End Neural Diarization with Perceiver-Based Attractors
Dec 07, 2023
Until recently, the field of speaker diarization was dominated by cascaded systems. Due to their limitations, mainly regarding overlapped speech and cumbersome pipelines, end-to-end models have gained great popularity lately. One of the most successful models is end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA). In this work, we replace the EDA module with a Perceiver-based one and show its advantages over EEND-EDA; namely obtaining better performance on the largely studied Callhome dataset, finding the quantity of speakers in a conversation more accurately, and running inference on almost half of the time on long recordings. Furthermore, when exhaustively compared with other methods, our model, DiaPer, reaches remarkable performance with a very lightweight design. Besides, we perform comparisons with other works and a cascaded baseline across more than ten public wide-band datasets. Together with this publication, we release the code of DiaPer as well as models trained on public and free data.
SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis
Nov 29, 2023Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. Traditional Generative Adversarial Networks (GAN) struggle to maintain consistent facial identity, while Neural Radiance Fields (NeRF) methods, although they can address this issue, often produce mismatched lip movements, inadequate facial expressions, and unstable head poses. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic and artificial outcomes. To address the critical issue of synchronization, identified as the "devil" in creating realistic talking heads, we introduce SyncTalk. This NeRF-based method effectively maintains subject identity, enhancing synchronization and realism in talking head synthesis. SyncTalk employs a Face-Sync Controller to align lip movements with speech and innovatively uses a 3D facial blendshape model to capture accurate facial expressions. Our Head-Sync Stabilizer optimizes head poses, achieving more natural head movements. The Portrait-Sync Generator restores hair details and blends the generated head with the torso for a seamless visual experience. Extensive experiments and user studies demonstrate that SyncTalk outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk
Modular Speech-to-Text Translation for Zero-Shot Cross-Modal Transfer
Oct 05, 2023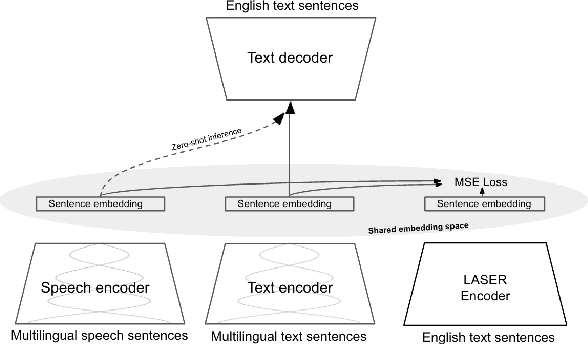
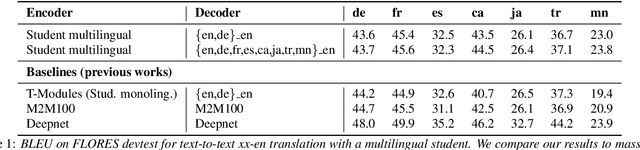

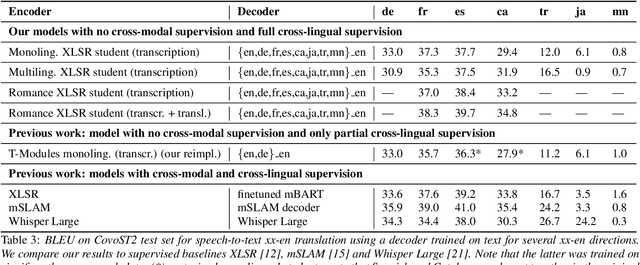
Recent research has shown that independently trained encoders and decoders, combined through a shared fixed-size representation, can achieve competitive performance in speech-to-text translation. In this work, we show that this type of approach can be further improved with multilingual training. We observe significant improvements in zero-shot cross-modal speech translation, even outperforming a supervised approach based on XLSR for several languages.
Multi-dimensional Speech Quality Assessment in Crowdsourcing
Sep 14, 2023

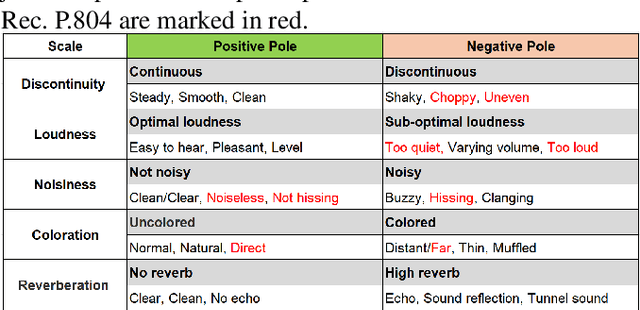
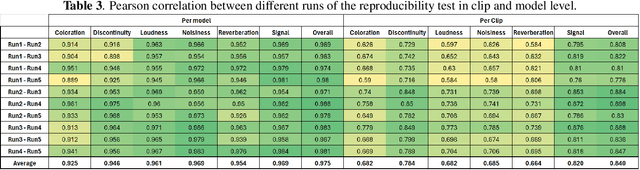
Subjective speech quality assessment is the gold standard for evaluating speech enhancement processing and telecommunication systems. The commonly used standard ITU-T Rec. P.800 defines how to measure speech quality in lab environments, and ITU-T Rec.~P.808 extended it for crowdsourcing. ITU-T Rec. P.835 extends P.800 to measure the quality of speech in the presence of noise. ITU-T Rec. P.804 targets the conversation test and introduces perceptual speech quality dimensions which are measured during the listening phase of the conversation. The perceptual dimensions are noisiness, coloration, discontinuity, and loudness. We create a crowdsourcing implementation of a multi-dimensional subjective test following the scales from P.804 and extend it to include reverberation, the speech signal, and overall quality. We show the tool is both accurate and reproducible. The tool has been used in the ICASSP 2023 Speech Signal Improvement challenge and we show the utility of these speech quality dimensions in this challenge. The tool will be publicly available as open-source at https://github.com/microsoft/P.808.
Analysis of Visual Features for Continuous Lipreading in Spanish
Nov 21, 2023During a conversation, our brain is responsible for combining information obtained from multiple senses in order to improve our ability to understand the message we are perceiving. Different studies have shown the importance of presenting visual information in these situations. Nevertheless, lipreading is a complex task whose objective is to interpret speech when audio is not available. By dispensing with a sense as crucial as hearing, it will be necessary to be aware of the challenge that this lack presents. In this paper, we propose an analysis of different speech visual features with the intention of identifying which of them is the best approach to capture the nature of lip movements for natural Spanish and, in this way, dealing with the automatic visual speech recognition task. In order to estimate our system, we present an audiovisual corpus compiled from a subset of the RTVE database, which has been used in the Albayz\'in evaluations. We employ a traditional system based on Hidden Markov Models with Gaussian Mixture Models. Results show that, although the task is difficult, in restricted conditions we obtain recognition results which determine that using eigenlips in combination with deep features is the best visual approach.
DualTalker: A Cross-Modal Dual Learning Approach for Speech-Driven 3D Facial Animation
Nov 08, 2023In recent years, audio-driven 3D facial animation has gained significant attention, particularly in applications such as virtual reality, gaming, and video conferencing. However, accurately modeling the intricate and subtle dynamics of facial expressions remains a challenge. Most existing studies approach the facial animation task as a single regression problem, which often fail to capture the intrinsic inter-modal relationship between speech signals and 3D facial animation and overlook their inherent consistency. Moreover, due to the limited availability of 3D-audio-visual datasets, approaches learning with small-size samples have poor generalizability that decreases the performance. To address these issues, in this study, we propose a cross-modal dual-learning framework, termed DualTalker, aiming at improving data usage efficiency as well as relating cross-modal dependencies. The framework is trained jointly with the primary task (audio-driven facial animation) and its dual task (lip reading) and shares common audio/motion encoder components. Our joint training framework facilitates more efficient data usage by leveraging information from both tasks and explicitly capitalizing on the complementary relationship between facial motion and audio to improve performance. Furthermore, we introduce an auxiliary cross-modal consistency loss to mitigate the potential over-smoothing underlying the cross-modal complementary representations, enhancing the mapping of subtle facial expression dynamics. Through extensive experiments and a perceptual user study conducted on the VOCA and BIWI datasets, we demonstrate that our approach outperforms current state-of-the-art methods both qualitatively and quantitatively. We have made our code and video demonstrations available at https://github.com/sabrina-su/iadf.git.
XLS-R fine-tuning on noisy word boundaries for unsupervised speech segmentation into words
Oct 08, 2023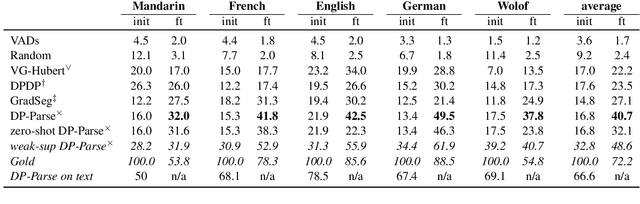
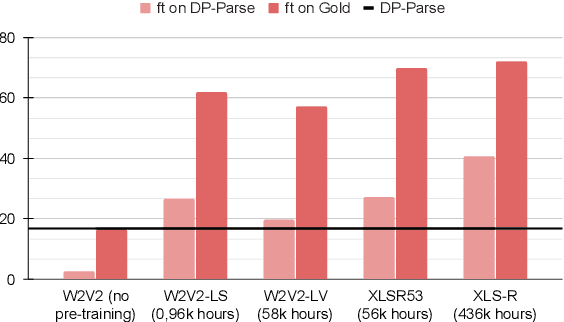
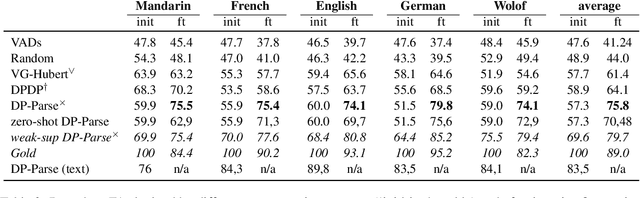
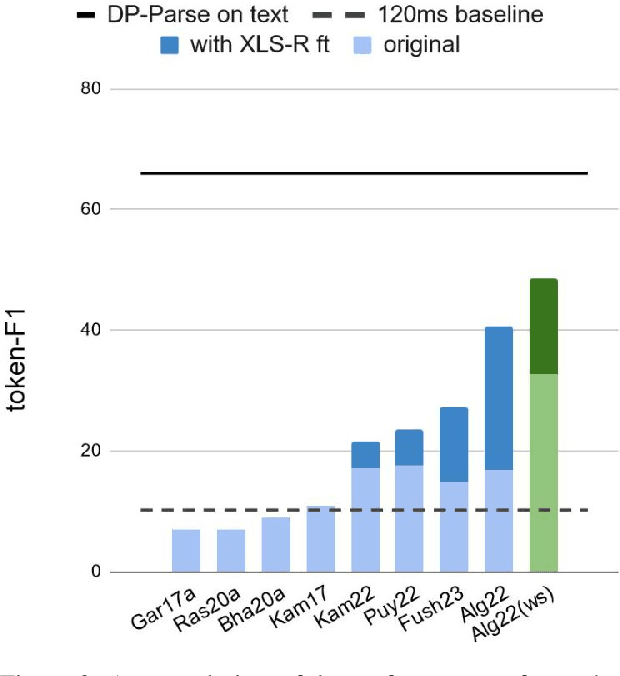
Due to the absence of explicit word boundaries in the speech stream, the task of segmenting spoken sentences into word units without text supervision is particularly challenging. In this work, we leverage the most recent self-supervised speech models that have proved to quickly adapt to new tasks through fine-tuning, even in low resource conditions. Taking inspiration from semi-supervised learning, we fine-tune an XLS-R model to predict word boundaries themselves produced by top-tier speech segmentation systems: DPDP, VG-HuBERT, GradSeg and DP-Parse. Once XLS-R is fine-tuned, it is used to infer new word boundary labels that are used in turn for another fine-tuning step. Our method consistently improves the performance of each system and sets a new state-of-the-art that is, on average 130% higher than the previous one as measured by the F1 score on correctly discovered word tokens on five corpora featuring different languages. Finally, our system can segment speech from languages unseen during fine-tuning in a zero-shot fashion.
Connecting Speech Encoder and Large Language Model for ASR
Sep 26, 2023The impressive capability and versatility of large language models (LLMs) have aroused increasing attention in automatic speech recognition (ASR), with several pioneering studies attempting to build integrated ASR models by connecting a speech encoder with an LLM. This paper presents a comparative study of three commonly used structures as connectors, including fully connected layers, multi-head cross-attention, and Q-Former. Speech encoders from the Whisper model series as well as LLMs from the Vicuna model series with different model sizes were studied. Experiments were performed on the commonly used LibriSpeech, Common Voice, and GigaSpeech datasets, where the LLMs with Q-Formers demonstrated consistent and considerable word error rate (WER) reductions over LLMs with other connector structures. Q-Former-based LLMs can generalise well to out-of-domain datasets, where 12% relative WER reductions over the Whisper baseline ASR model were achieved on the Eval2000 test set without using any in-domain training data from Switchboard. Moreover, a novel segment-level Q-Former is proposed to enable LLMs to recognise speech segments with a duration exceeding the limitation of the encoders, which results in 17% relative WER reductions over other connector structures on 90-second-long speech data.
Towards Conceptualization of "Fair Explanation": Disparate Impacts of anti-Asian Hate Speech Explanations on Content Moderators
Oct 23, 2023Recent research at the intersection of AI explainability and fairness has focused on how explanations can improve human-plus-AI task performance as assessed by fairness measures. We propose to characterize what constitutes an explanation that is itself "fair" -- an explanation that does not adversely impact specific populations. We formulate a novel evaluation method of "fair explanations" using not just accuracy and label time, but also psychological impact of explanations on different user groups across many metrics (mental discomfort, stereotype activation, and perceived workload). We apply this method in the context of content moderation of potential hate speech, and its differential impact on Asian vs. non-Asian proxy moderators, across explanation approaches (saliency map and counterfactual explanation). We find that saliency maps generally perform better and show less evidence of disparate impact (group) and individual unfairness than counterfactual explanations. Content warning: This paper contains examples of hate speech and racially discriminatory language. The authors do not support such content. Please consider your risk of discomfort carefully before continuing reading!
MUST: A Multilingual Student-Teacher Learning approach for low-resource speech recognition
Oct 29, 2023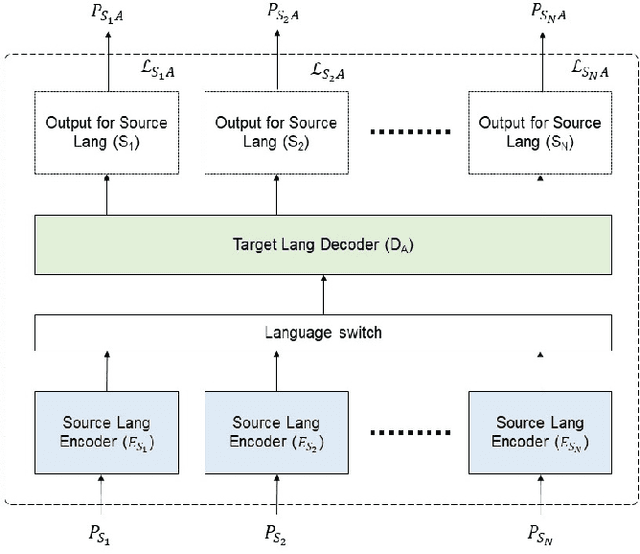
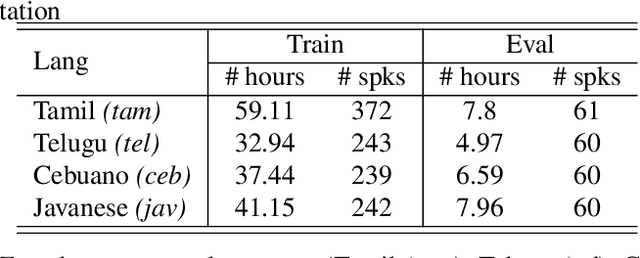
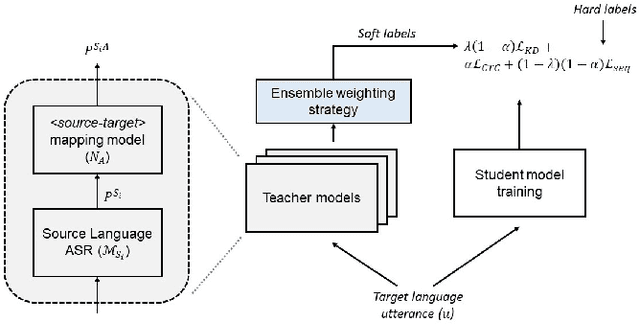
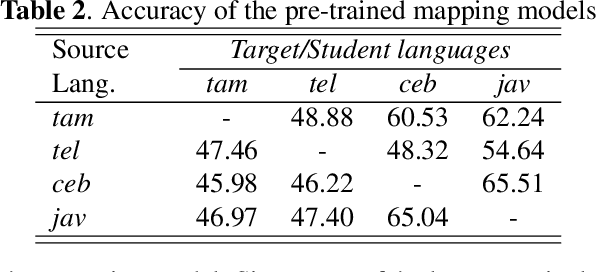
Student-teacher learning or knowledge distillation (KD) has been previously used to address data scarcity issue for training of speech recognition (ASR) systems. However, a limitation of KD training is that the student model classes must be a proper or improper subset of the teacher model classes. It prevents distillation from even acoustically similar languages if the character sets are not same. In this work, the aforementioned limitation is addressed by proposing a MUltilingual Student-Teacher (MUST) learning which exploits a posteriors mapping approach. A pre-trained mapping model is used to map posteriors from a teacher language to the student language ASR. These mapped posteriors are used as soft labels for KD learning. Various teacher ensemble schemes are experimented to train an ASR model for low-resource languages. A model trained with MUST learning reduces relative character error rate (CER) up to 9.5% in comparison with a baseline monolingual ASR.