 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Tuning Large language model for End-to-end Speech Translation
Oct 03, 2023
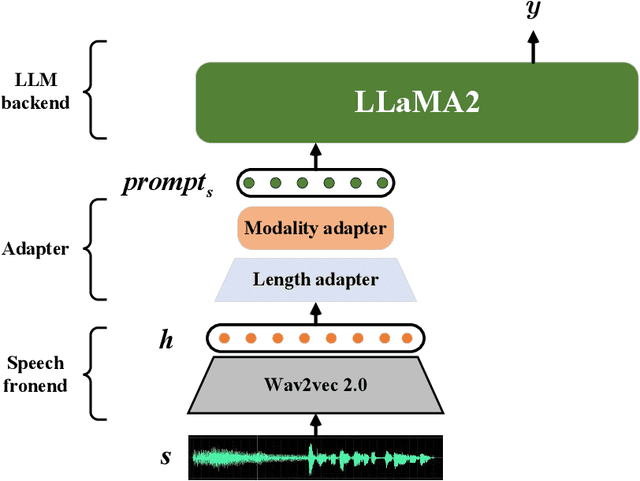
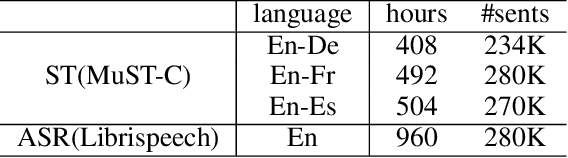
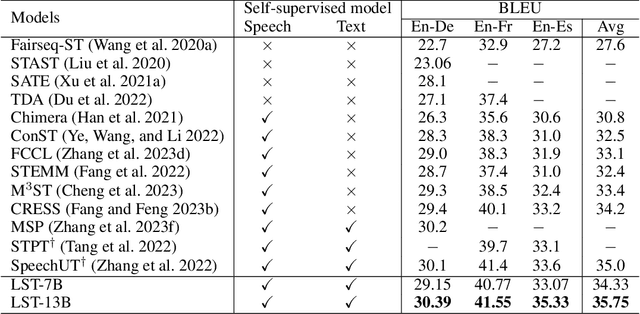
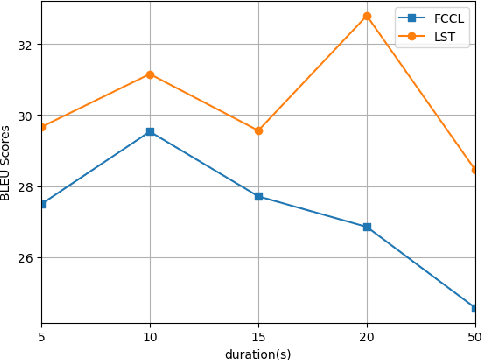
With the emergence of large language models (LLMs), multimodal models based on LLMs have demonstrated significant potential. Models such as LLaSM, X-LLM, and SpeechGPT exhibit an impressive ability to comprehend and generate human instructions. However, their performance often falters when faced with complex tasks like end-to-end speech translation (E2E-ST), a cross-language and cross-modal translation task. In comparison to single-modal models, multimodal models lag behind in these scenarios. This paper introduces LST, a Large multimodal model designed to excel at the E2E-ST task. LST consists of a speech frontend, an adapter, and a LLM backend. The training of LST consists of two stages: (1) Modality adjustment, where the adapter is tuned to align speech representation with text embedding space, and (2) Downstream task fine-tuning, where both the adapter and LLM model are trained to optimize performance on the E2EST task. Experimental results on the MuST-C speech translation benchmark demonstrate that LST-13B achieves BLEU scores of 30.39/41.55/35.33 on En-De/En-Fr/En-Es language pairs, surpassing previous models and establishing a new state-of-the-art. Additionally, we conduct an in-depth analysis of single-modal model selection and the impact of training strategies, which lays the foundation for future research. We will open up our code and models after review.
DiffusionSat: A Generative Foundation Model for Satellite Imagery
Dec 06, 2023Diffusion models have achieved state-of-the-art results on many modalities including images, speech, and video. However, existing models are not tailored to support remote sensing data, which is widely used in important applications including environmental monitoring and crop-yield prediction. Satellite images are significantly different from natural images -- they can be multi-spectral, irregularly sampled across time -- and existing diffusion models trained on images from the Web do not support them. Furthermore, remote sensing data is inherently spatio-temporal, requiring conditional generation tasks not supported by traditional methods based on captions or images. In this paper, we present DiffusionSat, to date the largest generative foundation model trained on a collection of publicly available large, high-resolution remote sensing datasets. As text-based captions are sparsely available for satellite images, we incorporate the associated metadata such as geolocation as conditioning information. Our method produces realistic samples and can be used to solve multiple generative tasks including temporal generation, superresolution given multi-spectral inputs and in-painting. Our method outperforms previous state-of-the-art methods for satellite image generation and is the first large-scale $\textit{generative}$ foundation model for satellite imagery.
Learning Repeatable Speech Embeddings Using An Intra-class Correlation Regularizer
Oct 25, 2023A good supervised embedding for a specific machine learning task is only sensitive to changes in the label of interest and is invariant to other confounding factors. We leverage the concept of repeatability from measurement theory to describe this property and propose to use the intra-class correlation coefficient (ICC) to evaluate the repeatability of embeddings. We then propose a novel regularizer, the ICC regularizer, as a complementary component for contrastive losses to guide deep neural networks to produce embeddings with higher repeatability. We use simulated data to explain why the ICC regularizer works better on minimizing the intra-class variance than the contrastive loss alone. We implement the ICC regularizer and apply it to three speech tasks: speaker verification, voice style conversion, and a clinical application for detecting dysphonic voice. The experimental results demonstrate that adding an ICC regularizer can improve the repeatability of learned embeddings compared to only using the contrastive loss; further, these embeddings lead to improved performance in these downstream tasks.
AdaMesh: Personalized Facial Expressions and Head Poses for Speech-Driven 3D Facial Animation
Oct 11, 2023
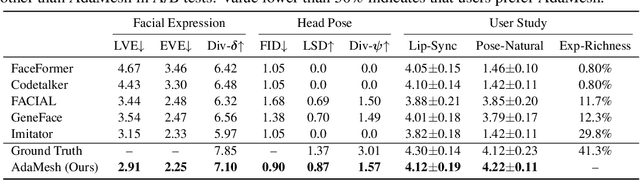
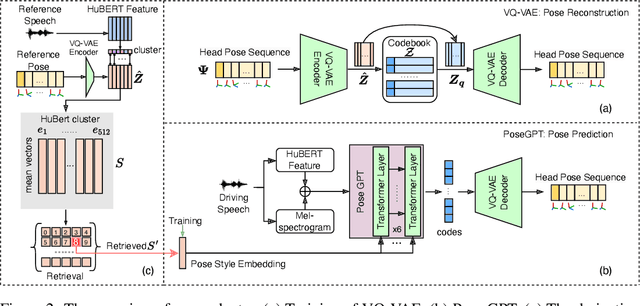

Speech-driven 3D facial animation aims at generating facial movements that are synchronized with the driving speech, which has been widely explored recently. Existing works mostly neglect the person-specific talking style in generation, including facial expression and head pose styles. Several works intend to capture the personalities by fine-tuning modules. However, limited training data leads to the lack of vividness. In this work, we propose AdaMesh, a novel adaptive speech-driven facial animation approach, which learns the personalized talking style from a reference video of about 10 seconds and generates vivid facial expressions and head poses. Specifically, we propose mixture-of-low-rank adaptation (MoLoRA) to fine-tune the expression adapter, which efficiently captures the facial expression style. For the personalized pose style, we propose a pose adapter by building a discrete pose prior and retrieving the appropriate style embedding with a semantic-aware pose style matrix without fine-tuning. Extensive experimental results show that our approach outperforms state-of-the-art methods, preserves the talking style in the reference video, and generates vivid facial animation. The supplementary video and code will be available at https://adamesh.github.io.
No Pitch Left Behind: Addressing Gender Unbalance in Automatic Speech Recognition through Pitch Manipulation
Oct 10, 2023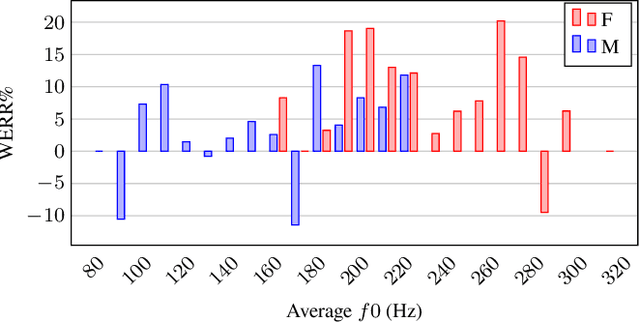
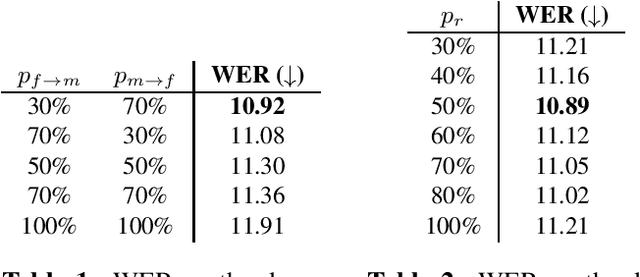
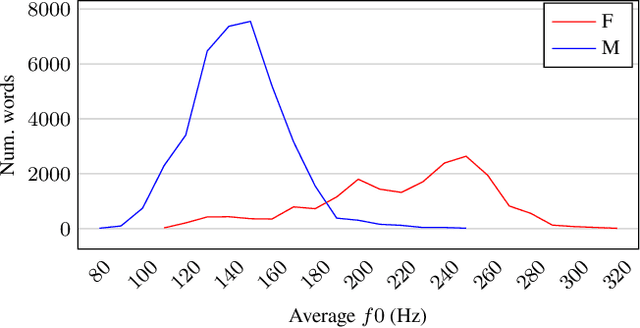

Automatic speech recognition (ASR) systems are known to be sensitive to the sociolinguistic variability of speech data, in which gender plays a crucial role. This can result in disparities in recognition accuracy between male and female speakers, primarily due to the under-representation of the latter group in the training data. While in the context of hybrid ASR models several solutions have been proposed, the gender bias issue has not been explicitly addressed in end-to-end neural architectures. To fill this gap, we propose a data augmentation technique that manipulates the fundamental frequency (f0) and formants. This technique reduces the data unbalance among genders by simulating voices of the under-represented female speakers and increases the variability within each gender group. Experiments on spontaneous English speech show that our technique yields a relative WER improvement up to 9.87% for utterances by female speakers, with larger gains for the least-represented f0 ranges.
VoxArabica: A Robust Dialect-Aware Arabic Speech Recognition System
Oct 27, 2023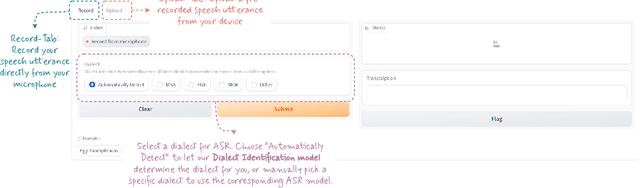

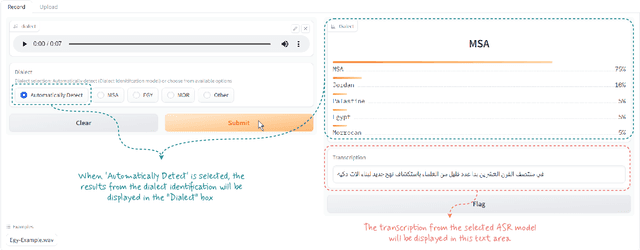
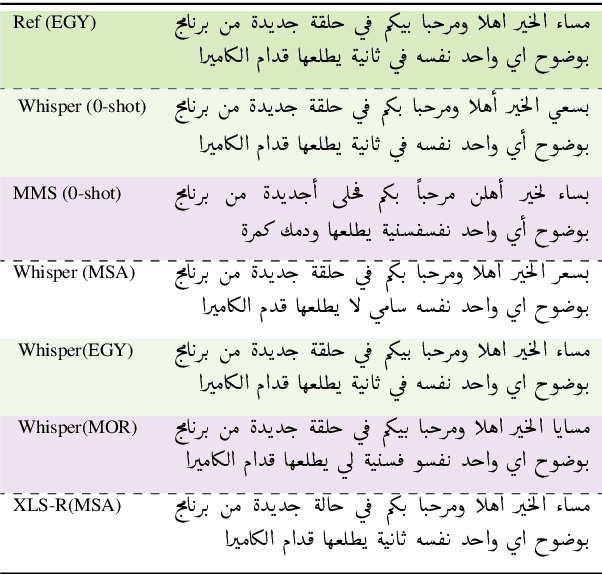
Arabic is a complex language with many varieties and dialects spoken by over 450 millions all around the world. Due to the linguistic diversity and variations, it is challenging to build a robust and generalized ASR system for Arabic. In this work, we address this gap by developing and demoing a system, dubbed VoxArabica, for dialect identification (DID) as well as automatic speech recognition (ASR) of Arabic. We train a wide range of models such as HuBERT (DID), Whisper, and XLS-R (ASR) in a supervised setting for Arabic DID and ASR tasks. Our DID models are trained to identify 17 different dialects in addition to MSA. We finetune our ASR models on MSA, Egyptian, Moroccan, and mixed data. Additionally, for the remaining dialects in ASR, we provide the option to choose various models such as Whisper and MMS in a zero-shot setting. We integrate these models into a single web interface with diverse features such as audio recording, file upload, model selection, and the option to raise flags for incorrect outputs. Overall, we believe VoxArabica will be useful for a wide range of audiences concerned with Arabic research. Our system is currently running at https://cdce-206-12-100-168.ngrok.io/.
On Time Domain Conformer Models for Monaural Speech Separation in Noisy Reverberant Acoustic Environments
Oct 09, 2023Speech separation remains an important topic for multi-speaker technology researchers. Convolution augmented transformers (conformers) have performed well for many speech processing tasks but have been under-researched for speech separation. Most recent state-of-the-art (SOTA) separation models have been time-domain audio separation networks (TasNets). A number of successful models have made use of dual-path (DP) networks which sequentially process local and global information. Time domain conformers (TD-Conformers) are an analogue of the DP approach in that they also process local and global context sequentially but have a different time complexity function. It is shown that for realistic shorter signal lengths, conformers are more efficient when controlling for feature dimension. Subsampling layers are proposed to further improve computational efficiency. The best TD-Conformer achieves 14.6 dB and 21.2 dB SISDR improvement on the WHAMR and WSJ0-2Mix benchmarks, respectively.
Unsupervised Speech Recognition with N-Skipgram and Positional Unigram Matching
Oct 03, 2023Training unsupervised speech recognition systems presents challenges due to GAN-associated instability, misalignment between speech and text, and significant memory demands. To tackle these challenges, we introduce a novel ASR system, ESPUM. This system harnesses the power of lower-order N-skipgrams (up to N=3) combined with positional unigram statistics gathered from a small batch of samples. Evaluated on the TIMIT benchmark, our model showcases competitive performance in ASR and phoneme segmentation tasks. Access our publicly available code at https://github.com/lwang114/GraphUnsupASR.
Guided Flows for Generative Modeling and Decision Making
Nov 22, 2023Classifier-free guidance is a key component for improving the performance of conditional generative models for many downstream tasks. It drastically improves the quality of samples produced, but has so far only been used for diffusion models. Flow Matching (FM), an alternative simulation-free approach, trains Continuous Normalizing Flows (CNFs) based on regressing vector fields. It remains an open question whether classifier-free guidance can be performed for Flow Matching models, and to what extent does it improve performance. In this paper, we explore the usage of Guided Flows for a variety of downstream applications involving conditional image generation, speech synthesis, and reinforcement learning. In particular, we are the first to apply flow models to the offline reinforcement learning setting. We also show that Guided Flows significantly improves the sample quality in image generation and zero-shot text-to-speech synthesis, and can make use of drastically low amounts of computation without affecting the agent's overall performance.
Test-Time Training for Speech
Sep 19, 2023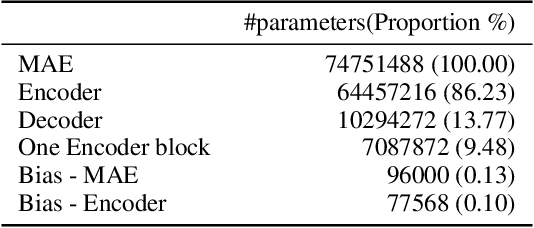

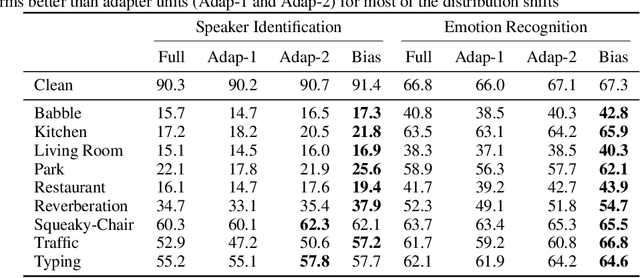
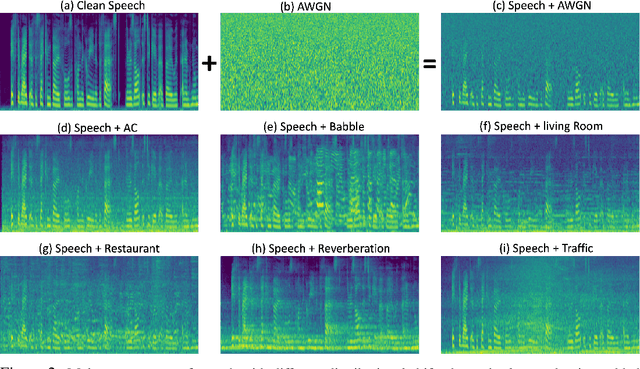
In this paper, we study the application of Test-Time Training (TTT) as a solution to handling distribution shifts in speech applications. In particular, we introduce distribution-shifts to the test datasets of standard speech-classification tasks -- for example, speaker-identification and emotion-detection -- and explore how Test-Time Training (TTT) can help adjust to the distribution-shift. In our experiments that include distribution shifts due to background noise and natural variations in speech such as gender and age, we identify some key-challenges with TTT including sensitivity to optimization hyperparameters (e.g., number of optimization steps and subset of parameters chosen for TTT) and scalability (e.g., as each example gets its own set of parameters, TTT is not scalable). Finally, we propose using BitFit -- a parameter-efficient fine-tuning algorithm proposed for text applications that only considers the bias parameters for fine-tuning -- as a solution to the aforementioned challenges and demonstrate that it is consistently more stable than fine-tuning all the parameters of the model.