 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A privacy-preserving method using secret key for convolutional neural network-based speech classification
Oct 06, 2023
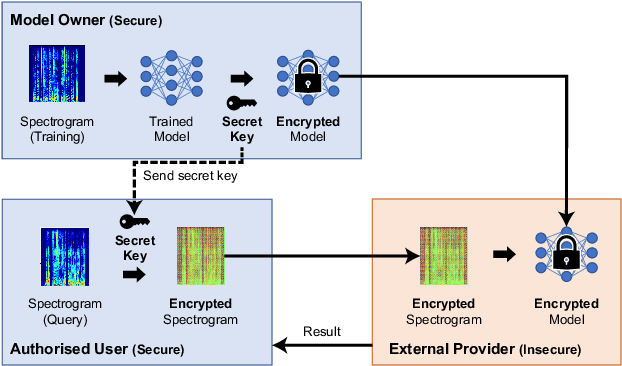
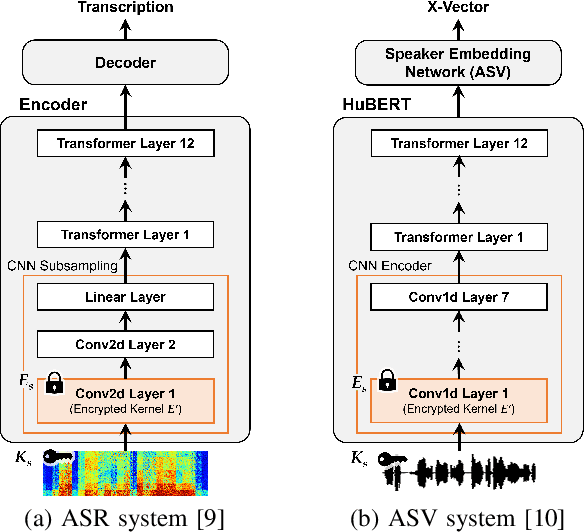
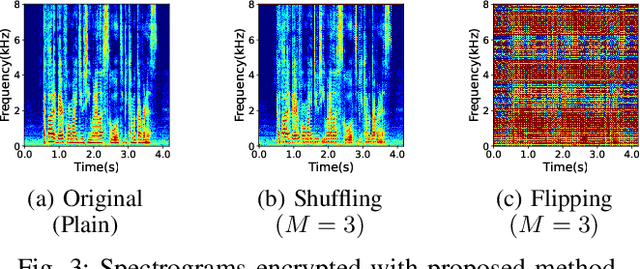
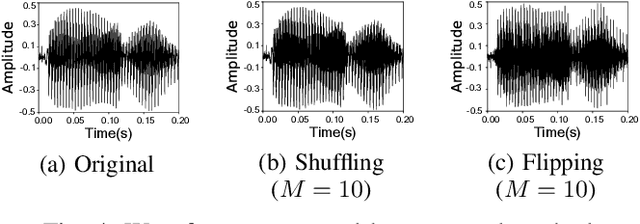
In this paper, we propose a privacy-preserving method with a secret key for convolutional neural network (CNN)-based speech classification tasks. Recently, many methods related to privacy preservation have been developed in image classification research fields. In contrast, in speech classification research fields, little research has considered these risks. To promote research on privacy preservation for speech classification, we provide an encryption method with a secret key in CNN-based speech classification systems. The encryption method is based on a random matrix with an invertible inverse. The encrypted speech data with a correct key can be accepted by a model with an encrypted kernel generated using an inverse matrix of a random matrix. Whereas the encrypted speech data is strongly distorted, the classification tasks can be correctly performed when a correct key is provided. Additionally, in this paper, we evaluate the difficulty of reconstructing the original information from the encrypted spectrograms and waveforms. In our experiments, the proposed encryption methods are performed in automatic speech recognition~(ASR) and automatic speaker verification~(ASV) tasks. The results show that the encrypted data can be used completely the same as the original data when a correct secret key is provided in the transformer-based ASR and x-vector-based ASV with self-supervised front-end systems. The robustness of the encrypted data against reconstruction attacks is also illustrated.
Optimizing Two-Pass Cross-Lingual Transfer Learning: Phoneme Recognition and Phoneme to Grapheme Translation
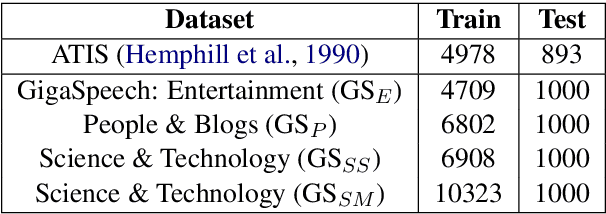
Dec 06, 2023This research optimizes two-pass cross-lingual transfer learning in low-resource languages by enhancing phoneme recognition and phoneme-to-grapheme translation models. Our approach optimizes these two stages to improve speech recognition across languages. We optimize phoneme vocabulary coverage by merging phonemes based on shared articulatory characteristics, thus improving recognition accuracy. Additionally, we introduce a global phoneme noise generator for realistic ASR noise during phoneme-to-grapheme training to reduce error propagation. Experiments on the CommonVoice 12.0 dataset show significant reductions in Word Error Rate (WER) for low-resource languages, highlighting the effectiveness of our approach. This research contributes to the advancements of two-pass ASR systems in low-resource languages, offering the potential for improved cross-lingual transfer learning.
Partial Rewriting for Multi-Stage ASR
Dec 08, 2023For many streaming automatic speech recognition tasks, it is important to provide timely intermediate streaming results, while refining a high quality final result. This can be done using a multi-stage architecture, where a small left-context only model creates streaming results and a larger left- and right-context model produces a final result at the end. While this significantly improves the quality of the final results without compromising the streaming emission latency of the system, streaming results do not benefit from the quality improvements. Here, we propose using a text manipulation algorithm that merges the streaming outputs of both models. We improve the quality of streaming results by around 10%, without altering the final results. Our approach introduces no additional latency and reduces flickering. It is also lightweight, does not require retraining the model, and it can be applied to a wide variety of multi-stage architectures.
Psychoacoustic Challenges Of Speech Enhancement On VoIP Platforms
Oct 11, 2023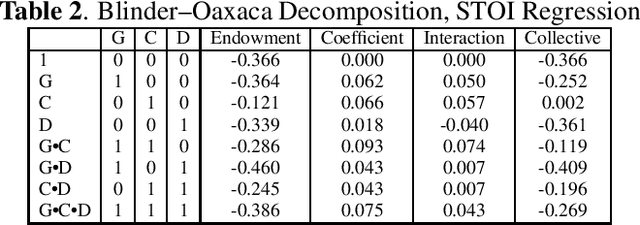
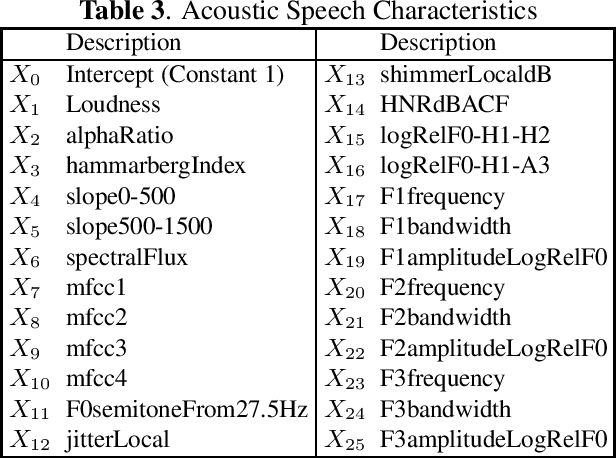

Within the ambit of VoIP (Voice over Internet Protocol) telecommunications, the complexities introduced by acoustic transformations merit rigorous analysis. This research, rooted in the exploration of proprietary sender-side denoising effects, meticulously evaluates platforms such as Google Meets and Zoom. The study draws upon the Deep Noise Suppression (DNS) 2020 dataset, ensuring a structured examination tailored to various denoising settings and receiver interfaces. A methodological novelty is introduced via the Oaxaca decomposition, traditionally an econometric tool, repurposed herein to analyze acoustic-phonetic perturbations within VoIP systems. To further ground the implications of these transformations, psychoacoustic metrics, specifically PESQ and STOI, were harnessed to furnish a comprehensive understanding of speech alterations. Cumulatively, the insights garnered underscore the intricate landscape of VoIP-influenced acoustic dynamics. In addition to the primary findings, a multitude of metrics are reported, extending the research purview. Moreover, out-of-domain benchmarking for both time and time-frequency domain speech enhancement models is included, thereby enhancing the depth and applicability of this inquiry.
Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
Oct 10, 2023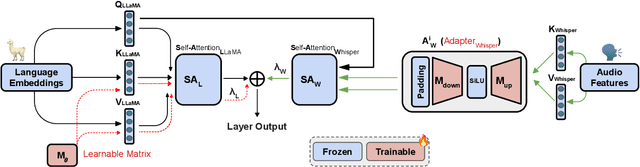
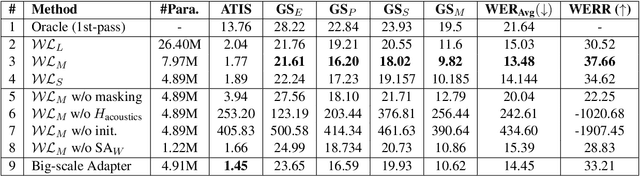
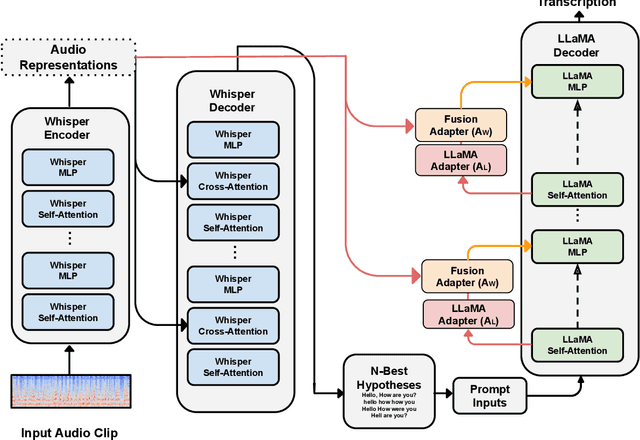
We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at https://github.com/Srijith-rkr/Whispering-LLaMA.
Loss Masking Is Not Needed in Decoder-only Transformer for Discrete-token Based ASR
Nov 08, 2023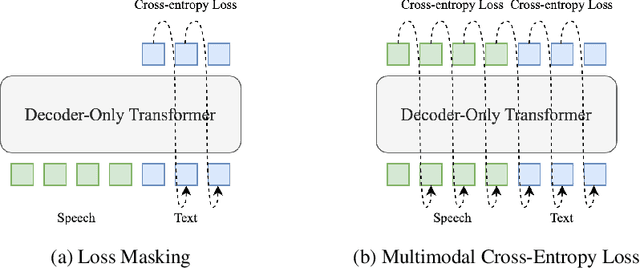
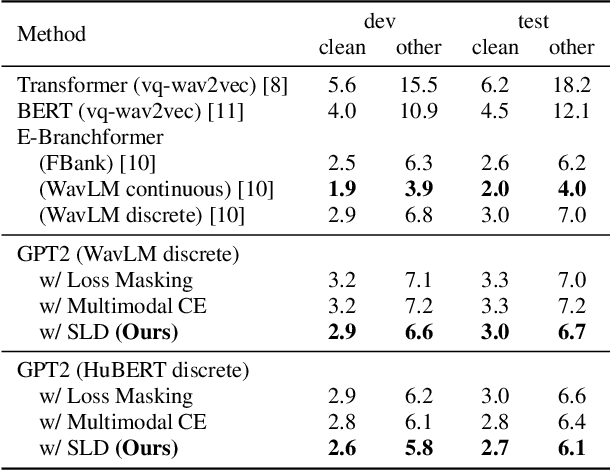
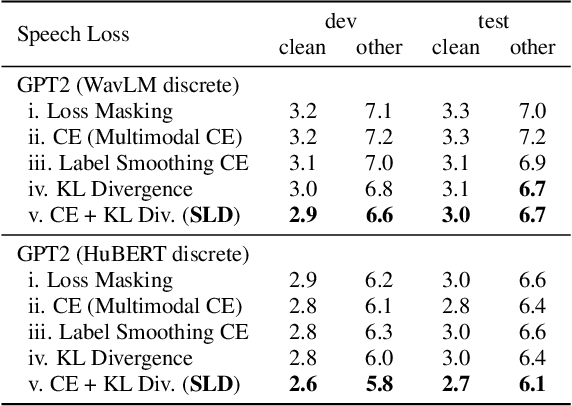
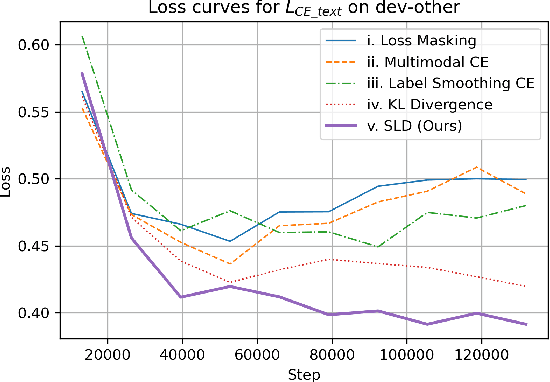
Recently, unified speech-text models, such as SpeechGPT, VioLA, and AudioPaLM, have achieved remarkable performance on speech tasks. These models convert continuous speech signals into discrete tokens (speech discretization) and merge text and speech tokens into a shared vocabulary. Then they train a single decoder-only Transformer on a mixture of speech tasks. Specifically, all these models utilize Loss Masking on the input speech tokens for the ASR task, which means that these models do not explicitly model the dependency between the speech tokens. In this paper, we attempt to model the sequence of speech tokens in an autoregressive manner like text. However, we find that applying the conventional cross-entropy loss on input speech tokens does not consistently improve the ASR performance over Loss Masking. Therefore, we propose a novel approach denoted Smoothed Label Distillation (SLD), which introduces a KL divergence loss with smoothed labels on the input speech tokens to effectively model speech tokens. Experiments demonstrate that our SLD approach alleviates the limitations of the cross-entropy loss and consistently outperforms Loss Masking for decoder-only Transformer based ASR using different speech discretization methods.
SER_AMPEL: A multi-source dataset for SER of Italian older adults
Nov 24, 2023In this paper, SER_AMPEL, a multi-source dataset for speech emotion recognition (SER) is presented. The peculiarity of the dataset is that it is collected with the aim of providing a reference for speech emotion recognition in case of Italian older adults. The dataset is collected following different protocols, in particular considering acted conversations, extracted from movies and TV series, and recording natural conversations where the emotions are elicited by proper questions. The evidence of the need for such a dataset emerges from the analysis of the state of the art. Preliminary considerations on the critical issues of SER are reported analyzing the classification results on a subset of the proposed dataset.
Unsupervised speech enhancement with diffusion-based generative models
Sep 19, 2023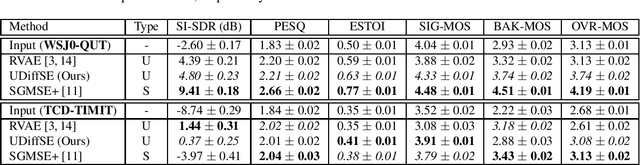
Recently, conditional score-based diffusion models have gained significant attention in the field of supervised speech enhancement, yielding state-of-the-art performance. However, these methods may face challenges when generalising to unseen conditions. To address this issue, we introduce an alternative approach that operates in an unsupervised manner, leveraging the generative power of diffusion models. Specifically, in a training phase, a clean speech prior distribution is learnt in the short-time Fourier transform (STFT) domain using score-based diffusion models, allowing it to unconditionally generate clean speech from Gaussian noise. Then, we develop a posterior sampling methodology for speech enhancement by combining the learnt clean speech prior with a noise model for speech signal inference. The noise parameters are simultaneously learnt along with clean speech estimation through an iterative expectationmaximisation (EM) approach. To the best of our knowledge, this is the first work exploring diffusion-based generative models for unsupervised speech enhancement, demonstrating promising results compared to a recent variational auto-encoder (VAE)-based unsupervised approach and a state-of-the-art diffusion-based supervised method. It thus opens a new direction for future research in unsupervised speech enhancement.
Speech Wikimedia: A 77 Language Multilingual Speech Dataset
Aug 30, 2023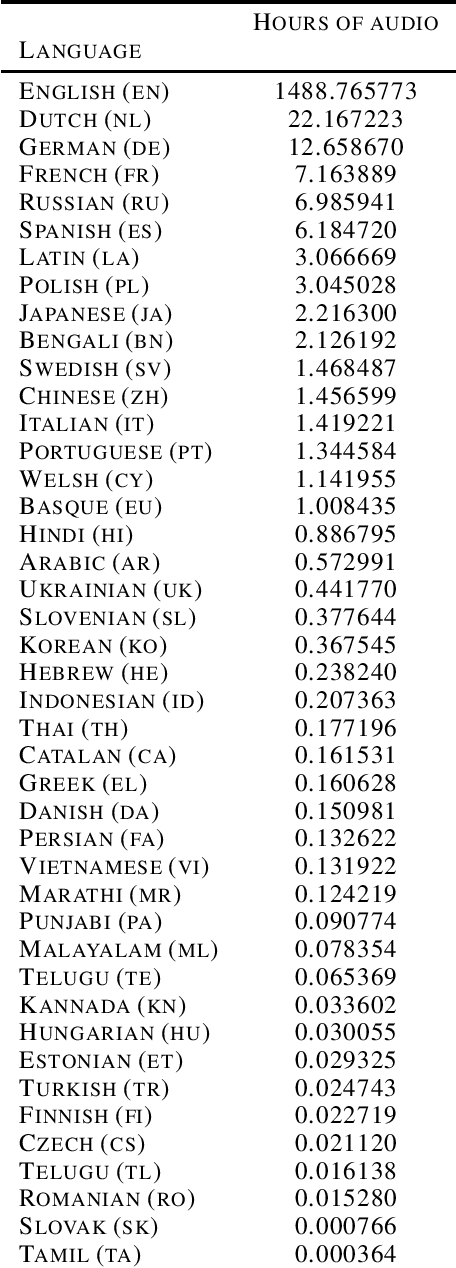
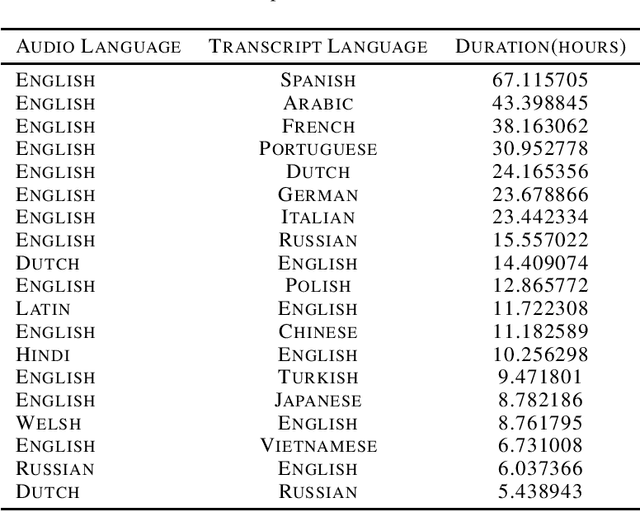
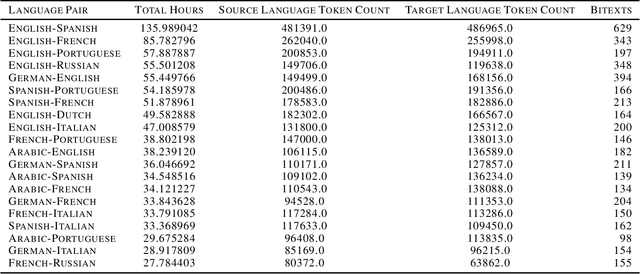
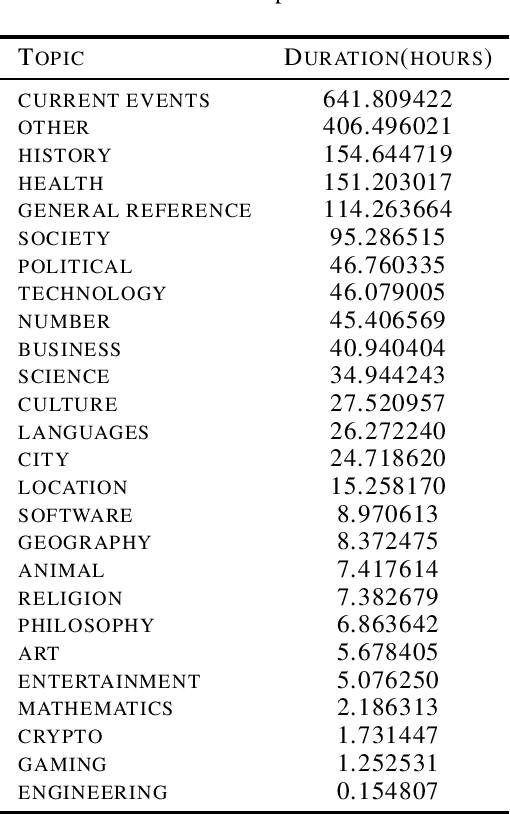
The Speech Wikimedia Dataset is a publicly available compilation of audio with transcriptions extracted from Wikimedia Commons. It includes 1780 hours (195 GB) of CC-BY-SA licensed transcribed speech from a diverse set of scenarios and speakers, in 77 different languages. Each audio file has one or more transcriptions in different languages, making this dataset suitable for training speech recognition, speech translation, and machine translation models.
Guided Flows for Generative Modeling and Decision Making
Dec 07, 2023Classifier-free guidance is a key component for enhancing the performance of conditional generative models across diverse tasks. While it has previously demonstrated remarkable improvements for the sample quality, it has only been exclusively employed for diffusion models. In this paper, we integrate classifier-free guidance into Flow Matching (FM) models, an alternative simulation-free approach that trains Continuous Normalizing Flows (CNFs) based on regressing vector fields. We explore the usage of \emph{Guided Flows} for a variety of downstream applications. We show that Guided Flows significantly improves the sample quality in conditional image generation and zero-shot text-to-speech synthesis, boasting state-of-the-art performance. Notably, we are the first to apply flow models for plan generation in the offline reinforcement learning setting, showcasing a 10x speedup in computation compared to diffusion models while maintaining comparable performance.