 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
The Impact of Silence on Speech Anti-Spoofing
Sep 21, 2023
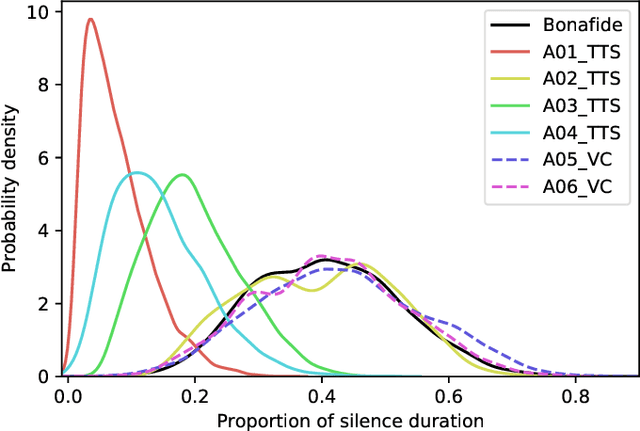
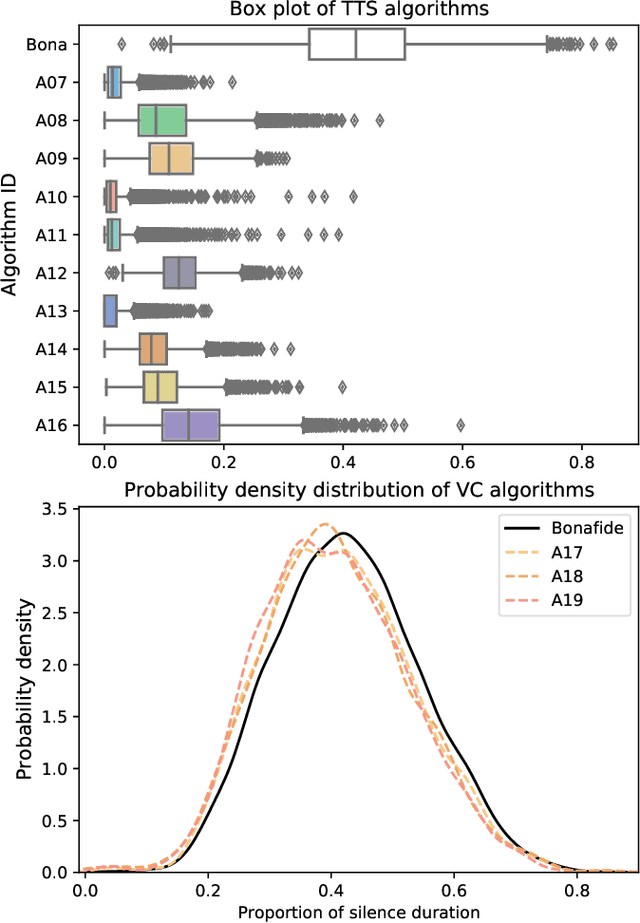
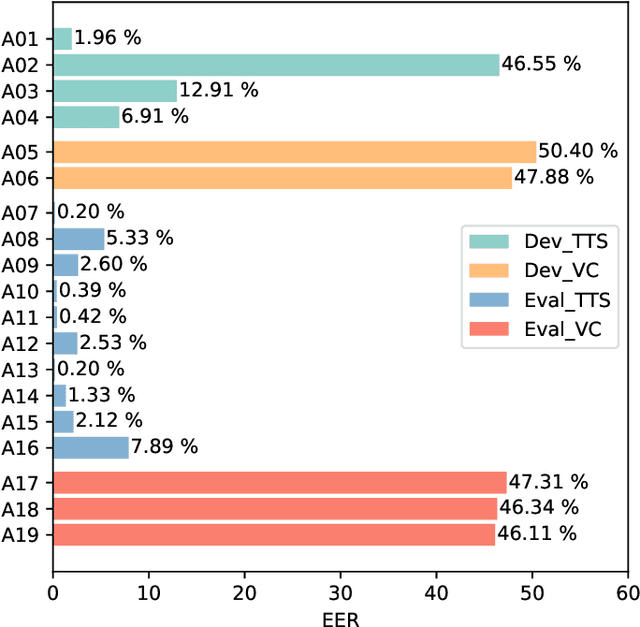
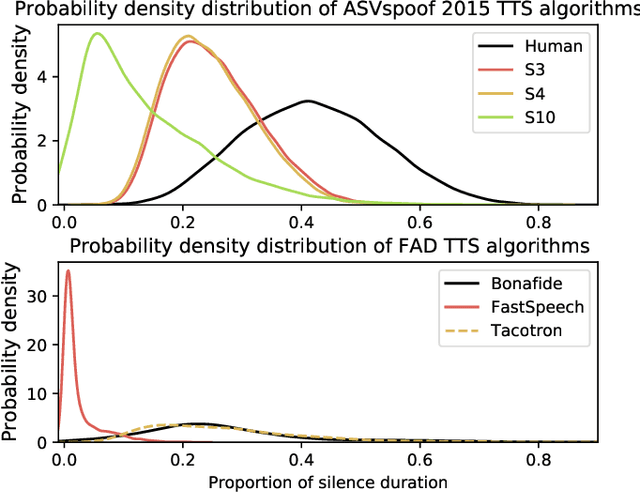
The current speech anti-spoofing countermeasures (CMs) show excellent performance on specific datasets. However, removing the silence of test speech through Voice Activity Detection (VAD) can severely degrade performance. In this paper, the impact of silence on speech anti-spoofing is analyzed. First, the reasons for the impact are explored, including the proportion of silence duration and the content of silence. The proportion of silence duration in spoof speech generated by text-to-speech (TTS) algorithms is lower than that in bonafide speech. And the content of silence generated by different waveform generators varies compared to bonafide speech. Then the impact of silence on model prediction is explored. Even after retraining, the spoof speech generated by neural network based end-to-end TTS algorithms suffers a significant rise in error rates when the silence is removed. To demonstrate the reasons for the impact of silence on CMs, the attention distribution of a CM is visualized through class activation mapping (CAM). Furthermore, the implementation and analysis of the experiments masking silence or non-silence demonstrates the significance of the proportion of silence duration for detecting TTS and the importance of silence content for detecting voice conversion (VC). Based on the experimental results, improving the robustness of CMs against unknown spoofing attacks by masking silence is also proposed. Finally, the attacks on anti-spoofing CMs through concatenating silence, and the mitigation of VAD and silence attack through low-pass filtering are introduced.
Diffusion Conditional Expectation Model for Efficient and Robust Target Speech Extraction
Sep 25, 2023Target Speech Extraction (TSE) is a crucial task in speech processing that focuses on isolating the clean speech of a specific speaker from complex mixtures. While discriminative methods are commonly used for TSE, they can introduce distortion in terms of speech perception quality. On the other hand, generative approaches, particularly diffusion-based methods, can enhance speech quality perceptually but suffer from slower inference speed. We propose an efficient generative approach named Diffusion Conditional Expectation Model (DCEM) for TSE. It can handle multi- and single-speaker scenarios in both noisy and clean conditions. Additionally, we introduce Regenerate-DCEM (R-DCEM) that can regenerate and optimize speech quality based on pre-processed speech from a discriminative model. Our method outperforms conventional methods in terms of both intrusive and non-intrusive metrics and demonstrates notable strengths in inference efficiency and robustness to unseen tasks. Audio examples are available online (https://vivian556123.github.io/dcem).
K-HATERS: A Hate Speech Detection Corpus in Korean with Target-Specific Ratings
Oct 24, 2023Numerous datasets have been proposed to combat the spread of online hate. Despite these efforts, a majority of these resources are English-centric, primarily focusing on overt forms of hate. This research gap calls for developing high-quality corpora in diverse languages that also encapsulate more subtle hate expressions. This study introduces K-HATERS, a new corpus for hate speech detection in Korean, comprising approximately 192K news comments with target-specific offensiveness ratings. This resource is the largest offensive language corpus in Korean and is the first to offer target-specific ratings on a three-point Likert scale, enabling the detection of hate expressions in Korean across varying degrees of offensiveness. We conduct experiments showing the effectiveness of the proposed corpus, including a comparison with existing datasets. Additionally, to address potential noise and bias in human annotations, we explore a novel idea of adopting the Cognitive Reflection Test, which is widely used in social science for assessing an individual's cognitive ability, as a proxy of labeling quality. Findings indicate that annotations from individuals with the lowest test scores tend to yield detection models that make biased predictions toward specific target groups and are less accurate. This study contributes to the NLP research on hate speech detection and resource construction. The code and dataset can be accessed at https://github.com/ssu-humane/K-HATERS.
Modular Speech-to-Text Translation for Zero-Shot Cross-Modal Transfer
Oct 05, 2023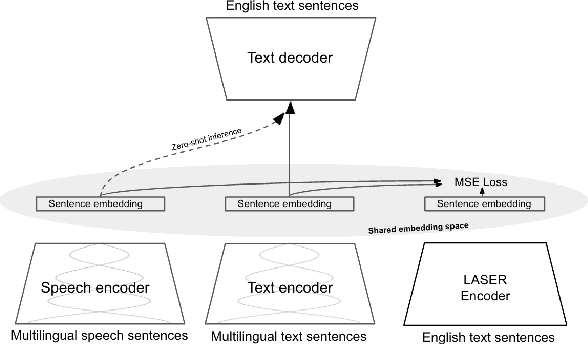
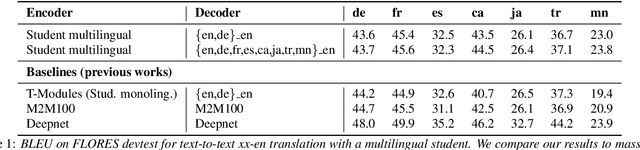

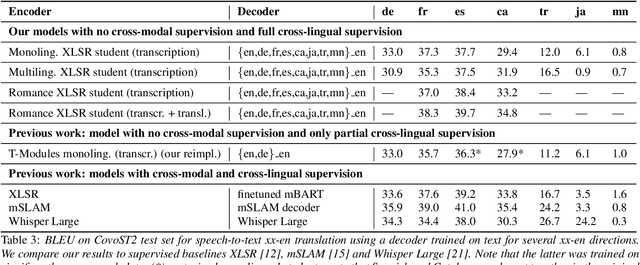
Recent research has shown that independently trained encoders and decoders, combined through a shared fixed-size representation, can achieve competitive performance in speech-to-text translation. In this work, we show that this type of approach can be further improved with multilingual training. We observe significant improvements in zero-shot cross-modal speech translation, even outperforming a supervised approach based on XLSR for several languages.
Analysis of Visual Features for Continuous Lipreading in Spanish
Nov 21, 2023During a conversation, our brain is responsible for combining information obtained from multiple senses in order to improve our ability to understand the message we are perceiving. Different studies have shown the importance of presenting visual information in these situations. Nevertheless, lipreading is a complex task whose objective is to interpret speech when audio is not available. By dispensing with a sense as crucial as hearing, it will be necessary to be aware of the challenge that this lack presents. In this paper, we propose an analysis of different speech visual features with the intention of identifying which of them is the best approach to capture the nature of lip movements for natural Spanish and, in this way, dealing with the automatic visual speech recognition task. In order to estimate our system, we present an audiovisual corpus compiled from a subset of the RTVE database, which has been used in the Albayz\'in evaluations. We employ a traditional system based on Hidden Markov Models with Gaussian Mixture Models. Results show that, although the task is difficult, in restricted conditions we obtain recognition results which determine that using eigenlips in combination with deep features is the best visual approach.
Multi-dimensional Speech Quality Assessment in Crowdsourcing
Sep 14, 2023

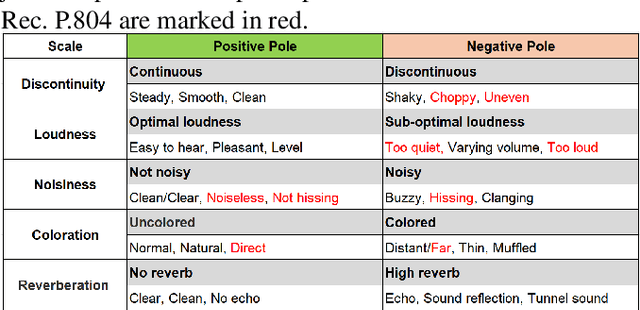
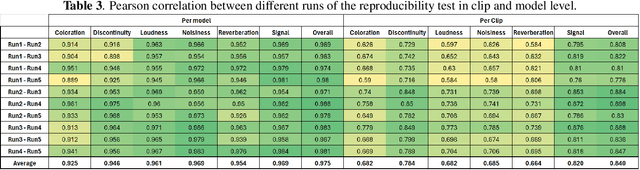
Subjective speech quality assessment is the gold standard for evaluating speech enhancement processing and telecommunication systems. The commonly used standard ITU-T Rec. P.800 defines how to measure speech quality in lab environments, and ITU-T Rec.~P.808 extended it for crowdsourcing. ITU-T Rec. P.835 extends P.800 to measure the quality of speech in the presence of noise. ITU-T Rec. P.804 targets the conversation test and introduces perceptual speech quality dimensions which are measured during the listening phase of the conversation. The perceptual dimensions are noisiness, coloration, discontinuity, and loudness. We create a crowdsourcing implementation of a multi-dimensional subjective test following the scales from P.804 and extend it to include reverberation, the speech signal, and overall quality. We show the tool is both accurate and reproducible. The tool has been used in the ICASSP 2023 Speech Signal Improvement challenge and we show the utility of these speech quality dimensions in this challenge. The tool will be publicly available as open-source at https://github.com/microsoft/P.808.
DualTalker: A Cross-Modal Dual Learning Approach for Speech-Driven 3D Facial Animation
Nov 08, 2023In recent years, audio-driven 3D facial animation has gained significant attention, particularly in applications such as virtual reality, gaming, and video conferencing. However, accurately modeling the intricate and subtle dynamics of facial expressions remains a challenge. Most existing studies approach the facial animation task as a single regression problem, which often fail to capture the intrinsic inter-modal relationship between speech signals and 3D facial animation and overlook their inherent consistency. Moreover, due to the limited availability of 3D-audio-visual datasets, approaches learning with small-size samples have poor generalizability that decreases the performance. To address these issues, in this study, we propose a cross-modal dual-learning framework, termed DualTalker, aiming at improving data usage efficiency as well as relating cross-modal dependencies. The framework is trained jointly with the primary task (audio-driven facial animation) and its dual task (lip reading) and shares common audio/motion encoder components. Our joint training framework facilitates more efficient data usage by leveraging information from both tasks and explicitly capitalizing on the complementary relationship between facial motion and audio to improve performance. Furthermore, we introduce an auxiliary cross-modal consistency loss to mitigate the potential over-smoothing underlying the cross-modal complementary representations, enhancing the mapping of subtle facial expression dynamics. Through extensive experiments and a perceptual user study conducted on the VOCA and BIWI datasets, we demonstrate that our approach outperforms current state-of-the-art methods both qualitatively and quantitatively. We have made our code and video demonstrations available at https://github.com/sabrina-su/iadf.git.
Improving Startup Success with Text Analysis
Dec 11, 2023Investors are interested in predicting future success of startup companies, preferably using publicly available data which can be gathered using free online sources. Using public-only data has been shown to work, but there is still much room for improvement. Two of the best performing prediction experiments use 17 and 49 features respectively, mostly numeric and categorical in nature. In this paper, we significantly expand and diversify both the sources and the number of features (to 171) to achieve better prediction. Data collected from Crunchbase, the Google Search API, and Twitter (now X) are used to predict whether a company will raise a round of funding within a fixed time horizon. Much of the new features are textual and the Twitter subset include linguistic metrics such as measures of passive voice and parts-of-speech. A total of ten machine learning models are also evaluated for best performance. The adaptable model can be used to predict funding 1-5 years into the future, with a variable cutoff threshold to favor either precision or recall. Prediction with comparable assumptions generally achieves F scores above 0.730 which outperforms previous attempts in the literature (0.531), and does so with fewer examples. Furthermore, we find that the vast majority of the performance impact comes from the top 18 of 171 features which are mostly generic company observations, including the best performing individual feature which is the free-form text description of the company.
XLS-R fine-tuning on noisy word boundaries for unsupervised speech segmentation into words
Oct 08, 2023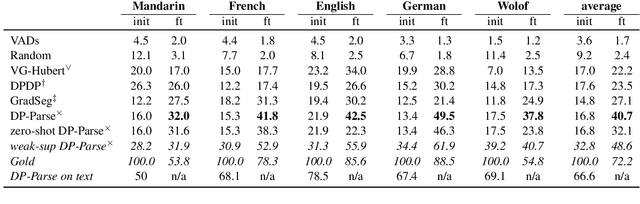
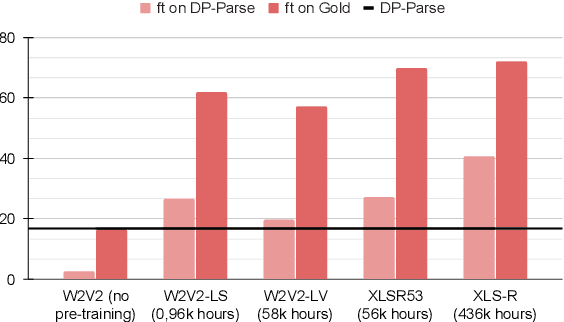
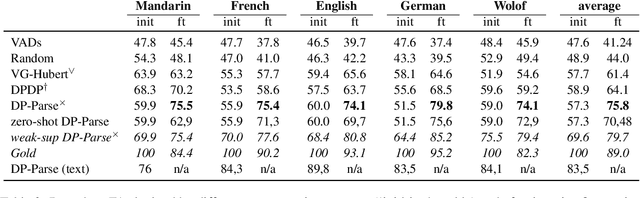
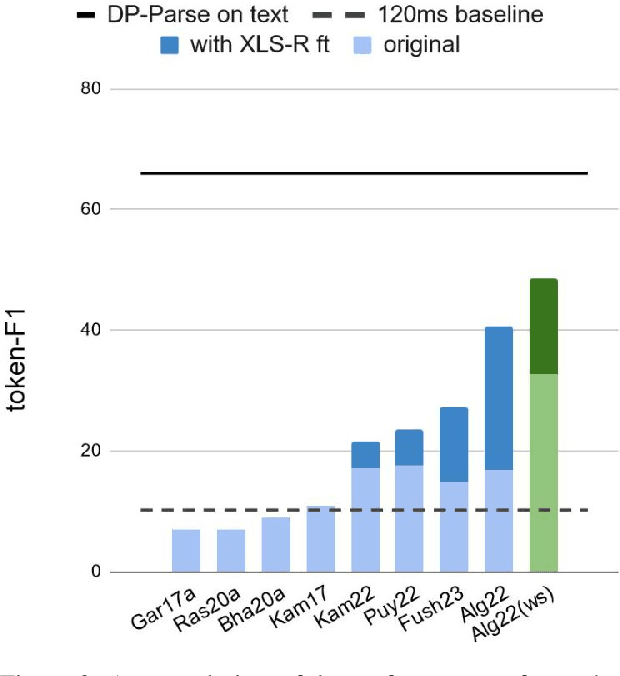
Due to the absence of explicit word boundaries in the speech stream, the task of segmenting spoken sentences into word units without text supervision is particularly challenging. In this work, we leverage the most recent self-supervised speech models that have proved to quickly adapt to new tasks through fine-tuning, even in low resource conditions. Taking inspiration from semi-supervised learning, we fine-tune an XLS-R model to predict word boundaries themselves produced by top-tier speech segmentation systems: DPDP, VG-HuBERT, GradSeg and DP-Parse. Once XLS-R is fine-tuned, it is used to infer new word boundary labels that are used in turn for another fine-tuning step. Our method consistently improves the performance of each system and sets a new state-of-the-art that is, on average 130% higher than the previous one as measured by the F1 score on correctly discovered word tokens on five corpora featuring different languages. Finally, our system can segment speech from languages unseen during fine-tuning in a zero-shot fashion.
A Comprehensive Survey on Multi-modal Conversational Emotion Recognition with Deep Learning
Dec 10, 2023Multi-modal conversation emotion recognition (MCER) aims to recognize and track the speaker's emotional state using text, speech, and visual information in the conversation scene. Analyzing and studying MCER issues is significant to affective computing, intelligent recommendations, and human-computer interaction fields. Unlike the traditional single-utterance multi-modal emotion recognition or single-modal conversation emotion recognition, MCER is a more challenging problem that needs to deal with more complex emotional interaction relationships. The critical issue is learning consistency and complementary semantics for multi-modal feature fusion based on emotional interaction relationships. To solve this problem, people have conducted extensive research on MCER based on deep learning technology, but there is still a lack of systematic review of the modeling methods. Therefore, a timely and comprehensive overview of MCER's recent advances in deep learning is of great significance to academia and industry. In this survey, we provide a comprehensive overview of MCER modeling methods and roughly divide MCER methods into four categories, i.e., context-free modeling, sequential context modeling, speaker-differentiated modeling, and speaker-relationship modeling. In addition, we further discuss MCER's publicly available popular datasets, multi-modal feature extraction methods, application areas, existing challenges, and future development directions. We hope that our review can help MCER researchers understand the current research status in emotion recognition, provide some inspiration, and develop more efficient models.