 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Phonological Level wav2vec2-based Mispronunciation Detection and Diagnosis Method
Nov 13, 2023
The automatic identification and analysis of pronunciation errors, known as Mispronunciation Detection and Diagnosis (MDD) plays a crucial role in Computer Aided Pronunciation Learning (CAPL) tools such as Second-Language (L2) learning or speech therapy applications. Existing MDD methods relying on analysing phonemes can only detect categorical errors of phonemes that have an adequate amount of training data to be modelled. With the unpredictable nature of the pronunciation errors of non-native or disordered speakers and the scarcity of training datasets, it is unfeasible to model all types of mispronunciations. Moreover, phoneme-level MDD approaches have a limited ability to provide detailed diagnostic information about the error made. In this paper, we propose a low-level MDD approach based on the detection of speech attribute features. Speech attribute features break down phoneme production into elementary components that are directly related to the articulatory system leading to more formative feedback to the learner. We further propose a multi-label variant of the Connectionist Temporal Classification (CTC) approach to jointly model the non-mutually exclusive speech attributes using a single model. The pre-trained wav2vec2 model was employed as a core model for the speech attribute detector. The proposed method was applied to L2 speech corpora collected from English learners from different native languages. The proposed speech attribute MDD method was further compared to the traditional phoneme-level MDD and achieved a significantly lower False Acceptance Rate (FAR), False Rejection Rate (FRR), and Diagnostic Error Rate (DER) over all speech attributes compared to the phoneme-level equivalent.
Speech-to-Speech Translation with Discrete-Unit-Based Style Transfer
Sep 14, 2023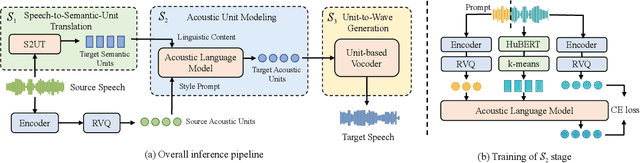
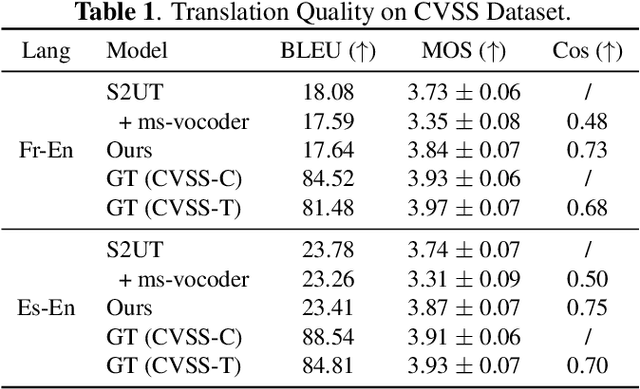
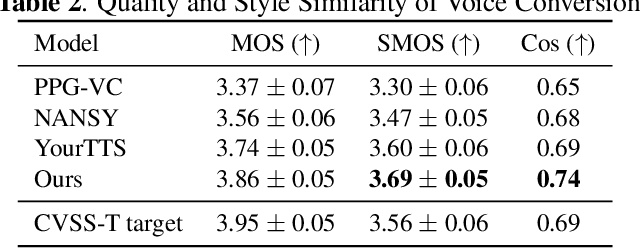
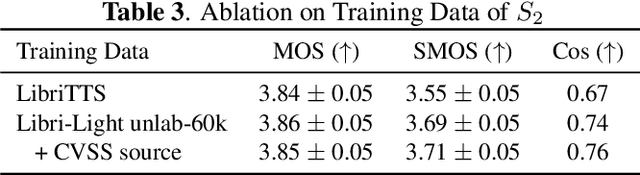
Direct speech-to-speech translation (S2ST) with discrete self-supervised representations has achieved remarkable accuracy, but is unable to preserve the speaker timbre of the source speech during translation. Meanwhile, the scarcity of high-quality speaker-parallel data poses a challenge for learning style transfer between source and target speech. We propose an S2ST framework with an acoustic language model based on discrete units from a self-supervised model and a neural codec for style transfer. The acoustic language model leverages self-supervised in-context learning, acquiring the ability for style transfer without relying on any speaker-parallel data, thereby overcoming the issue of data scarcity. By using extensive training data, our model achieves zero-shot cross-lingual style transfer on previously unseen source languages. Experiments show that our model generates translated speeches with high fidelity and style similarity. Audio samples are available at http://stylelm.github.io/ .
AutoPrep: An Automatic Preprocessing Framework for In-the-Wild Speech Data
Sep 25, 2023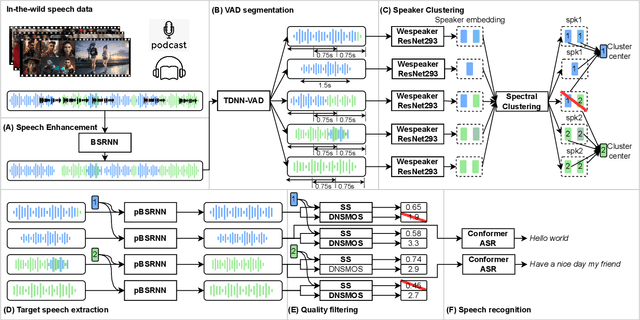
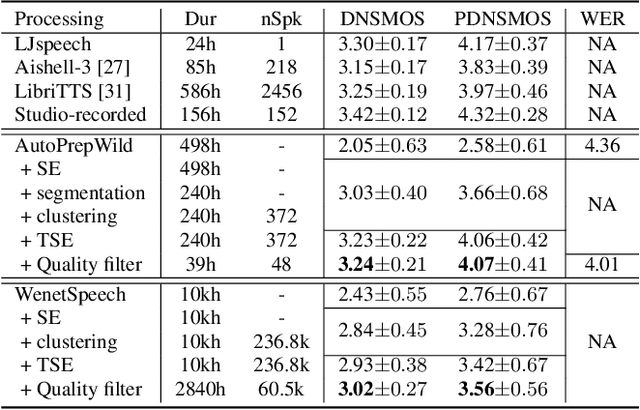

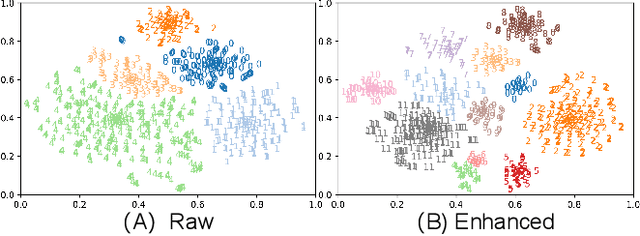
Recently, the utilization of extensive open-sourced text data has significantly advanced the performance of text-based large language models (LLMs). However, the use of in-the-wild large-scale speech data in the speech technology community remains constrained. One reason for this limitation is that a considerable amount of the publicly available speech data is compromised by background noise, speech overlapping, lack of speech segmentation information, missing speaker labels, and incomplete transcriptions, which can largely hinder their usefulness. On the other hand, human annotation of speech data is both time-consuming and costly. To address this issue, we introduce an automatic in-the-wild speech data preprocessing framework (AutoPrep) in this paper, which is designed to enhance speech quality, generate speaker labels, and produce transcriptions automatically. The proposed AutoPrep framework comprises six components: speech enhancement, speech segmentation, speaker clustering, target speech extraction, quality filtering and automatic speech recognition. Experiments conducted on the open-sourced WenetSpeech and our self-collected AutoPrepWild corpora demonstrate that the proposed AutoPrep framework can generate preprocessed data with similar DNSMOS and PDNSMOS scores compared to several open-sourced TTS datasets. The corresponding TTS system can achieve up to 0.68 in-domain speaker similarity.
Improving Startup Success with Text Analysis
Dec 11, 2023Investors are interested in predicting future success of startup companies, preferably using publicly available data which can be gathered using free online sources. Using public-only data has been shown to work, but there is still much room for improvement. Two of the best performing prediction experiments use 17 and 49 features respectively, mostly numeric and categorical in nature. In this paper, we significantly expand and diversify both the sources and the number of features (to 171) to achieve better prediction. Data collected from Crunchbase, the Google Search API, and Twitter (now X) are used to predict whether a company will raise a round of funding within a fixed time horizon. Much of the new features are textual and the Twitter subset include linguistic metrics such as measures of passive voice and parts-of-speech. A total of ten machine learning models are also evaluated for best performance. The adaptable model can be used to predict funding 1-5 years into the future, with a variable cutoff threshold to favor either precision or recall. Prediction with comparable assumptions generally achieves F scores above 0.730 which outperforms previous attempts in the literature (0.531), and does so with fewer examples. Furthermore, we find that the vast majority of the performance impact comes from the top 18 of 171 features which are mostly generic company observations, including the best performing individual feature which is the free-form text description of the company.
Modeling of Speech-dependent Own Voice Transfer Characteristics for Hearables with In-ear Microphones
Oct 10, 2023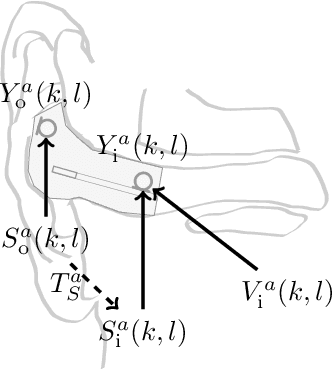
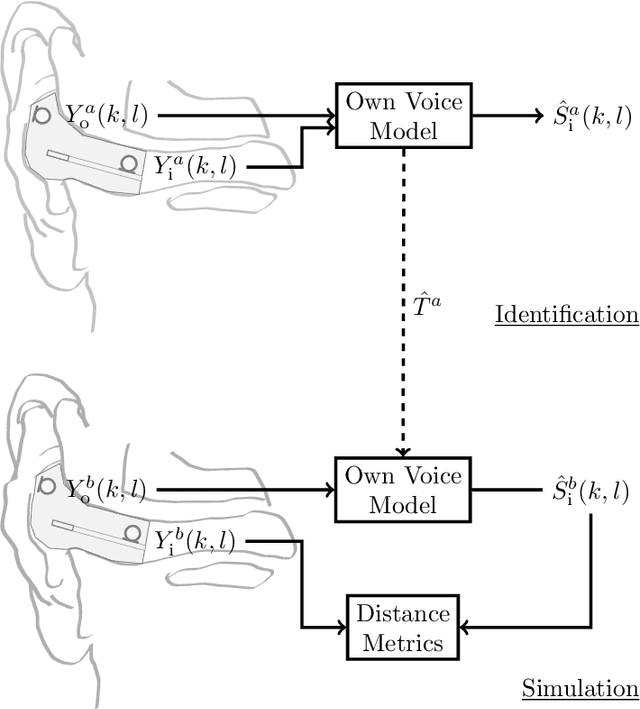
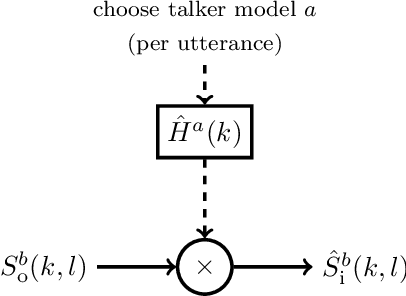
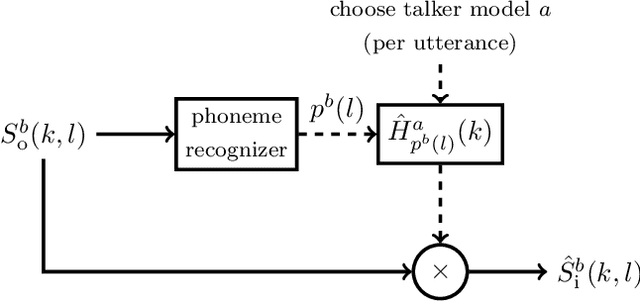
Hearables often contain an in-ear microphone, which may be used to capture the own voice of its user. However, due to ear canal occlusion the in-ear microphone mostly records body-conducted speech, which suffers from band-limitation effects and is subject to amplification of low frequency content. These transfer characteristics are assumed to vary both based on speech content and between individual talkers. It is desirable to have an accurate model of the own voice transfer characteristics between hearable microphones. Such a model can be used, e.g., to simulate a large amount of in-ear recordings to train supervised learning-based algorithms aiming at compensating own voice transfer characteristics. In this paper we propose a speech-dependent system identification model based on phoneme recognition. Using recordings from a prototype hearable, the modeling accuracy is evaluated in terms of technical measures. We investigate robustness of transfer characteristic models to utterance or talker mismatch. Simulation results show that using the proposed speech-dependent model is preferable for simulating in-ear recordings compared to a speech-independent model. The proposed model is able to generalize better to new utterances than an adaptive filtering-based model. Additionally, we find that talker-averaged models generalize better to different talkers than individual models.
A Comprehensive Survey on Multi-modal Conversational Emotion Recognition with Deep Learning
Dec 10, 2023Multi-modal conversation emotion recognition (MCER) aims to recognize and track the speaker's emotional state using text, speech, and visual information in the conversation scene. Analyzing and studying MCER issues is significant to affective computing, intelligent recommendations, and human-computer interaction fields. Unlike the traditional single-utterance multi-modal emotion recognition or single-modal conversation emotion recognition, MCER is a more challenging problem that needs to deal with more complex emotional interaction relationships. The critical issue is learning consistency and complementary semantics for multi-modal feature fusion based on emotional interaction relationships. To solve this problem, people have conducted extensive research on MCER based on deep learning technology, but there is still a lack of systematic review of the modeling methods. Therefore, a timely and comprehensive overview of MCER's recent advances in deep learning is of great significance to academia and industry. In this survey, we provide a comprehensive overview of MCER modeling methods and roughly divide MCER methods into four categories, i.e., context-free modeling, sequential context modeling, speaker-differentiated modeling, and speaker-relationship modeling. In addition, we further discuss MCER's publicly available popular datasets, multi-modal feature extraction methods, application areas, existing challenges, and future development directions. We hope that our review can help MCER researchers understand the current research status in emotion recognition, provide some inspiration, and develop more efficient models.
R-Spin: Efficient Speaker and Noise-invariant Representation Learning with Acoustic Pieces
Nov 15, 2023This paper introduces Robust Spin (R-Spin), a data-efficient self-supervised fine-tuning framework for speaker and noise-invariant speech representations by learning discrete acoustic units with speaker-invariant clustering (Spin). R-Spin resolves Spin's issues and enhances content representations by learning to predict acoustic pieces. R-Spin offers a 12X reduction in computational resources compared to previous state-of-the-art methods while outperforming them in severely distorted speech scenarios. This paper provides detailed analyses to show how discrete units contribute to speech encoder training and improving robustness in diverse acoustic environments.
MixRep: Hidden Representation Mixup for Low-Resource Speech Recognition
Oct 27, 2023In this paper, we present MixRep, a simple and effective data augmentation strategy based on mixup for low-resource ASR. MixRep interpolates the feature dimensions of hidden representations in the neural network that can be applied to both the acoustic feature input and the output of each layer, which generalizes the previous MixSpeech method. Further, we propose to combine the mixup with a regularization along the time axis of the input, which is shown as complementary. We apply MixRep to a Conformer encoder of an E2E LAS architecture trained with a joint CTC loss. We experiment on the WSJ dataset and subsets of the SWB dataset, covering reading and telephony conversational speech. Experimental results show that MixRep consistently outperforms other regularization methods for low-resource ASR. Compared to a strong SpecAugment baseline, MixRep achieves a +6.5\% and a +6.7\% relative WER reduction on the eval92 set and the Callhome part of the eval'2000 set.
Psychoacoustic Challenges Of Speech Enhancement On VoIP Platforms
Oct 11, 2023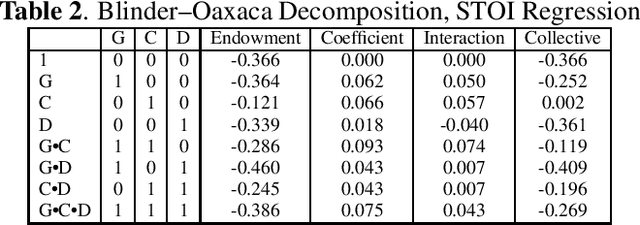

Within the ambit of VoIP (Voice over Internet Protocol) telecommunications, the complexities introduced by acoustic transformations merit rigorous analysis. This research, rooted in the exploration of proprietary sender-side denoising effects, meticulously evaluates platforms such as Google Meets and Zoom. The study draws upon the Deep Noise Suppression (DNS) 2020 dataset, ensuring a structured examination tailored to various denoising settings and receiver interfaces. A methodological novelty is introduced via the Oaxaca decomposition, traditionally an econometric tool, repurposed herein to analyze acoustic-phonetic perturbations within VoIP systems. To further ground the implications of these transformations, psychoacoustic metrics, specifically PESQ and STOI, were harnessed to furnish a comprehensive understanding of speech alterations. Cumulatively, the insights garnered underscore the intricate landscape of VoIP-influenced acoustic dynamics. In addition to the primary findings, a multitude of metrics are reported, extending the research purview. Moreover, out-of-domain benchmarking for both time and time-frequency domain speech enhancement models is included, thereby enhancing the depth and applicability of this inquiry.
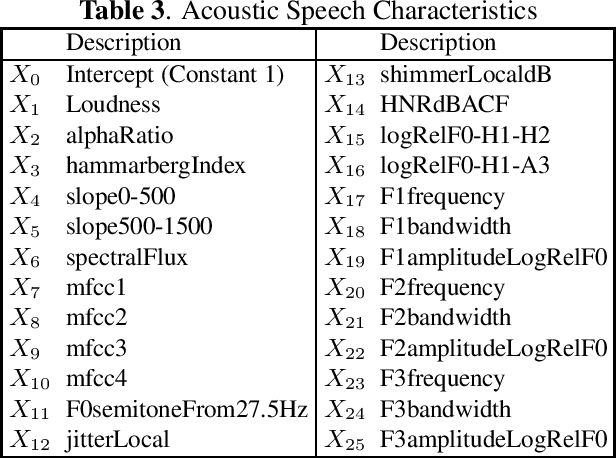
A privacy-preserving method using secret key for convolutional neural network-based speech classification
Oct 06, 2023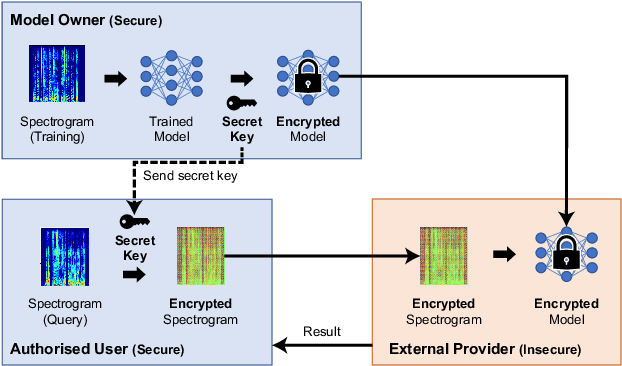
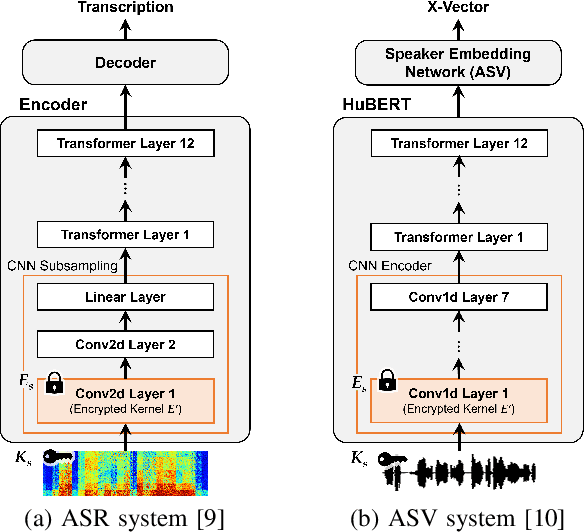
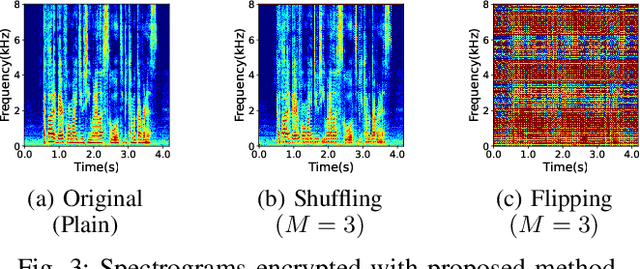
In this paper, we propose a privacy-preserving method with a secret key for convolutional neural network (CNN)-based speech classification tasks. Recently, many methods related to privacy preservation have been developed in image classification research fields. In contrast, in speech classification research fields, little research has considered these risks. To promote research on privacy preservation for speech classification, we provide an encryption method with a secret key in CNN-based speech classification systems. The encryption method is based on a random matrix with an invertible inverse. The encrypted speech data with a correct key can be accepted by a model with an encrypted kernel generated using an inverse matrix of a random matrix. Whereas the encrypted speech data is strongly distorted, the classification tasks can be correctly performed when a correct key is provided. Additionally, in this paper, we evaluate the difficulty of reconstructing the original information from the encrypted spectrograms and waveforms. In our experiments, the proposed encryption methods are performed in automatic speech recognition~(ASR) and automatic speaker verification~(ASV) tasks. The results show that the encrypted data can be used completely the same as the original data when a correct secret key is provided in the transformer-based ASR and x-vector-based ASV with self-supervised front-end systems. The robustness of the encrypted data against reconstruction attacks is also illustrated.