 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Collaborative Learning with Artificial Intelligence Speakers (CLAIS): Pre-Service Elementary Science Teachers' Responses to the Prototype
Dec 20, 2023
This research aims to demonstrate that AI can function not only as a tool for learning, but also as an intelligent agent with which humans can engage in collaborative learning (CL) to change epistemic practices in science classrooms. We adopted a design and development research approach, following the Analysis, Design, Development, Implementation and Evaluation (ADDIE) model, to prototype a tangible instructional system called Collaborative Learning with AI Speakers (CLAIS). The CLAIS system is designed to have 3-4 human learners join an AI speaker to form a small group, where humans and AI are considered as peers participating in the Jigsaw learning process. The development was carried out using the NUGU AI speaker platform. The CLAIS system was successfully implemented in a Science Education course session with 15 pre-service elementary science teachers. The participants evaluated the CLAIS system through mixed methods surveys as teachers, learners, peers, and users. Quantitative data showed that the participants' Intelligent-Technological, Pedagogical, And Content Knowledge was significantly increased after the CLAIS session, the perception of the CLAIS learning experience was positive, the peer assessment on AI speakers and human peers was different, and the user experience was ambivalent. Qualitative data showed that the participants anticipated future changes in the epistemic process in science classrooms, while acknowledging technical issues such as speech recognition performance and response latency. This study highlights the potential of Human-AI Collaboration for knowledge co-construction in authentic classroom settings and exemplify how AI could shape the future landscape of epistemic practices in the classroom.
Label Smoothing for Enhanced Text Sentiment Classification
Dec 11, 2023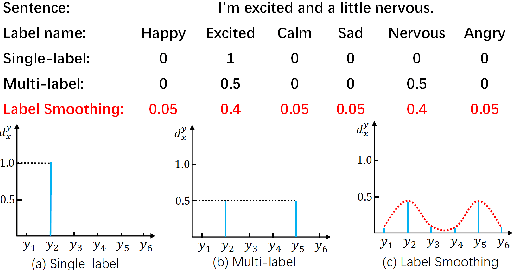

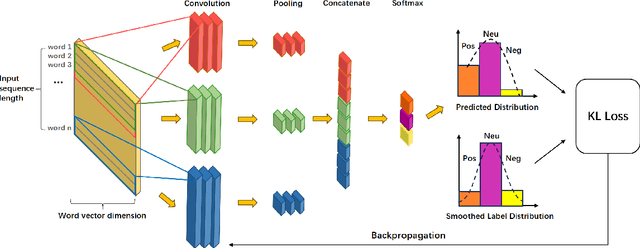
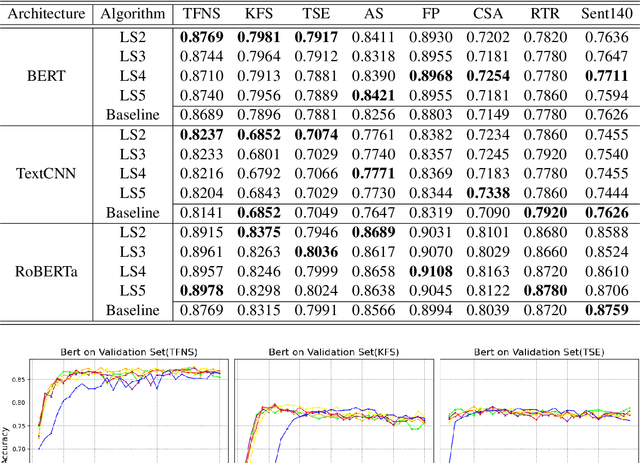
Label smoothing is a widely used technique in various domains, such as image classification and speech recognition, known for effectively combating model overfitting. However, there is few research on its application to text sentiment classification. To fill in the gap, this study investigates the implementation of label smoothing for sentiment classification by utilizing different levels of smoothing. The primary objective is to enhance sentiment classification accuracy by transforming discrete labels into smoothed label distributions. Through extensive experiments, we demonstrate the superior performance of label smoothing in text sentiment classification tasks across eight diverse datasets and deep learning architectures: TextCNN, BERT, and RoBERTa, under two learning schemes: training from scratch and fine-tuning.
Audio Deepfake Detection with Self-Supervised WavLM and Multi-Fusion Attentive Classifier
Dec 13, 2023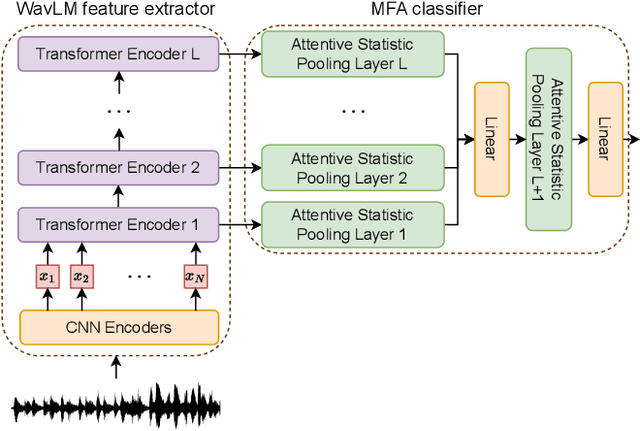
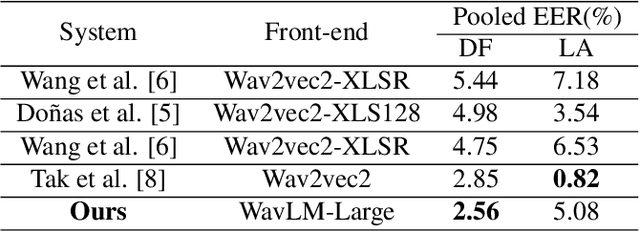
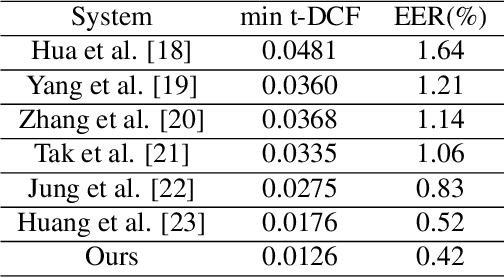

With the rapid development of speech synthesis and voice conversion technologies, Audio Deepfake has become a serious threat to the Automatic Speaker Verification (ASV) system. Numerous countermeasures are proposed to detect this type of attack. In this paper, we report our efforts to combine the self-supervised WavLM model and Multi-Fusion Attentive classifier for audio deepfake detection. Our method exploits the WavLM model to extract features that are more conducive to spoofing detection for the first time. Then, we propose a novel Multi-Fusion Attentive (MFA) classifier based on the Attentive Statistics Pooling (ASP) layer. The MFA captures the complementary information of audio features at both time and layer levels. Experiments demonstrate that our methods achieve state-of-the-art results on the ASVspoof 2021 DF set and provide competitive results on the ASVspoof 2019 and 2021 LA set.
Voxtlm: unified decoder-only models for consolidating speech recognition/synthesis and speech/text continuation tasks
Sep 18, 2023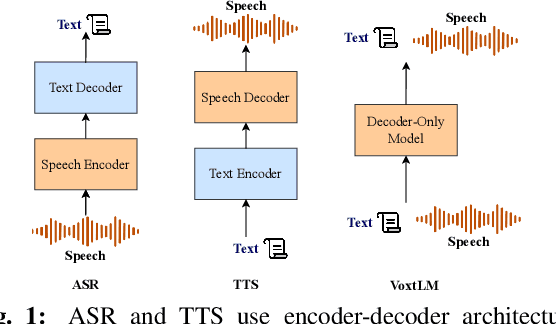

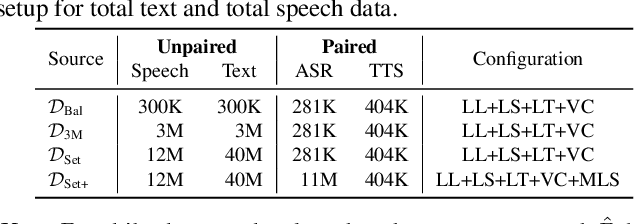

We propose a decoder-only language model, \textit{VoxtLM}, that can perform four tasks: speech recognition, speech synthesis, text generation, and speech continuation. VoxtLM integrates text vocabulary with discrete speech tokens from self-supervised speech features and uses special tokens to enable multitask learning. Compared to a single-task model, VoxtLM exhibits a significant improvement in speech synthesis, with improvements in both speech intelligibility from 28.9 to 5.6 and objective quality from 2.68 to 3.90. VoxtLM also improves speech generation and speech recognition performance over the single-task counterpart. VoxtLM is trained with publicly available data and training recipes and model checkpoints will be open-sourced to make fully reproducible work.
Deep Beamforming for Speech Enhancement and Speaker Localization with an Array Response-Aware Loss Function
Oct 22, 2023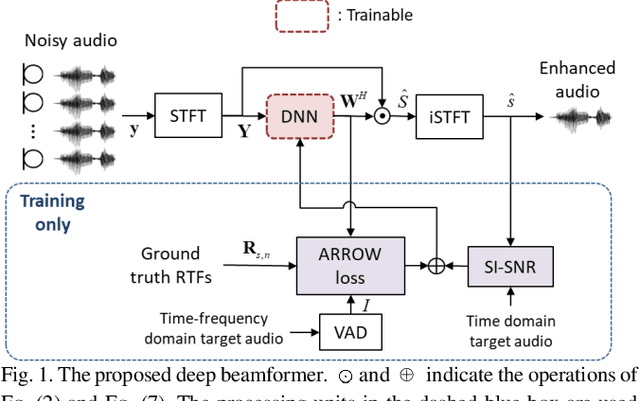
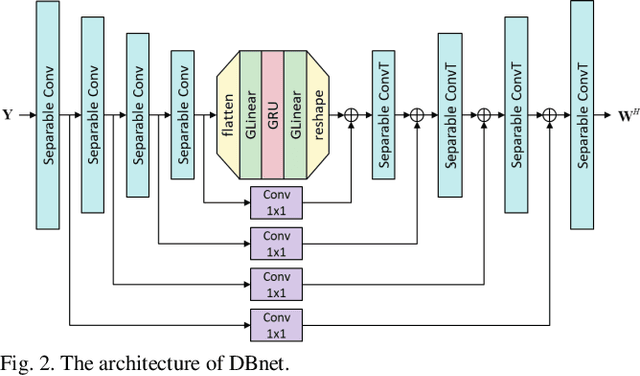
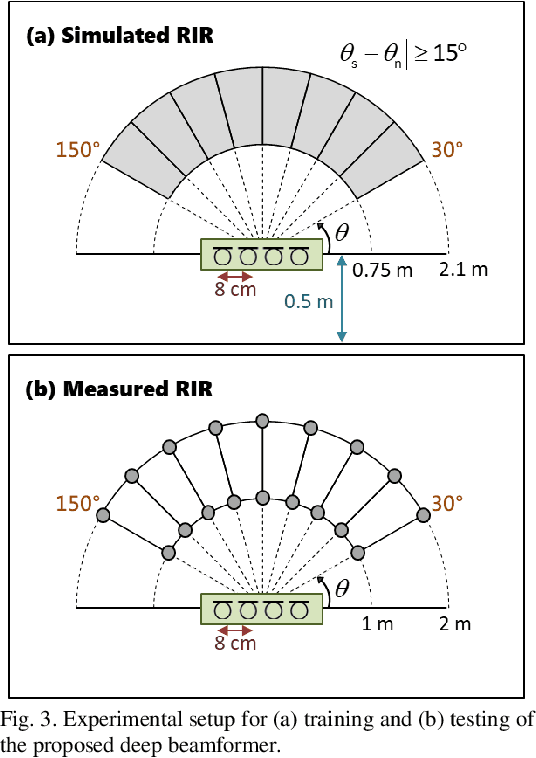
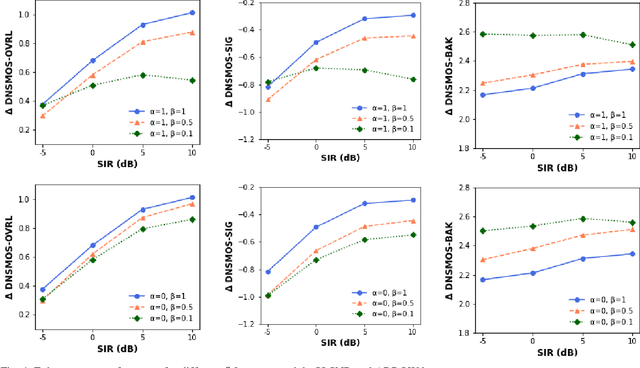
Recent research advances in deep neural network (DNN)-based beamformers have shown great promise for speech enhancement under adverse acoustic conditions. Different network architectures and input features have been explored in estimating beamforming weights. In this paper, we propose a deep beamformer based on an efficient convolutional recurrent network (CRN) trained with a novel ARray RespOnse-aWare (ARROW) loss function. The ARROW loss exploits the array responses of the target and interferer by using the ground truth relative transfer functions (RTFs). The DNN-based beamforming system, trained with ARROW loss through supervised learning, is able to perform speech enhancement and speaker localization jointly. Experimental results have shown that the proposed deep beamformer, trained with the linearly weighted scale-invariant source-to-noise ratio (SI-SNR) and ARROW loss functions, achieves superior performance in speech enhancement and speaker localization compared to two baselines.
Understanding Probe Behaviors through Variational Bounds of Mutual Information
Dec 15, 2023With the success of self-supervised representations, researchers seek a better understanding of the information encapsulated within a representation. Among various interpretability methods, we focus on classification-based linear probing. We aim to foster a solid understanding and provide guidelines for linear probing by constructing a novel mathematical framework leveraging information theory. First, we connect probing with the variational bounds of mutual information (MI) to relax the probe design, equating linear probing with fine-tuning. Then, we investigate empirical behaviors and practices of probing through our mathematical framework. We analyze the layer-wise performance curve being convex, which seemingly violates the data processing inequality. However, we show that the intermediate representations can have the biggest MI estimate because of the tradeoff between better separability and decreasing MI. We further suggest that the margin of linearly separable representations can be a criterion for measuring the "goodness of representation." We also compare accuracy with MI as the measuring criteria. Finally, we empirically validate our claims by observing the self-supervised speech models on retaining word and phoneme information.
Homophone Disambiguation Reveals Patterns of Context Mixing in Speech Transformers
Oct 15, 2023Transformers have become a key architecture in speech processing, but our understanding of how they build up representations of acoustic and linguistic structure is limited. In this study, we address this gap by investigating how measures of 'context-mixing' developed for text models can be adapted and applied to models of spoken language. We identify a linguistic phenomenon that is ideal for such a case study: homophony in French (e.g. livre vs livres), where a speech recognition model has to attend to syntactic cues such as determiners and pronouns in order to disambiguate spoken words with identical pronunciations and transcribe them while respecting grammatical agreement. We perform a series of controlled experiments and probing analyses on Transformer-based speech models. Our findings reveal that representations in encoder-only models effectively incorporate these cues to identify the correct transcription, whereas encoders in encoder-decoder models mainly relegate the task of capturing contextual dependencies to decoder modules.
PerMod: Perceptually Grounded Voice Modification with Latent Diffusion Models
Dec 13, 2023Perceptual modification of voice is an elusive goal. While non-experts can modify an image or sentence perceptually with available tools, it is not clear how to similarly modify speech along perceptual axes. Voice conversion does make it possible to convert one voice to another, but these modifications are handled by black box models, and the specifics of what perceptual qualities to modify and how to modify them are unclear. Towards allowing greater perceptual control over voice, we introduce PerMod, a conditional latent diffusion model that takes in an input voice and a perceptual qualities vector, and produces a voice with the matching perceptual qualities. Unlike prior work, PerMod generates a new voice corresponding to specific perceptual modifications. Evaluating perceptual quality vectors with RMSE from both human and predicted labels, we demonstrate that PerMod produces voices with the desired perceptual qualities for typical voices, but performs poorly on atypical voices.
Do self-supervised speech and language models extract similar representations as human brain?
Oct 07, 2023Speech and language models trained through self-supervised learning (SSL) demonstrate strong alignment with brain activity during speech and language perception. However, given their distinct training modalities, it remains unclear whether they correlate with the same neural aspects. We directly address this question by evaluating the brain prediction performance of two representative SSL models, Wav2Vec2.0 and GPT-2, designed for speech and language tasks. Our findings reveal that both models accurately predict speech responses in the auditory cortex, with a significant correlation between their brain predictions. Notably, shared speech contextual information between Wav2Vec2.0 and GPT-2 accounts for the majority of explained variance in brain activity, surpassing static semantic and lower-level acoustic-phonetic information. These results underscore the convergence of speech contextual representations in SSL models and their alignment with the neural network underlying speech perception, offering valuable insights into both SSL models and the neural basis of speech and language processing.
JVNV: A Corpus of Japanese Emotional Speech with Verbal Content and Nonverbal Expressions
Oct 09, 2023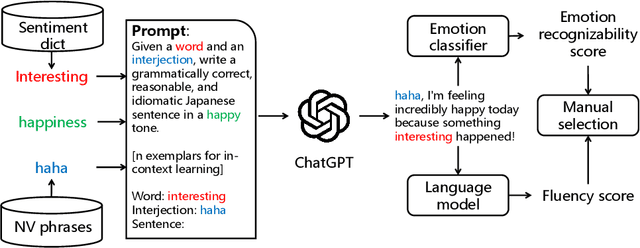


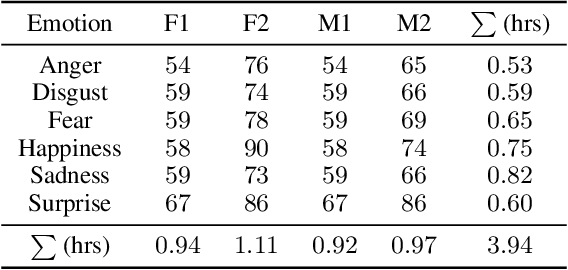
We present the JVNV, a Japanese emotional speech corpus with verbal content and nonverbal vocalizations whose scripts are generated by a large-scale language model. Existing emotional speech corpora lack not only proper emotional scripts but also nonverbal vocalizations (NVs) that are essential expressions in spoken language to express emotions. We propose an automatic script generation method to produce emotional scripts by providing seed words with sentiment polarity and phrases of nonverbal vocalizations to ChatGPT using prompt engineering. We select 514 scripts with balanced phoneme coverage from the generated candidate scripts with the assistance of emotion confidence scores and language fluency scores. We demonstrate the effectiveness of JVNV by showing that JVNV has better phoneme coverage and emotion recognizability than previous Japanese emotional speech corpora. We then benchmark JVNV on emotional text-to-speech synthesis using discrete codes to represent NVs. We show that there still exists a gap between the performance of synthesizing read-aloud speech and emotional speech, and adding NVs in the speech makes the task even harder, which brings new challenges for this task and makes JVNV a valuable resource for relevant works in the future. To our best knowledge, JVNV is the first speech corpus that generates scripts automatically using large language models.