 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Exploiting Symmetric Temporally Sparse BPTT for Efficient RNN Training
Dec 14, 2023
Recurrent Neural Networks (RNNs) are useful in temporal sequence tasks. However, training RNNs involves dense matrix multiplications which require hardware that can support a large number of arithmetic operations and memory accesses. Implementing online training of RNNs on the edge calls for optimized algorithms for an efficient deployment on hardware. Inspired by the spiking neuron model, the Delta RNN exploits temporal sparsity during inference by skipping over the update of hidden states from those inactivated neurons whose change of activation across two timesteps is below a defined threshold. This work describes a training algorithm for Delta RNNs that exploits temporal sparsity in the backward propagation phase to reduce computational requirements for training on the edge. Due to the symmetric computation graphs of forward and backward propagation during training, the gradient computation of inactivated neurons can be skipped. Results show a reduction of $\sim$80% in matrix operations for training a 56k parameter Delta LSTM on the Fluent Speech Commands dataset with negligible accuracy loss. Logic simulations of a hardware accelerator designed for the training algorithm show 2-10X speedup in matrix computations for an activation sparsity range of 50%-90%. Additionally, we show that the proposed Delta RNN training will be useful for online incremental learning on edge devices with limited computing resources.
Analysis of Speech Separation Performance Degradation on Emotional Speech Mixtures
Sep 14, 2023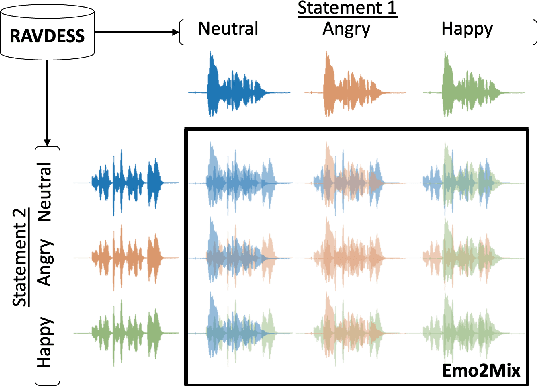
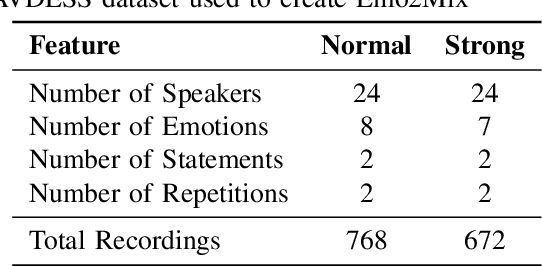
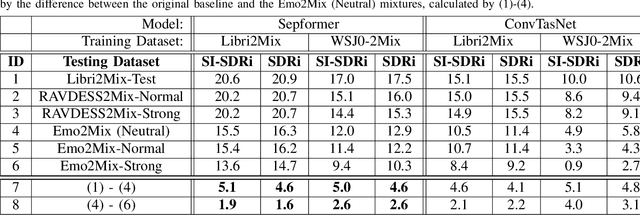
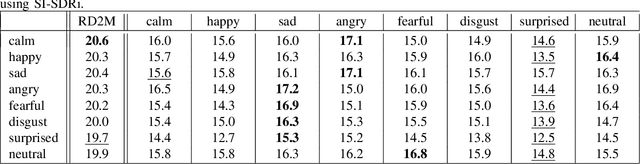
Despite recent strides made in Speech Separation, most models are trained on datasets with neutral emotions. Emotional speech has been known to degrade performance of models in a variety of speech tasks, which reduces the effectiveness of these models when deployed in real-world scenarios. In this paper we perform analysis to differentiate the performance degradation arising from the emotions in speech from the impact of out-of-domain inference. This is measured using a carefully designed test dataset, Emo2Mix, consisting of balanced data across all emotional combinations. We show that even models with strong out-of-domain performance such as Sepformer can still suffer significant degradation of up to 5.1 dB SI-SDRi on mixtures with strong emotions. This demonstrates the importance of accounting for emotions in real-world speech separation applications.
Thech. Report: Genuinization of Speech waveform PMF for speaker detection spoofing and countermeasures
Oct 09, 2023In the context of spoofing attacks in speaker recognition systems, we observed that the waveform probability mass function (PMF) of genuine speech differs significantly from the PMF of speech resulting from the attacks. This is true for synthesized or converted speech as well as replayed speech. We also noticed that this observation seems to have a significant impact on spoofing detection performance. In this article, we propose an algorithm, denoted genuinization, capable of reducing the waveform distribution gap between authentic speech and spoofing speech. Our genuinization algorithm is evaluated on ASVspoof 2019 challenge datasets, using the baseline system provided by the challenge organization. We first assess the influence of genuinization on spoofing performance. Using genuinization for the spoofing attacks degrades spoofing detection performance by up to a factor of 10. Next, we integrate the genuinization algorithm in the spoofing countermeasures and we observe a huge spoofing detection improvement in different cases. The results of our experiments show clearly that waveform distribution plays an important role and must be taken into account by anti-spoofing systems.
A Single Speech Enhancement Model Unifying Dereverberation, Denoising, Speaker Counting, Separation, and Extraction
Oct 12, 2023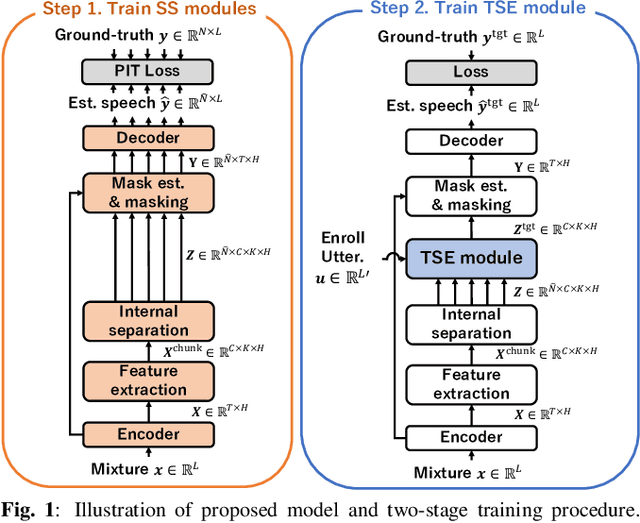
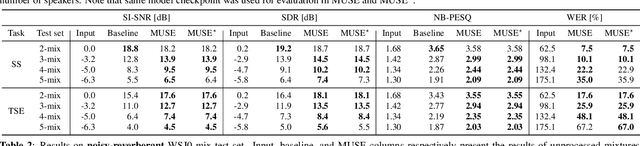
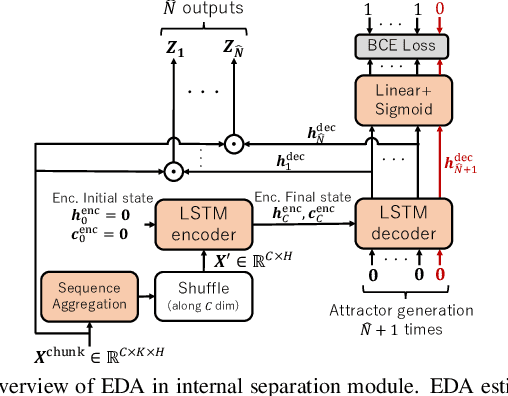
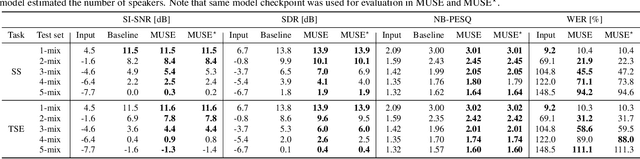
We propose a multi-task universal speech enhancement (MUSE) model that can perform five speech enhancement (SE) tasks: dereverberation, denoising, speech separation (SS), target speaker extraction (TSE), and speaker counting. This is achieved by integrating two modules into an SE model: 1) an internal separation module that does both speaker counting and separation; and 2) a TSE module that extracts the target speech from the internal separation outputs using target speaker cues. The model is trained to perform TSE if the target speaker cue is given and SS otherwise. By training the model to remove noise and reverberation, we allow the model to tackle the five tasks mentioned above with a single model, which has not been accomplished yet. Evaluation results demonstrate that the proposed MUSE model can successfully handle multiple tasks with a single model.
Batched Low-Rank Adaptation of Foundation Models
Dec 09, 2023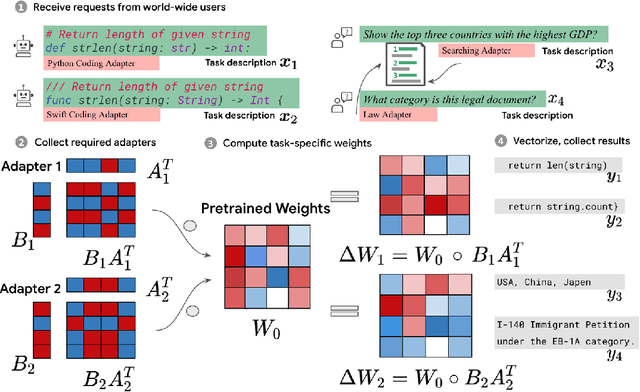
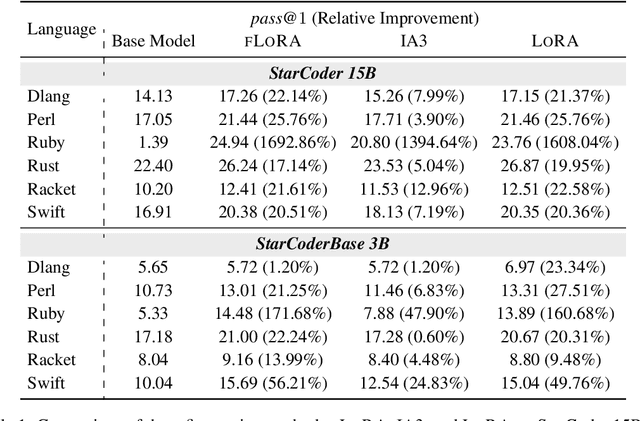
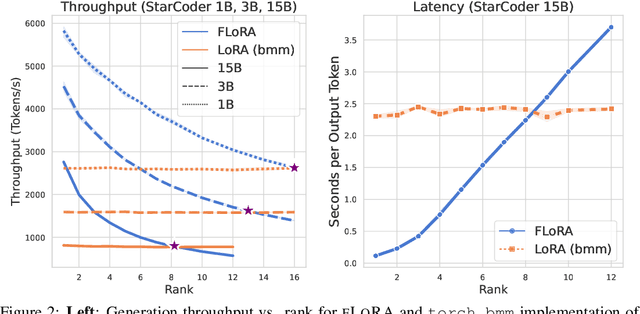

Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Deep Beamforming for Speech Enhancement and Speaker Localization with an Array Response-Aware Loss Function
Oct 19, 2023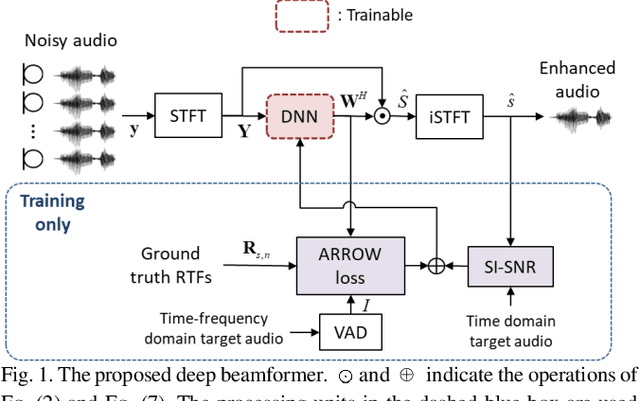
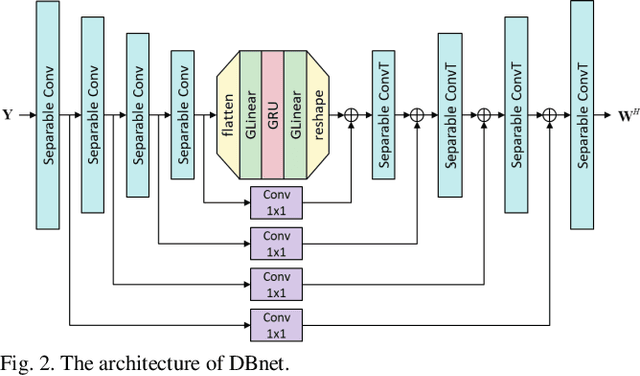
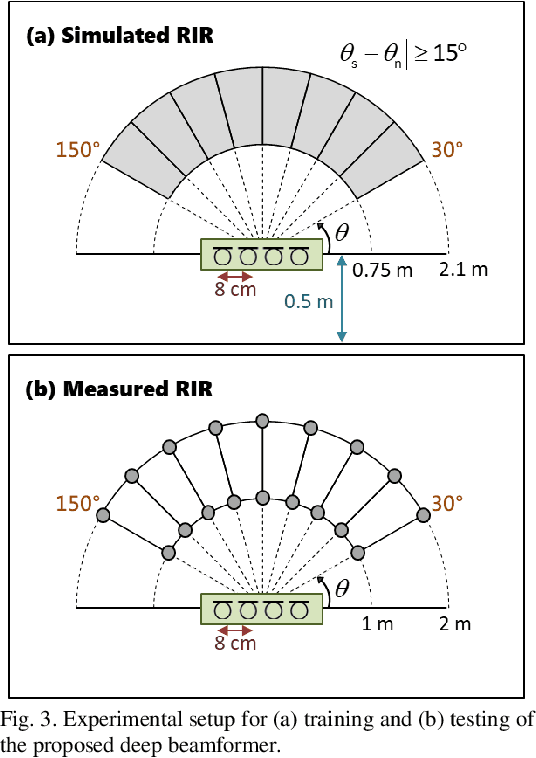
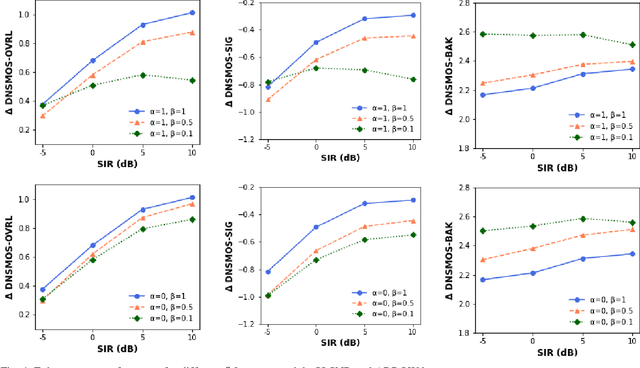
Recent research advances in deep neural network (DNN)-based beamformers have shown great promise for speech enhancement under adverse acoustic conditions. Different network architectures and input features have been explored in estimating beamforming weights. In this paper, we propose a deep beamformer based on an efficient convolutional recurrent network (CNN) trained with a novel ARray RespOnse-aWare (ARROW) loss function. The ARROW loss exploits the array responses of the target and interferer by using the ground truth relative transfer functions (RTFs). The DNN-based beamforming system, trained with ARROW loss through supervised learning, is able to perform speech enhancement and speaker localization jointly. Experimental results have shown that the proposed deep beamformer, trained with the linearly weighted scale-invariant source-to-noise ratio (SI-SNR) and ARROW loss functions, achieves superior performance in speech enhancement and speaker localization compared to two baselines.
Spatial HuBERT: Self-supervised Spatial Speech Representation Learning for a Single Talker from Multi-channel Audio
Oct 17, 2023Self-supervised learning has been used to leverage unlabelled data, improving accuracy and generalisation of speech systems through the training of representation models. While many recent works have sought to produce effective representations across a variety of acoustic domains, languages, modalities and even simultaneous speakers, these studies have all been limited to single-channel audio recordings. This paper presents Spatial HuBERT, a self-supervised speech representation model that learns both acoustic and spatial information pertaining to a single speaker in a potentially noisy environment by using multi-channel audio inputs. Spatial HuBERT learns representations that outperform state-of-the-art single-channel speech representations on a variety of spatial downstream tasks, particularly in reverberant and noisy environments. We also demonstrate the utility of the representations learned by Spatial HuBERT on a speech localisation downstream task. Along with this paper, we publicly release a new dataset of 100 000 simulated first-order ambisonics room impulse responses.
MUST&P-SRL: Multi-lingual and Unified Syllabification in Text and Phonetic Domains for Speech Representation Learning
Oct 17, 2023In this paper, we present a methodology for linguistic feature extraction, focusing particularly on automatically syllabifying words in multiple languages, with a design to be compatible with a forced-alignment tool, the Montreal Forced Aligner (MFA). In both the textual and phonetic domains, our method focuses on the extraction of phonetic transcriptions from text, stress marks, and a unified automatic syllabification (in text and phonetic domains). The system was built with open-source components and resources. Through an ablation study, we demonstrate the efficacy of our approach in automatically syllabifying words from several languages (English, French and Spanish). Additionally, we apply the technique to the transcriptions of the CMU ARCTIC dataset, generating valuable annotations available online\footnote{\url{https://github.com/noetits/MUST_P-SRL}} that are ideal for speech representation learning, speech unit discovery, and disentanglement of speech factors in several speech-related fields.
RepCodec: A Speech Representation Codec for Speech Tokenization
Aug 31, 2023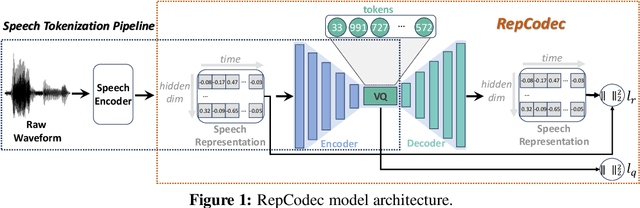
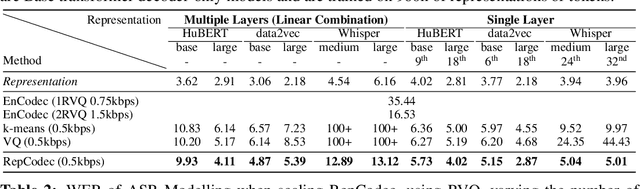
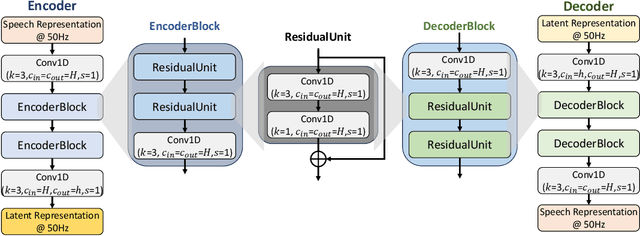
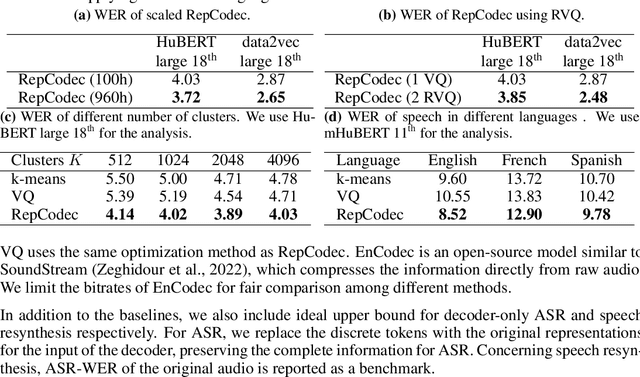
With recent rapid growth of large language models (LLMs), discrete speech tokenization has played an important role for injecting speech into LLMs. However, this discretization gives rise to a loss of information, consequently impairing overall performance. To improve the performance of these discrete speech tokens, we present RepCodec, a novel speech representation codec for semantic speech tokenization. In contrast to audio codecs which reconstruct the raw audio, RepCodec learns a vector quantization codebook through reconstructing speech representations from speech encoders like HuBERT or data2vec. Together, the speech encoder, the codec encoder and the vector quantization codebook form a pipeline for converting speech waveforms into semantic tokens. The extensive experiments illustrate that RepCodec, by virtue of its enhanced information retention capacity, significantly outperforms the widely used k-means clustering approach in both speech understanding and generation. Furthermore, this superiority extends across various speech encoders and languages, affirming the robustness of RepCodec. We believe our method can facilitate large language modeling research on speech processing.
Efficient Representation of the Activation Space in Deep Neural Networks
Dec 13, 2023The representations of the activation space of deep neural networks (DNNs) are widely utilized for tasks like natural language processing, anomaly detection and speech recognition. Due to the diverse nature of these tasks and the large size of DNNs, an efficient and task-independent representation of activations becomes crucial. Empirical p-values have been used to quantify the relative strength of an observed node activation compared to activations created by already-known inputs. Nonetheless, keeping raw data for these calculations increases memory resource consumption and raises privacy concerns. To this end, we propose a model-agnostic framework for creating representations of activations in DNNs using node-specific histograms to compute p-values of observed activations without retaining already-known inputs. Our proposed approach demonstrates promising potential when validated with multiple network architectures across various downstream tasks and compared with the kernel density estimates and brute-force empirical baselines. In addition, the framework reduces memory usage by 30% with up to 4 times faster p-value computing time while maintaining state of-the-art detection power in downstream tasks such as the detection of adversarial attacks and synthesized content. Moreover, as we do not persist raw data at inference time, we could potentially reduce susceptibility to attacks and privacy issues.