 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Identifying Planetary Names in Astronomy Papers: A Multi-Step Approach
Dec 17, 2023
The automatic identification of planetary feature names in astronomy publications presents numerous challenges. These features include craters, defined as roughly circular depressions resulting from impact or volcanic activity; dorsas, which are elongate raised structures or wrinkle ridges; and lacus, small irregular patches of dark, smooth material on the Moon, referred to as "lake" (Planetary Names Working Group, n.d.). Many feature names overlap with places or people's names that they are named after, for example, Syria, Tempe, Einstein, and Sagan, to name a few (U.S. Geological Survey, n.d.). Some feature names have been used in many contexts, for instance, Apollo, which can refer to mission, program, sample, astronaut, seismic, seismometers, core, era, data, collection, instrument, and station, in addition to the crater on the Moon. Some feature names can appear in the text as adjectives, like the lunar craters Black, Green, and White. Some feature names in other contexts serve as directions, like craters West and South on the Moon. Additionally, some features share identical names across different celestial bodies, requiring disambiguation, such as the Adams crater, which exists on both the Moon and Mars. We present a multi-step pipeline combining rule-based filtering, statistical relevance analysis, part-of-speech (POS) tagging, named entity recognition (NER) model, hybrid keyword harvesting, knowledge graph (KG) matching, and inference with a locally installed large language model (LLM) to reliably identify planetary names despite these challenges. When evaluated on a dataset of astronomy papers from the Astrophysics Data System (ADS), this methodology achieves an F1-score over 0.97 in disambiguating planetary feature names.
Do self-supervised speech and language models extract similar representations as human brain?
Oct 07, 2023Speech and language models trained through self-supervised learning (SSL) demonstrate strong alignment with brain activity during speech and language perception. However, given their distinct training modalities, it remains unclear whether they correlate with the same neural aspects. We directly address this question by evaluating the brain prediction performance of two representative SSL models, Wav2Vec2.0 and GPT-2, designed for speech and language tasks. Our findings reveal that both models accurately predict speech responses in the auditory cortex, with a significant correlation between their brain predictions. Notably, shared speech contextual information between Wav2Vec2.0 and GPT-2 accounts for the majority of explained variance in brain activity, surpassing static semantic and lower-level acoustic-phonetic information. These results underscore the convergence of speech contextual representations in SSL models and their alignment with the neural network underlying speech perception, offering valuable insights into both SSL models and the neural basis of speech and language processing.
Modular Customizable ROS-Based Framework for Rapid Development of Social Robots
Nov 27, 2023Developing socially competent robots requires tight integration of robotics, computer vision, speech processing, and web technologies. We present the Socially-interactive Robot Software platform (SROS), an open-source framework addressing this need through a modular layered architecture. SROS bridges the Robot Operating System (ROS) layer for mobility with web and Android interface layers using standard messaging and APIs. Specialized perceptual and interactive skills are implemented as ROS services for reusable deployment on any robot. This facilitates rapid prototyping of collaborative behaviors that synchronize perception with physical actuation. We experimentally validated core SROS technologies including computer vision, speech processing, and GPT2 autocomplete speech implemented as plug-and-play ROS services. Modularity is demonstrated through the successful integration of an additional ROS package, without changes to hardware or software platforms. The capabilities enabled confirm SROS's effectiveness in developing socially interactive robots through synchronized cross-domain interaction. Through demonstrations showing synchronized multimodal behaviors on an example platform, we illustrate how the SROS architectural approach addresses shortcomings of previous work by lowering barriers for researchers to advance the state-of-the-art in adaptive, collaborative customizable human-robot systems through novel applications integrating perceptual and social abilities.
JVNV: A Corpus of Japanese Emotional Speech with Verbal Content and Nonverbal Expressions
Oct 09, 2023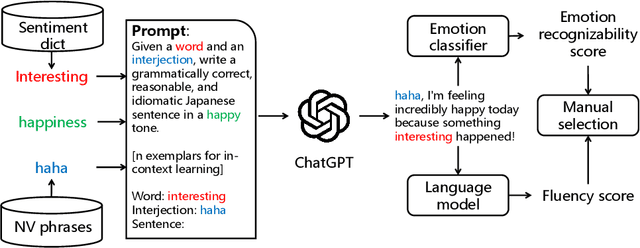


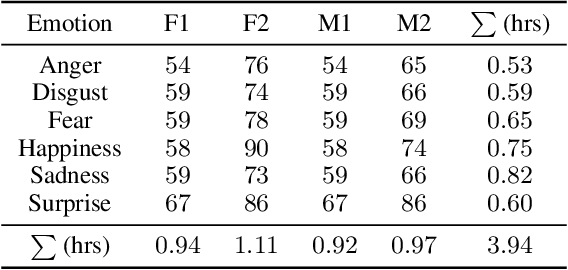
We present the JVNV, a Japanese emotional speech corpus with verbal content and nonverbal vocalizations whose scripts are generated by a large-scale language model. Existing emotional speech corpora lack not only proper emotional scripts but also nonverbal vocalizations (NVs) that are essential expressions in spoken language to express emotions. We propose an automatic script generation method to produce emotional scripts by providing seed words with sentiment polarity and phrases of nonverbal vocalizations to ChatGPT using prompt engineering. We select 514 scripts with balanced phoneme coverage from the generated candidate scripts with the assistance of emotion confidence scores and language fluency scores. We demonstrate the effectiveness of JVNV by showing that JVNV has better phoneme coverage and emotion recognizability than previous Japanese emotional speech corpora. We then benchmark JVNV on emotional text-to-speech synthesis using discrete codes to represent NVs. We show that there still exists a gap between the performance of synthesizing read-aloud speech and emotional speech, and adding NVs in the speech makes the task even harder, which brings new challenges for this task and makes JVNV a valuable resource for relevant works in the future. To our best knowledge, JVNV is the first speech corpus that generates scripts automatically using large language models.
Adaptive Computation Modules: Granular Conditional Computation For Efficient Inference
Dec 15, 2023The computational cost of transformer models makes them inefficient in low-latency or low-power applications. While techniques such as quantization or linear attention can reduce the computational load, they may incur a reduction in accuracy. In addition, globally reducing the cost for all inputs may be sub-optimal. We observe that for each layer, the full width of the layer may be needed only for a small subset of tokens inside a batch and that the "effective" width needed to process a token can vary from layer to layer. Motivated by this observation, we introduce the Adaptive Computation Module (ACM), a generic module that dynamically adapts its computational load to match the estimated difficulty of the input on a per-token basis. An ACM consists of a sequence of learners that progressively refine the output of their preceding counterparts. An additional gating mechanism determines the optimal number of learners to execute for each token. We also describe a distillation technique to replace any pre-trained model with an "ACMized" variant. The distillation phase is designed to be highly parallelizable across layers while being simple to plug-and-play into existing networks. Our evaluation of transformer models in computer vision and speech recognition demonstrates that substituting layers with ACMs significantly reduces inference costs without degrading the downstream accuracy for a wide interval of user-defined budgets.
Subspace Hybrid MVDR Beamforming for Augmented Hearing
Nov 30, 2023Signal-dependent beamformers are advantageous over signal-independent beamformers when the acoustic scenario - be it real-world or simulated - is straightforward in terms of the number of sound sources, the ambient sound field and their dynamics. However, in the context of augmented reality audio using head-worn microphone arrays, the acoustic scenarios encountered are often far from straightforward. The design of robust, high-performance, adaptive beamformers for such scenarios is an on-going challenge. This is due to the violation of the typically required assumptions on the noise field caused by, for example, rapid variations resulting from complex acoustic environments, and/or rotations of the listener's head. This work proposes a multi-channel speech enhancement algorithm which utilises the adaptability of signal-dependent beamformers while still benefiting from the computational efficiency and robust performance of signal-independent super-directive beamformers. The algorithm has two stages. (i) The first stage is a hybrid beamformer based on a dictionary of weights corresponding to a set of noise field models. (ii) The second stage is a wide-band subspace post-filter to remove any artifacts resulting from (i). The algorithm is evaluated using both real-world recordings and simulations of a cocktail-party scenario. Noise suppression, intelligibility and speech quality results show a significant performance improvement by the proposed algorithm compared to the baseline super-directive beamformer. A data-driven implementation of the noise field dictionary is shown to provide more noise suppression, and similar speech intelligibility and quality, compared to a parametric dictionary.
Exploiting Symmetric Temporally Sparse BPTT for Efficient RNN Training
Dec 14, 2023Recurrent Neural Networks (RNNs) are useful in temporal sequence tasks. However, training RNNs involves dense matrix multiplications which require hardware that can support a large number of arithmetic operations and memory accesses. Implementing online training of RNNs on the edge calls for optimized algorithms for an efficient deployment on hardware. Inspired by the spiking neuron model, the Delta RNN exploits temporal sparsity during inference by skipping over the update of hidden states from those inactivated neurons whose change of activation across two timesteps is below a defined threshold. This work describes a training algorithm for Delta RNNs that exploits temporal sparsity in the backward propagation phase to reduce computational requirements for training on the edge. Due to the symmetric computation graphs of forward and backward propagation during training, the gradient computation of inactivated neurons can be skipped. Results show a reduction of $\sim$80% in matrix operations for training a 56k parameter Delta LSTM on the Fluent Speech Commands dataset with negligible accuracy loss. Logic simulations of a hardware accelerator designed for the training algorithm show 2-10X speedup in matrix computations for an activation sparsity range of 50%-90%. Additionally, we show that the proposed Delta RNN training will be useful for online incremental learning on edge devices with limited computing resources.
AV-CPL: Continuous Pseudo-Labeling for Audio-Visual Speech Recognition
Sep 29, 2023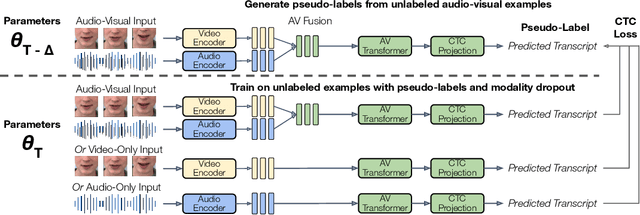
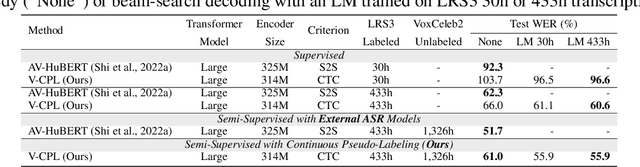
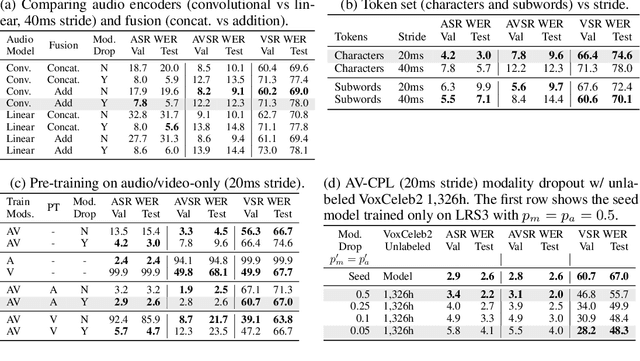
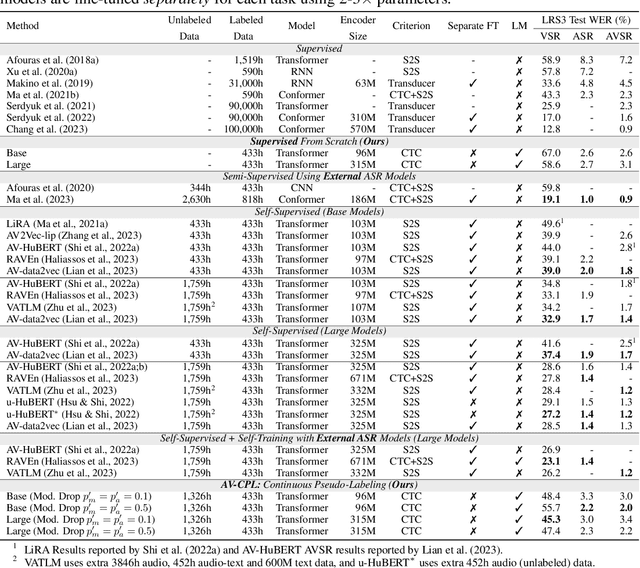
Audio-visual speech contains synchronized audio and visual information that provides cross-modal supervision to learn representations for both automatic speech recognition (ASR) and visual speech recognition (VSR). We introduce continuous pseudo-labeling for audio-visual speech recognition (AV-CPL), a semi-supervised method to train an audio-visual speech recognition (AVSR) model on a combination of labeled and unlabeled videos with continuously regenerated pseudo-labels. Our models are trained for speech recognition from audio-visual inputs and can perform speech recognition using both audio and visual modalities, or only one modality. Our method uses the same audio-visual model for both supervised training and pseudo-label generation, mitigating the need for external speech recognition models to generate pseudo-labels. AV-CPL obtains significant improvements in VSR performance on the LRS3 dataset while maintaining practical ASR and AVSR performance. Finally, using visual-only speech data, our method is able to leverage unlabeled visual speech to improve VSR.
CorrTalk: Correlation Between Hierarchical Speech and Facial Activity Variances for 3D Animation
Oct 17, 2023Speech-driven 3D facial animation is a challenging cross-modal task that has attracted growing research interest. During speaking activities, the mouth displays strong motions, while the other facial regions typically demonstrate comparatively weak activity levels. Existing approaches often simplify the process by directly mapping single-level speech features to the entire facial animation, which overlook the differences in facial activity intensity leading to overly smoothed facial movements. In this study, we propose a novel framework, CorrTalk, which effectively establishes the temporal correlation between hierarchical speech features and facial activities of different intensities across distinct regions. A novel facial activity intensity metric is defined to distinguish between strong and weak facial activity, obtained by computing the short-time Fourier transform of facial vertex displacements. Based on the variances in facial activity, we propose a dual-branch decoding framework to synchronously synthesize strong and weak facial activity, which guarantees wider intensity facial animation synthesis. Furthermore, a weighted hierarchical feature encoder is proposed to establish temporal correlation between hierarchical speech features and facial activity at different intensities, which ensures lip-sync and plausible facial expressions. Extensive qualitatively and quantitatively experiments as well as a user study indicate that our CorrTalk outperforms existing state-of-the-art methods. The source code and supplementary video are publicly available at: https://zjchu.github.io/projects/CorrTalk/
Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
Oct 16, 2023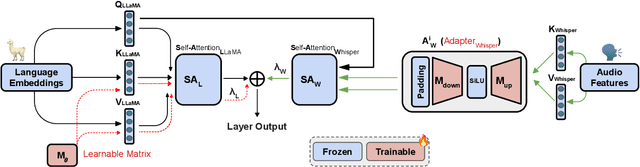
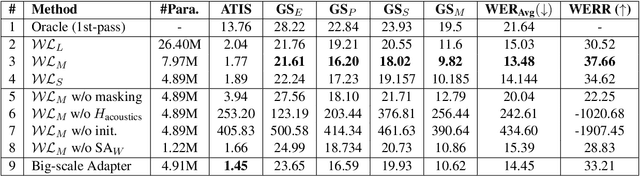
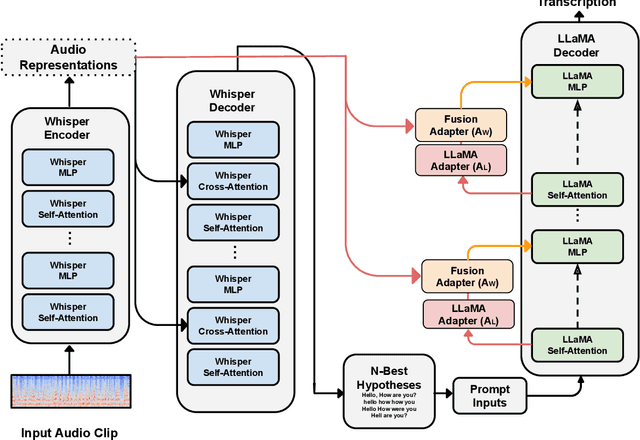
We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at https://github.com/Srijith-rkr/Whispering-LLaMA.