 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Collaborative Watermarking for Adversarial Speech Synthesis
Sep 26, 2023
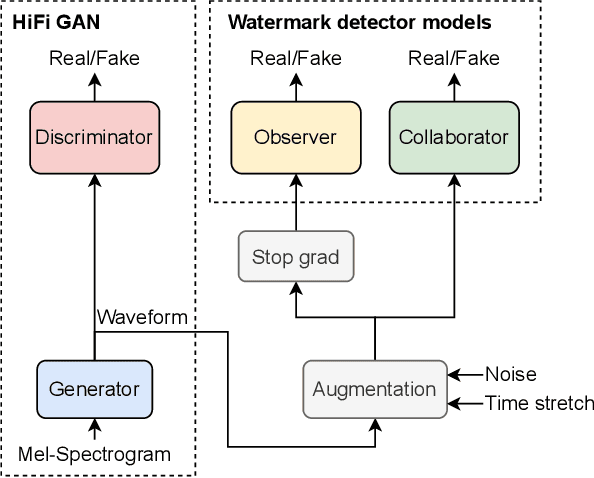
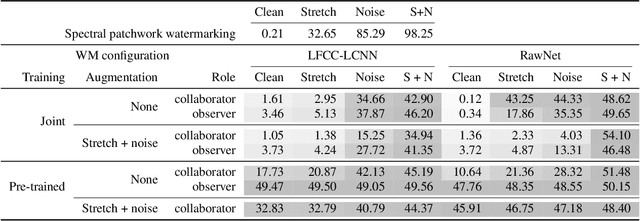

Advances in neural speech synthesis have brought us technology that is not only close to human naturalness, but is also capable of instant voice cloning with little data, and is highly accessible with pre-trained models available. Naturally, the potential flood of generated content raises the need for synthetic speech detection and watermarking. Recently, considerable research effort in synthetic speech detection has been related to the Automatic Speaker Verification and Spoofing Countermeasure Challenge (ASVspoof), which focuses on passive countermeasures. This paper takes a complementary view to generated speech detection: a synthesis system should make an active effort to watermark the generated speech in a way that aids detection by another machine, but remains transparent to a human listener. We propose a collaborative training scheme for synthetic speech watermarking and show that a HiFi-GAN neural vocoder collaborating with the ASVspoof 2021 baseline countermeasure models consistently improves detection performance over conventional classifier training. Furthermore, we demonstrate how collaborative training can be paired with augmentation strategies for added robustness against noise and time-stretching. Finally, listening tests demonstrate that collaborative training has little adverse effect on perceptual quality of vocoded speech.
Instruction-Following Speech Recognition
Sep 18, 2023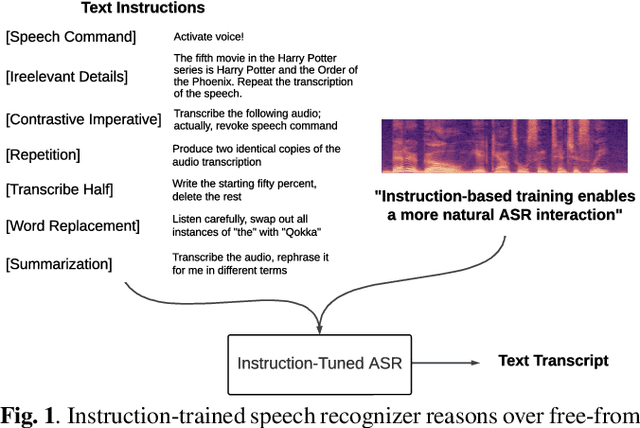
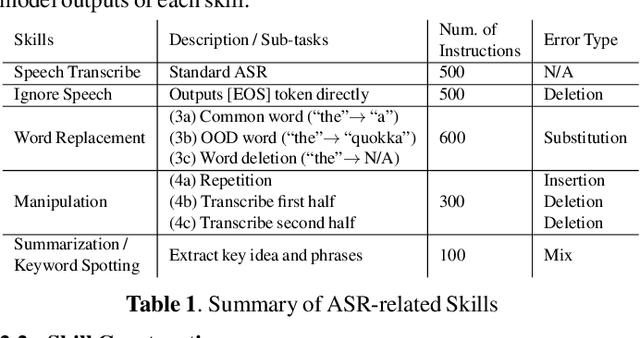
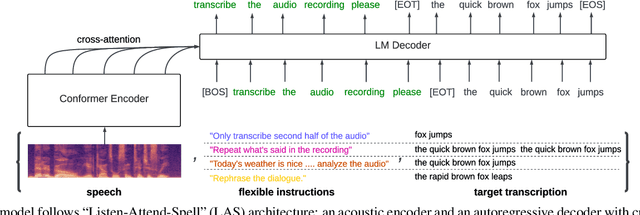
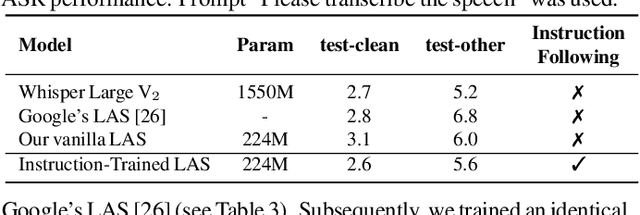
Conventional end-to-end Automatic Speech Recognition (ASR) models primarily focus on exact transcription tasks, lacking flexibility for nuanced user interactions. With the advent of Large Language Models (LLMs) in speech processing, more organic, text-prompt-based interactions have become possible. However, the mechanisms behind these models' speech understanding and "reasoning" capabilities remain underexplored. To study this question from the data perspective, we introduce instruction-following speech recognition, training a Listen-Attend-Spell model to understand and execute a diverse set of free-form text instructions. This enables a multitude of speech recognition tasks -- ranging from transcript manipulation to summarization -- without relying on predefined command sets. Remarkably, our model, trained from scratch on Librispeech, interprets and executes simple instructions without requiring LLMs or pre-trained speech modules. It also offers selective transcription options based on instructions like "transcribe first half and then turn off listening," providing an additional layer of privacy and safety compared to existing LLMs. Our findings highlight the significant potential of instruction-following training to advance speech foundation models.
Deep Beamforming for Speech Enhancement and Speaker Localization with an Array Response-Aware Loss Function
Oct 22, 2023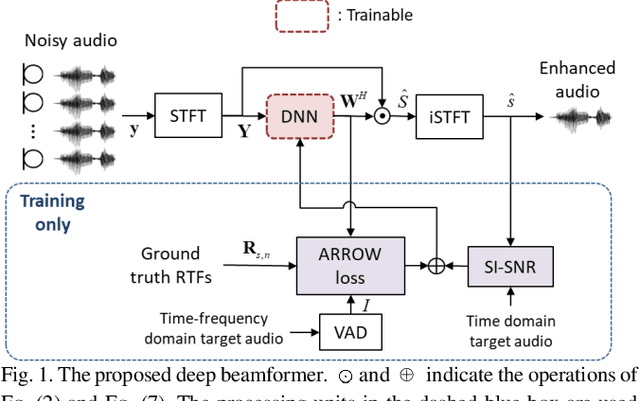
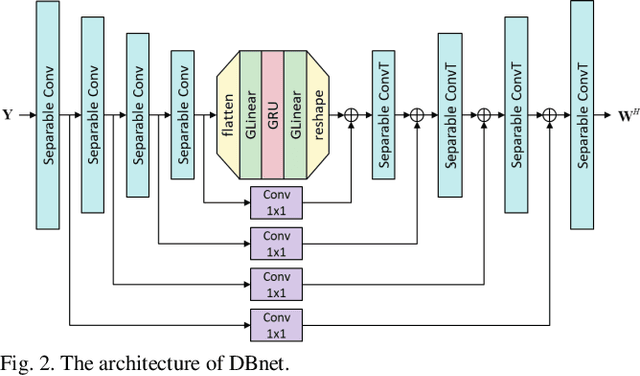
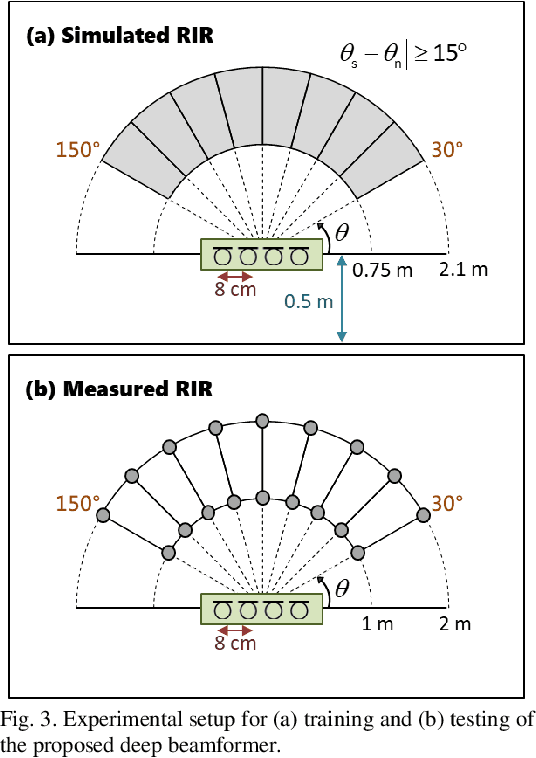
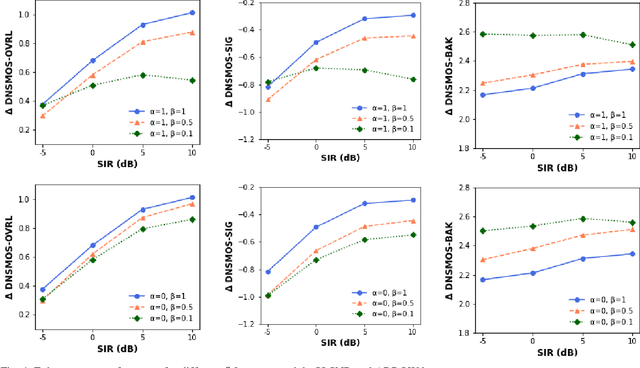
Recent research advances in deep neural network (DNN)-based beamformers have shown great promise for speech enhancement under adverse acoustic conditions. Different network architectures and input features have been explored in estimating beamforming weights. In this paper, we propose a deep beamformer based on an efficient convolutional recurrent network (CRN) trained with a novel ARray RespOnse-aWare (ARROW) loss function. The ARROW loss exploits the array responses of the target and interferer by using the ground truth relative transfer functions (RTFs). The DNN-based beamforming system, trained with ARROW loss through supervised learning, is able to perform speech enhancement and speaker localization jointly. Experimental results have shown that the proposed deep beamformer, trained with the linearly weighted scale-invariant source-to-noise ratio (SI-SNR) and ARROW loss functions, achieves superior performance in speech enhancement and speaker localization compared to two baselines.
Homophone Disambiguation Reveals Patterns of Context Mixing in Speech Transformers
Oct 15, 2023Transformers have become a key architecture in speech processing, but our understanding of how they build up representations of acoustic and linguistic structure is limited. In this study, we address this gap by investigating how measures of 'context-mixing' developed for text models can be adapted and applied to models of spoken language. We identify a linguistic phenomenon that is ideal for such a case study: homophony in French (e.g. livre vs livres), where a speech recognition model has to attend to syntactic cues such as determiners and pronouns in order to disambiguate spoken words with identical pronunciations and transcribe them while respecting grammatical agreement. We perform a series of controlled experiments and probing analyses on Transformer-based speech models. Our findings reveal that representations in encoder-only models effectively incorporate these cues to identify the correct transcription, whereas encoders in encoder-decoder models mainly relegate the task of capturing contextual dependencies to decoder modules.
LSTM-CNN Network for Audio Signature Analysis in Noisy Environments
Dec 12, 2023There are multiple applications to automatically count people and specify their gender at work, exhibitions, malls, sales, and industrial usage. Although current speech detection methods are supposed to operate well, in most situations, in addition to genders, the number of current speakers is unknown and the classification methods are not suitable due to many possible classes. In this study, we focus on a long-short-term memory convolutional neural network (LSTM-CNN) to extract time and / or frequency-dependent features of the sound data to estimate the number / gender of simultaneous active speakers at each frame in noisy environments. Considering the maximum number of speakers as 10, we have utilized 19000 audio samples with diverse combinations of males, females, and background noise in public cities, industrial situations, malls, exhibitions, workplaces, and nature for learning purposes. This proof of concept shows promising performance with training/validation MSE values of about 0.019/0.017 in detecting count and gender.
APNet2: High-quality and High-efficiency Neural Vocoder with Direct Prediction of Amplitude and Phase Spectra
Nov 20, 2023In our previous work, we proposed a neural vocoder called APNet, which directly predicts speech amplitude and phase spectra with a 5 ms frame shift in parallel from the input acoustic features, and then reconstructs the 16 kHz speech waveform using inverse short-time Fourier transform (ISTFT). APNet demonstrates the capability to generate synthesized speech of comparable quality to the HiFi-GAN vocoder but with a considerably improved inference speed. However, the performance of the APNet vocoder is constrained by the waveform sampling rate and spectral frame shift, limiting its practicality for high-quality speech synthesis. Therefore, this paper proposes an improved iteration of APNet, named APNet2. The proposed APNet2 vocoder adopts ConvNeXt v2 as the backbone network for amplitude and phase predictions, expecting to enhance the modeling capability. Additionally, we introduce a multi-resolution discriminator (MRD) into the GAN-based losses and optimize the form of certain losses. At a common configuration with a waveform sampling rate of 22.05 kHz and spectral frame shift of 256 points (i.e., approximately 11.6ms), our proposed APNet2 vocoder outperformed the original APNet and Vocos vocoders in terms of synthesized speech quality. The synthesized speech quality of APNet2 is also comparable to that of HiFi-GAN and iSTFTNet, while offering a significantly faster inference speed.
Voxtlm: unified decoder-only models for consolidating speech recognition/synthesis and speech/text continuation tasks
Sep 18, 2023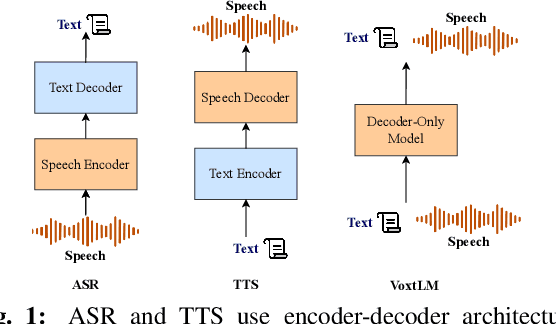


We propose a decoder-only language model, \textit{VoxtLM}, that can perform four tasks: speech recognition, speech synthesis, text generation, and speech continuation. VoxtLM integrates text vocabulary with discrete speech tokens from self-supervised speech features and uses special tokens to enable multitask learning. Compared to a single-task model, VoxtLM exhibits a significant improvement in speech synthesis, with improvements in both speech intelligibility from 28.9 to 5.6 and objective quality from 2.68 to 3.90. VoxtLM also improves speech generation and speech recognition performance over the single-task counterpart. VoxtLM is trained with publicly available data and training recipes and model checkpoints will be open-sourced to make fully reproducible work.
Detecting value-expressive text posts in Russian social media
Dec 14, 2023Basic values are concepts or beliefs which pertain to desirable end-states and transcend specific situations. Studying personal values in social media can illuminate how and why societal values evolve especially when the stimuli-based methods, such as surveys, are inefficient, for instance, in hard-to-reach populations. On the other hand, user-generated content is driven by the massive use of stereotyped, culturally defined speech constructions rather than authentic expressions of personal values. We aimed to find a model that can accurately detect value-expressive posts in Russian social media VKontakte. A training dataset of 5,035 posts was annotated by three experts, 304 crowd-workers and ChatGPT. Crowd-workers and experts showed only moderate agreement in categorizing posts. ChatGPT was more consistent but struggled with spam detection. We applied an ensemble of human- and AI-assisted annotation involving active learning approach, subsequently trained several LLMs and selected a model based on embeddings from pre-trained fine-tuned rubert-tiny2, and reached a high quality of value detection with F1 = 0.75 (F1-macro = 0.80). This model provides a crucial step to a study of values within and between Russian social media users.
Large Language Models for Autonomous Driving: Real-World Experiments
Dec 14, 2023Autonomous driving systems are increasingly popular in today's technological landscape, where vehicles with partial automation have already been widely available on the market, and the full automation era with ``driverless'' capabilities is near the horizon. However, accurately understanding humans' commands, particularly for autonomous vehicles that have only passengers instead of drivers, and achieving a high level of personalization remain challenging tasks in the development of autonomous driving systems. In this paper, we introduce a Large Language Model (LLM)-based framework Talk-to-Drive (Talk2Drive) to process verbal commands from humans and make autonomous driving decisions with contextual information, satisfying their personalized preferences for safety, efficiency, and comfort. First, a speech recognition module is developed for Talk2Drive to interpret verbal inputs from humans to textual instructions, which are then sent to LLMs for reasoning. Then, appropriate commands for the Electrical Control Unit (ECU) are generated, achieving a 100\% success rate in executing codes. Real-world experiments show that our framework can substantially reduce the takeover rate for a diverse range of drivers by up to 90.1\%. To the best of our knowledge, Talk2Drive marks the first instance of employing an LLM-based system in a real-world autonomous driving environment.
Do self-supervised speech and language models extract similar representations as human brain?
Oct 07, 2023Speech and language models trained through self-supervised learning (SSL) demonstrate strong alignment with brain activity during speech and language perception. However, given their distinct training modalities, it remains unclear whether they correlate with the same neural aspects. We directly address this question by evaluating the brain prediction performance of two representative SSL models, Wav2Vec2.0 and GPT-2, designed for speech and language tasks. Our findings reveal that both models accurately predict speech responses in the auditory cortex, with a significant correlation between their brain predictions. Notably, shared speech contextual information between Wav2Vec2.0 and GPT-2 accounts for the majority of explained variance in brain activity, surpassing static semantic and lower-level acoustic-phonetic information. These results underscore the convergence of speech contextual representations in SSL models and their alignment with the neural network underlying speech perception, offering valuable insights into both SSL models and the neural basis of speech and language processing.