 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Generative linguistic representation for spoken language identification
Dec 18, 2023
Effective extraction and application of linguistic features are central to the enhancement of spoken Language IDentification (LID) performance. With the success of recent large models, such as GPT and Whisper, the potential to leverage such pre-trained models for extracting linguistic features for LID tasks has become a promising area of research. In this paper, we explore the utilization of the decoder-based network from the Whisper model to extract linguistic features through its generative mechanism for improving the classification accuracy in LID tasks. We devised two strategies - one based on the language embedding method and the other focusing on direct optimization of LID outputs while simultaneously enhancing the speech recognition tasks. We conducted experiments on the large-scale multilingual datasets MLS, VoxLingua107, and CommonVoice to test our approach. The experimental results demonstrated the effectiveness of the proposed method on both in-domain and out-of-domain datasets for LID tasks.
Dialect Transfer for Swiss German Speech Translation
Oct 13, 2023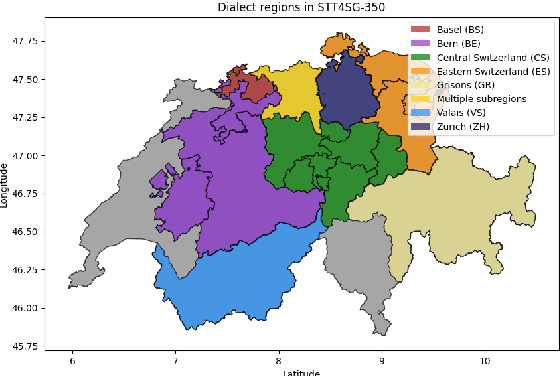
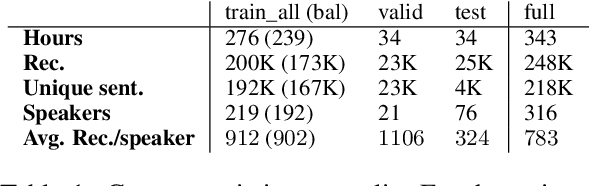
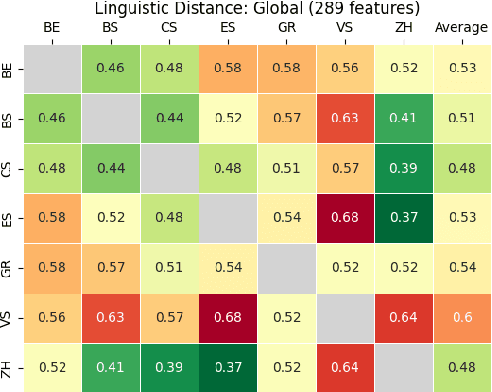
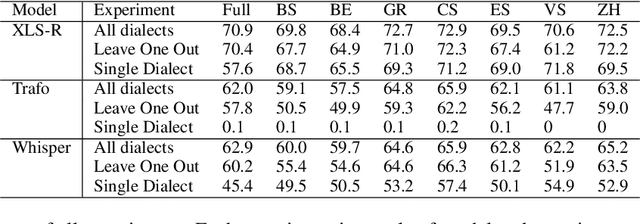
This paper investigates the challenges in building Swiss German speech translation systems, specifically focusing on the impact of dialect diversity and differences between Swiss German and Standard German. Swiss German is a spoken language with no formal writing system, it comprises many diverse dialects and is a low-resource language with only around 5 million speakers. The study is guided by two key research questions: how does the inclusion and exclusion of dialects during the training of speech translation models for Swiss German impact the performance on specific dialects, and how do the differences between Swiss German and Standard German impact the performance of the systems? We show that dialect diversity and linguistic differences pose significant challenges to Swiss German speech translation, which is in line with linguistic hypotheses derived from empirical investigations.
Unified speech and gesture synthesis using flow matching
Oct 08, 2023As text-to-speech technologies achieve remarkable naturalness in read-aloud tasks, there is growing interest in multimodal synthesis of verbal and non-verbal communicative behaviour, such as spontaneous speech and associated body gestures. This paper presents a novel, unified architecture for jointly synthesising speech acoustics and skeleton-based 3D gesture motion from text, trained using optimal-transport conditional flow matching (OT-CFM). The proposed architecture is simpler than the previous state of the art, has a smaller memory footprint, and can capture the joint distribution of speech and gestures, generating both modalities together in one single process. The new training regime, meanwhile, enables better synthesis quality in much fewer steps (network evaluations) than before. Uni- and multimodal subjective tests demonstrate improved speech naturalness, gesture human-likeness, and cross-modal appropriateness compared to existing benchmarks.
Creating Spoken Dialog Systems in Ultra-Low Resourced Settings
Dec 11, 2023Automatic Speech Recognition (ASR) systems are a crucial technology that is used today to design a wide variety of applications, most notably, smart assistants, such as Alexa. ASR systems are essentially dialogue systems that employ Spoken Language Understanding (SLU) to extract meaningful information from speech. The main challenge with designing such systems is that they require a huge amount of labeled clean data to perform competitively, such data is extremely hard to collect and annotate to respective SLU tasks, furthermore, when designing such systems for low resource languages, where data is extremely limited, the severity of the problem intensifies. In this paper, we focus on a fairly popular SLU task, that is, Intent Classification while working with a low resource language, namely, Flemish. Intent Classification is a task concerned with understanding the intents of the user interacting with the system. We build on existing light models for intent classification in Flemish, and our main contribution is applying different augmentation techniques on two levels -- the voice level, and the phonetic transcripts level -- to the existing models to counter the problem of scarce labeled data in low-resource languages. We find that our data augmentation techniques, on both levels, have improved the model performance on a number of tasks.
FlowMur: A Stealthy and Practical Audio Backdoor Attack with Limited Knowledge
Dec 15, 2023Speech recognition systems driven by DNNs have revolutionized human-computer interaction through voice interfaces, which significantly facilitate our daily lives. However, the growing popularity of these systems also raises special concerns on their security, particularly regarding backdoor attacks. A backdoor attack inserts one or more hidden backdoors into a DNN model during its training process, such that it does not affect the model's performance on benign inputs, but forces the model to produce an adversary-desired output if a specific trigger is present in the model input. Despite the initial success of current audio backdoor attacks, they suffer from the following limitations: (i) Most of them require sufficient knowledge, which limits their widespread adoption. (ii) They are not stealthy enough, thus easy to be detected by humans. (iii) Most of them cannot attack live speech, reducing their practicality. To address these problems, in this paper, we propose FlowMur, a stealthy and practical audio backdoor attack that can be launched with limited knowledge. FlowMur constructs an auxiliary dataset and a surrogate model to augment adversary knowledge. To achieve dynamicity, it formulates trigger generation as an optimization problem and optimizes the trigger over different attachment positions. To enhance stealthiness, we propose an adaptive data poisoning method according to Signal-to-Noise Ratio (SNR). Furthermore, ambient noise is incorporated into the process of trigger generation and data poisoning to make FlowMur robust to ambient noise and improve its practicality. Extensive experiments conducted on two datasets demonstrate that FlowMur achieves high attack performance in both digital and physical settings while remaining resilient to state-of-the-art defenses. In particular, a human study confirms that triggers generated by FlowMur are not easily detected by participants.
Token-Level Contrastive Learning with Modality-Aware Prompting for Multimodal Intent Recognition
Dec 22, 2023Multimodal intent recognition aims to leverage diverse modalities such as expressions, body movements and tone of speech to comprehend user's intent, constituting a critical task for understanding human language and behavior in real-world multimodal scenarios. Nevertheless, the majority of existing methods ignore potential correlations among different modalities and own limitations in effectively learning semantic features from nonverbal modalities. In this paper, we introduce a token-level contrastive learning method with modality-aware prompting (TCL-MAP) to address the above challenges. To establish an optimal multimodal semantic environment for text modality, we develop a modality-aware prompting module (MAP), which effectively aligns and fuses features from text, video and audio modalities with similarity-based modality alignment and cross-modality attention mechanism. Based on the modality-aware prompt and ground truth labels, the proposed token-level contrastive learning framework (TCL) constructs augmented samples and employs NT-Xent loss on the label token. Specifically, TCL capitalizes on the optimal textual semantic insights derived from intent labels to guide the learning processes of other modalities in return. Extensive experiments show that our method achieves remarkable improvements compared to state-of-the-art methods. Additionally, ablation analyses demonstrate the superiority of the modality-aware prompt over the handcrafted prompt, which holds substantial significance for multimodal prompt learning. The codes are released at https://github.com/thuiar/TCL-MAP.
FusDom: Combining In-Domain and Out-of-Domain Knowledge for Continuous Self-Supervised Learning
Dec 20, 2023Continued pre-training (CP) offers multiple advantages, like target domain adaptation and the potential to exploit the continuous stream of unlabeled data available online. However, continued pre-training on out-of-domain distributions often leads to catastrophic forgetting of previously acquired knowledge, leading to sub-optimal ASR performance. This paper presents FusDom, a simple and novel methodology for SSL-based continued pre-training. FusDom learns speech representations that are robust and adaptive yet not forgetful of concepts seen in the past. Instead of solving the SSL pre-text task on the output representations of a single model, FusDom leverages two identical pre-trained SSL models, a teacher and a student, with a modified pre-training head to solve the CP SSL pre-text task. This head employs a cross-attention mechanism between the representations of both models while only the student receives gradient updates and the teacher does not. Finally, the student is fine-tuned for ASR. In practice, FusDom outperforms all our baselines across settings significantly, with WER improvements in the range of 0.2 WER - 7.3 WER in the target domain while retaining the performance in the earlier domain.
Ultra Low Complexity Deep Learning Based Noise Suppression
Dec 13, 2023This paper introduces an innovative method for reducing the computational complexity of deep neural networks in real-time speech enhancement on resource-constrained devices. The proposed approach utilizes a two-stage processing framework, employing channelwise feature reorientation to reduce the computational load of convolutional operations. By combining this with a modified power law compression technique for enhanced perceptual quality, this approach achieves noise suppression performance comparable to state-of-the-art methods with significantly less computational requirements. Notably, our algorithm exhibits 3 to 4 times less computational complexity and memory usage than prior state-of-the-art approaches.
Improved Long-Form Speech Recognition by Jointly Modeling the Primary and Non-primary Speakers
Dec 18, 2023ASR models often suffer from a long-form deletion problem where the model predicts sequential blanks instead of words when transcribing a lengthy audio (in the order of minutes or hours). From the perspective of a user or downstream system consuming the ASR results, this behavior can be perceived as the model "being stuck", and potentially make the product hard to use. One of the culprits for long-form deletion is training-test data mismatch, which can happen even when the model is trained on diverse and large-scale data collected from multiple application domains. In this work, we introduce a novel technique to simultaneously model different groups of speakers in the audio along with the standard transcript tokens. Speakers are grouped as primary and non-primary, which connects the application domains and significantly alleviates the long-form deletion problem. This improved model neither needs any additional training data nor incurs additional training or inference cost.
GSmoothFace: Generalized Smooth Talking Face Generation via Fine Grained 3D Face Guidance
Dec 12, 2023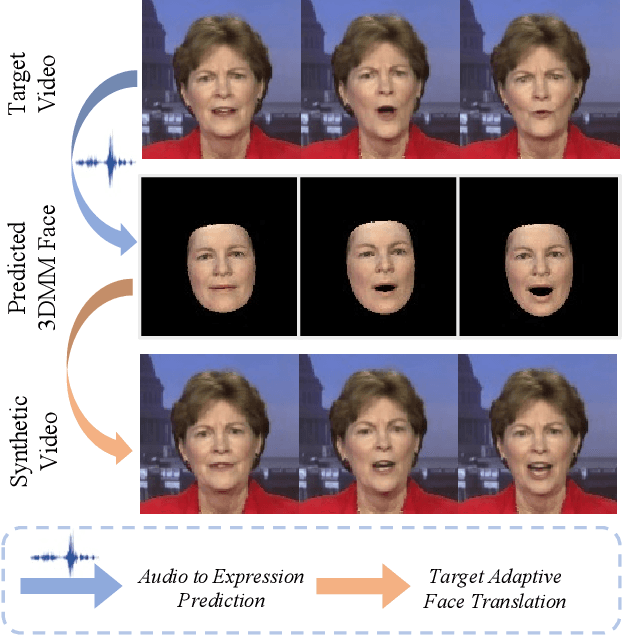
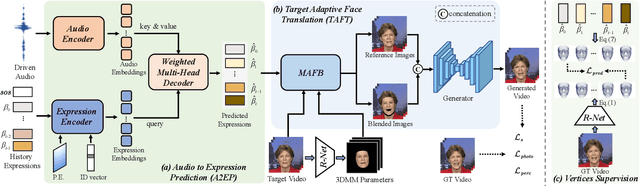
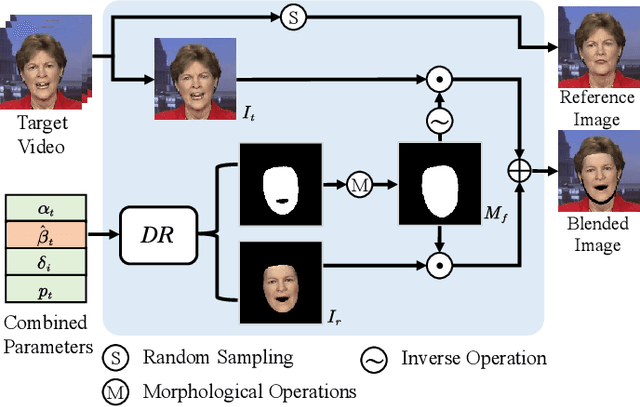
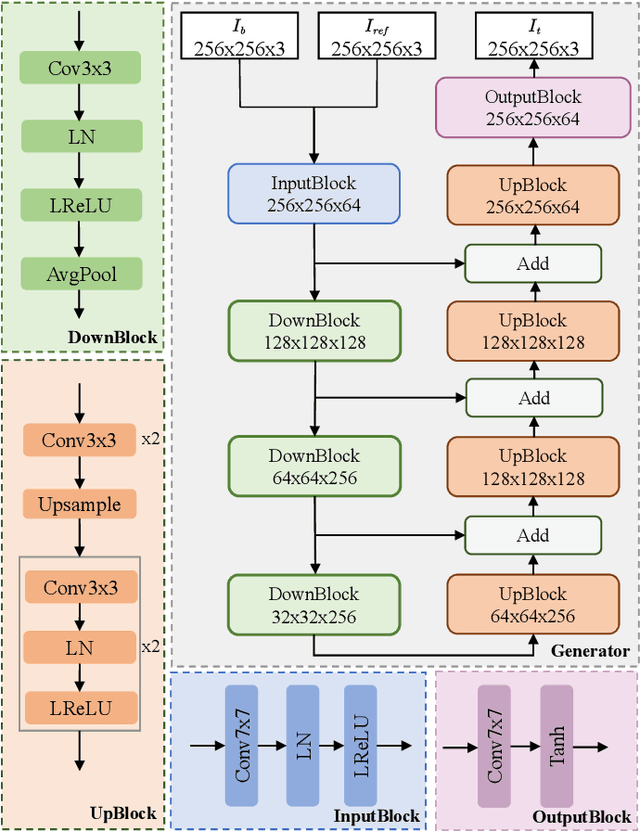
Although existing speech-driven talking face generation methods achieve significant progress, they are far from real-world application due to the avatar-specific training demand and unstable lip movements. To address the above issues, we propose the GSmoothFace, a novel two-stage generalized talking face generation model guided by a fine-grained 3d face model, which can synthesize smooth lip dynamics while preserving the speaker's identity. Our proposed GSmoothFace model mainly consists of the Audio to Expression Prediction (A2EP) module and the Target Adaptive Face Translation (TAFT) module. Specifically, we first develop the A2EP module to predict expression parameters synchronized with the driven speech. It uses a transformer to capture the long-term audio context and learns the parameters from the fine-grained 3D facial vertices, resulting in accurate and smooth lip-synchronization performance. Afterward, the well-designed TAFT module, empowered by Morphology Augmented Face Blending (MAFB), takes the predicted expression parameters and target video as inputs to modify the facial region of the target video without distorting the background content. The TAFT effectively exploits the identity appearance and background context in the target video, which makes it possible to generalize to different speakers without retraining. Both quantitative and qualitative experiments confirm the superiority of our method in terms of realism, lip synchronization, and visual quality. See the project page for code, data, and request pre-trained models: https://zhanghm1995.github.io/GSmoothFace.