 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Collaborative Learning with Artificial Intelligence Speakers (CLAIS): Pre-Service Elementary Science Teachers' Responses to the Prototype
Dec 20, 2023
This research aims to demonstrate that AI can function not only as a tool for learning, but also as an intelligent agent with which humans can engage in collaborative learning (CL) to change epistemic practices in science classrooms. We adopted a design and development research approach, following the Analysis, Design, Development, Implementation and Evaluation (ADDIE) model, to prototype a tangible instructional system called Collaborative Learning with AI Speakers (CLAIS). The CLAIS system is designed to have 3-4 human learners join an AI speaker to form a small group, where humans and AI are considered as peers participating in the Jigsaw learning process. The development was carried out using the NUGU AI speaker platform. The CLAIS system was successfully implemented in a Science Education course session with 15 pre-service elementary science teachers. The participants evaluated the CLAIS system through mixed methods surveys as teachers, learners, peers, and users. Quantitative data showed that the participants' Intelligent-Technological, Pedagogical, And Content Knowledge was significantly increased after the CLAIS session, the perception of the CLAIS learning experience was positive, the peer assessment on AI speakers and human peers was different, and the user experience was ambivalent. Qualitative data showed that the participants anticipated future changes in the epistemic process in science classrooms, while acknowledging technical issues such as speech recognition performance and response latency. This study highlights the potential of Human-AI Collaboration for knowledge co-construction in authentic classroom settings and exemplify how AI could shape the future landscape of epistemic practices in the classroom.
TIA: A Teaching Intonation Assessment Dataset in Real Teaching Situations
Dec 14, 2023Intonation is one of the important factors affecting the teaching language arts, so it is an urgent problem to be addressed by evaluating the teachers' intonation through artificial intelligence technology. However, the lack of an intonation assessment dataset has hindered the development of the field. To this end, this paper constructs a Teaching Intonation Assessment (TIA) dataset for the first time in real teaching situations. This dataset covers 9 disciplines, 396 teachers, total of 11,444 utterance samples with a length of 15 seconds. In order to test the validity of the dataset, this paper proposes a teaching intonation assessment model (TIAM) based on low-level and deep-level features of speech. The experimental results show that TIAM based on the dataset constructed in this paper is basically consistent with the results of manual evaluation, and the results are better than the baseline models, which proves the effectiveness of the evaluation model.
Augmenty: A Python Library for Structured Text Augmentation
Dec 09, 2023Augmnety is a Python library for structured text augmentation. It is built on top of spaCy and allows for augmentation of both the text and its annotations. Augmenty provides a wide range of augmenters which can be combined in a flexible manner to create complex augmentation pipelines. It also includes a set of primitives that can be used to create custom augmenters such as word replacement augmenters. This functionality allows for augmentations within a range of applications such as named entity recognition (NER), part-of-speech tagging, and dependency parsing.
SPRING-INX: A Multilingual Indian Language Speech Corpus by SPRING Lab, IIT Madras
Oct 23, 2023India is home to a multitude of languages of which 22 languages are recognised by the Indian Constitution as official. Building speech based applications for the Indian population is a difficult problem owing to limited data and the number of languages and accents to accommodate. To encourage the language technology community to build speech based applications in Indian languages, we are open sourcing SPRING-INX data which has about 2000 hours of legally sourced and manually transcribed speech data for ASR system building in Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Odia, Punjabi and Tamil. This endeavor is by SPRING Lab , Indian Institute of Technology Madras and is a part of National Language Translation Mission (NLTM), funded by the Indian Ministry of Electronics and Information Technology (MeitY), Government of India. We describe the data collection and data cleaning process along with the data statistics in this paper.
Efficient Monotonic Multihead Attention
Dec 07, 2023We introduce the Efficient Monotonic Multihead Attention (EMMA), a state-of-the-art simultaneous translation model with numerically-stable and unbiased monotonic alignment estimation. In addition, we present improved training and inference strategies, including simultaneous fine-tuning from an offline translation model and reduction of monotonic alignment variance. The experimental results demonstrate that the proposed model attains state-of-the-art performance in simultaneous speech-to-text translation on the Spanish and English translation task.
Audio Deepfake Detection with Self-Supervised WavLM and Multi-Fusion Attentive Classifier
Dec 13, 2023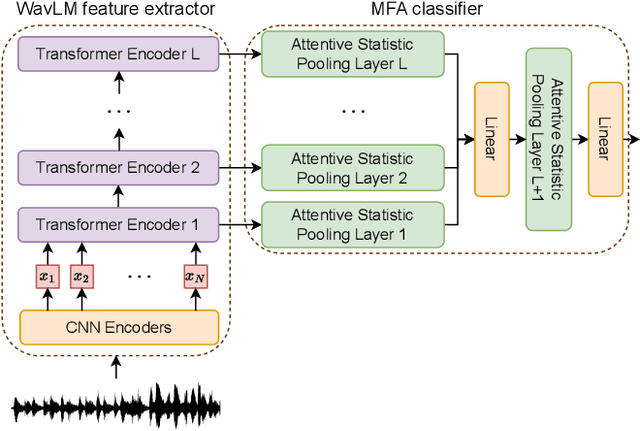
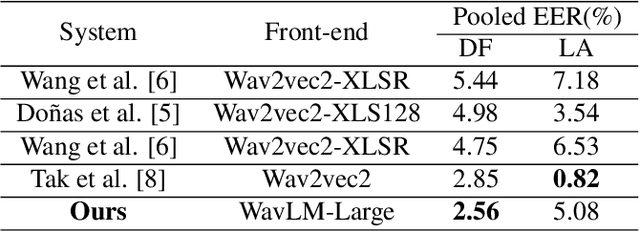
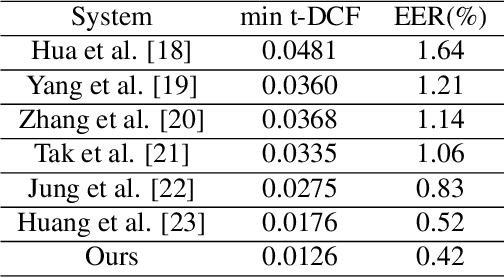

With the rapid development of speech synthesis and voice conversion technologies, Audio Deepfake has become a serious threat to the Automatic Speaker Verification (ASV) system. Numerous countermeasures are proposed to detect this type of attack. In this paper, we report our efforts to combine the self-supervised WavLM model and Multi-Fusion Attentive classifier for audio deepfake detection. Our method exploits the WavLM model to extract features that are more conducive to spoofing detection for the first time. Then, we propose a novel Multi-Fusion Attentive (MFA) classifier based on the Attentive Statistics Pooling (ASP) layer. The MFA captures the complementary information of audio features at both time and layer levels. Experiments demonstrate that our methods achieve state-of-the-art results on the ASVspoof 2021 DF set and provide competitive results on the ASVspoof 2019 and 2021 LA set.
Label Smoothing for Enhanced Text Sentiment Classification
Dec 11, 2023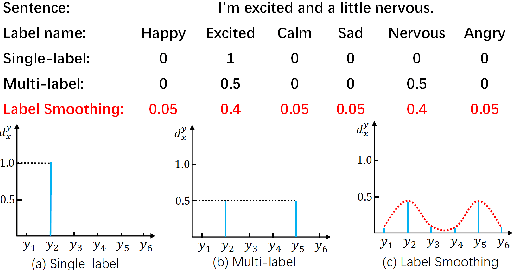

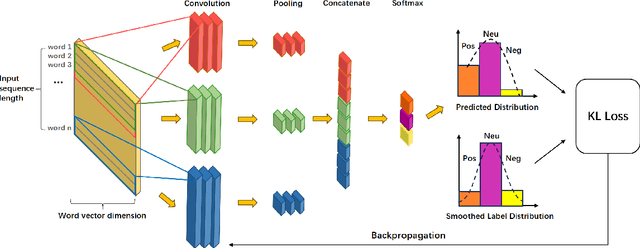
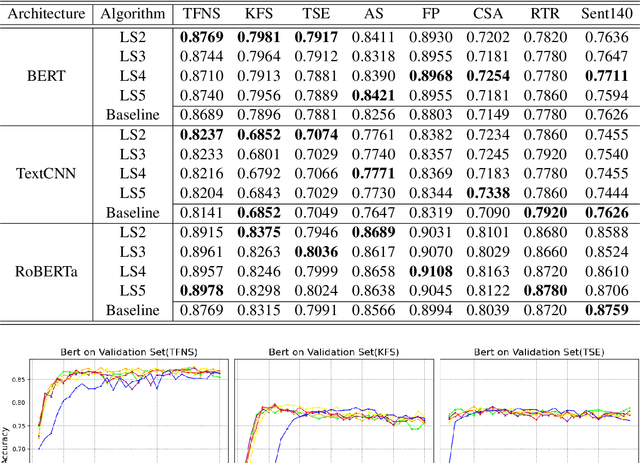
Label smoothing is a widely used technique in various domains, such as image classification and speech recognition, known for effectively combating model overfitting. However, there is few research on its application to text sentiment classification. To fill in the gap, this study investigates the implementation of label smoothing for sentiment classification by utilizing different levels of smoothing. The primary objective is to enhance sentiment classification accuracy by transforming discrete labels into smoothed label distributions. Through extensive experiments, we demonstrate the superior performance of label smoothing in text sentiment classification tasks across eight diverse datasets and deep learning architectures: TextCNN, BERT, and RoBERTa, under two learning schemes: training from scratch and fine-tuning.
End-to-end Joint Rich and Normalized ASR with a limited amount of rich training data
Nov 29, 2023Joint rich and normalized automatic speech recognition (ASR), that produces transcriptions both with and without punctuation and capitalization, remains a challenge. End-to-end (E2E) ASR models offer both convenience and the ability to perform such joint transcription of speech. Training such models requires paired speech and rich text data, which is not widely available. In this paper, we compare two different approaches to train a stateless Transducer-based E2E joint rich and normalized ASR system, ready for streaming applications, with a limited amount of rich labeled data. The first approach uses a language model to generate pseudo-rich transcriptions of normalized training data. The second approach uses a single decoder conditioned on the type of the output. The first approach leads to E2E rich ASR which perform better on out-of-domain data, with up to 9% relative reduction in errors. The second approach demonstrates the feasibility of an E2E joint rich and normalized ASR system using as low as 5% rich training data with moderate (2.42% absolute) increase in errors.
Understanding Probe Behaviors through Variational Bounds of Mutual Information
Dec 15, 2023With the success of self-supervised representations, researchers seek a better understanding of the information encapsulated within a representation. Among various interpretability methods, we focus on classification-based linear probing. We aim to foster a solid understanding and provide guidelines for linear probing by constructing a novel mathematical framework leveraging information theory. First, we connect probing with the variational bounds of mutual information (MI) to relax the probe design, equating linear probing with fine-tuning. Then, we investigate empirical behaviors and practices of probing through our mathematical framework. We analyze the layer-wise performance curve being convex, which seemingly violates the data processing inequality. However, we show that the intermediate representations can have the biggest MI estimate because of the tradeoff between better separability and decreasing MI. We further suggest that the margin of linearly separable representations can be a criterion for measuring the "goodness of representation." We also compare accuracy with MI as the measuring criteria. Finally, we empirically validate our claims by observing the self-supervised speech models on retaining word and phoneme information.
LIP-RTVE: An Audiovisual Database for Continuous Spanish in the Wild
Nov 21, 2023Speech is considered as a multi-modal process where hearing and vision are two fundamentals pillars. In fact, several studies have demonstrated that the robustness of Automatic Speech Recognition systems can be improved when audio and visual cues are combined to represent the nature of speech. In addition, Visual Speech Recognition, an open research problem whose purpose is to interpret speech by reading the lips of the speaker, has been a focus of interest in the last decades. Nevertheless, in order to estimate these systems in the currently Deep Learning era, large-scale databases are required. On the other hand, while most of these databases are dedicated to English, other languages lack sufficient resources. Thus, this paper presents a semi-automatically annotated audiovisual database to deal with unconstrained natural Spanish, providing 13 hours of data extracted from Spanish television. Furthermore, baseline results for both speaker-dependent and speaker-independent scenarios are reported using Hidden Markov Models, a traditional paradigm that has been widely used in the field of Speech Technologies.