 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Latent Feature-based Data Splits to Improve Generalisation Evaluation: A Hate Speech Detection Case Study
Nov 16, 2023
With the ever-growing presence of social media platforms comes the increased spread of harmful content and the need for robust hate speech detection systems. Such systems easily overfit to specific targets and keywords, and evaluating them without considering distribution shifts that might occur between train and test data overestimates their benefit. We challenge hate speech models via new train-test splits of existing datasets that rely on the clustering of models' hidden representations. We present two split variants (Subset-Sum-Split and Closest-Split) that, when applied to two datasets using four pretrained models, reveal how models catastrophically fail on blind spots in the latent space. This result generalises when developing a split with one model and evaluating it on another. Our analysis suggests that there is no clear surface-level property of the data split that correlates with the decreased performance, which underscores that task difficulty is not always humanly interpretable. We recommend incorporating latent feature-based splits in model development and release two splits via the GenBench benchmark.
Path Signature Representation of Patient-Clinician Interactions as a Predictor for Neuropsychological Tests Outcomes in Children: A Proof of Concept
Dec 12, 2023This research report presents a proof-of-concept study on the application of machine learning techniques to video and speech data collected during diagnostic cognitive assessments of children with a neurodevelopmental disorder. The study utilised a dataset of 39 video recordings, capturing extensive sessions where clinicians administered, among other things, four cognitive assessment tests. From the first 40 minutes of each clinical session, covering the administration of the Wechsler Intelligence Scale for Children (WISC-V), we extracted head positions and speech turns of both clinician and child. Despite the limited sample size and heterogeneous recording styles, the analysis successfully extracted path signatures as features from the recorded data, focusing on patient-clinician interactions. Importantly, these features quantify the interpersonal dynamics of the assessment process (dialogue and movement patterns). Results suggest that these features exhibit promising potential for predicting all cognitive tests scores of the entire session length and for prototyping a predictive model as a clinical decision support tool. Overall, this proof of concept demonstrates the feasibility of leveraging machine learning techniques for clinical video and speech data analysis in order to potentially enhance the efficiency of cognitive assessments for neurodevelopmental disorders in children.
Accented Speech Recognition With Accent-specific Codebooks
Oct 25, 2023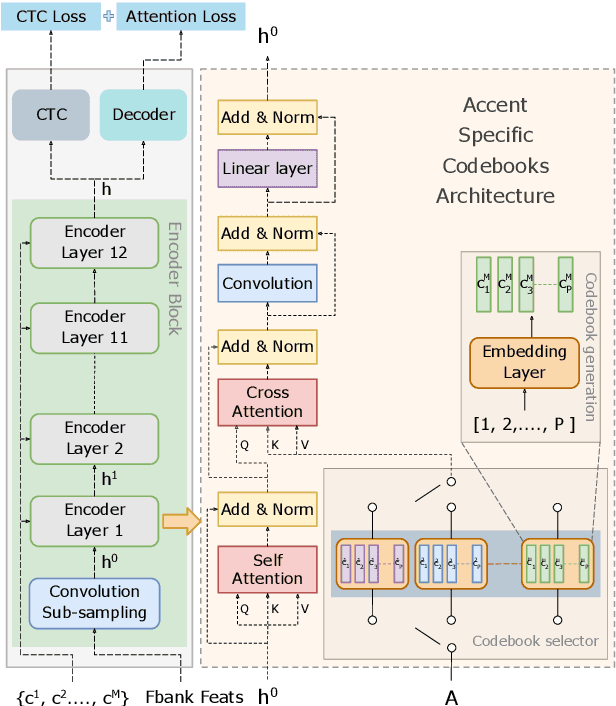
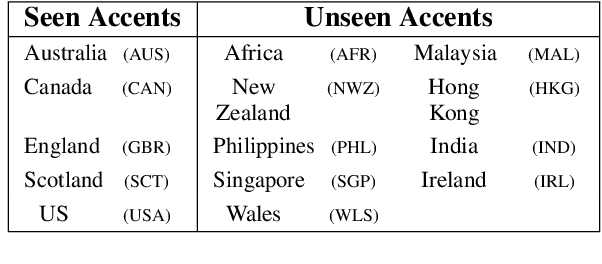
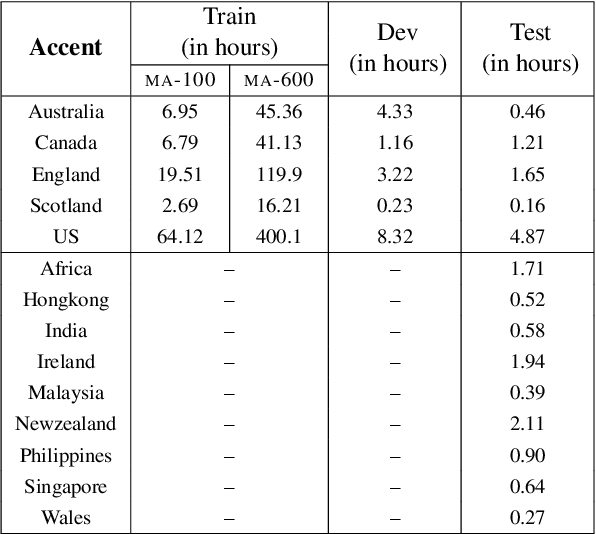
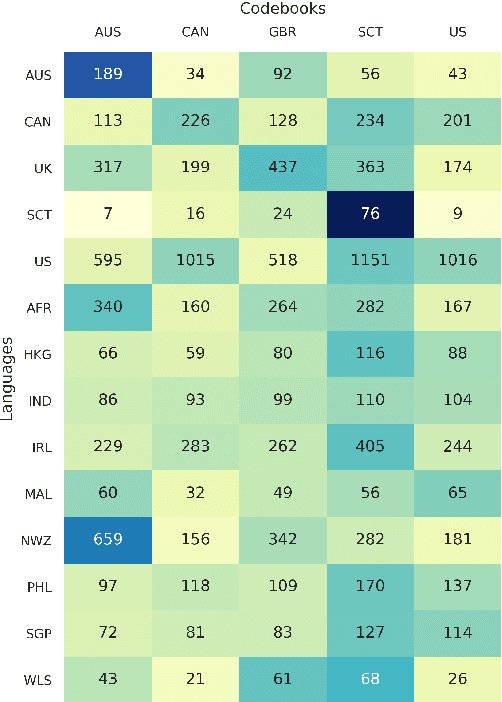
Speech accents pose a significant challenge to state-of-the-art automatic speech recognition (ASR) systems. Degradation in performance across underrepresented accents is a severe deterrent to the inclusive adoption of ASR. In this work, we propose a novel accent adaptation approach for end-to-end ASR systems using cross-attention with a trainable set of codebooks. These learnable codebooks capture accent-specific information and are integrated within the ASR encoder layers. The model is trained on accented English speech, while the test data also contained accents which were not seen during training. On the Mozilla Common Voice multi-accented dataset, we show that our proposed approach yields significant performance gains not only on the seen English accents (up to $37\%$ relative improvement in word error rate) but also on the unseen accents (up to $5\%$ relative improvement in WER). Further, we illustrate benefits for a zero-shot transfer setup on the L2Artic dataset. We also compare the performance with other approaches based on accent adversarial training.
Muted: Multilingual Targeted Offensive Speech Identification and Visualization
Dec 18, 2023Offensive language such as hate, abuse, and profanity (HAP) occurs in various content on the web. While previous work has mostly dealt with sentence level annotations, there have been a few recent attempts to identify offensive spans as well. We build upon this work and introduce Muted, a system to identify multilingual HAP content by displaying offensive arguments and their targets using heat maps to indicate their intensity. Muted can leverage any transformer-based HAP-classification model and its attention mechanism out-of-the-box to identify toxic spans, without further fine-tuning. In addition, we use the spaCy library to identify the specific targets and arguments for the words predicted by the attention heatmaps. We present the model's performance on identifying offensive spans and their targets in existing datasets and present new annotations on German text. Finally, we demonstrate our proposed visualization tool on multilingual inputs.
VOT: Revolutionizing Speaker Verification with Memory and Attention Mechanisms
Dec 28, 2023Speaker verification is essentially the process of identifying unknown speakers within an 'open set'. Our objective is to create optimal embeddings that condense information into concise speech-level representations, ensuring short distances within the same speaker and long distances between different speakers. Despite the prevalence of self-attention and convolution methods in speaker verification, they grapple with the challenge of high computational complexity.In order to surmount the limitations posed by the Transformer in extracting local features and the computational intricacies of multilayer convolution, we introduce the Memory-Attention framework. This framework incorporates a deep feed-forward temporal memory network (DFSMN) into the self-attention mechanism, capturing long-term context by stacking multiple layers and enhancing the modeling of local dependencies. Building upon this, we design a novel model called VOT, utilizing a parallel variable weight summation structure and introducing an attention-based statistical pooling layer.To address the hard sample mining problem, we enhance the AM-Softmax loss function and propose a new loss function named AM-Softmax-Focal. Experimental results on the VoxCeleb1 dataset not only showcase a significant improvement in system performance but also surpass the majority of mainstream models, validating the importance of local information in the speaker verification task. The code will be available on GitHub.
Make BERT-based Chinese Spelling Check Model Enhanced by Layerwise Attention and Gaussian Mixture Model
Dec 27, 2023BERT-based models have shown a remarkable ability in the Chinese Spelling Check (CSC) task recently. However, traditional BERT-based methods still suffer from two limitations. First, although previous works have identified that explicit prior knowledge like Part-Of-Speech (POS) tagging can benefit in the CSC task, they neglected the fact that spelling errors inherent in CSC data can lead to incorrect tags and therefore mislead models. Additionally, they ignored the correlation between the implicit hierarchical information encoded by BERT's intermediate layers and different linguistic phenomena. This results in sub-optimal accuracy. To alleviate the above two issues, we design a heterogeneous knowledge-infused framework to strengthen BERT-based CSC models. To incorporate explicit POS knowledge, we utilize an auxiliary task strategy driven by Gaussian mixture model. Meanwhile, to incorporate implicit hierarchical linguistic knowledge within the encoder, we propose a novel form of n-gram-based layerwise self-attention to generate a multilayer representation. Experimental results show that our proposed framework yields a stable performance boost over four strong baseline models and outperforms the previous state-of-the-art methods on two datasets.
* 10 pages, 4 figures, 2023 International Joint Conference on Neural Networks (IJCNN)
Extending Whisper with prompt tuning to target-speaker ASR
Dec 13, 2023Target-speaker automatic speech recognition (ASR) aims to transcribe the desired speech of a target speaker from multi-talker overlapped utterances. Most of the existing target-speaker ASR (TS-ASR) methods involve either training from scratch or fully fine-tuning a pre-trained model, leading to significant training costs and becoming inapplicable to large foundation models. This work leverages prompt tuning, a parameter-efficient fine-tuning approach, to extend Whisper, a large-scale single-talker ASR model, to TS-ASR. Experimental results show that prompt tuning can achieve performance comparable to state-of-the-art full fine-tuning approaches while only requiring about 1% of task-specific model parameters. Notably, the original Whisper's features, such as inverse text normalization and timestamp prediction, are retained in target-speaker ASR, keeping the generated transcriptions natural and informative.
Acoustic BPE for Speech Generation with Discrete Tokens
Oct 23, 2023Discrete audio tokens derived from self-supervised learning models have gained widespread usage in speech generation. However, current practice of directly utilizing audio tokens poses challenges for sequence modeling due to the length of the token sequence. Additionally, this approach places the burden on the model to establish correlations between tokens, further complicating the modeling process. To address this issue, we propose acoustic BPE which encodes frequent audio token patterns by utilizing byte-pair encoding. Acoustic BPE effectively reduces the sequence length and leverages the prior morphological information present in token sequence, which alleviates the modeling challenges of token correlation. Through comprehensive investigations on a speech language model trained with acoustic BPE, we confirm the notable advantages it offers, including faster inference and improved syntax capturing capabilities. In addition, we propose a novel rescore method to select the optimal synthetic speech among multiple candidates generated by rich-diversity TTS system. Experiments prove that rescore selection aligns closely with human preference, which highlights acoustic BPE's potential to other speech generation tasks.
Enhancing Consistency in Multimodal Dialogue System Using LLM with Dialogue Scenario
Dec 20, 2023This paper describes our dialogue system submitted to Dialogue Robot Competition 2023. The system's task is to help a user at a travel agency decide on a plan for visiting two sightseeing spots in Kyoto City that satisfy the user. Our dialogue system is flexible and stable and responds to user requirements by controlling dialogue flow according to dialogue scenarios. We also improved user satisfaction by introducing motion and speech control based on system utterances and user situations. In the preliminary round, our system was ranked fifth in the impression evaluation and sixth in the plan evaluation among all 12 teams.
Audio-visual fine-tuning of audio-only ASR models
Dec 14, 2023Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.