 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Accented Speech Recognition With Accent-specific Codebooks
Oct 27, 2023
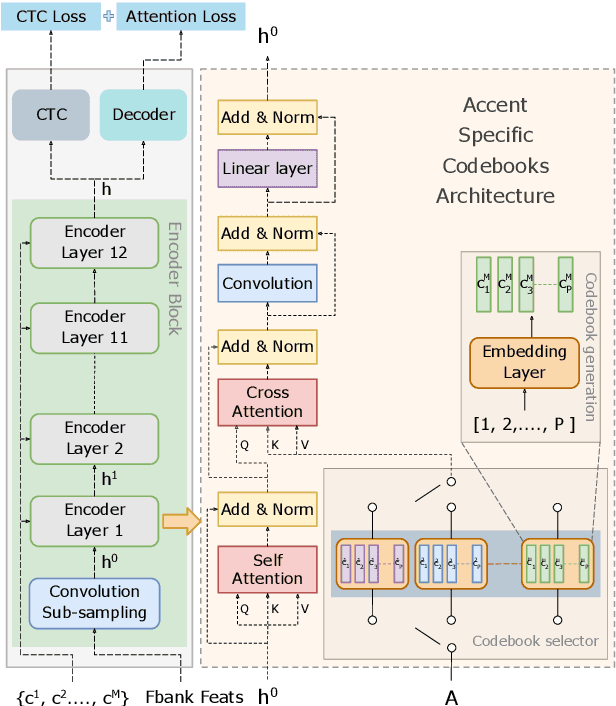
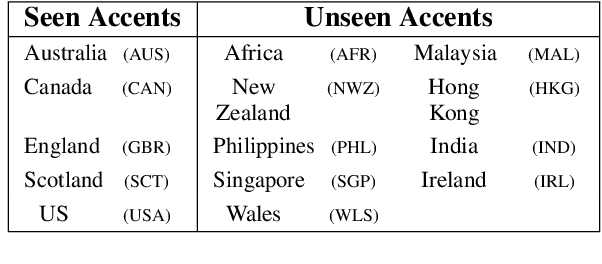
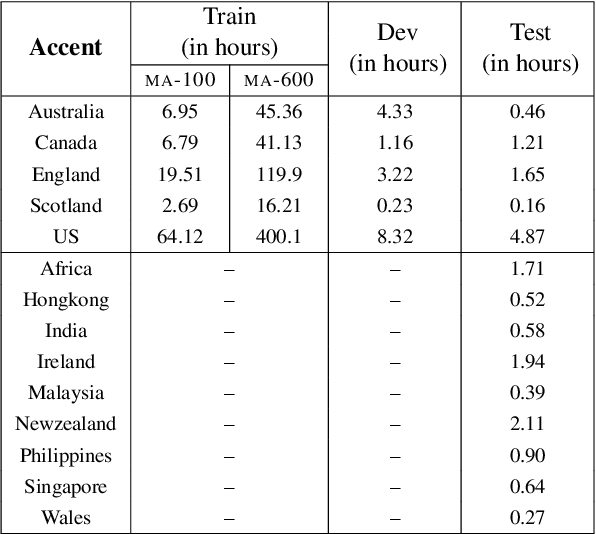
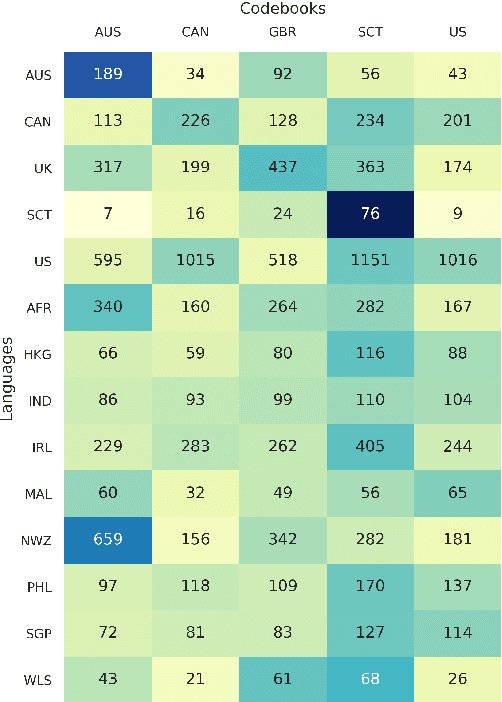
Speech accents pose a significant challenge to state-of-the-art automatic speech recognition (ASR) systems. Degradation in performance across underrepresented accents is a severe deterrent to the inclusive adoption of ASR. In this work, we propose a novel accent adaptation approach for end-to-end ASR systems using cross-attention with a trainable set of codebooks. These learnable codebooks capture accent-specific information and are integrated within the ASR encoder layers. The model is trained on accented English speech, while the test data also contained accents which were not seen during training. On the Mozilla Common Voice multi-accented dataset, we show that our proposed approach yields significant performance gains not only on the seen English accents (up to $37\%$ relative improvement in word error rate) but also on the unseen accents (up to $5\%$ relative improvement in WER). Further, we illustrate benefits for a zero-shot transfer setup on the L2Artic dataset. We also compare the performance with other approaches based on accent adversarial training.
SpokesBiz -- an Open Corpus of Conversational Polish
Dec 19, 2023This paper announces the early release of SpokesBiz, a freely available corpus of conversational Polish developed within the CLARIN-BIZ project and comprising over 650 hours of recordings. The transcribed recordings have been diarized and manually annotated for punctuation and casing. We outline the general structure and content of the corpus, showcasing selected applications in linguistic research, evaluation and improvement of automatic speech recognition (ASR) systems
DCHT: Deep Complex Hybrid Transformer for Speech Enhancement
Oct 30, 2023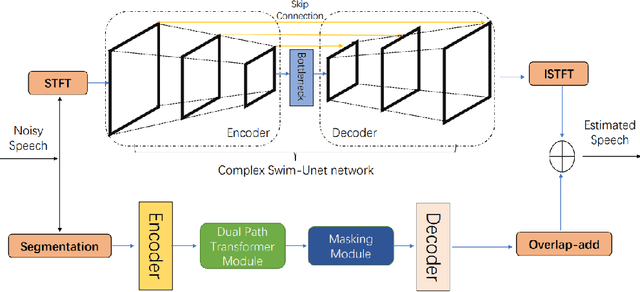
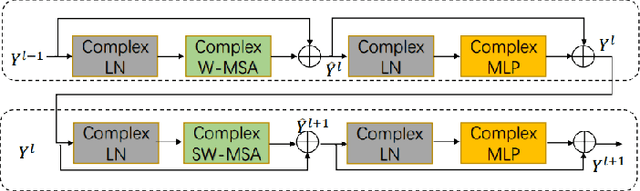
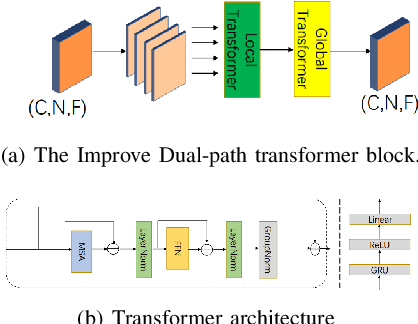
Most of the current deep learning-based approaches for speech enhancement only operate in the spectrogram or waveform domain. Although a cross-domain transformer combining waveform- and spectrogram-domain inputs has been proposed, its performance can be further improved. In this paper, we present a novel deep complex hybrid transformer that integrates both spectrogram and waveform domains approaches to improve the performance of speech enhancement. The proposed model consists of two parts: a complex Swin-Unet in the spectrogram domain and a dual-path transformer network (DPTnet) in the waveform domain. We first construct a complex Swin-Unet network in the spectrogram domain and perform speech enhancement in the complex audio spectrum. We then introduce improved DPT by adding memory-compressed attention. Our model is capable of learning multi-domain features to reduce existing noise on different domains in a complementary way. The experimental results on the BirdSoundsDenoising dataset and the VCTK+DEMAND dataset indicate that our method can achieve better performance compared to state-of-the-art methods.
Enhancing Spoofing Speech Detection Using Rhythm Information
Oct 18, 2023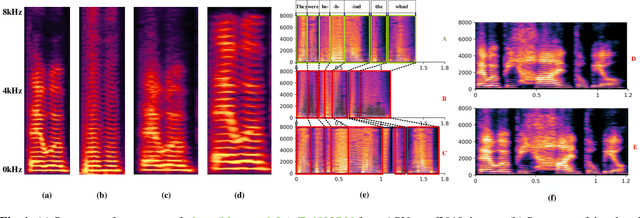
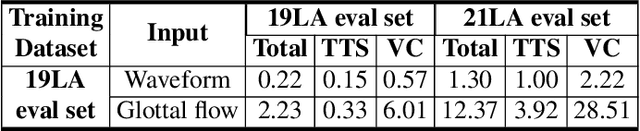
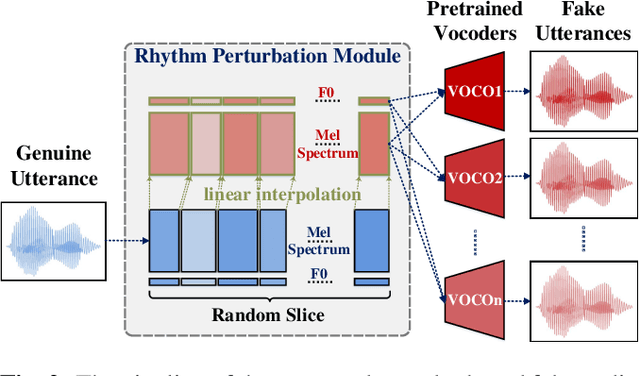
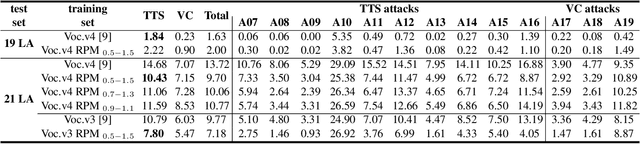
Spoofing speech detection is a hot and in-demand research field. However, current spoofing speech detection systems is lack of convincing evidence. In this paper, to increase the reliability of detection systems, the flaws of rhythm information inherent in the TTS-generated speech are analyzed. TTS models take text as input and utilize acoustic models to predict rhythm information, which introduces artifacts in the rhythm information. By filtering out vocal tract response, the remaining glottal flow with rhythm information retains detection ability for TTS-generated speech. Based on these analyses, a rhythm perturbation module is proposed to enhance the copy-synthesis data augmentation method. Fake utterances generated by the proposed method force the detecting model to pay attention to the artifacts in rhythm information and effectively improve the ability to detect TTS-generated speech of the anti-spoofing countermeasures.
Detecting Speech Abnormalities with a Perceiver-based Sequence Classifier that Leverages a Universal Speech Model
Oct 16, 2023We propose a Perceiver-based sequence classifier to detect abnormalities in speech reflective of several neurological disorders. We combine this classifier with a Universal Speech Model (USM) that is trained (unsupervised) on 12 million hours of diverse audio recordings. Our model compresses long sequences into a small set of class-specific latent representations and a factorized projection is used to predict different attributes of the disordered input speech. The benefit of our approach is that it allows us to model different regions of the input for different classes and is at the same time data efficient. We evaluated the proposed model extensively on a curated corpus from the Mayo Clinic. Our model outperforms standard transformer (80.9%) and perceiver (81.8%) models and achieves an average accuracy of 83.1%. With limited task-specific data, we find that pretraining is important and surprisingly pretraining with the unrelated automatic speech recognition (ASR) task is also beneficial. Encodings from the middle layers provide a mix of both acoustic and phonetic information and achieve best prediction results compared to just using the final layer encodings (83.1% vs. 79.6%). The results are promising and with further refinements may help clinicians detect speech abnormalities without needing access to highly specialized speech-language pathologists.
Rapid Speaker Adaptation in Low Resource Text to Speech Systems using Synthetic Data and Transfer learning
Dec 02, 2023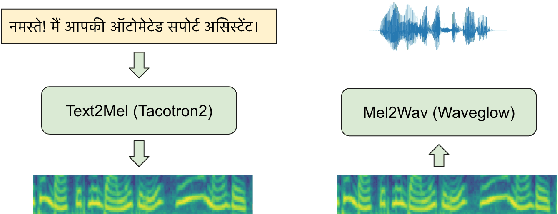

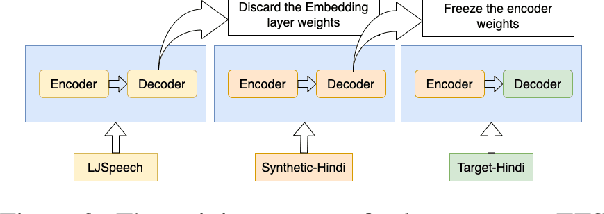
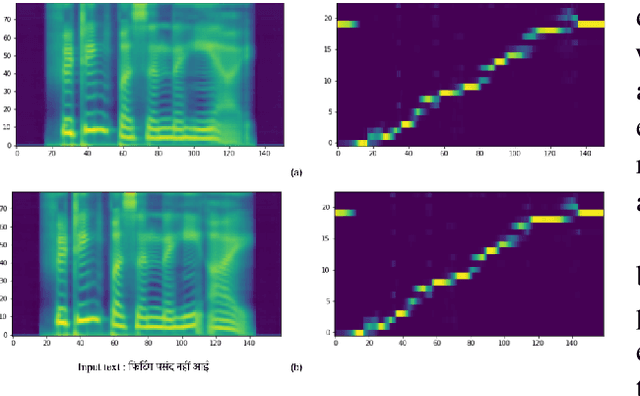
Text-to-speech (TTS) systems are being built using end-to-end deep learning approaches. However, these systems require huge amounts of training data. We present our approach to built production quality TTS and perform speaker adaptation in extremely low resource settings. We propose a transfer learning approach using high-resource language data and synthetically generated data. We transfer the learnings from the out-domain high-resource English language. Further, we make use of out-of-the-box single-speaker TTS in the target language to generate in-domain synthetic data. We employ a three-step approach to train a high-quality single-speaker TTS system in a low-resource Indian language Hindi. We use a Tacotron2 like setup with a spectrogram prediction network and a waveglow vocoder. The Tacotron2 acoustic model is trained on English data, followed by synthetic Hindi data from the existing TTS system. Finally, the decoder of this model is fine-tuned on only 3 hours of target Hindi speaker data to enable rapid speaker adaptation. We show the importance of this dual pre-training and decoder-only fine-tuning using subjective MOS evaluation. Using transfer learning from high-resource language and synthetic corpus we present a low-cost solution to train a custom TTS model.
Automatic Textual Normalization for Hate Speech Detection
Nov 15, 2023Social media data is a valuable resource for research, yet it contains a wide range of non-standard words (NSW). These irregularities hinder the effective operation of NLP tools. Current state-of-the-art methods for the Vietnamese language address this issue as a problem of lexical normalization, involving the creation of manual rules or the implementation of multi-staged deep learning frameworks, which necessitate extensive efforts to craft intricate rules. In contrast, our approach is straightforward, employing solely a sequence-to-sequence (Seq2Seq) model. In this research, we provide a dataset for textual normalization, comprising 2,181 human-annotated comments with an inter-annotator agreement of 0.9014. By leveraging the Seq2Seq model for textual normalization, our results reveal that the accuracy achieved falls slightly short of 70%. Nevertheless, textual normalization enhances the accuracy of the Hate Speech Detection (HSD) task by approximately 2%, demonstrating its potential to improve the performance of complex NLP tasks. Our dataset is accessible for research purposes.
Pseudo-Labeling for Domain-Agnostic Bangla Automatic Speech Recognition
Nov 06, 2023One of the major challenges for developing automatic speech recognition (ASR) for low-resource languages is the limited access to labeled data with domain-specific variations. In this study, we propose a pseudo-labeling approach to develop a large-scale domain-agnostic ASR dataset. With the proposed methodology, we developed a 20k+ hours labeled Bangla speech dataset covering diverse topics, speaking styles, dialects, noisy environments, and conversational scenarios. We then exploited the developed corpus to design a conformer-based ASR system. We benchmarked the trained ASR with publicly available datasets and compared it with other available models. To investigate the efficacy, we designed and developed a human-annotated domain-agnostic test set composed of news, telephony, and conversational data among others. Our results demonstrate the efficacy of the model trained on psuedo-label data for the designed test-set along with publicly-available Bangla datasets. The experimental resources will be publicly available.(https://github.com/hishab-nlp/Pseudo-Labeling-for-Domain-Agnostic-Bangla-ASR)
Cross-Linguistic Offensive Language Detection: BERT-Based Analysis of Bengali, Assamese, & Bodo Conversational Hateful Content from Social Media
Dec 16, 2023In today's age, social media reigns as the paramount communication platform, providing individuals with the avenue to express their conjectures, intellectual propositions, and reflections. Unfortunately, this freedom often comes with a downside as it facilitates the widespread proliferation of hate speech and offensive content, leaving a deleterious impact on our world. Thus, it becomes essential to discern and eradicate such offensive material from the realm of social media. This article delves into the comprehensive results and key revelations from the HASOC-2023 offensive language identification result. The primary emphasis is placed on the meticulous detection of hate speech within the linguistic domains of Bengali, Assamese, and Bodo, forming the framework for Task 4: Annihilate Hates. In this work, we used BERT models, including XML-Roberta, L3-cube, IndicBERT, BenglaBERT, and BanglaHateBERT. The research outcomes were promising and showed that XML-Roberta-lagre performed better than monolingual models in most cases. Our team 'TeamBD' achieved rank 3rd for Task 4 - Assamese, & 5th for Bengali.
UniX-Encoder: A Universal $X$-Channel Speech Encoder for Ad-Hoc Microphone Array Speech Processing
Oct 25, 2023The speech field is evolving to solve more challenging scenarios, such as multi-channel recordings with multiple simultaneous talkers. Given the many types of microphone setups out there, we present the UniX-Encoder. It's a universal encoder designed for multiple tasks, and worked with any microphone array, in both solo and multi-talker environments. Our research enhances previous multi-channel speech processing efforts in four key areas: 1) Adaptability: Contrasting traditional models constrained to certain microphone array configurations, our encoder is universally compatible. 2) Multi-Task Capability: Beyond the single-task focus of previous systems, UniX-Encoder acts as a robust upstream model, adeptly extracting features for diverse tasks including ASR and speaker recognition. 3) Self-Supervised Training: The encoder is trained without requiring labeled multi-channel data. 4) End-to-End Integration: In contrast to models that first beamform then process single-channels, our encoder offers an end-to-end solution, bypassing explicit beamforming or separation. To validate its effectiveness, we tested the UniX-Encoder on a synthetic multi-channel dataset from the LibriSpeech corpus. Across tasks like speech recognition and speaker diarization, our encoder consistently outperformed combinations like the WavLM model with the BeamformIt frontend.