 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Neural Networks Hear You Loud And Clear: Hearing Loss Compensation Using Deep Neural Networks
Mar 15, 2024
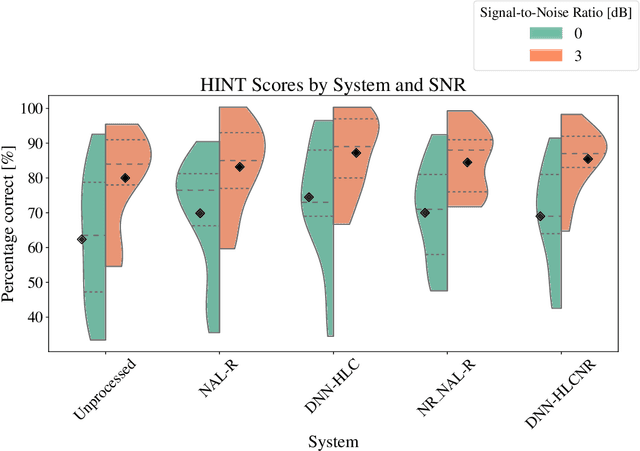
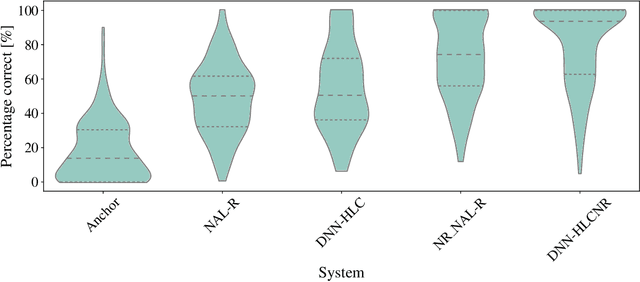
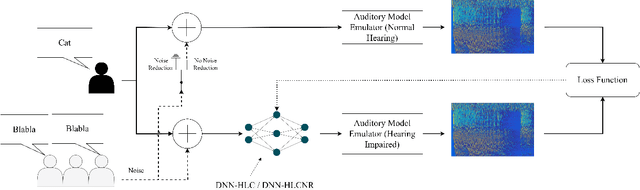
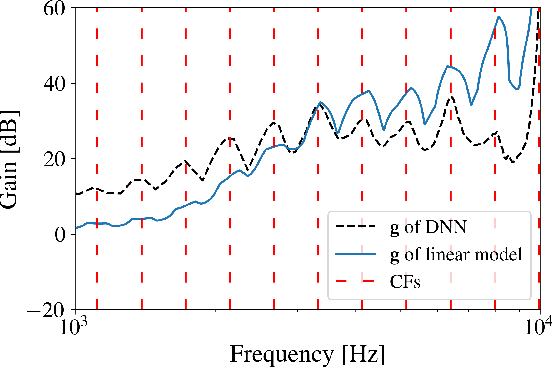
This article investigates the use of deep neural networks (DNNs) for hearing-loss compensation. Hearing loss is a prevalent issue affecting millions of people worldwide, and conventional hearing aids have limitations in providing satisfactory compensation. DNNs have shown remarkable performance in various auditory tasks, including speech recognition, speaker identification, and music classification. In this study, we propose a DNN-based approach for hearing-loss compensation, which is trained on the outputs of hearing-impaired and normal-hearing DNN-based auditory models in response to speech signals. First, we introduce a framework for emulating auditory models using DNNs, focusing on an auditory-nerve model in the auditory pathway. We propose a linearization of the DNN-based approach, which we use to analyze the DNN-based hearing-loss compensation. Additionally we develop a simple approach to choose the acoustic center frequencies of the auditory model used for the compensation strategy. Finally, we evaluate the DNN-based hearing-loss compensation strategies using listening tests with hearing impaired listeners. The results demonstrate that the proposed approach results in feasible hearing-loss compensation strategies. Our proposed approach was shown to provide an increase in speech intelligibility and was found to outperform a conventional approach in terms of perceived speech quality.
Fusion approaches for emotion recognition from speech using acoustic and text-based features
Mar 27, 2024In this paper, we study different approaches for classifying emotions from speech using acoustic and text-based features. We propose to obtain contextualized word embeddings with BERT to represent the information contained in speech transcriptions and show that this results in better performance than using Glove embeddings. We also propose and compare different strategies to combine the audio and text modalities, evaluating them on IEMOCAP and MSP-PODCAST datasets. We find that fusing acoustic and text-based systems is beneficial on both datasets, though only subtle differences are observed across the evaluated fusion approaches. Finally, for IEMOCAP, we show the large effect that the criteria used to define the cross-validation folds have on results. In particular, the standard way of creating folds for this dataset results in a highly optimistic estimation of performance for the text-based system, suggesting that some previous works may overestimate the advantage of incorporating transcriptions.
The NeurIPS 2023 Machine Learning for Audio Workshop: Affective Audio Benchmarks and Novel Data
Mar 21, 2024


The NeurIPS 2023 Machine Learning for Audio Workshop brings together machine learning (ML) experts from various audio domains. There are several valuable audio-driven ML tasks, from speech emotion recognition to audio event detection, but the community is sparse compared to other ML areas, e.g., computer vision or natural language processing. A major limitation with audio is the available data; with audio being a time-dependent modality, high-quality data collection is time-consuming and costly, making it challenging for academic groups to apply their often state-of-the-art strategies to a larger, more generalizable dataset. In this short white paper, to encourage researchers with limited access to large-datasets, the organizers first outline several open-source datasets that are available to the community, and for the duration of the workshop are making several propriety datasets available. Namely, three vocal datasets, Hume-Prosody, Hume-VocalBurst, an acted emotional speech dataset Modulate-Sonata, and an in-game streamer dataset Modulate-Stream. We outline the current baselines on these datasets but encourage researchers from across audio to utilize them outside of the initial baseline tasks.
Energy-Based Models with Applications to Speech and Language Processing
Mar 16, 2024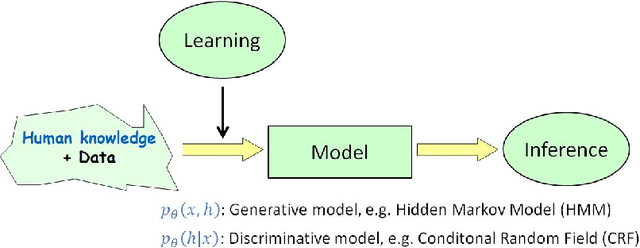
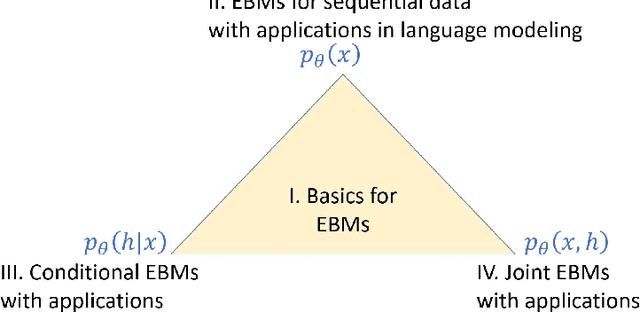
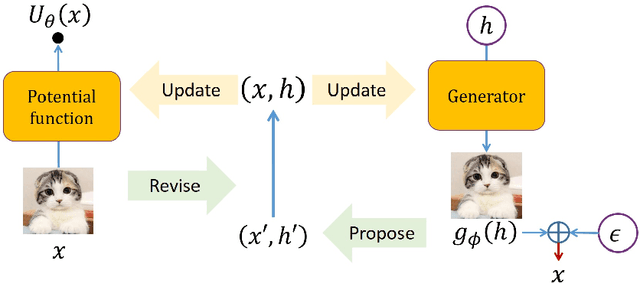
Energy-Based Models (EBMs) are an important class of probabilistic models, also known as random fields and undirected graphical models. EBMs are un-normalized and thus radically different from other popular self-normalized probabilistic models such as hidden Markov models (HMMs), autoregressive models, generative adversarial nets (GANs) and variational auto-encoders (VAEs). Over the past years, EBMs have attracted increasing interest not only from the core machine learning community, but also from application domains such as speech, vision, natural language processing (NLP) and so on, due to significant theoretical and algorithmic progress. The sequential nature of speech and language also presents special challenges and needs a different treatment from processing fix-dimensional data (e.g., images). Therefore, the purpose of this monograph is to present a systematic introduction to energy-based models, including both algorithmic progress and applications in speech and language processing. First, the basics of EBMs are introduced, including classic models, recent models parameterized by neural networks, sampling methods, and various learning methods from the classic learning algorithms to the most advanced ones. Then, the application of EBMs in three different scenarios is presented, i.e., for modeling marginal, conditional and joint distributions, respectively. 1) EBMs for sequential data with applications in language modeling, where the main focus is on the marginal distribution of a sequence itself; 2) EBMs for modeling conditional distributions of target sequences given observation sequences, with applications in speech recognition, sequence labeling and text generation; 3) EBMs for modeling joint distributions of both sequences of observations and targets, and their applications in semi-supervised learning and calibrated natural language understanding.
* The version before publisher editing
What has LeBenchmark Learnt about French Syntax?
Mar 04, 2024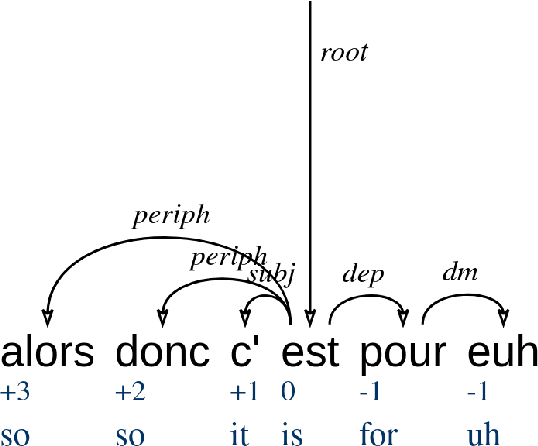
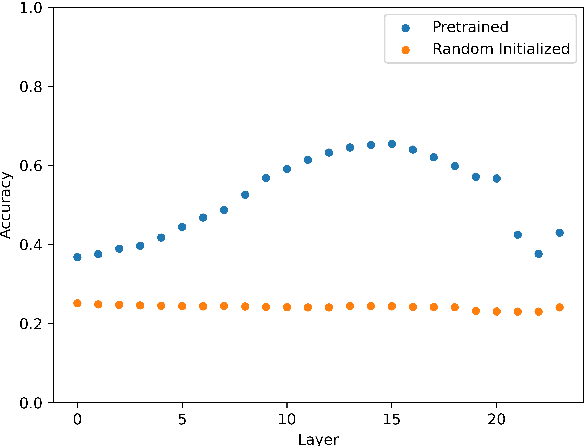
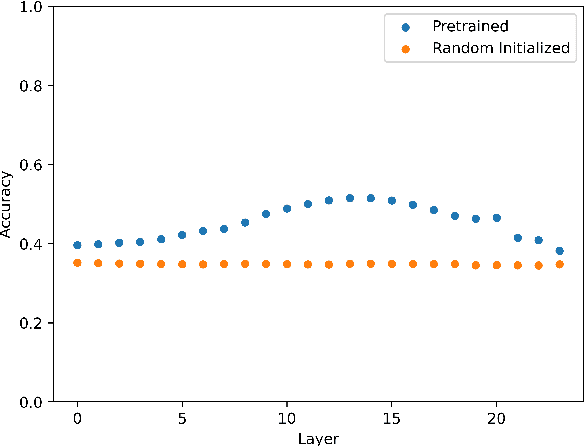
The paper reports on a series of experiments aiming at probing LeBenchmark, a pretrained acoustic model trained on 7k hours of spoken French, for syntactic information. Pretrained acoustic models are increasingly used for downstream speech tasks such as automatic speech recognition, speech translation, spoken language understanding or speech parsing. They are trained on very low level information (the raw speech signal), and do not have explicit lexical knowledge. Despite that, they obtained reasonable results on tasks that requires higher level linguistic knowledge. As a result, an emerging question is whether these models encode syntactic information. We probe each representation layer of LeBenchmark for syntax, using the Orf\'eo treebank, and observe that it has learnt some syntactic information. Our results show that syntactic information is more easily extractable from the middle layers of the network, after which a very sharp decrease is observed.
Towards Decoupling Frontend Enhancement and Backend Recognition in Monaural Robust ASR
Mar 11, 2024
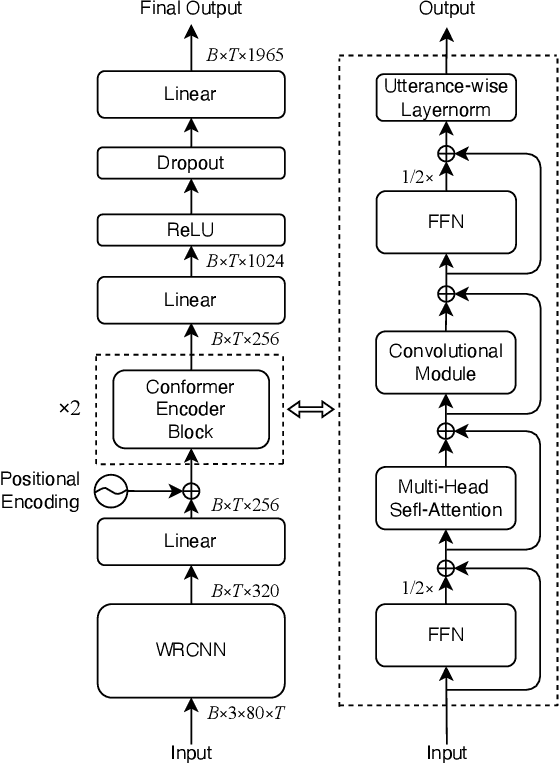
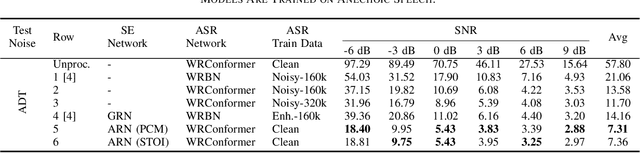
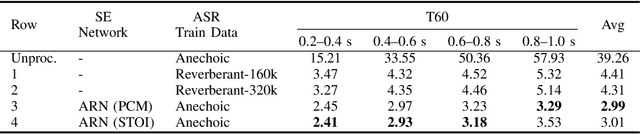
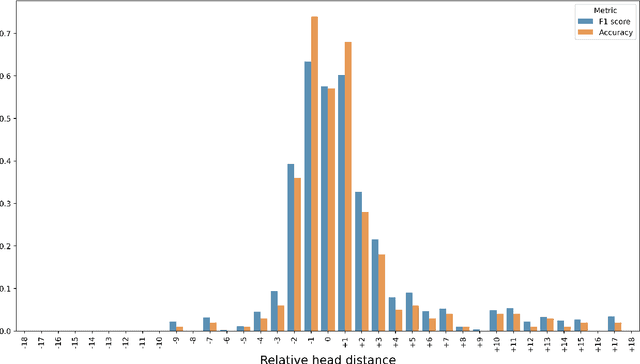
It has been shown that the intelligibility of noisy speech can be improved by speech enhancement (SE) algorithms. However, monaural SE has not been established as an effective frontend for automatic speech recognition (ASR) in noisy conditions compared to an ASR model trained on noisy speech directly. The divide between SE and ASR impedes the progress of robust ASR systems, especially as SE has made major advances in recent years. This paper focuses on eliminating this divide with an ARN (attentive recurrent network) time-domain and a CrossNet time-frequency domain enhancement models. The proposed systems fully decouple frontend enhancement and backend ASR trained only on clean speech. Results on the WSJ, CHiME-2, LibriSpeech, and CHiME-4 corpora demonstrate that ARN and CrossNet enhanced speech both translate to improved ASR results in noisy and reverberant environments, and generalize well to real acoustic scenarios. The proposed system outperforms the baselines trained on corrupted speech directly. Furthermore, it cuts the previous best word error rate (WER) on CHiME-2 by $28.4\%$ relatively with a $5.57\%$ WER, and achieves $3.32/4.44\%$ WER on single-channel CHiME-4 simulated/real test data without training on CHiME-4.
SCORE: Self-supervised Correspondence Fine-tuning for Improved Content Representations
Mar 10, 2024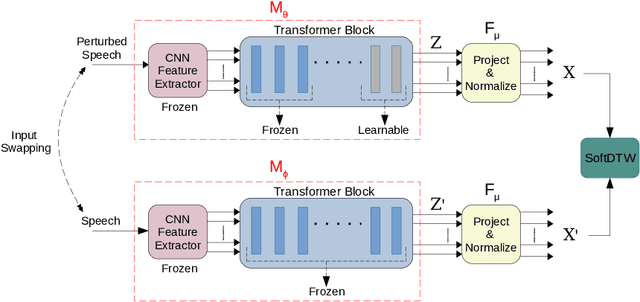
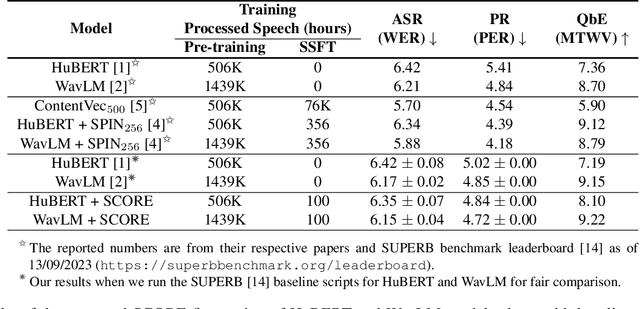
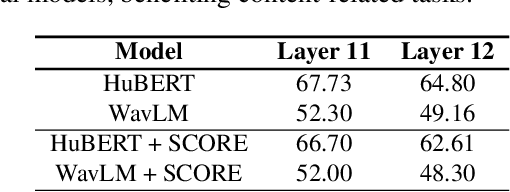
There is a growing interest in cost-effective self-supervised fine-tuning (SSFT) of self-supervised learning (SSL)-based speech models to obtain task-specific representations. These task-specific representations are used for robust performance on various downstream tasks by fine-tuning on the labelled data. This work presents a cost-effective SSFT method named Self-supervised Correspondence (SCORE) fine-tuning to adapt the SSL speech representations for content-related tasks. The proposed method uses a correspondence training strategy, aiming to learn similar representations from perturbed speech and original speech. Commonly used data augmentation techniques for content-related tasks (ASR) are applied to obtain perturbed speech. SCORE fine-tuned HuBERT outperforms the vanilla HuBERT on SUPERB benchmark with only a few hours of fine-tuning (< 5 hrs) on a single GPU for automatic speech recognition, phoneme recognition, and query-by-example tasks, with relative improvements of 1.09%, 3.58%, and 12.65%, respectively. SCORE provides competitive results with the recently proposed SSFT method SPIN, using only 1/3 of the processed speech compared to SPIN.
AIx Speed: Playback Speed Optimization Using Listening Comprehension of Speech Recognition Models
Mar 05, 2024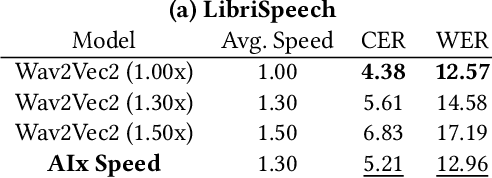
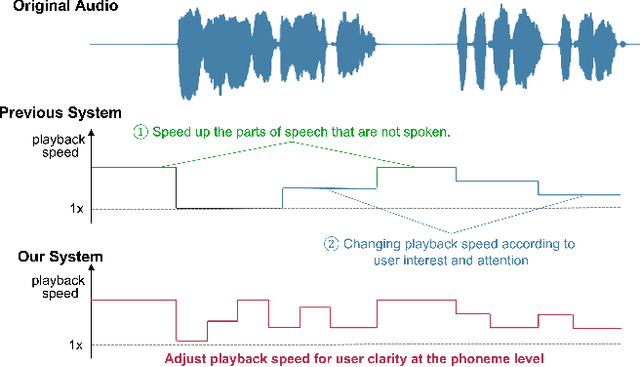
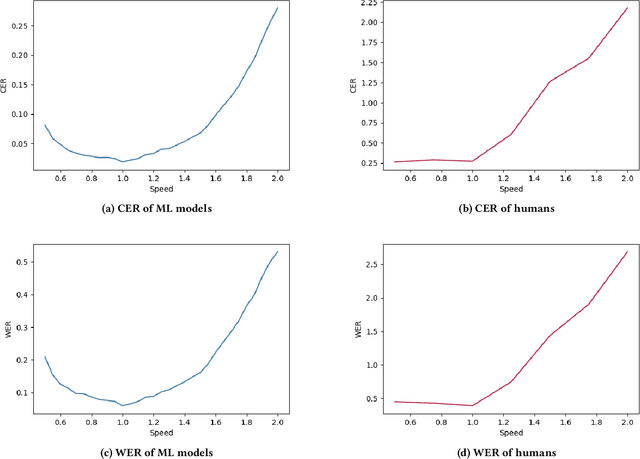
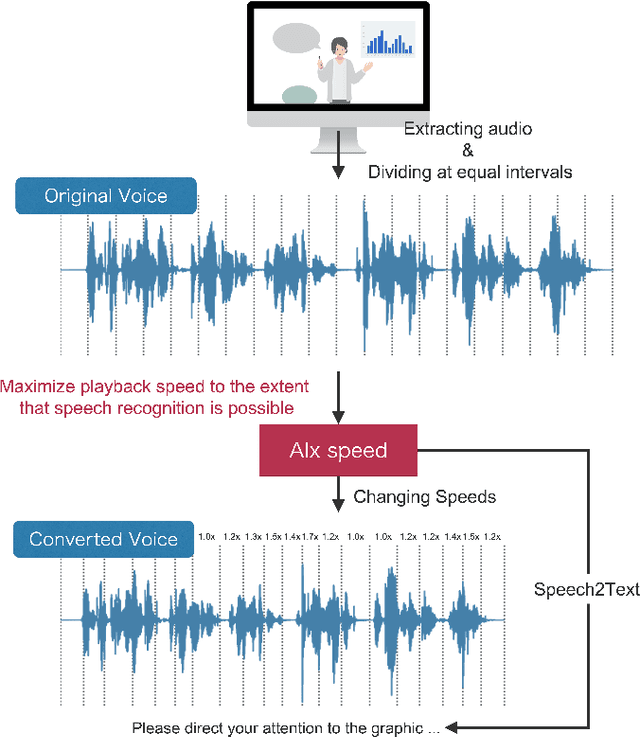
Since humans can listen to audio and watch videos at faster speeds than actually observed, we often listen to or watch these pieces of content at higher playback speeds to increase the time efficiency of content comprehension. To further utilize this capability, systems that automatically adjust the playback speed according to the user's condition and the type of content to assist in more efficient comprehension of time-series content have been developed. However, there is still room for these systems to further extend human speed-listening ability by generating speech with playback speed optimized for even finer time units and providing it to humans. In this study, we determine whether humans can hear the optimized speech and propose a system that automatically adjusts playback speed at units as small as phonemes while ensuring speech intelligibility. The system uses the speech recognizer score as a proxy for how well a human can hear a certain unit of speech and maximizes the speech playback speed to the extent that a human can hear. This method can be used to produce fast but intelligible speech. In the evaluation experiment, we compared the speech played back at a constant fast speed and the flexibly speed-up speech generated by the proposed method in a blind test and confirmed that the proposed method produced speech that was easier to listen to.
SlideAVSR: A Dataset of Paper Explanation Videos for Audio-Visual Speech Recognition
Jan 18, 2024Audio-visual speech recognition (AVSR) is a multimodal extension of automatic speech recognition (ASR), using video as a complement to audio. In AVSR, considerable efforts have been directed at datasets for facial features such as lip-readings, while they often fall short in evaluating the image comprehension capabilities in broader contexts. In this paper, we construct SlideAVSR, an AVSR dataset using scientific paper explanation videos. SlideAVSR provides a new benchmark where models transcribe speech utterances with texts on the slides on the presentation recordings. As technical terminologies that are frequent in paper explanations are notoriously challenging to transcribe without reference texts, our SlideAVSR dataset spotlights a new aspect of AVSR problems. As a simple yet effective baseline, we propose DocWhisper, an AVSR model that can refer to textual information from slides, and confirm its effectiveness on SlideAVSR.
Two-pass Endpoint Detection for Speech Recognition
Jan 17, 2024Endpoint (EP) detection is a key component of far-field speech recognition systems that assist the user through voice commands. The endpoint detector has to trade-off between accuracy and latency, since waiting longer reduces the cases of users being cut-off early. We propose a novel two-pass solution for endpointing, where the utterance endpoint detected from a first pass endpointer is verified by a 2nd-pass model termed EP Arbitrator. Our method improves the trade-off between early cut-offs and latency over a baseline endpointer, as tested on datasets including voice-assistant transactional queries, conversational speech, and the public SLURP corpus. We demonstrate that our method shows improvements regardless of the first-pass EP model used.