 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Morphology-Based Investigation of Positional Encodings
Apr 06, 2024
How does the importance of positional encoding in pre-trained language models (PLMs) vary across languages with different morphological complexity? In this paper, we offer the first study addressing this question, encompassing 23 morphologically diverse languages and 5 different downstream tasks. We choose two categories of tasks: syntactic tasks (part-of-speech tagging, named entity recognition, dependency parsing) and semantic tasks (natural language inference, paraphrasing). We consider language-specific BERT models trained on monolingual corpus for our investigation. The main experiment consists of nullifying the effect of positional encoding during fine-tuning and investigating its impact across various tasks and languages. Our findings demonstrate that the significance of positional encoding diminishes as the morphological complexity of a language increases. Across all experiments, we observe clustering of languages according to their morphological typology - with analytic languages at one end and synthetic languages at the opposite end.
PhysicsAssistant: An LLM-Powered Interactive Learning Robot for Physics Lab Investigations
Mar 27, 2024Robot systems in education can leverage Large language models' (LLMs) natural language understanding capabilities to provide assistance and facilitate learning. This paper proposes a multimodal interactive robot (PhysicsAssistant) built on YOLOv8 object detection, cameras, speech recognition, and chatbot using LLM to provide assistance to students' physics labs. We conduct a user study on ten 8th-grade students to empirically evaluate the performance of PhysicsAssistant with a human expert. The Expert rates the assistants' responses to student queries on a 0-4 scale based on Bloom's taxonomy to provide educational support. We have compared the performance of PhysicsAssistant (YOLOv8+GPT-3.5-turbo) with GPT-4 and found that the human expert rating of both systems for factual understanding is the same. However, the rating of GPT-4 for conceptual and procedural knowledge (3 and 3.2 vs 2.2 and 2.6, respectively) is significantly higher than PhysicsAssistant (p < 0.05). However, the response time of GPT-4 is significantly higher than PhysicsAssistant (3.54 vs 1.64 sec, p < 0.05). Hence, despite the relatively lower response quality of PhysicsAssistant than GPT-4, it has shown potential for being used as a real-time lab assistant to provide timely responses and can offload teachers' labor to assist with repetitive tasks. To the best of our knowledge, this is the first attempt to build such an interactive multimodal robotic assistant for K-12 science (physics) education.
Probing the Information Encoded in Neural-based Acoustic Models of Automatic Speech Recognition Systems
Feb 29, 2024Deep learning architectures have made significant progress in terms of performance in many research areas. The automatic speech recognition (ASR) field has thus benefited from these scientific and technological advances, particularly for acoustic modeling, now integrating deep neural network architectures. However, these performance gains have translated into increased complexity regarding the information learned and conveyed through these black-box architectures. Following many researches in neural networks interpretability, we propose in this article a protocol that aims to determine which and where information is located in an ASR acoustic model (AM). To do so, we propose to evaluate AM performance on a determined set of tasks using intermediate representations (here, at different layer levels). Regarding the performance variation and targeted tasks, we can emit hypothesis about which information is enhanced or perturbed at different architecture steps. Experiments are performed on both speaker verification, acoustic environment classification, gender classification, tempo-distortion detection systems and speech sentiment/emotion identification. Analysis showed that neural-based AMs hold heterogeneous information that seems surprisingly uncorrelated with phoneme recognition, such as emotion, sentiment or speaker identity. The low-level hidden layers globally appears useful for the structuring of information while the upper ones would tend to delete useless information for phoneme recognition.
An Effective Mixture-Of-Experts Approach For Code-Switching Speech Recognition Leveraging Encoder Disentanglement
Feb 27, 2024With the massive developments of end-to-end (E2E) neural networks, recent years have witnessed unprecedented breakthroughs in automatic speech recognition (ASR). However, the codeswitching phenomenon remains a major obstacle that hinders ASR from perfection, as the lack of labeled data and the variations between languages often lead to degradation of ASR performance. In this paper, we focus exclusively on improving the acoustic encoder of E2E ASR to tackle the challenge caused by the codeswitching phenomenon. Our main contributions are threefold: First, we introduce a novel disentanglement loss to enable the lower-layer of the encoder to capture inter-lingual acoustic information while mitigating linguistic confusion at the higher-layer of the encoder. Second, through comprehensive experiments, we verify that our proposed method outperforms the prior-art methods using pretrained dual-encoders, meanwhile having access only to the codeswitching corpus and consuming half of the parameterization. Third, the apparent differentiation of the encoders' output features also corroborates the complementarity between the disentanglement loss and the mixture-of-experts (MoE) architecture.
A Cross-Modal Approach to Silent Speech with LLM-Enhanced Recognition
Mar 02, 2024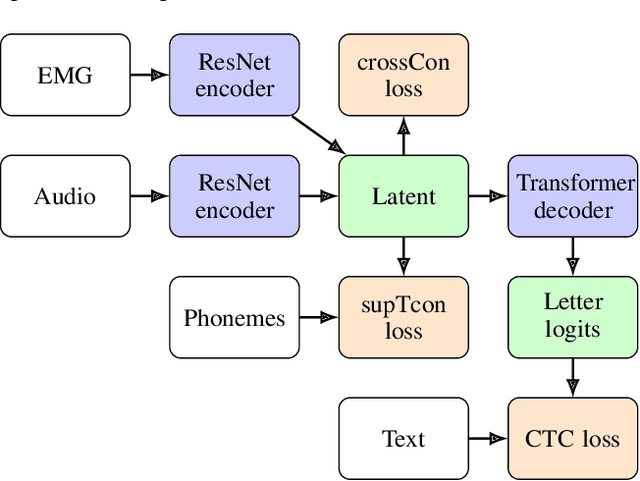
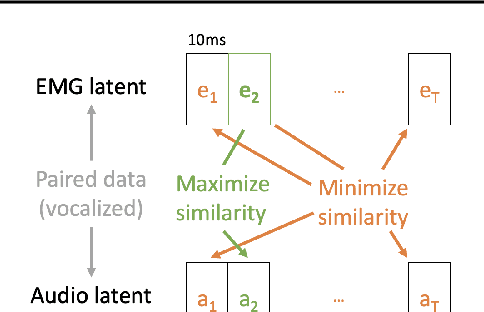

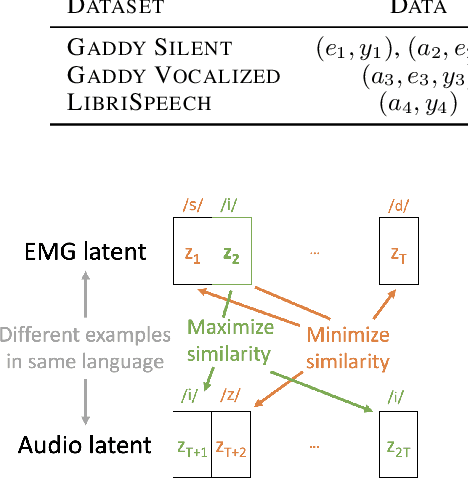
Silent Speech Interfaces (SSIs) offer a noninvasive alternative to brain-computer interfaces for soundless verbal communication. We introduce Multimodal Orofacial Neural Audio (MONA), a system that leverages cross-modal alignment through novel loss functions--cross-contrast (crossCon) and supervised temporal contrast (supTcon)--to train a multimodal model with a shared latent representation. This architecture enables the use of audio-only datasets like LibriSpeech to improve silent speech recognition. Additionally, our introduction of Large Language Model (LLM) Integrated Scoring Adjustment (LISA) significantly improves recognition accuracy. Together, MONA LISA reduces the state-of-the-art word error rate (WER) from 28.8% to 12.2% in the Gaddy (2020) benchmark dataset for silent speech on an open vocabulary. For vocal EMG recordings, our method improves the state-of-the-art from 23.3% to 3.7% WER. In the Brain-to-Text 2024 competition, LISA performs best, improving the top WER from 9.8% to 8.9%. To the best of our knowledge, this work represents the first instance where noninvasive silent speech recognition on an open vocabulary has cleared the threshold of 15% WER, demonstrating that SSIs can be a viable alternative to automatic speech recognition (ASR). Our work not only narrows the performance gap between silent and vocalized speech but also opens new possibilities in human-computer interaction, demonstrating the potential of cross-modal approaches in noisy and data-limited regimes.
Speech Emotion Recognition Via CNN-Transforemr and Multidimensional Attention Mechanism
Mar 07, 2024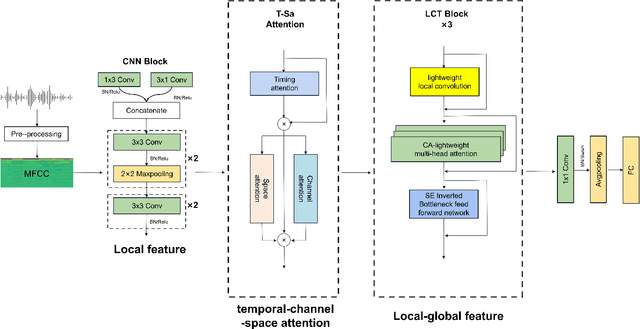
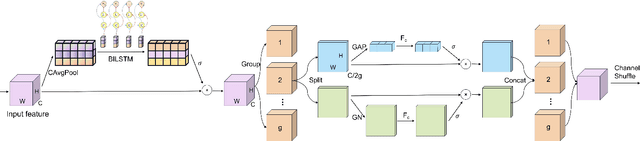
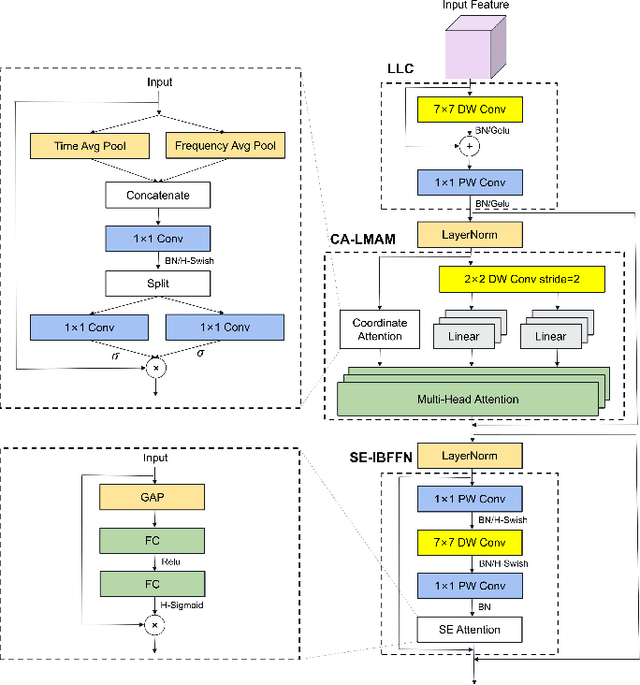
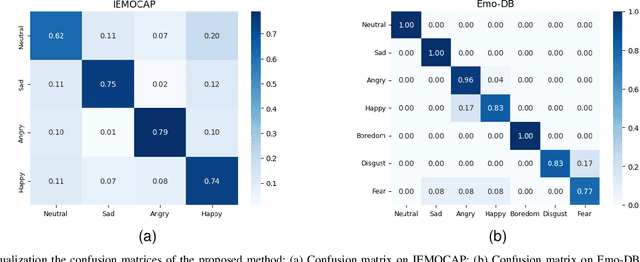
Speech Emotion Recognition (SER) is crucial in human-machine interactions. Mainstream approaches utilize Convolutional Neural Networks or Recurrent Neural Networks to learn local energy feature representations of speech segments from speech information, but struggle with capturing global information such as the duration of energy in speech. Some use Transformers to capture global information, but there is room for improvement in terms of parameter count and performance. Furthermore, existing attention mechanisms focus on spatial or channel dimensions, hindering learning of important temporal information in speech. In this paper, to model local and global information at different levels of granularity in speech and capture temporal, spatial and channel dependencies in speech signals, we propose a Speech Emotion Recognition network based on CNN-Transformer and multi-dimensional attention mechanisms. Specifically, a stack of CNN blocks is dedicated to capturing local information in speech from a time-frequency perspective. In addition, a time-channel-space attention mechanism is used to enhance features across three dimensions. Moreover, we model local and global dependencies of feature sequences using large convolutional kernels with depthwise separable convolutions and lightweight Transformer modules. We evaluate the proposed method on IEMOCAP and Emo-DB datasets and show our approach significantly improves the performance over the state-of-the-art methods. Our code is available on https://github.com/SCNU-RISLAB/CNN-Transforemr-and-Multidimensional-Attention-Mechanism
Extracting Biomedical Entities from Noisy Audio Transcripts
Mar 26, 2024Automatic Speech Recognition (ASR) technology is fundamental in transcribing spoken language into text, with considerable applications in the clinical realm, including streamlining medical transcription and integrating with Electronic Health Record (EHR) systems. Nevertheless, challenges persist, especially when transcriptions contain noise, leading to significant drops in performance when Natural Language Processing (NLP) models are applied. Named Entity Recognition (NER), an essential clinical task, is particularly affected by such noise, often termed the ASR-NLP gap. Prior works have primarily studied ASR's efficiency in clean recordings, leaving a research gap concerning the performance in noisy environments. This paper introduces a novel dataset, BioASR-NER, designed to bridge the ASR-NLP gap in the biomedical domain, focusing on extracting adverse drug reactions and mentions of entities from the Brief Test of Adult Cognition by Telephone (BTACT) exam. Our dataset offers a comprehensive collection of almost 2,000 clean and noisy recordings. In addressing the noise challenge, we present an innovative transcript-cleaning method using GPT4, investigating both zero-shot and few-shot methodologies. Our study further delves into an error analysis, shedding light on the types of errors in transcription software, corrections by GPT4, and the challenges GPT4 faces. This paper aims to foster improved understanding and potential solutions for the ASR-NLP gap, ultimately supporting enhanced healthcare documentation practices.
Real-time Speech Extraction Using Spatially Regularized Independent Low-rank Matrix Analysis and Rank-constrained Spatial Covariance Matrix Estimation
Mar 19, 2024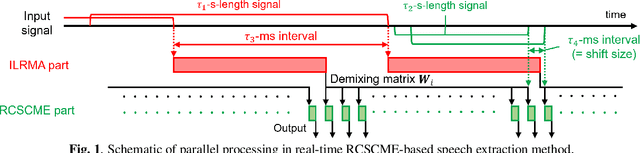
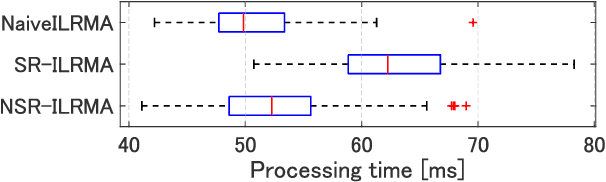
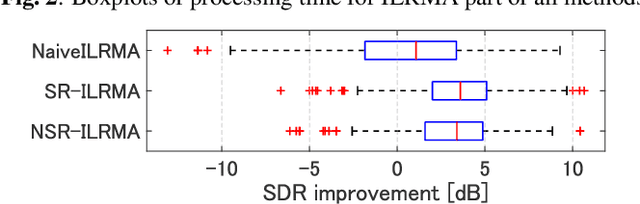
Real-time speech extraction is an important challenge with various applications such as speech recognition in a human-like avatar/robot. In this paper, we propose the real-time extension of a speech extraction method based on independent low-rank matrix analysis (ILRMA) and rank-constrained spatial covariance matrix estimation (RCSCME). The RCSCME-based method is a multichannel blind speech extraction method that demonstrates superior speech extraction performance in diffuse noise environments. To improve the performance, we introduce spatial regularization into the ILRMA part of the RCSCME-based speech extraction and design two regularizers. Speech extraction experiments demonstrated that the proposed methods can function in real time and the designed regularizers improve the speech extraction performance.
Deep functional multiple index models with an application to SER
Mar 26, 2024Speech Emotion Recognition (SER) plays a crucial role in advancing human-computer interaction and speech processing capabilities. We introduce a novel deep-learning architecture designed specifically for the functional data model known as the multiple-index functional model. Our key innovation lies in integrating adaptive basis layers and an automated data transformation search within the deep learning framework. Simulations for this new model show good performances. This allows us to extract features tailored for chunk-level SER, based on Mel Frequency Cepstral Coefficients (MFCCs). We demonstrate the effectiveness of our approach on the benchmark IEMOCAP database, achieving good performance compared to existing methods.
Initial Decoding with Minimally Augmented Language Model for Improved Lattice Rescoring in Low Resource ASR
Mar 16, 2024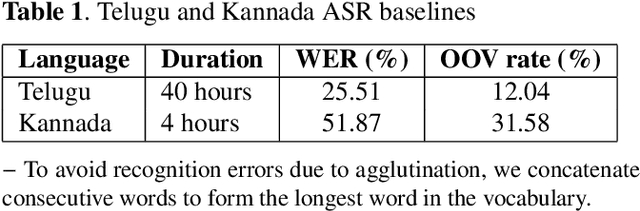
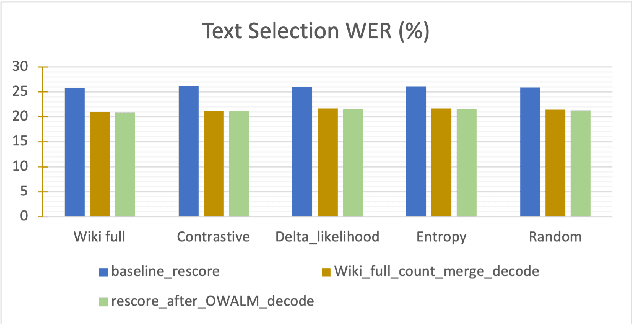
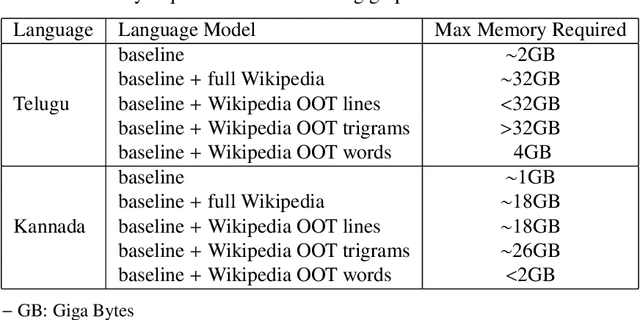
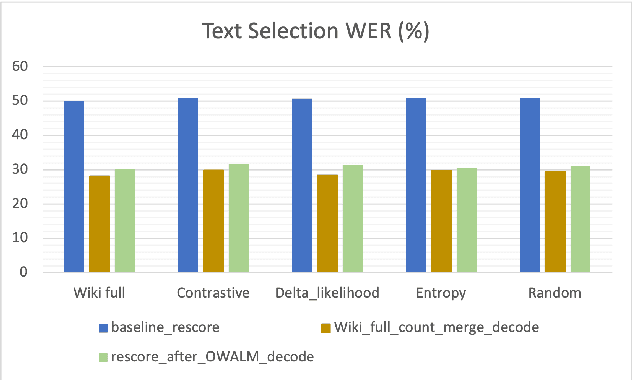
This paper addresses the problem of improving speech recognition accuracy with lattice rescoring in low-resource languages where the baseline language model is insufficient for generating inclusive lattices. We minimally augment the baseline language model with word unigram counts that are present in a larger text corpus of the target language but absent in the baseline. The lattices generated after decoding with such an augmented baseline language model are more comprehensive. We obtain 21.8% (Telugu) and 41.8% (Kannada) relative word error reduction with our proposed method. This reduction in word error rate is comparable to 21.5% (Telugu) and 45.9% (Kannada) relative word error reduction obtained by decoding with full Wikipedia text augmented language mode while our approach consumes only 1/8th the memory. We demonstrate that our method is comparable with various text selection-based language model augmentation and also consistent for data sets of different sizes. Our approach is applicable for training speech recognition systems under low resource conditions where speech data and compute resources are insufficient, while there is a large text corpus that is available in the target language. Our research involves addressing the issue of out-of-vocabulary words of the baseline in general and does not focus on resolving the absence of named entities. Our proposed method is simple and yet computationally less expensive.