 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Pre-trained Speech Processing Models Contain Human-Like Biases that Propagate to Speech Emotion Recognition
Oct 29, 2023
Previous work has established that a person's demographics and speech style affect how well speech processing models perform for them. But where does this bias come from? In this work, we present the Speech Embedding Association Test (SpEAT), a method for detecting bias in one type of model used for many speech tasks: pre-trained models. The SpEAT is inspired by word embedding association tests in natural language processing, which quantify intrinsic bias in a model's representations of different concepts, such as race or valence (something's pleasantness or unpleasantness) and capture the extent to which a model trained on large-scale socio-cultural data has learned human-like biases. Using the SpEAT, we test for six types of bias in 16 English speech models (including 4 models also trained on multilingual data), which come from the wav2vec 2.0, HuBERT, WavLM, and Whisper model families. We find that 14 or more models reveal positive valence (pleasantness) associations with abled people over disabled people, with European-Americans over African-Americans, with females over males, with U.S. accented speakers over non-U.S. accented speakers, and with younger people over older people. Beyond establishing that pre-trained speech models contain these biases, we also show that they can have real world effects. We compare biases found in pre-trained models to biases in downstream models adapted to the task of Speech Emotion Recognition (SER) and find that in 66 of the 96 tests performed (69%), the group that is more associated with positive valence as indicated by the SpEAT also tends to be predicted as speaking with higher valence by the downstream model. Our work provides evidence that, like text and image-based models, pre-trained speech based-models frequently learn human-like biases. Our work also shows that bias found in pre-trained models can propagate to the downstream task of SER.
Combining Language Models For Specialized Domains: A Colorful Approach
Nov 01, 2023General purpose language models (LMs) encounter difficulties when processing domain-specific jargon and terminology, which are frequently utilized in specialized fields such as medicine or industrial settings. Moreover, they often find it challenging to interpret mixed speech that blends general language with specialized jargon. This poses a challenge for automatic speech recognition systems operating within these specific domains. In this work, we introduce a novel approach that integrates domain-specific or secondary LM into general-purpose LM. This strategy involves labeling, or "coloring", each word to indicate its association with either the general or the domain-specific LM. We develop an optimized algorithm that enhances the beam search algorithm to effectively handle inferences involving colored words. Our evaluations indicate that this approach is highly effective in integrating jargon into language tasks. Notably, our method substantially lowers the error rate for domain-specific words without compromising performance in the general domain.
Improved Child Text-to-Speech Synthesis through Fastpitch-based Transfer Learning
Nov 07, 2023Speech synthesis technology has witnessed significant advancements in recent years, enabling the creation of natural and expressive synthetic speech. One area of particular interest is the generation of synthetic child speech, which presents unique challenges due to children's distinct vocal characteristics and developmental stages. This paper presents a novel approach that leverages the Fastpitch text-to-speech (TTS) model for generating high-quality synthetic child speech. This study uses the transfer learning training pipeline. The approach involved finetuning a multi-speaker TTS model to work with child speech. We use the cleaned version of the publicly available MyST dataset (55 hours) for our finetuning experiments. We also release a prototype dataset of synthetic speech samples generated from this research together with model code to support further research. By using a pretrained MOSNet, we conducted an objective assessment that showed a significant correlation between real and synthetic child voices. Additionally, to validate the intelligibility of the generated speech, we employed an automatic speech recognition (ASR) model to compare the word error rates (WER) of real and synthetic child voices. The speaker similarity between the real and generated speech is also measured using a pretrained speaker encoder.
DistilWhisper: Efficient Distillation of Multi-task Speech Models via Language-Specific Experts
Nov 02, 2023Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still under-performs on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we propose DistilWhisper, an approach able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Server-side Rescoring of Spoken Entity-centric Knowledge Queries for Virtual Assistants
Nov 02, 2023On-device Virtual Assistants (VAs) powered by Automatic Speech Recognition (ASR) require effective knowledge integration for the challenging entity-rich query recognition. In this paper, we conduct an empirical study of modeling strategies for server-side rescoring of spoken information domain queries using various categories of Language Models (LMs) (N-gram word LMs, sub-word neural LMs). We investigate the combination of on-device and server-side signals, and demonstrate significant WER improvements of 23%-35% on various entity-centric query subpopulations by integrating various server-side LMs compared to performing ASR on-device only. We also perform a comparison between LMs trained on domain data and a GPT-3 variant offered by OpenAI as a baseline. Furthermore, we also show that model fusion of multiple server-side LMs trained from scratch most effectively combines complementary strengths of each model and integrates knowledge learned from domain-specific data to a VA ASR system.
Careful Whisper -- leveraging advances in automatic speech recognition for robust and interpretable aphasia subtype classification
Aug 02, 2023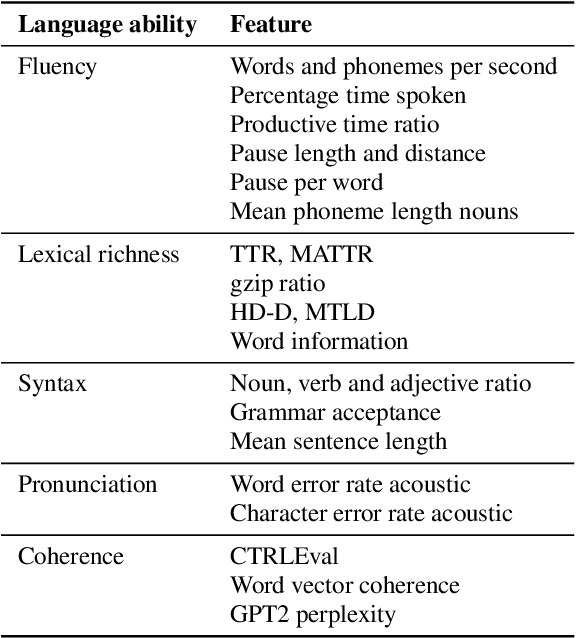
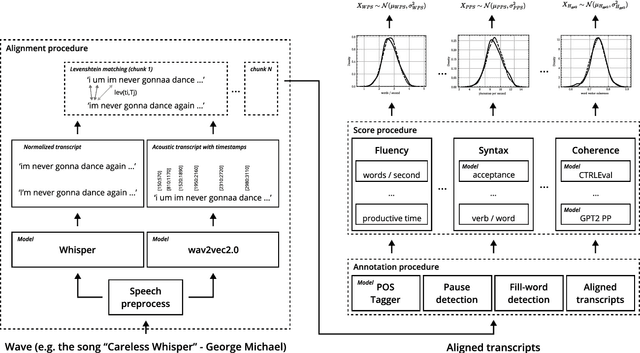

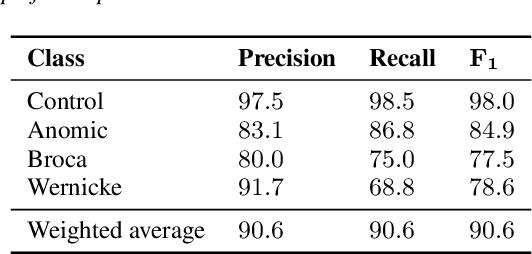
This paper presents a fully automated approach for identifying speech anomalies from voice recordings to aid in the assessment of speech impairments. By combining Connectionist Temporal Classification (CTC) and encoder-decoder-based automatic speech recognition models, we generate rich acoustic and clean transcripts. We then apply several natural language processing methods to extract features from these transcripts to produce prototypes of healthy speech. Basic distance measures from these prototypes serve as input features for standard machine learning classifiers, yielding human-level accuracy for the distinction between recordings of people with aphasia and a healthy control group. Furthermore, the most frequently occurring aphasia types can be distinguished with 90% accuracy. The pipeline is directly applicable to other diseases and languages, showing promise for robustly extracting diagnostic speech biomarkers.
Churn Prediction via Multimodal Fusion Learning:Integrating Customer Financial Literacy, Voice, and Behavioral Data
Dec 03, 2023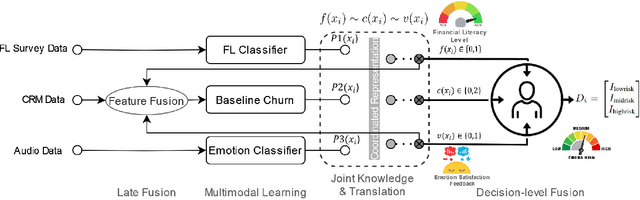
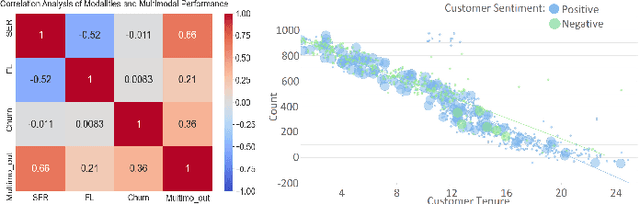
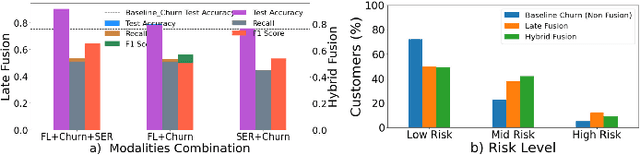
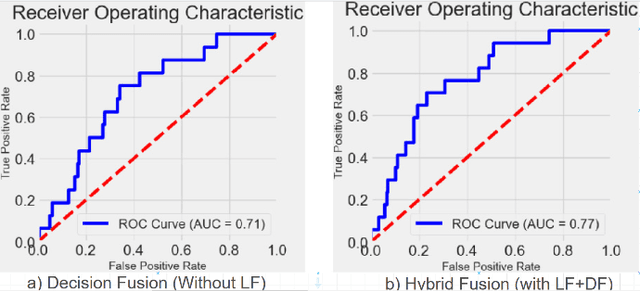
In todays competitive landscape, businesses grapple with customer retention. Churn prediction models, although beneficial, often lack accuracy due to the reliance on a single data source. The intricate nature of human behavior and high dimensional customer data further complicate these efforts. To address these concerns, this paper proposes a multimodal fusion learning model for identifying customer churn risk levels in financial service providers. Our multimodal approach integrates customer sentiments financial literacy (FL) level, and financial behavioral data, enabling more accurate and bias-free churn prediction models. The proposed FL model utilizes a SMOGN COREG supervised model to gauge customer FL levels from their financial data. The baseline churn model applies an ensemble artificial neural network and oversampling techniques to predict churn propensity in high-dimensional financial data. We also incorporate a speech emotion recognition model employing a pre-trained CNN-VGG16 to recognize customer emotions based on pitch, energy, and tone. To integrate these diverse features while retaining unique insights, we introduced late and hybrid fusion techniques that complementary boost coordinated multimodal co learning. Robust metrics were utilized to evaluate the proposed multimodal fusion model and hence the approach validity, including mean average precision and macro-averaged F1 score. Our novel approach demonstrates a marked improvement in churn prediction, achieving a test accuracy of 91.2%, a Mean Average Precision (MAP) score of 66, and a Macro-Averaged F1 score of 54 through the proposed hybrid fusion learning technique compared with late fusion and baseline models. Furthermore, the analysis demonstrates a positive correlation between negative emotions, low FL scores, and high-risk customers.
Identifying Planetary Names in Astronomy Papers: A Multi-Step Approach
Dec 17, 2023The automatic identification of planetary feature names in astronomy publications presents numerous challenges. These features include craters, defined as roughly circular depressions resulting from impact or volcanic activity; dorsas, which are elongate raised structures or wrinkle ridges; and lacus, small irregular patches of dark, smooth material on the Moon, referred to as "lake" (Planetary Names Working Group, n.d.). Many feature names overlap with places or people's names that they are named after, for example, Syria, Tempe, Einstein, and Sagan, to name a few (U.S. Geological Survey, n.d.). Some feature names have been used in many contexts, for instance, Apollo, which can refer to mission, program, sample, astronaut, seismic, seismometers, core, era, data, collection, instrument, and station, in addition to the crater on the Moon. Some feature names can appear in the text as adjectives, like the lunar craters Black, Green, and White. Some feature names in other contexts serve as directions, like craters West and South on the Moon. Additionally, some features share identical names across different celestial bodies, requiring disambiguation, such as the Adams crater, which exists on both the Moon and Mars. We present a multi-step pipeline combining rule-based filtering, statistical relevance analysis, part-of-speech (POS) tagging, named entity recognition (NER) model, hybrid keyword harvesting, knowledge graph (KG) matching, and inference with a locally installed large language model (LLM) to reliably identify planetary names despite these challenges. When evaluated on a dataset of astronomy papers from the Astrophysics Data System (ADS), this methodology achieves an F1-score over 0.97 in disambiguating planetary feature names.
Augmenty: A Python Library for Structured Text Augmentation
Dec 09, 2023Augmnety is a Python library for structured text augmentation. It is built on top of spaCy and allows for augmentation of both the text and its annotations. Augmenty provides a wide range of augmenters which can be combined in a flexible manner to create complex augmentation pipelines. It also includes a set of primitives that can be used to create custom augmenters such as word replacement augmenters. This functionality allows for augmentations within a range of applications such as named entity recognition (NER), part-of-speech tagging, and dependency parsing.
Leveraging Timestamp Information for Serialized Joint Streaming Recognition and Translation
Oct 23, 2023The growing need for instant spoken language transcription and translation is driven by increased global communication and cross-lingual interactions. This has made offering translations in multiple languages essential for user applications. Traditional approaches to automatic speech recognition (ASR) and speech translation (ST) have often relied on separate systems, leading to inefficiencies in computational resources, and increased synchronization complexity in real time. In this paper, we propose a streaming Transformer-Transducer (T-T) model able to jointly produce many-to-one and one-to-many transcription and translation using a single decoder. We introduce a novel method for joint token-level serialized output training based on timestamp information to effectively produce ASR and ST outputs in the streaming setting. Experiments on {it,es,de}->en prove the effectiveness of our approach, enabling the generation of one-to-many joint outputs with a single decoder for the first time.